SpidR-Adapt: A Universal Speech Representation Model for Few-Shot Adaptation
Abstract: Human infants, with only a few hundred hours of speech exposure, acquire basic units of new languages, highlighting a striking efficiency gap compared to the data-hungry self-supervised speech models. To address this gap, this paper introduces SpidR-Adapt for rapid adaptation to new languages using minimal unlabeled data. We cast such low-resource speech representation learning as a meta-learning problem and construct a multi-task adaptive pre-training (MAdaPT) protocol which formulates the adaptation process as a bi-level optimization framework. To enable scalable meta-training under this framework, we propose a novel heuristic solution, first-order bi-level optimization (FOBLO), avoiding heavy computation costs. Finally, we stabilize meta-training by using a robust initialization through interleaved supervision which alternates self-supervised and supervised objectives. Empirically, SpidR-Adapt achieves rapid gains in phonemic discriminability (ABX) and spoken language modeling (sWUGGY, sBLIMP, tSC), improving over in-domain LLMs after training on less than 1h of target-language audio, over $100\times$ more data-efficient than standard training. These findings highlight a practical, architecture-agnostic path toward biologically inspired, data-efficient representations. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr-adapt.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SpidR-Adapt, explained simply
1) What’s this paper about?
This paper is about teaching computers to understand the basic sounds and patterns of new languages using very little audio. Human babies can start picking up the building blocks of a language after hearing just a few hundred hours. Most AI models need thousands of hours. The authors introduce a new method, called SpidR-Adapt, that helps speech models learn new languages much faster—sometimes after hearing less than an hour of audio.
2) What questions are the researchers asking?
The paper focuses on a few big questions:
- How can we make speech models learn new languages quickly when there’s not much data?
- Can we design a training process that helps a model “learn how to learn” from tiny amounts of audio?
- Will this faster learning still produce good results on tests that measure language understanding, like recognizing sounds, words, and grammar?
3) How does their approach work?
Think of this as training a model to be a fast learner, not just a good learner.
To do this, the authors combine three main ideas:
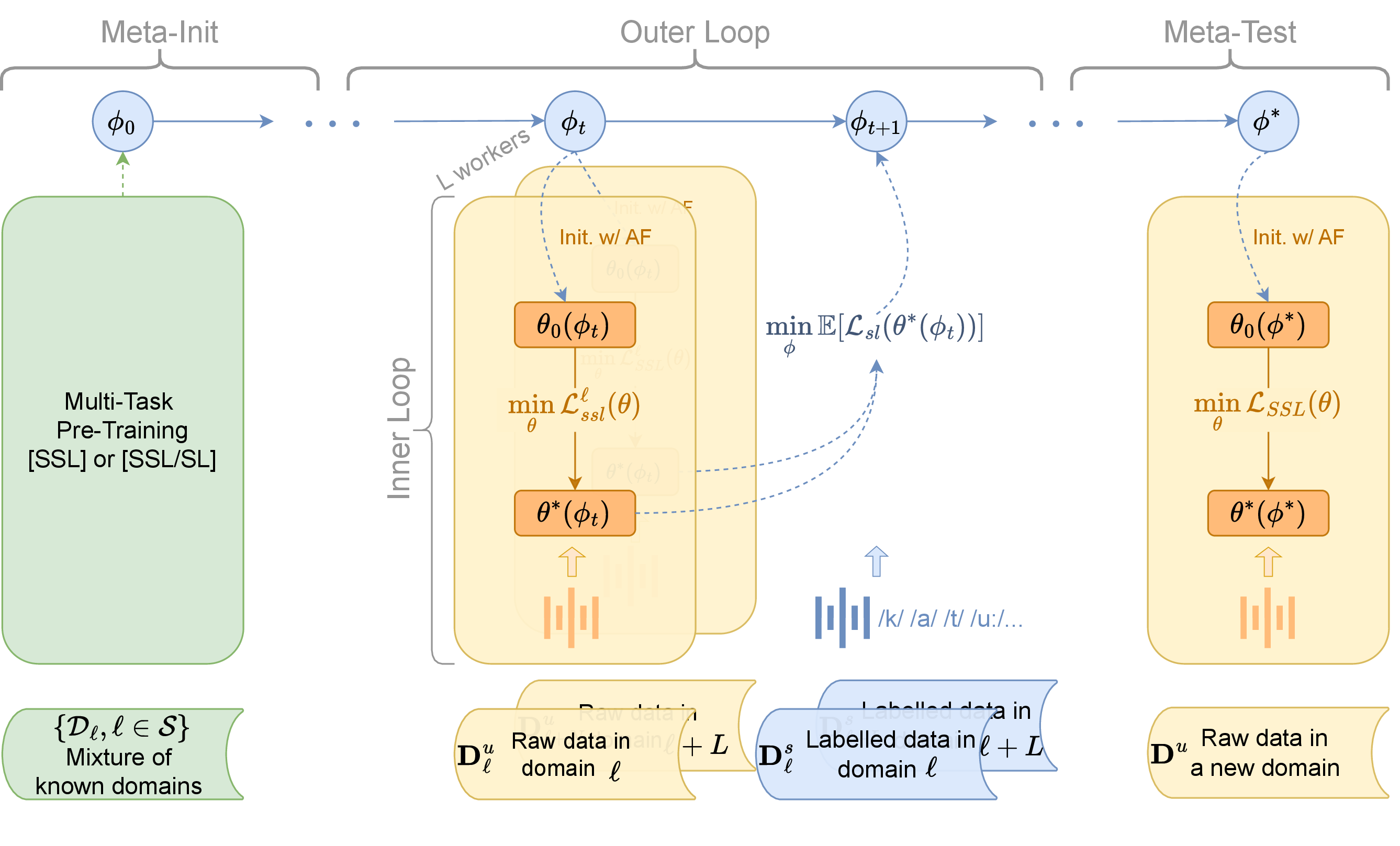
- Multi-task Adaptive Pre-training (MAdaPT): Imagine “practice lives” for the model. In each practice round (an episode), the model pretends it’s learning a new language from a small amount of unlabeled audio (like a baby hearing speech without captions). Then, the model gets a tiny bit of feedback from labeled examples (like a teacher giving hints). Over many episodes and many languages, the model learns general skills that make it adapt quickly to new languages later.
- First-Order Bi-Level Optimization (FOBLO):
- Inner loop: practice adapting to a small dataset without labels.
- Outer loop: get feedback using a few labeled examples to adjust how the model should adapt next time.
FOBLO is a shortcut that avoids heavy math (no expensive second-derivative calculations). It updates the model based on the difference between “before feedback” and “after feedback,” which is much faster but still effective.
- Interleaved supervision: Most of the time the model learns from unlabeled audio (self-supervised learning), but occasionally it gets small, labeled hints about phonemes (the smallest sound units, like “p” or “b”). This is like mostly practicing on your own but sometimes being corrected by a coach. Interleaving these two helps the model start from a stronger, more stable place.
There’s also “active forgetting”:
- Active forgetting: At the start of each practice round, the model resets some parts that tend to store too-specific details from earlier languages. It’s like wiping a whiteboard before starting a new lesson so the model doesn’t get stuck on old patterns and can generalize better.
All of this is built on top of a strong speech model called SpidR, so the new system is called SpidR-Adapt. The method is “architecture-agnostic,” which means it could work with other similar models too.
Key terms in everyday language:
- Unlabeled data: audio without captions or phoneme labels.
- Labeled data: audio with the correct answers attached (like which phoneme is being spoken).
- Meta-learning: “learning to learn” quickly, by practicing on many small tasks so you adapt better to new ones later.
- Bi-level optimization: two-layer training—one layer practices adapting, the other layer watches how that went and updates the model to adapt better next time.
4) What did they find, and why does it matter?
Main findings:
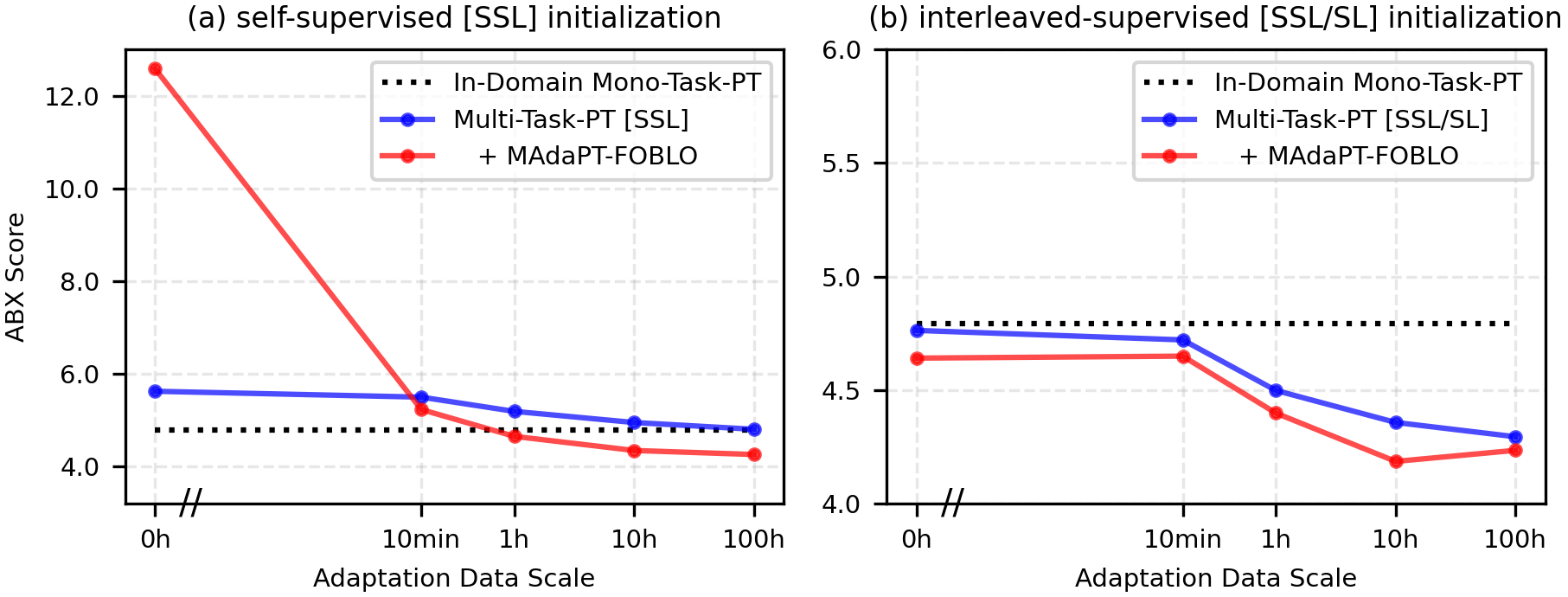
- Huge data savings: SpidR-Adapt reaches the quality of models trained on thousands of hours of in-language audio after adapting with less than 1 hour of new-language audio. That’s about 100× more data-efficient than standard training.
- Better sound discrimination: The model quickly improves at telling apart similar speech sounds (measured by ABX tests, which are like “spot the difference” games for sounds).
- Stronger spoken language modeling: On tasks that test word-likeness, grammar choices, and story continuation (sWUGGY, sBLIMP, and a story-cloze test), the adapted model performs better than standard methods and often close to strong “in-domain” systems.
- Robust across languages: Trained on many languages and tested on unseen ones, the approach adapts quickly, even with tiny audio samples.
Why this matters:
- Many languages don’t have huge recorded datasets. A method that learns from minutes or hours instead of thousands of hours makes speech technology more accessible worldwide.
- It moves AI a step closer to the efficiency of human learning.
5) What’s the impact of this research?
This work shows a practical way to build speech models that can quickly pick up new languages using very little data—more like how children learn. It could help:
- Support low-resource languages (where there isn’t much recorded speech).
- Speed up building voice assistants and speech tools for new regions.
- Inspire more “learning to learn” approaches in other areas of AI.
The authors also share code and model checkpoints, making it easier for others to try and build on this work.
In short: SpidR-Adapt teaches speech models to adapt fast—using clever training loops, occasional hints, and smart resets—so they can learn new languages with only a tiny amount of audio.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to guide concrete next steps for researchers.
- Reliance on supervised outer-loop labels: quantify the performance gap between FOBLO (with phoneme supervision) and fully unsupervised meta-optimization; develop and evaluate label-free outer-loop objectives (e.g., ABX-driven loss, mutual-information maximization, articulatory feature proxies, contrastive constraints across speakers).
- Architecture-agnostic claim remains untested: replicate MAdaPT-FOBLO with non-SpidR backbones (HuBERT, WavLM, wav2vec 2.0, Whisper encoders) and report whether gains persist and where adaptations are needed.
- Lack of theoretical guarantees for FOBLO with mismatched inner/outer losses: provide convergence analysis, characterize bias introduced by first-order stopping of inner-loop gradients, and compare against second-order bi-level methods (MAML-style implicit gradients, differentiable bilevel solvers).
- Active forgetting design is underexplored: systematically ablate which components to reset (heads, codebooks, teacher, embeddings), reset frequency, and partial vs full resets; quantify stability–plasticity trade-offs and catastrophic forgetting across episodes.
- Sensitivity to interleaved supervision schedule: vary supervised step frequency, supervised layer choice, and language-specific heads; report ablations and guidelines for robust meta-initialization without heavy supervision.
- Label noise and sparsity: measure the impact of noisy MFA alignments and limited labeled hours on outer-loop effectiveness; evaluate robust objectives (e.g., label smoothing, confidence-weighted losses, co-teaching) and semi-supervised outer-loop alternatives.
- Limited typological coverage in meta-test: extend evaluation beyond English/French/German to typologically diverse languages (tonal: Mandarin/Vietnamese; agglutinative: Turkish/Finnish; polysynthetic; click languages), low-resource and non-European languages; report performance stratified by typological features.
- Within-language generalization is untested: evaluate adaptation to dialects, accents, code-switching, speaking styles, and demographic variation (age, gender) to test speaker and sociolinguistic robustness.
- Real-world robustness: assess performance under noise, reverberation, channel mismatch (telephony, far-field), and domain shift (broadcast vs conversational speech); test sensitivity to VAD/segmentation choices.
- Data-efficiency accounting: report total pretraining/meta-training hours, wall-clock time, and energy consumption relative to baselines; quantify whether 1-hour adaptation parity offsets the meta-training cost at scale.
- SLM evaluation scope: extend sWUGGY/sBLIMP/tSC beyond English to multiple languages; evaluate multilingual spoken LMs and cross-lingual transfer; include longer-context narrative/coherence and prosody-sensitive tasks.
- Downstream task breadth: test adaptation gains on ASR (low-resource and multilingual), keyword spotting, speaker/intent/emotion recognition, and speech-to-speech/translation to validate broader utility.
- Continual learning dynamics: move from episodic meta-training to online, sequential adaptation; measure retention on previous languages, backward transfer, and catastrophic forgetting; consider EWC/LwF/regularization baselines.
- EMA teacher behavior is not explained: systematically study the effect of freezing the teacher (β0=1) vs standard decay, its interaction with FOBLO/Reptile, and implications for stability and adaptation speed.
- Initialization of codebooks/heads: compare random N(0,1) sampling and 20-step warmup against data-driven schemes (k-means on target audio, orthogonal/codebook diversification, per-speaker initialization), and quantify their impact.
- Task and episode scheduling: explore risk-aware/curriculum task selection across languages, chunk sizes (10h vs shorter), and inner/outer step counts (M/N); investigate streaming mini-budgets (e.g., 1–5 minutes) and their effect on rapid adaptation.
- Parameter-efficient adaptation: evaluate adapters, LoRA, prefix-tuning or head-only updates to reduce compute and memory for on-device adaptation; compare to full finetuning used in meta-test.
- Statistical robustness: report variance across seeds, confidence intervals, and significance tests for ABX/SLM metrics; release multiple checkpoints to support reproducibility.
- Fairness and bias: audit performance across demographic groups and languages underrepresented in VoxPopuli/CommonVoice; analyze potential biases and propose mitigation (balanced sampling, fairness-aware objectives).
- Infant-learning claims: design experiments that align with human developmental trajectories (e.g., comparable exposure schedules, phoneme contrast learning curves) to empirically substantiate biological inspiration claims.
- Security and adversarial robustness: test resilience to adversarial perturbations and spoofing; propose defenses compatible with meta-adaptation.
- Model efficiency and deployability: report parameter counts, memory footprint, inference/adaptation latency, and feasibility on edge devices; explore compression/quantization without harming adaptation.
- Integration of SLM into meta-learning: directly meta-optimize spoken LLMs (outer-loop on SLM objectives) to improve data-efficiency for language modeling, not only representation learning.
- Cross-layer supervision choice: study why 6th vs 8th layer yields best adaptation under different initializations; develop criteria to select supervised/meta-optimized layers automatically.
- Open-source completeness: provide detailed training/runtime scripts for MAdaPT-FOBLO/Reptile, ablation configs, and exact dataset splits to facilitate replication across labs and architectures.
Glossary
- ABX: A phonemic discriminability metric that tests whether embeddings distinguish minimal phone contrasts; lower is better. "We report ABX scores (lower is better) averaged across three test languages (French, German, English)"
- Active forgetting: A mechanism that periodically resets parts of a model to improve plasticity and reduce language-specific overfitting. "To suppress unstable and language-specific learning from past episodes, we introduce an active forgetting mechanism."
- Across-speaker condition: An ABX evaluation setup where A and B are from one speaker and X is from another, making discrimination harder. "while the across-speaker condition uses A and B from one speaker and X from another"
- Bi-level optimization: An optimization setup with nested objectives, where an inner problem is optimized inside an outer one. "we propose a generic bi-level optimization framework"
- Codebook: A set of discrete target representations (vectors) used by the teacher in self-supervised speech models. "is the target codebook of the teacher at the intermediate layer "
- CommonVoice: A multilingual crowdsourced speech dataset used for training and evaluation. "Small-scale adaptation corpora were also created for the meta-development languages, sourced from CommonVoice~\cite{Ardila2020CommonVoice}"
- Episode: A meta-learning unit that simulates an adaptation scenario with an inner-loop and an outer-loop. "each episode consisting 1800 inner- and 200 outer-steps."
- Exponential Moving Average (EMA): A smoothed update mechanism where the teacher parameters track the student via EMA. "The teacher is an exponential moving average (EMA) of the student."
- Few-shot adaptation: Rapid model tuning to a new domain with very limited data. "Overview of SpidR-Adapt for few-shot speech adaptation."
- First-Order Bi-level Optimization (FOBLO): A first-order meta-optimization heuristic that approximates bi-level updates efficiently. "First Order Bi-level Optimization (FOBLO), a meta-optimization heuristic"
- First-order model-agnostic meta-learning (FOMAML): A first-order variant of MAML that avoids second-order derivatives for scalability. "First-order model-agnostic meta-learning (FOMAML) and Reptile"
- HuBERT: A self-supervised speech model that uses masked prediction and clustering to learn representations. "Self-supervised models like HuBERT \citep{hsu2021hubert} and WavLM \citep{chen2022wavlm} use masked prediction and clustering to build speech representations"
- In-Domain (ID): Training or evaluation conducted on data from the same domain or language as the target. "evaluate adaptation capabilities of speech encoders under in-domain (ID) and out-of-domain (OoD) setups."
- Inductive biases: Built-in model predispositions that guide learning toward plausible structures. "A key reason for this discrepancy lies in inductive biases"
- Inductive priors: Prior assumptions embedded in a model that help it generalize efficiently to new tasks or languages. "Without built-in inductive priors, they fail to discover linguistic abstractions of new languages efficiently."
- Inner-loop: The adaptation phase in meta-learning where a model is trained on a specific task. "in the inner-loop, the model is repeatedly adapted to a new task"
- Interleaved supervision: A training strategy that alternates self-supervised steps with occasional supervised phoneme steps. "Interleaved supervision, which incorporates self-supervised training with occasional phoneme supervised steps"
- Jacobian product: A product of Jacobians arising in differentiating through multiple optimization steps; expensive in second-order meta-learning. "computing the Jacobian product of the second derivative"
- MAdaPT (Multi-task Adaptive Pre-Training): A protocol that frames adaptation as bi-level meta-learning across data-scarce episodes. "Multi-task Adaptive Pre-training (MAdaPT), a novel protocol that frames model learning as a bi-level optimization problem."
- Masked prediction: A self-supervised objective where parts of input are masked and the model predicts them. "use masked prediction and clustering to build speech representations"
- Meta-learning: A framework that optimizes models to adapt quickly to new tasks via nested inner/outer training loops. "Meta-learning aims to optimize models for rapid adaptation to new tasks, often in low-resource settings"
- Meta-parameters: Shared parameters shaped by the outer loop to enable fast inner-loop adaptation. "Meta-parameters are shared across concurrent tasks and can be intuitively viewed as inductive biases for speech representation learning."
- Montreal Forced Aligners (MFA): A toolkit for aligning phonemes to audio using forced alignment. "using Montreal Forced Aligners (MFA; \citeauthor{mcauliffe2017montreal}, \citeyear{mcauliffe2017montreal})"
- Online clustering: Clustering that is performed continuously during training to refine discrete targets. "combining self-distillation and online clustering"
- Out-of-Domain (OoD): Training or evaluation on data from a different domain or language than the target. "evaluate adaptation capabilities of speech encoders under in-domain (ID) and out-of-domain (OoD) setups."
- Outer-loop: The meta-optimization phase that updates meta-parameters based on adaptation performance. "and in the outer-loop, its meta-parameters are updated"
- PER (Phoneme Error Rate): An error metric measuring how predicted units map to phoneme sequences. "phoneme error rate (PER), after mapping units to the most frequently associated phoneme"
- PNMI (Phone-Normalized Mutual Information): Mutual information between units and phoneme labels, normalized by phone distributions. "phone-normalized mutual information (PNMI), the uncertainty eliminated about a phone label by a predicted unit"
- Phonemic discriminability: The extent to which learned representations distinguish phonemes. "rapid gains in phonemic discriminability (ABX)"
- Reptile: A first-order meta-learning algorithm that approximates meta-gradients using parameter differences. "including comparisons with alternative meta-learning heuristics (Reptile)"
- Self-distillation: A training approach where a model learns from its own teacher outputs to improve representations. "SpidR \cite{Poli2025SpidR} improves on prior SSL models by combining self-distillation and online clustering"
- Self-supervised learning (SSL): Learning representations using unlabeled data via pretext tasks. "Self-supervised learning (SSL) has enabled speech models to learn rich representations from unlabeled audio"
- Silero Voice Activity Detector: A tool for segmenting audio into speech/non-speech regions during preprocessing. "we apply the Silero Voice Activity Detector to the audio files"
- SLM (Spoken Language Modeling): Modeling linguistic structure directly from speech for tasks like lexical and syntactic judgments. "spoken language modeling (SLM)"
- SpidR: A self-supervised speech model with efficient training that uses self-distillation and online clustering. "We build on SpidR \cite{Poli2025SpidR}, a speech SSL model"
- SpidR-Adapt: A fast-adaptive extension of SpidR designed for data-efficient language adaptation. "This paper introduces SpidR-Adapt for rapid adaptation to new languages using minimal unlabeled data."
- Student-teacher architecture: A setup where a student network learns from a teacher network, often via EMA. "which has a student-teacher architecture."
- Spoken Topic StoryCloze (tSC): A discourse-level evaluation where models choose appropriate story continuations. "Spoken Topic StoryCloze"
- sBLIMP: A speech-based syntactic evaluation using minimal sentence pairs. "sWUGGY, sBLIMP, tSC"
- sWUGGY: A speech-based lexical evaluation testing word vs. non-word probabilities. "sWUGGY, sBLIMP, tSC"
- Triphone: A three-phoneme sequence used in ABX tasks to assess discriminability. "In the ABX task, embeddings are computed for three triphones: A, B, and X."
- VoxCommunis Corpus: A corpus providing phoneme-aligned data for multiple languages. "collected from VoxCommunis Corpus~\cite{ahn2022voxcommunis}"
- VoxPopuli: A large multilingual speech corpus used for unlabeled training. "collected from VoxPopuli~\cite{wang-etal-2021-voxpopuli}"
- WavLM: A self-supervised speech model leveraging masked prediction and clustering. "Self-supervised models like HuBERT \citep{hsu2021hubert} and WavLM \citep{chen2022wavlm} use masked prediction and clustering to build speech representations"
- Within-speaker condition: An ABX evaluation setup where triphones come from the same speaker. "The within-speaker condition uses triphones from the same speaker"
- Zero Resource 2017 Challenge: A benchmark suite for evaluating unsupervised speech representation learning. "the test set of the Zero Resource 2017 Challenge"
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that leverage the paper’s findings, methods, and open-source assets. Each item notes sector alignment, potential tools/workflows, and key assumptions or dependencies.
- Software/Telecom: Rapid language and dialect enablement for speech pipelines
- What: Adapt pre-trained speech representations to a new language or dialect with 10–60 minutes of unlabeled audio; plug into ASR, keyword-spotting, diarization, VAD, and wake-word systems.
- How: Use SpidR-Adapt checkpoints and the MAdaPT-FOBLO workflow; evaluate adaptation with ABX; fine-tune existing decoders or downstream classifiers.
- Assumptions/Dependencies: Access to a small, representative unlabeled audio sample from the target language; modest compute for adaptation (single GPU is sufficient); availability of downstream supervised components (e.g., LLMs/decoders).
- Accessibility: Accent- and speaker-specific personalization on device
- What: Improve recognition for regional accents or atypical speech with a brief user-specific unlabeled recording.
- How: Run few-shot adaptation on-device (or at the edge), leveraging active forgetting for plasticity; validate with ABX before deployment.
- Assumptions/Dependencies: On-device or edge compute capacity; privacy-preserving data handling and storage; integration into mobile/OS speech stacks.
- Customer Service and Finance: Multilingual call center analytics in low-resource markets
- What: Fast adaptation of embeddings for keyword spotting, intent detection, topic modeling in contact-center audio where labels are scarce.
- How: Adapt representations on unlabeled call snippets; plug into existing analytics/QA pipelines; monitor sWUGGY/sBLIMP proxies for linguistic quality.
- Assumptions/Dependencies: Legal and ethical access to unlabeled call audio; existing analytics stack; domain match between adaptation sample and live traffic.
- Content Moderation and Safety: Rapid language coverage expansion
- What: Extend keyword detection or safety classifiers to new languages quickly without labeled corpora.
- How: Adapt embeddings using MAdaPT-FOBLO; build lightweight supervised classifiers on top of adapted features.
- Assumptions/Dependencies: Small unlabeled corpora; scalable inference infrastructure; clear policies for data use.
- Academia (Speech/Phonology/Computational Linguistics): Zero-resource experimentation
- What: Study phonemic discriminability, plasticity, and cross-lingual transfer using ABX, PNMI, PER and spoken-language modeling metrics.
- How: Use the open-source SpidR-Adapt code and checkpoints; fastabx for evaluation; replicate MAdaPT/FOBLO and interleaved supervision regimes.
- Assumptions/Dependencies: Familiarity with PyTorch toolchains; ethical access to audio datasets; reproducible evaluation protocols.
- Field Linguistics and Language Documentation: Bootstrapping units in endangered languages
- What: Derive phoneme-like units and spoken-language features from hours of field recordings to accelerate lexicon building and annotation.
- How: Adapt representations to unlabeled community audio; use ABX/PNMI to quantify unit quality; iteratively refine with small supervised labels if available.
- Assumptions/Dependencies: Consent-based data collection; variable acoustic conditions; potential need for domain-specific cleanup.
- Education: Pronunciation feedback and accent-aware learning aids
- What: Improve phone-level discriminability for learners; provide accent-aware pronunciation scoring and corrective feedback.
- How: Adapt to the learner’s accent with brief unlabeled recordings; integrate adapted features into pronunciation scoring modules.
- Assumptions/Dependencies: Small personal audio samples; alignment tools or proxy metrics to guide feedback quality.
- Robotics/Industrial Voice Interfaces: Rapid adaptation for workforce accents
- What: Robust voice commands for mixed-accent environments (e.g., warehouses, manufacturing floors).
- How: Collect a small unlabeled sample from the site; adapt embeddings; deploy updated voice-commands system.
- Assumptions/Dependencies: Domain noise robustness; on-prem or edge compute; safety-critical validation.
- Energy/Sustainability: Lower training energy and costs
- What: Replace multi-thousand-hour training cycles with hour-level adaptation to reduce compute and carbon footprint.
- How: Adopt MAdaPT-FOBLO for language coverage expansion; track energy savings versus traditional SSL runs.
- Assumptions/Dependencies: Availability of initial meta-trained checkpoints; organizational willingness to shift training strategies.
- Government/Policy: Multilingual public-service voice lines and IVR
- What: Quickly add language support to hotlines and IVR systems in under-resourced languages using unlabeled citizen speech.
- How: Adapt embeddings on anonymized, consented audio; deploy language updates faster than classic data-collection cycles.
- Assumptions/Dependencies: Regulatory compliance (privacy/consent), fair-use and procurement policies; oversight for bias and accessibility.
Long-Term Applications
The following use cases are promising but require further research, scaling, or integration beyond the current paper’s scope.
- Healthcare: Personalization for atypical speech (e.g., dysarthria, aphasia)
- What: Patient-specific few-shot adaptation to improve clinical ASR and communication aids.
- How: Extend MAdaPT to robustly handle clinical variability; integrate with healthcare-grade evaluation and deployment.
- Assumptions/Dependencies: Clinical datasets, rigorous validation, privacy/security compliance (HIPAA/GDPR).
- End-to-End Spoken Language Modeling and ASR inside MAdaPT
- What: Meta-learn entire SLM/ASR stacks (not just representations) for label-efficient adaptation.
- How: Incorporate decoders and LMs into the bi-level training; explore FOBLO-style updates for full pipelines.
- Assumptions/Dependencies: Algorithmic extensions, compute and engineering effort, more comprehensive benchmarks.
- Fully Label-Free Meta-Training at Scale
- What: Remove outer-loop supervision entirely for hundreds of languages.
- How: Advance Reptile-like or novel first-order methods tailored to SSL-only inner/outer loops; self-supervised validation signals.
- Assumptions/Dependencies: Reliable unsupervised meta-objectives; stronger stability guarantees; diverse language coverage.
- Continual, On-Device Learning with Active Forgetting
- What: Lifelong adaptation to user speech while preventing catastrophic forgetting.
- How: Expand active forgetting mechanisms; devise safe, incremental updates; privacy-preserving on-device training.
- Assumptions/Dependencies: Edge hardware capability, battery constraints, robust rollback/monitoring.
- Security/Biometrics: Robust multilingual speaker verification
- What: Few-shot adaptation of speaker recognition systems across languages/dialects.
- How: Use adapted embeddings to stabilize voice biometrics; handle cross-language variability.
- Assumptions/Dependencies: Fairness and anti-spoofing safeguards; regulatory acceptance.
- Education (L2 Learning): Cross-lingual phonotactic guidance
- What: Tools that account for learners’ L1 phonotactics to tailor L2 feedback.
- How: Adapt representations to learners’ L1/L2 mix; generate targeted exercises.
- Assumptions/Dependencies: Pedagogical validation; integrations with learning platforms.
- Multimodal Assistants: Cross-modal meta-adaptation
- What: Unified models that adapt across speech, text, and vision for assistants in new cultural contexts.
- How: Extend MAdaPT to multimodal backbones; coordinate cross-loop objectives.
- Assumptions/Dependencies: Multimodal datasets, robust interleaving schedules, new evaluation suites.
- Disaster Response and Field Robotics: Voice teleoperation in emergent languages
- What: Rapidly deploy voice interfaces in regions with scarce labeled data.
- How: Few-shot adaptation from ambient team communications; robust noise handling.
- Assumptions/Dependencies: Harsh acoustic conditions; safety-critical performance; mobile/edge deployment.
- Public Policy: Ethical, consent-based unlabeled audio programs for digital inclusion
- What: National frameworks to collect minimal unlabeled speech to expand language access in public services.
- How: Establish consent protocols, privacy-preserving pipelines, and open benchmarks (ABX/PNMI).
- Assumptions/Dependencies: Legal frameworks, community trust, transparency in model use and evaluation.
- Tooling and Standards: “Language Expansion Kits” and ABX-as-a-Service
- What: Productized toolchains that automate data intake, adaptation, ABX evaluation, and deployment checks.
- How: Build standardized workflows over SpidR-Adapt; host ABX dashboards and quality gates.
- Assumptions/Dependencies: Mature MLOps integration; maintainability; community/industry buy-in.
Collections
Sign up for free to add this paper to one or more collections.