- The paper introduces a unified compiler that uses an e-graph-based equality saturation engine to optimize layout, distribution, and scheduling for LLM deployment.
- The paper demonstrates competitive performance improvements on both single-core and multi-core benchmarks by minimizing memory and compute time.
- The paper presents innovative techniques such as auto vectorization and SBP abstraction, reducing manual intervention while achieving near hand-optimized efficiency.
Authoritative Analysis of "nncase: An End-to-End Compiler for Efficient LLM Deployment on Heterogeneous Storage Architectures" (2512.21571)
Motivation and Architectural Challenges
LLMs with scale exceeding billions to trillions of parameters pose considerable challenges with respect to computational throughput and memory subsystem heterogeneity. Deployment environments range from distributed accelerators, each with complex memory and compute hierarchies, to single-node commodity hardware with deep, multi-level caches and varying vector and tensor processing units. The primary bottleneck is the "memory wall," where memory bandwidth increases lag behind exponential growth in compute capacity, making intra- and inter-hierarchy data movement the critical factor for performance. Contemporary compilers tend to be tailored for specific uniform or non-uniform memory architectures, requiring distinct optimization stacks and incurring substantial adaptation costs. nncase addresses these generalization and optimization limitations by proposing a unified, end-to-end compiler that abstracts all targets into the NUMA model and leverages an e-graph-based equality saturation engine for global, multi-objective optimization.
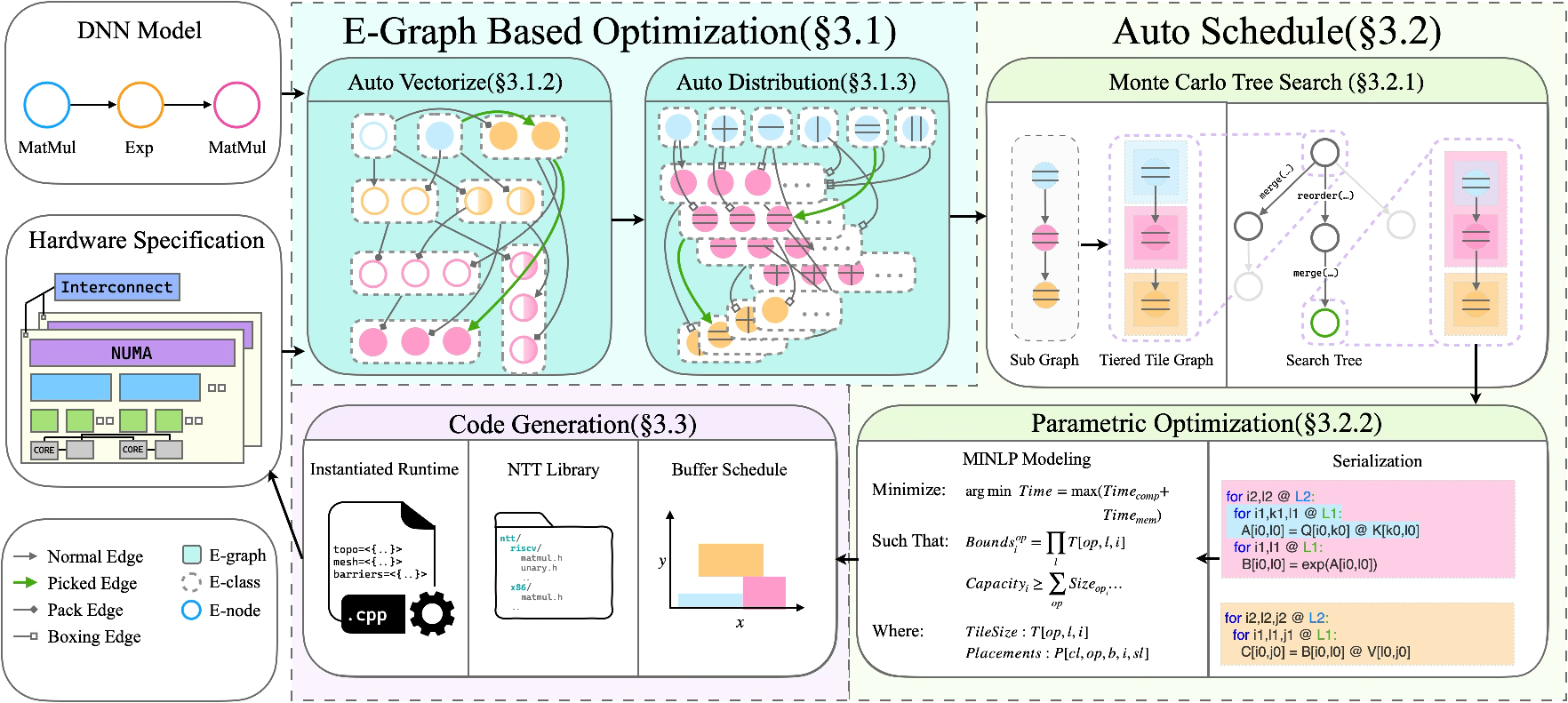
Figure 1: Overview of nncase's modular architecture enabling unified optimization across diverse memory and compute hierarchies.
E-Graph-Based Rewriting and Unified Optimization Paradigm
Traditional deep learning compiler strategies—kernel-level (local) and graph-level (global) layout optimizations—fail to exploit layout reuse or navigate fine-grained vector-tensor trade-offs. The greedy nature of term rewriting leads to irrevocable transformation sequences and potentially suboptimal execution. nncase adopts equality saturation within an e-graph intermediate representation, concurrently applying all applicable rewrite patterns and retaining multiple semantically equivalent graph versions. This enables comprehensive trade-off exploration between compute efficiency and layout transformation cost, which is resolved via an integrated Roofline-based cost model and SAT-based extraction for the optimal path.
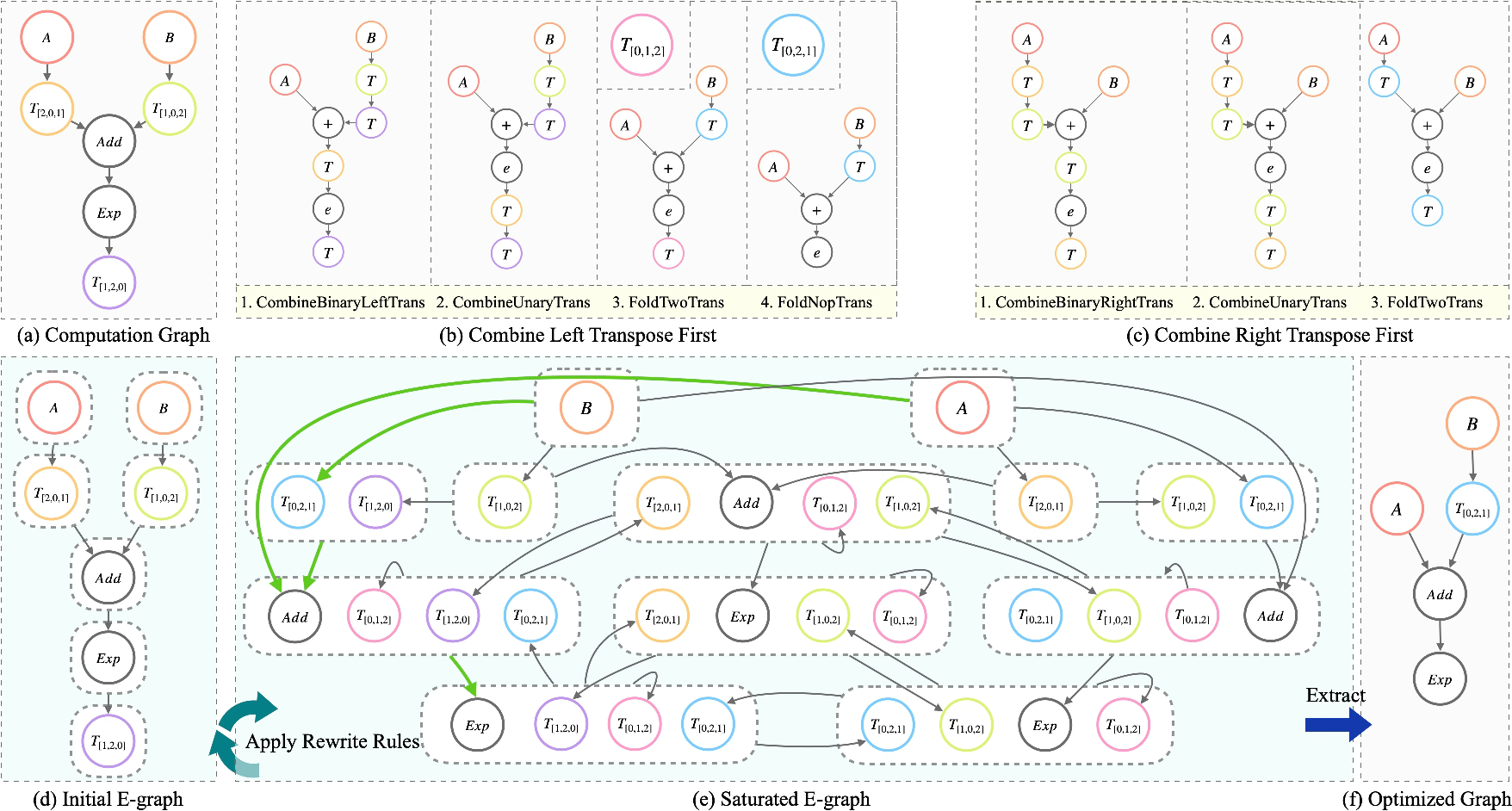
Figure 2: Direct comparison between traditional greedy term rewriting and e-graph-based equality saturation, highlighting avoidance of phase ordering pitfalls.
Auto Vectorize for Heterogeneous Compute Adaptation
Modern processors feature mixed scalar, SIMD, and matrix units with conflicting layout requirements. Auto Vectorize generates multiple hardware-specific packed variants in the e-graph, dynamically tuning packing factors and fusing out redundant Pack/Unpack operations. Attentional subgraphs exemplify this: optimal flows retain block layouts end-to-end across MatMul and element-wise ops, minimizing memory restoration costs.
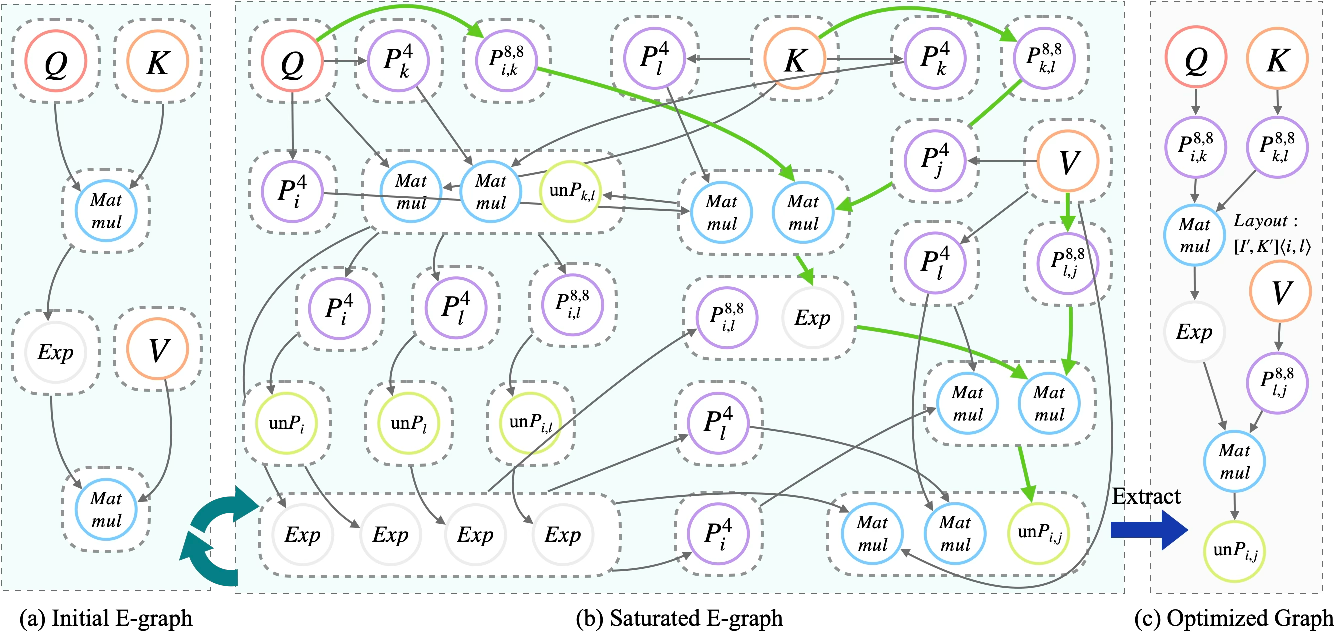
Figure 3: Auto Vectorize seamlessly adapts attention-like subgraphs to block and vector layouts, removing unnecessary layout conversions.
Auto Distribution via SBP Abstraction
Distributed strategy search—mapping tensors and ops across nodes—must balance communication and compute cost, strictly constrained by memory limits. Manual annotation and hierarchical search frameworks often settle for local minima and require tedious intervention. nncase natively models strategies using the SBP (Split, Broadcast, Partial-value) abstraction, expressing all valid sharding permutations within the e-graph. Extraction incorporates both objective minimization and hard memory constraints, guaranteeing feasible solutions.
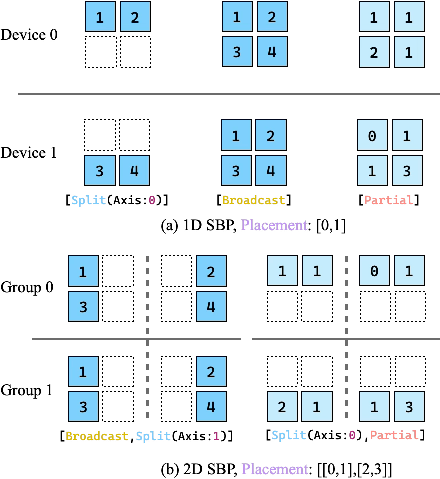
Figure 4: SBP abstraction and placement mechanisms for tensor distribution, enabling topology-agnostic equivalence in the e-graph.
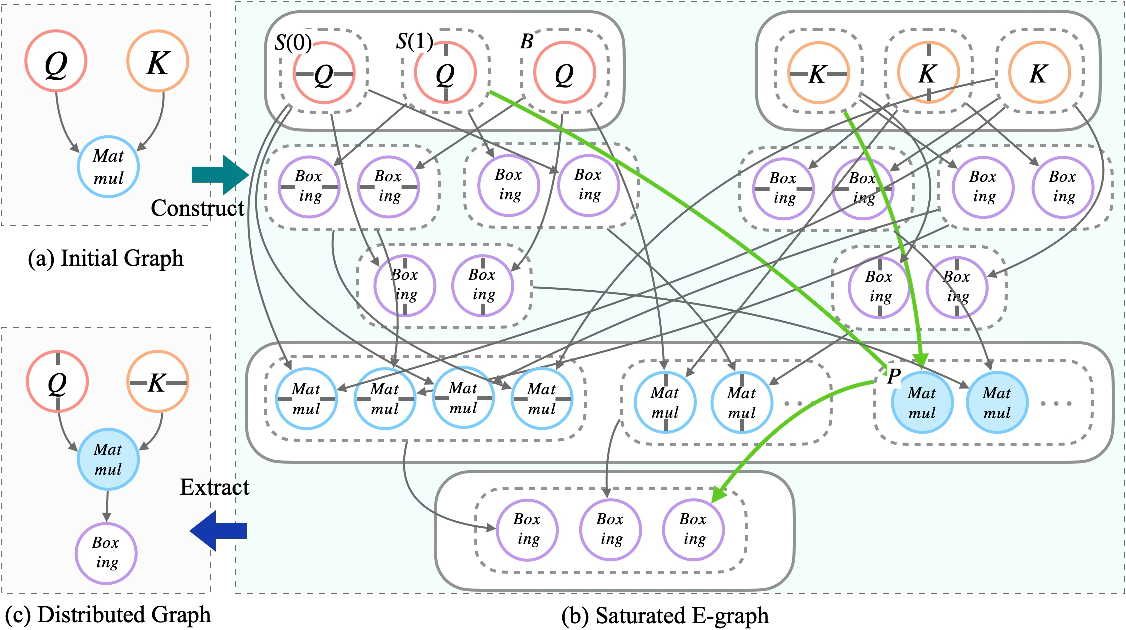
Figure 5: Visualization of the e-graph structure for distributed search space expansion and optimal extraction.
Hierarchical Auto Schedule: MCTS and MINLP Synergy
Kernel scheduling is dissected into structural (loop ordering, fusion) and parametric (tile size, buffer location) spaces. Tiered tile graphs encode deep memory hierarchy and operator fusion relationships, with MCTS driving exploration of loop and fusion configurations. For each structural candidate, a Mixed-Integer Nonlinear Programming solver addresses tile sizing and buffer placement under multi-level, cache-capacity constraints. The objective is to minimize the maximum of memory and compute time, leveraging micro-kernel performance prediction and hardware bandwidth characterization.
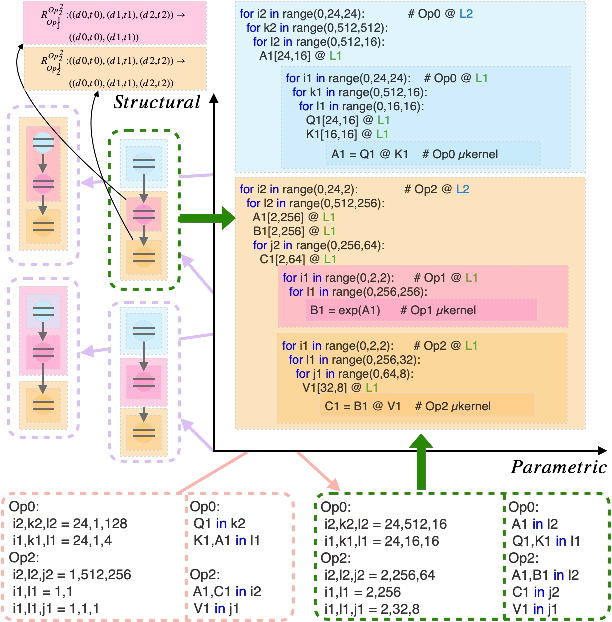
Figure 6: Decomposition of kernel scheduling search space into structural (fusion/order) and parametric (tile size/buffering) dimensions.
Hardware-Aware Code Generation and NTT
Efficient codegen is ensured via logical-to-physical bufferization with zero-copy alias analysis for view ops and bin-packing for optimal memory allocation. Kernel templates exploit the nncase Tensor Template Library (NTT), which provides register-optimized, architecture-specific \textmu kernels and supports both static and dynamic shape inference. For distributed scenarios, the extended NTTD enables mesh topology encoding and static sharding strategies, circumventing runtime policy dispatch.

Figure 7: Sample generated C++ employing NTT library primitives, utilizing static and dynamic tensor shape inference.
Empirical Validation Across Qwen3 Model Family
Benchmarks on AMD Ryzen 9 5900X (12-core, 128GB DDR4) with Qwen3-0.6B/-1.7B in F32/F16 precision assert:
- Single-Core: nncase achieves 8.7 tokens/s on Qwen3-0.6B (F32) vs. 10.61 for hand-optimized llama.cpp and 7.58 for IPEX; in F16, nncase reaches 13.87 tokens/s, trailing llama.cpp by ~19%, but outperforming IPEX by 36%. On Qwen3-1.7B, nncase maintains a 21% lead on IPEX despite a 19% lower rate than llama.cpp.
- Multi-Core (4T/8T): nncase scales to 23.5 tokens/s (Qwen3-0.6B-F16, 4T), surpassing llama.cpp and leading by over 50% against IPEX. Scaling advantage is further pronounced on Qwen3-1.7B—nncase (8.85 tokens/s) overtakes both llama.cpp and IPEX due to static partitioning and minimized runtime scheduling overhead.
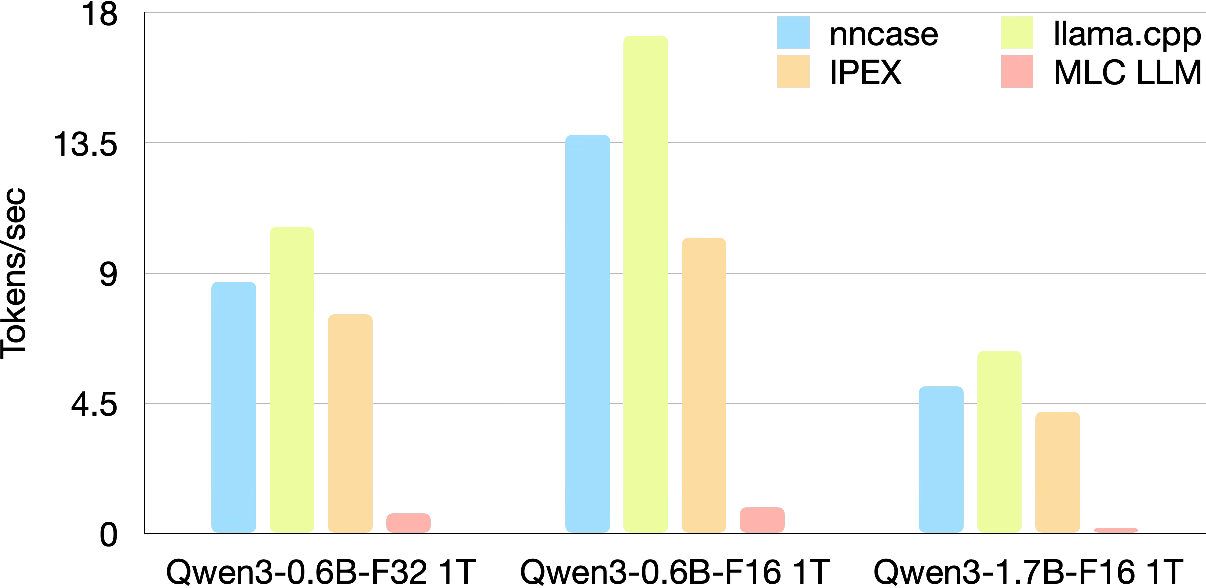
Figure 8: LLM decoding throughput comparison (single core, 1T) among nncase, llama.cpp, IPEX, and MLC LLM.
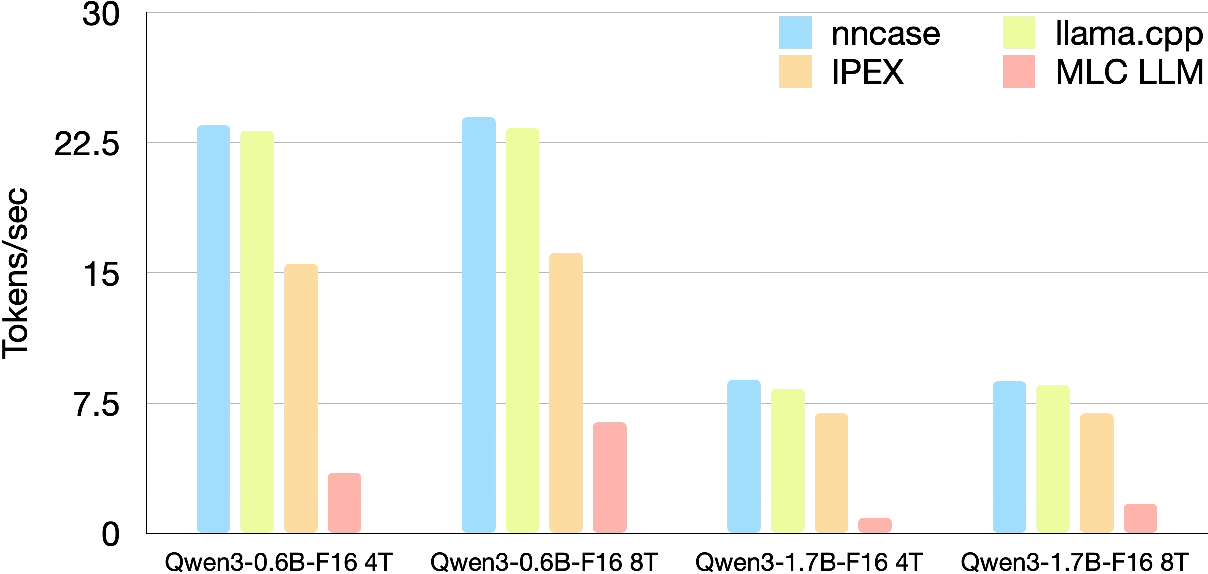
Figure 9: Multi-core scaling throughput, highlighting nncase's static scheduling superiority.
Theoretical and Practical Implications
The unification of layout, distribution, and scheduling optimization in a single e-graph-based engine, with integrated cost modeling and constraint satisfaction, enables near-optimal deployment across CPUs and distributed environments without manual intervention. The "compile once, adapt everywhere" principle supports seamless migration to new hardware targets. The framework’s buffer-aware codegen and microkernel templates guarantee register-level performance, previously achievable only through manual engineering. nncase's distributed paradigm is shown to outperform traditional OpenMP/threading models on multi-core CPUs by leveraging static task partitioning over logical nodes.
Anticipated future directions, given the framework's modularity, include backend extension for SIMT architectures (GPUs), more advanced computation-communication overlap pipelining, and large-scale compilation overhead characterization. The design opens the path toward pushing distributed systems methodologies into single-node deployment, with broader implications for on-chip AI and low-latency inference in edge/topologically heterogeneous environments.
Conclusion
nncase establishes a comprehensive, open-source framework for the compilation and deployment of LLMs on hardware with deeply heterogeneous storage and compute architectures. Through e-graph-based rewrite abstraction, equality saturation, and topology-agnostic distribution and scheduling, the system achieves strict adherence to memory constraints and balanced latency-minimizing execution plans. Empirical results underpin its claim of outperforming existing compilers and matching or exceeding hand-optimized baselines across both single and multi-core configurations. This unified approach is poised to facilitate scalable, high-performance LLM inference for emerging memory and compute landscapes, with extensibility toward massively parallel and multi-node settings.