NEMO-4-PAYPAL: Leveraging NVIDIA's Nemo Framework for empowering PayPal's Commerce Agent
Abstract: We present the development and optimization of PayPal's Commerce Agent, powered by NEMO-4-PAYPAL, a multi-agent system designed to revolutionize agentic commerce on the PayPal platform. Through our strategic partnership with NVIDIA, we leveraged the NeMo Framework for LLM model fine-tuning to enhance agent performance. Specifically, we optimized the Search and Discovery agent by replacing our base model with a fine-tuned Nemotron small LLM (SLM). We conducted comprehensive experiments using the llama3.1-nemotron-nano-8B-v1 architecture, training LoRA-based models through systematic hyperparameter sweeps across learning rates, optimizers (Adam, AdamW), cosine annealing schedules, and LoRA ranks. Our contributions include: (1) the first application of NVIDIA's NeMo Framework to commerce-specific agent optimization, (2) LLM powered fine-tuning strategy for retrieval-focused commerce tasks, (3) demonstration of significant improvements in latency and cost while maintaining agent quality, and (4) a scalable framework for multi-agent system optimization in production e-commerce environments. Our results demonstrate that the fine-tuned Nemotron SLM effectively resolves the key performance issue in the retrieval component, which represents over 50\% of total agent response time, while maintaining or enhancing overall system performance.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explains how PayPal made its shopping assistant faster and cheaper to run by teaming up with NVIDIA. They used NVIDIA’s NeMo tools to fine-tune a smaller AI model so the assistant could understand what shoppers want and search for products more quickly, without hurting the overall quality of its answers.
What were the goals?
Here are the goals in simple terms:
- Make PayPal’s shopping assistant respond much faster, especially during product search.
- Cut computing costs while keeping the assistant’s suggestions helpful and accurate.
- Test a method for tuning smaller AI models to do specific e-commerce tasks well.
- Build a setup that can improve different parts of a multi-agent system (many small AIs working together) in a real, large-scale online shopping environment.
How did they do it?
To keep things clear, think of a giant store and a helpful “digital librarian” who finds the right items when you ask for something. The paper describes how they trained and organized this librarian to work faster and smarter.
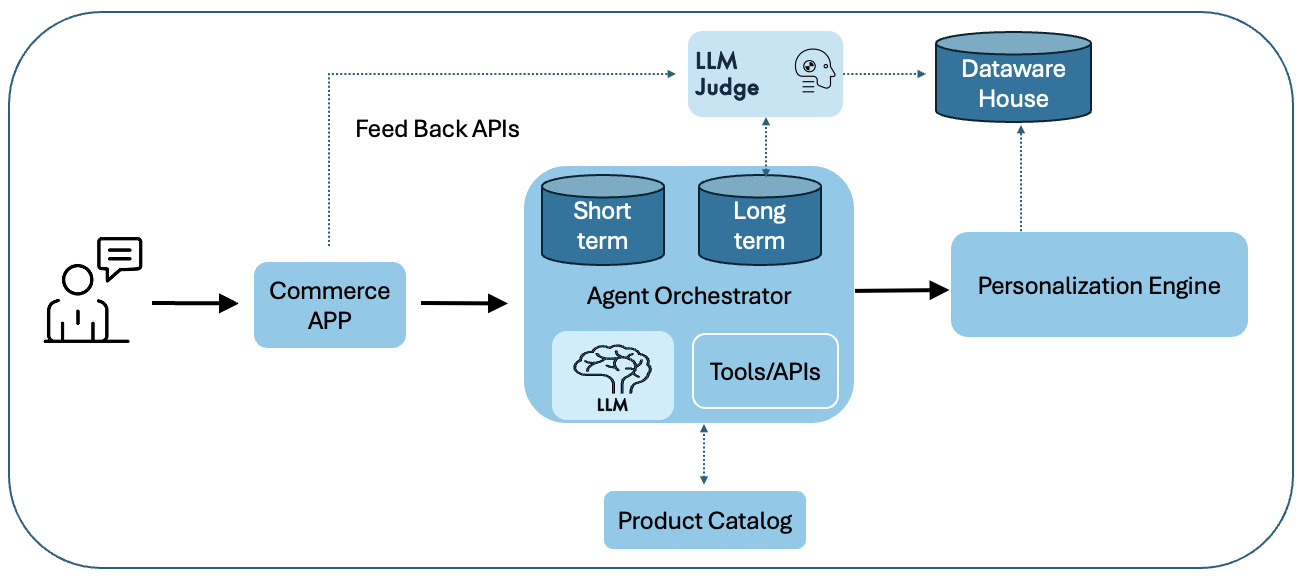
The Commerce Agent (many helpers working together)
PayPal’s assistant is made of several specialized mini-AIs, each with a job:
- One understands your question and turns it into a “search-ready” format.
- One finds matching products (retrieval).
- One orders the results from best to okay (ranking).
- One checks quality and keeps the conversation on track. These mini-AIs are coordinated by an orchestration framework that manages memory, tools, and product data.
Training smaller models to do a focused job
Instead of using a big, general AI model for everything, they trained a Small LLM (SLM) from the Nemotron family (about 8 billion parameters) for the specific task of query understanding and search. They fine-tuned this model using NVIDIA’s NeMo Framework and a method called LoRA, which lets you adapt a model by training a small number of added parameters—like teaching a skilled worker a new specialty without retraining their entire education.
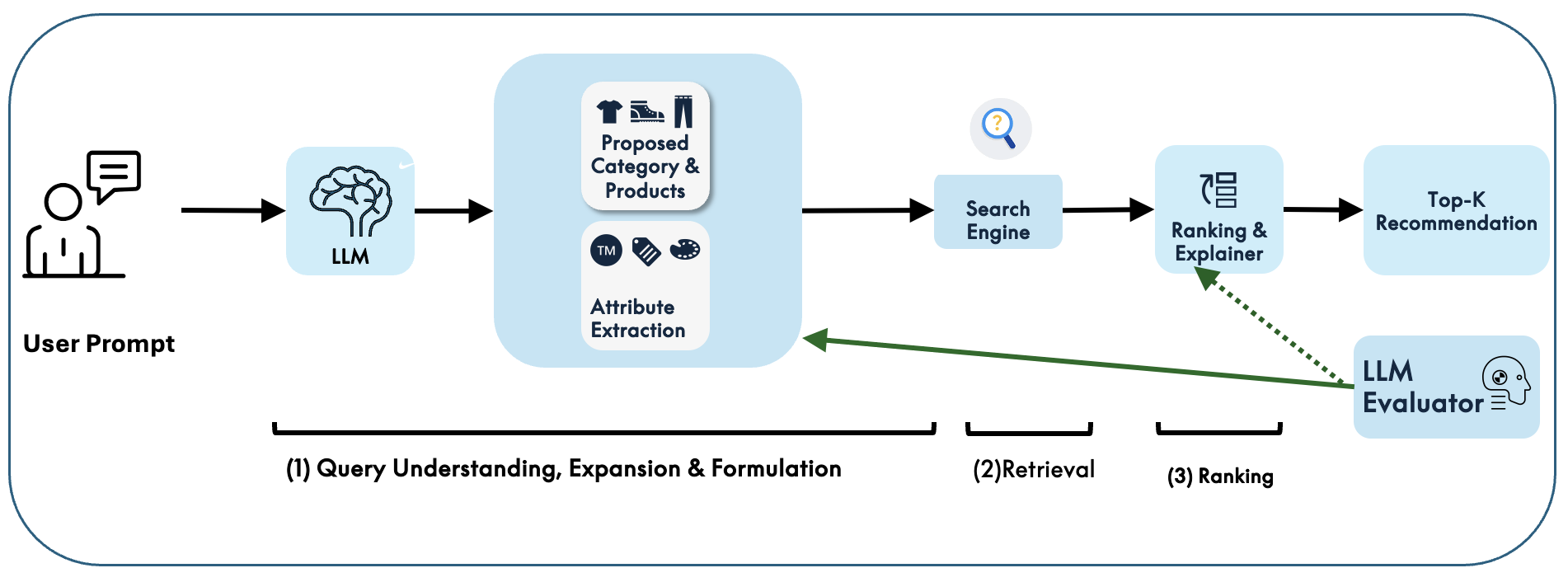
Making search smarter with HyDE
They used a technique called HyDE (Hypothetical Document Embeddings). Imagine you ask, “Suggest tech accessories for skiing.” The model:
- Extracts key details (category, attributes like “heated,” “waterproof,” etc.).
- Writes a short “hypothetical” product description that captures what you really want.
- Uses this to find similar real products in the catalog. It’s like describing your dream item so the search engine can find the closest real matches.
Measuring performance and quality
They ran many experiments, changing training settings (like learning rates and optimizers) to find the best model. To judge quality, they sometimes used another AI to rate the results (LLM-as-a-Judge), comparing pairs of outputs and using a rubric to score them.
They also tried Direct Preference Optimization (DPO), which teaches the model to prefer better answers by showing it pairs: a “chosen” response and a “rejected” one. It’s like learning taste by comparing examples instead of memorizing rigid rules.
Speeding up with GPUs and smart deployment
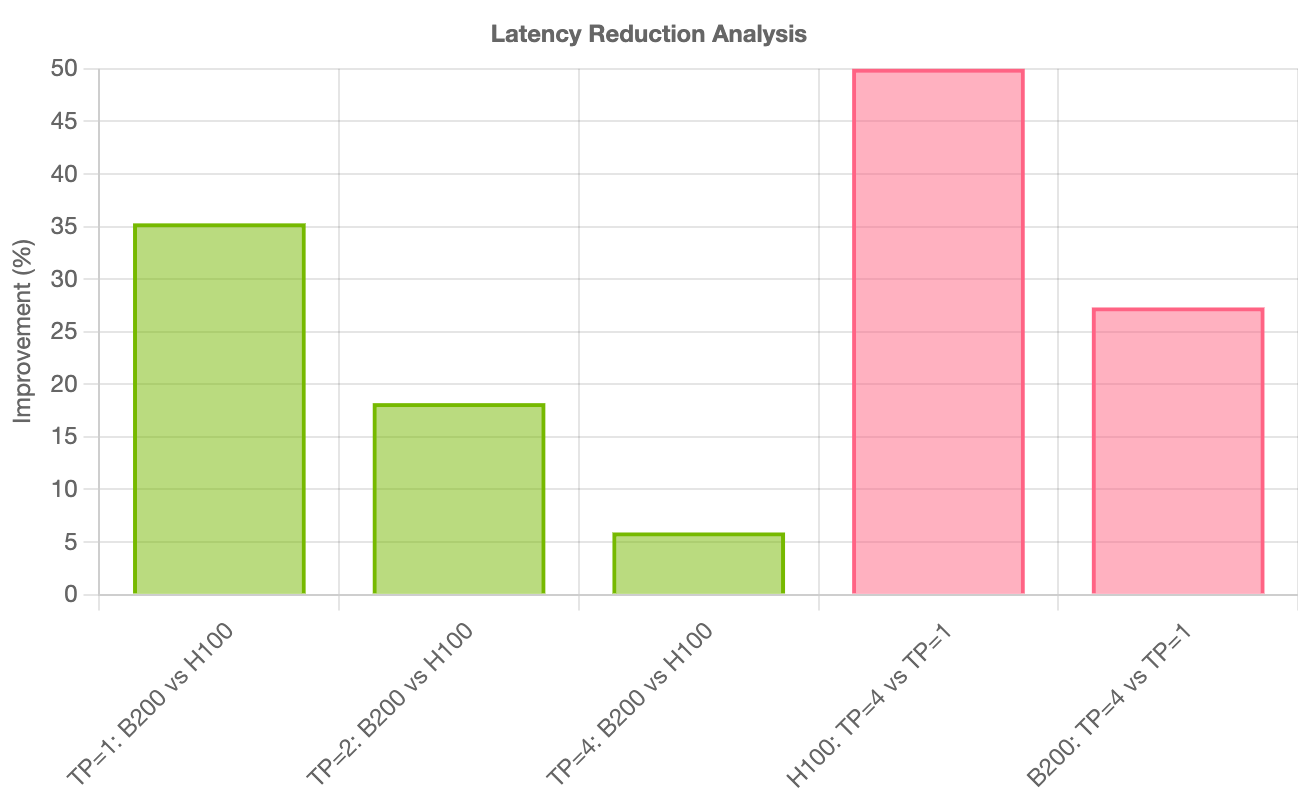
They tested different NVIDIA GPUs (H100 and the newer B200 “Blackwell”) and used parallel processing (splitting work across chips) to cut waiting time (“latency”). They deployed with NVIDIA NIM, which picks the fastest inference engine automatically. This made the system even quicker.
What did they find?
Here are the main results:
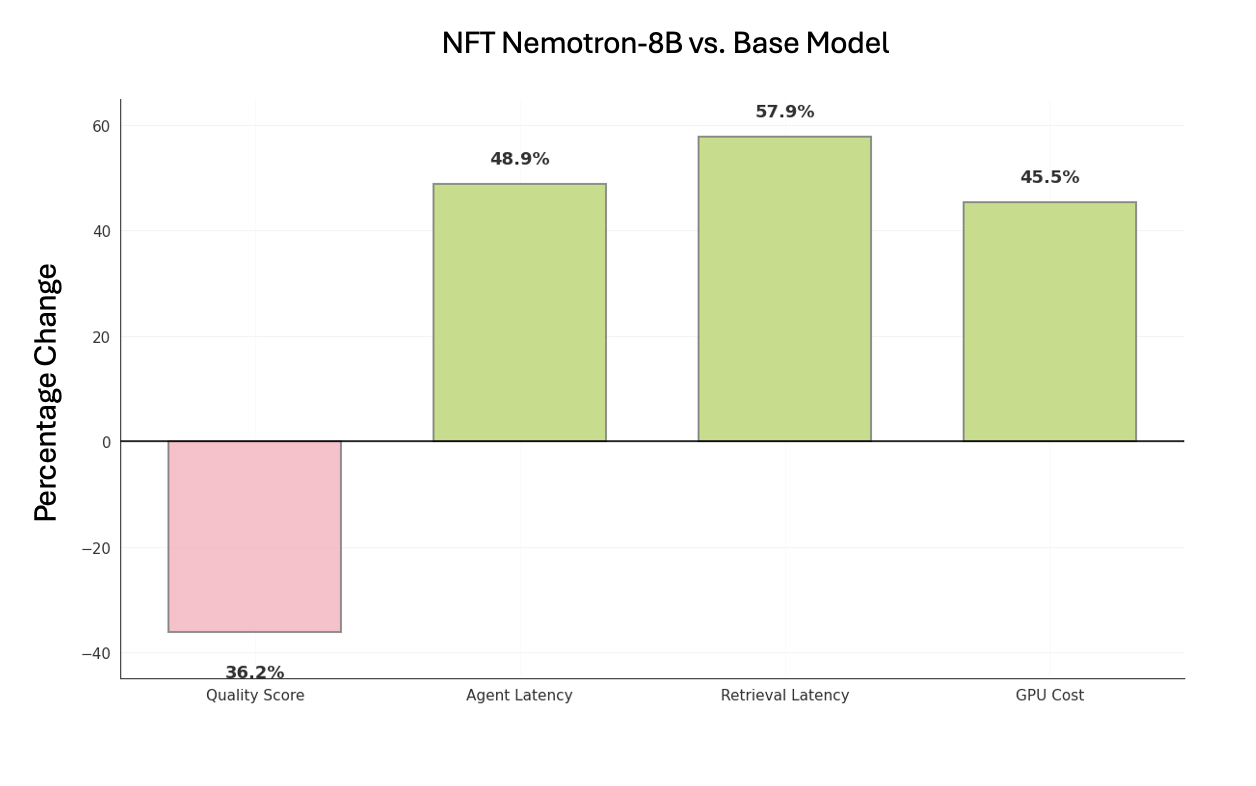
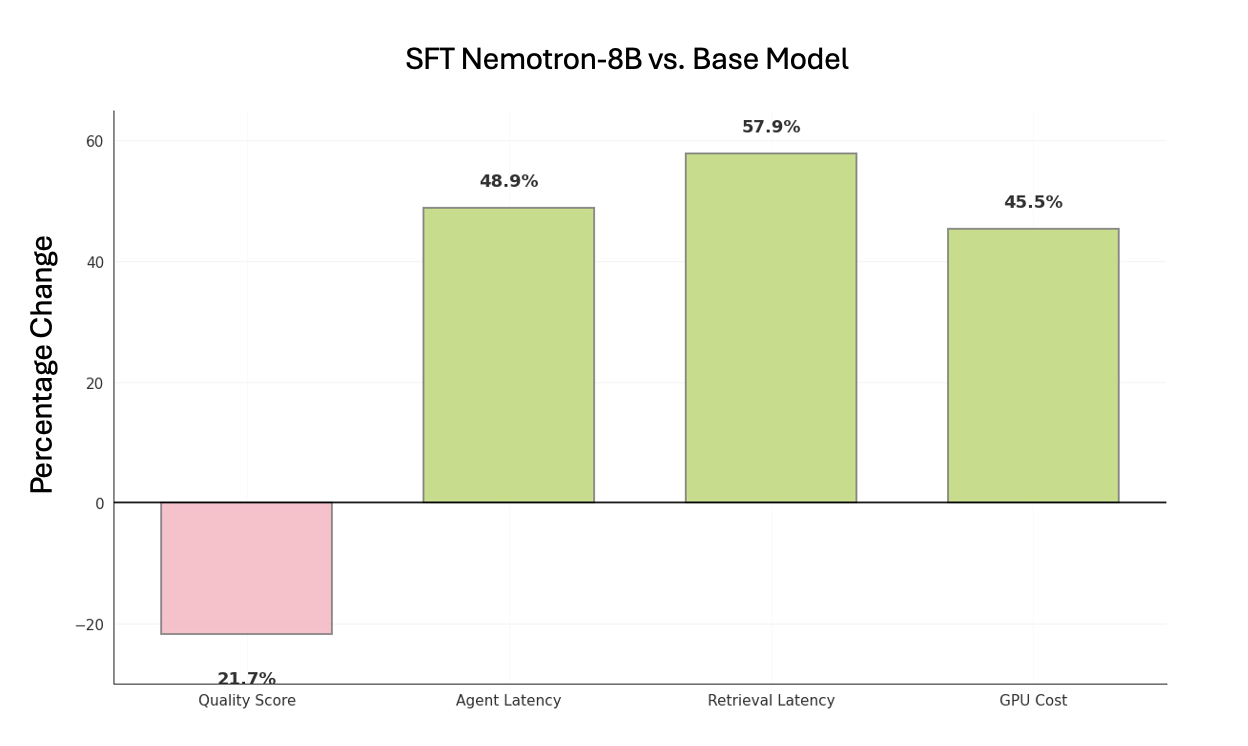
- The fine-tuned Nemotron small model sped up the slowest part: turning a user’s message into a smart search query. That area used to take more than half of the assistant’s total time.
- Overall response time went down by roughly half. Retrieval got faster by about 58%, and the assistant’s total latency dropped by around 49%.
- Monthly GPU costs dropped by about 45%.
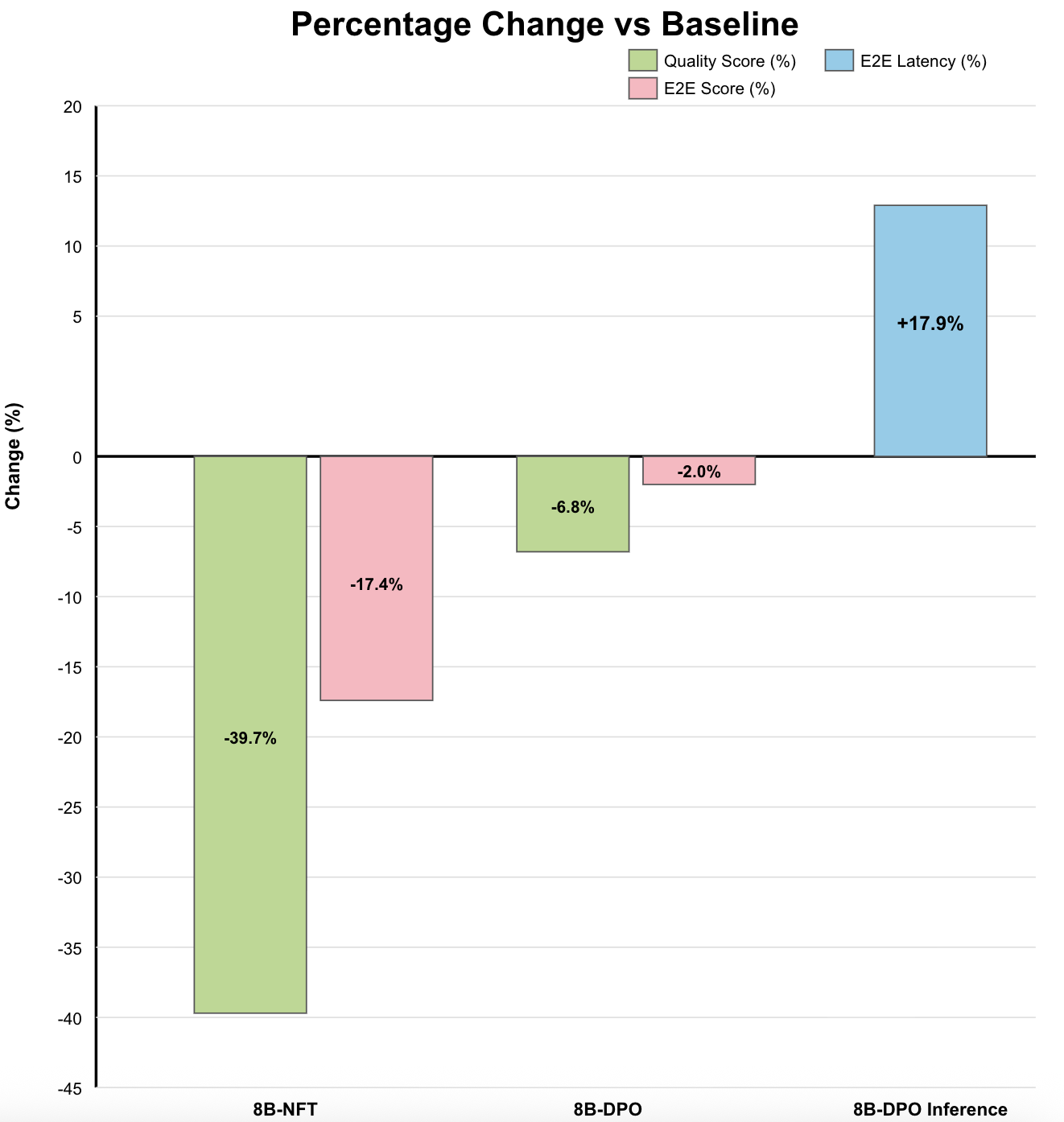
- Quality stayed competitive. In some tests, the fine-tuned model matched or slightly improved the quality compared to the base setup. DPO helped minimize quality drops when pushing for more speed.
- Newer GPUs (B200) and running tasks in parallel gave noticeable extra speed-ups.
In short: the assistant became faster and cheaper, and its recommendations stayed helpful.
Why does it matter?
- Better shopping experience: Faster replies mean smoother conversations and less waiting when you search for products.
- Smarter search: The assistant understands your intent, not just keywords, so it finds products that fit your needs more closely.
- Lower costs at scale: Cutting compute costs makes it easier to offer these benefits to millions of users.
- Practical blueprint: The paper shows a clear, repeatable way to improve specific parts of a large AI system, which other companies can follow.
- Future-ready: Using smaller, fine-tuned models for focused tasks can be more efficient than relying on one giant model for everything.
Takeaway
By fine-tuning a small, focused AI model with NVIDIA’s NeMo tools and smart training methods like LoRA and DPO, PayPal made its commerce assistant much faster and cheaper while keeping its quality strong. This approach is a practical path for building quick, reliable, and personalized shopping experiences at a massive scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be concrete and actionable for future research or engineering work.
- Baseline clarity: The “base model” and baseline retrieval stack are insufficiently described (architecture, parameter count, inference engine, quantization settings, tokenizer, prompt template); provide a fully specified baseline to enable apples-to-apples comparisons.
- Evaluation metrics coverage: The study relies heavily on LLM-as-a-Judge scores; add standard IR metrics (Recall@k, MRR, NDCG@k), grounding accuracy (catalog match rate), and schema adherence rates to quantify retrieval and ranking effectiveness.
- Human and online evaluation: No human-in-the-loop assessments or production A/B experiments are reported; measure business metrics (conversion rate, CTR, add-to-cart, dwell time, bounce rate) and conduct controlled A/B tests to validate offline gains translate into user impact.
- Judge model reliability: The paper does not specify the judge model(s), calibration procedures, or agreement metrics; assess inter-annotator reliability (Krippendorff’s alpha) and cross-judge consistency, and report bias checks for judge models.
- Dataset transparency: The composition of the 10k synthetic + real chat dataset lacks detail (category distribution, language mix, geography, session length, query types, long-tail coverage, label provenance); publish a data card covering sampling, annotation guidelines, and known biases.
- Synthetic data effects: The impact of synthetic data on model behavior and generalization is not analyzed; run controlled ablations on varying synthetic-to-real ratios and measure downstream retrieval/ranking performance, hallucination rates, and domain overfitting.
- Privacy and compliance: Using customer chats to build profiles raises privacy and regulatory concerns; document PII handling, consent, minimization, retention, GDPR/CCPA compliance, DSAR workflows, and any differential privacy or de-identification techniques.
- Personalization cold start: The approach depends on purchase history; develop and evaluate strategies for new users (contextual bandits, demographic priors, session-based signals) and for new products (item cold start).
- Fairness and inclusivity: Gender-aligned recommendations are enforced without evaluation of fairness or inclusivity; assess performance across genders, non-binary users, regions, and merchants, and measure stereotype amplification and disparate impact.
- Safety/guardrail robustness: Safety policies are described but not stress-tested; evaluate against prompt injection, jailbreaks, adversarial queries, illegal or harmful item requests, and measure guardrail precision/recall and false positives.
- Retrieval method ablation: HyDE is adopted without comparative baselines; compare HyDE against BM25, static/dynamic query expansion, dual-encoder dense retrieval (e.g., E5, Contriever), hybrid sparse+dense, and multi-vector encoders; report IR metrics per method.
- Embedding and index details: The embedding models, vector store type, ANN algorithm (e.g., HNSW, IVF-PQ), and index parameters are unspecified; detail and ablate encoder choices, dimensionality, quantization, recall-latency trade-offs, and re-ranking strategies.
- Ranking module evaluation: Ranking is delegated to another LLM with no comparison to classic learning-to-rank (LambdaMART, XGBoost LTR, neural LTR); benchmark accuracy (NDCG@k), calibration, and consistency across queries/catalog segments.
- Pipeline-level ablations: Query understanding, retrieval, and ranking contributions are confounded; isolate and quantify each stage’s effect via ablations (e.g., swapping only query formulation vs. only retrieval vs. only ranking) on both latency and quality.
- Hardware vs. model improvements: Latency gains mix hardware (B200 vs. H100), engine, and fine-tuning effects; decompose contributions via controlled experiments to attribute improvements to model fine-tuning versus inference stack versus GPU architecture.
- Load and tail latency: Only average latencies are discussed; report p90/p95/p99 latencies, throughput (req/s), concurrency scaling, queueing effects, and backpressure behavior under production-like load.
- Quantization and memory: Inference quantization settings (INT8/FP8/FP16), KV cache strategies, and memory footprints are unreported; evaluate quantization impacts on latency, cost, and quality, including stability across diverse query lengths.
- Guided JSON reliability: Guided JSON is mentioned without error metrics; measure schema adherence, parse failure rates, recovery strategies, and downstream impacts on tool calls and retrieval consistency.
- Hallucination grounding: HyDE may hallucinate product attributes; quantify hallucination rates, catalog grounding accuracy (SKU match, attribute correctness), and the effectiveness of filters to suppress non-existent products or brands.
- Catalog dynamism: No evaluation of model robustness to inventory changes, out-of-stock items, or rapid catalog drift; build tests for freshness handling, reindexing schedules, and stale recommendation suppression.
- Multi-lingual and regional support: Global PayPal use is implied but language coverage (non-English), locale formatting (currency, units), and regional regulatory constraints are not addressed; evaluate multilingual performance and localization.
- Tool success and orchestration: The agent’s tool invocation reliability, error handling, recovery policies, and orchestration metrics (tool success rate, plan execution success, loop detection) are not reported; instrument and evaluate these systematically.
- DPO methodology detail: Preference data sources (human vs. model-generated), rubric, sampling, and label quality are unclear; expand DPO dataset, report hyperparameters, training stability, and compare SFT vs. DPO on identical setups and metrics.
- Reproducibility: Training seeds, durations, compute budgets, LoRA ranks, learning rates, schedulers, parameter counts, and prompt templates are not fully specified; provide a reproducibility appendix or artifacts (configs, logs, ablation results).
- Business cost modeling: “45% monthly GPU cost reduction” lacks context (traffic volume, concurrency, instance pricing, autoscaling policies); report cost-per-query, cost-per-session, and sensitivity analyses under varying traffic profiles.
- Energy and sustainability: Energy use and carbon footprint are not measured; estimate energy per 1k queries and evaluate sustainability improvements alongside cost and latency.
- User experience outcomes: The trade-off between modest quality drops and latency gains is not tied to UX thresholds; study how latency vs. quality trade-offs affect user satisfaction and business KPIs.
- Error analysis: The paper lacks qualitative error categorization; perform error analyses on failed/rejected cases (attribute extraction errors, mis-gendering, off-target categories, irrelevant products) to guide targeted fixes.
- Security and compliance for deployment: NIM microservices and LangChain orchestration introduce supply chain and container risks; document CVE scanning, SBOM, isolation, secrets management, and runtime policy enforcement.
- Continuous learning and monitoring: There is no described pipeline for drift detection, automated retraining triggers, rollback criteria, or gating tests; design and report a continuous evaluation/governance framework for safe iteration.
- Generalization across scenarios: Performance is not stratified by category, seasonality, event-type queries (e.g., holidays, travel), or long-tail intents; add stratified benchmarks and stress tests across diverse commerce scenarios.
- Clarity of reported results: Several captions state “latency up 57.9%” while implying improvement; standardize sign conventions and report absolute values, confidence intervals, and statistical significance to avoid ambiguity.
Practical Applications
Immediate Applications
Below is a concise set of deployable applications that can be implemented now using the paper’s methods and findings.
- Latency-optimized query formulation for e-commerce search and recommendation
- Sector: Retail/e-commerce, Software
- Tools: Fine-tuned Nemotron SLM (llama3.1-nemotron-nano-8B-v1) via NeMo SDK; HyDE-based retrieval; LangChain orchestration; JSON-guided outputs; NVIDIA NIM for inference
- Dependencies: High-quality catalog metadata and embeddings; reliable vector search; consented user profiles; GPU access (H100/B200); production-grade orchestration
- Cost reduction in LLM-powered commerce agents through SLM replacement
- Sector: Retail/e-commerce, Finance (FinOps), Software
- Tools: PEFT (LoRA/QLoRA) fine-tuning with NeMo; sharded checkpoints; 3D parallelism; NIM engine selection
- Dependencies: Comparable quality to baseline LLMs; robust evaluation pipeline; workload profiling to validate -45% GPU cost claims
- GPU capacity planning and inference tuning
- Sector: Software/ML Ops, Energy/Green AI
- Tools: NIM microservices with TensorRT-LLM/vLLM/SGLang; TP sweeps (TP=1..4); hardware benchmarking (H100 vs B200)
- Dependencies: Access to Blackwell (B200) or H100; latency/throughput targets; budget constraints; driver/runtime compatibility
- Production-grade multi-agent commerce orchestration
- Sector: Retail/e-commerce, Software
- Tools: LangChain-based Generic Agent Orchestrator; Conversation Planning; Task Planner; Agent Tools (search, ranking, cart); Unified Session Management
- Dependencies: Stable domain APIs (catalog, pricing, inventory, cart); session persistence; LLM Evaluator integration; guardrails for safety
- Personalized top‑K recommendations grounded in user profiles
- Sector: Retail/e-commerce, Marketing
- Tools: Offline user profile generation from purchase history; fine-tuned LLM ranking; HyDE retrieval grounding
- Dependencies: Privacy-compliant data pipelines (consent, regional regulations); profile freshness; bias/fairness checks (e.g., gender alignment rules)
- Synthetic data generation and preference-pair pipelines (SFT/DPO)
- Sector: Software/ML, Academia (applied ML)
- Tools: Synthetic prompt–response generation; DPO preference datasets; LLM-as-a-Judge rubric evaluation
- Dependencies: Quality controls for synthetic data; judge reliability; domain-specific rubrics; reproducible evaluation
- Schema-bound JSON generation for downstream integration
- Sector: Software, Retail/e-commerce
- Tools: Guided JSON outputs for category, attribute, product lists; validation and post-processing services
- Dependencies: Strict schema definitions; error handling; catalog alignment and normalization
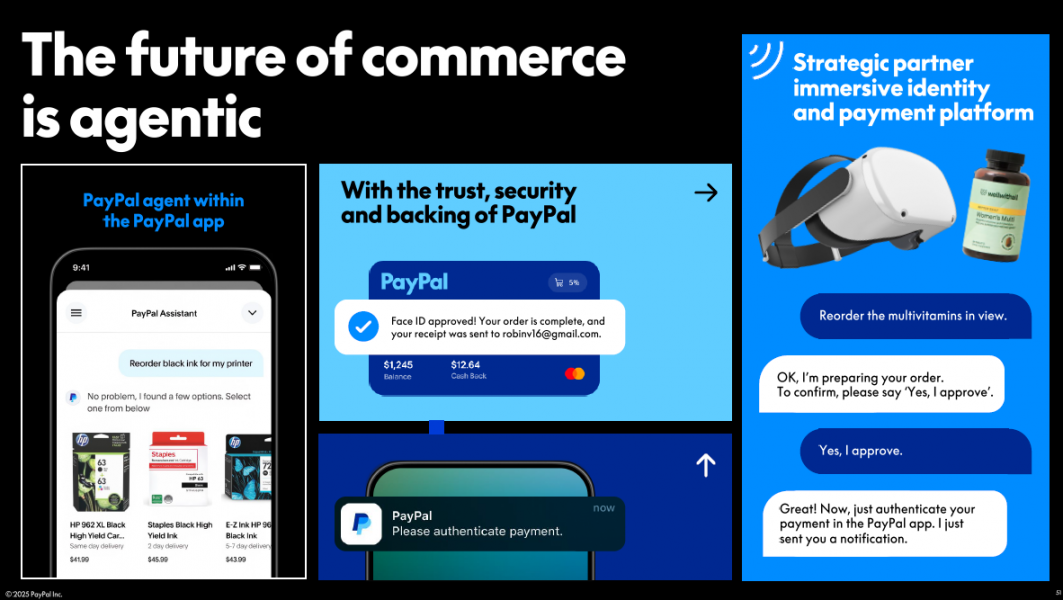
- Conversational shopping assistance for web/mobile
- Sector: Retail/e-commerce, Daily life
- Tools: Commerce Agent front ends; multi-turn dialogue planning; memory framework; personalization engine
- Dependencies: UX instrumentation; fallback flows; safety prompts (avoid illegal/weapons/explicit content); robust connection to inventory
- Continuous agent monitoring with LLM-as-a-Judge
- Sector: Software/ML Ops, Retail/e-commerce
- Tools: Pairwise and rubric-based evaluation; end-to-end scoring (query formulation, attribute extraction, recommendation)
- Dependencies: Calibrated rubrics; periodic human validation; drift detection; CI/CD integration
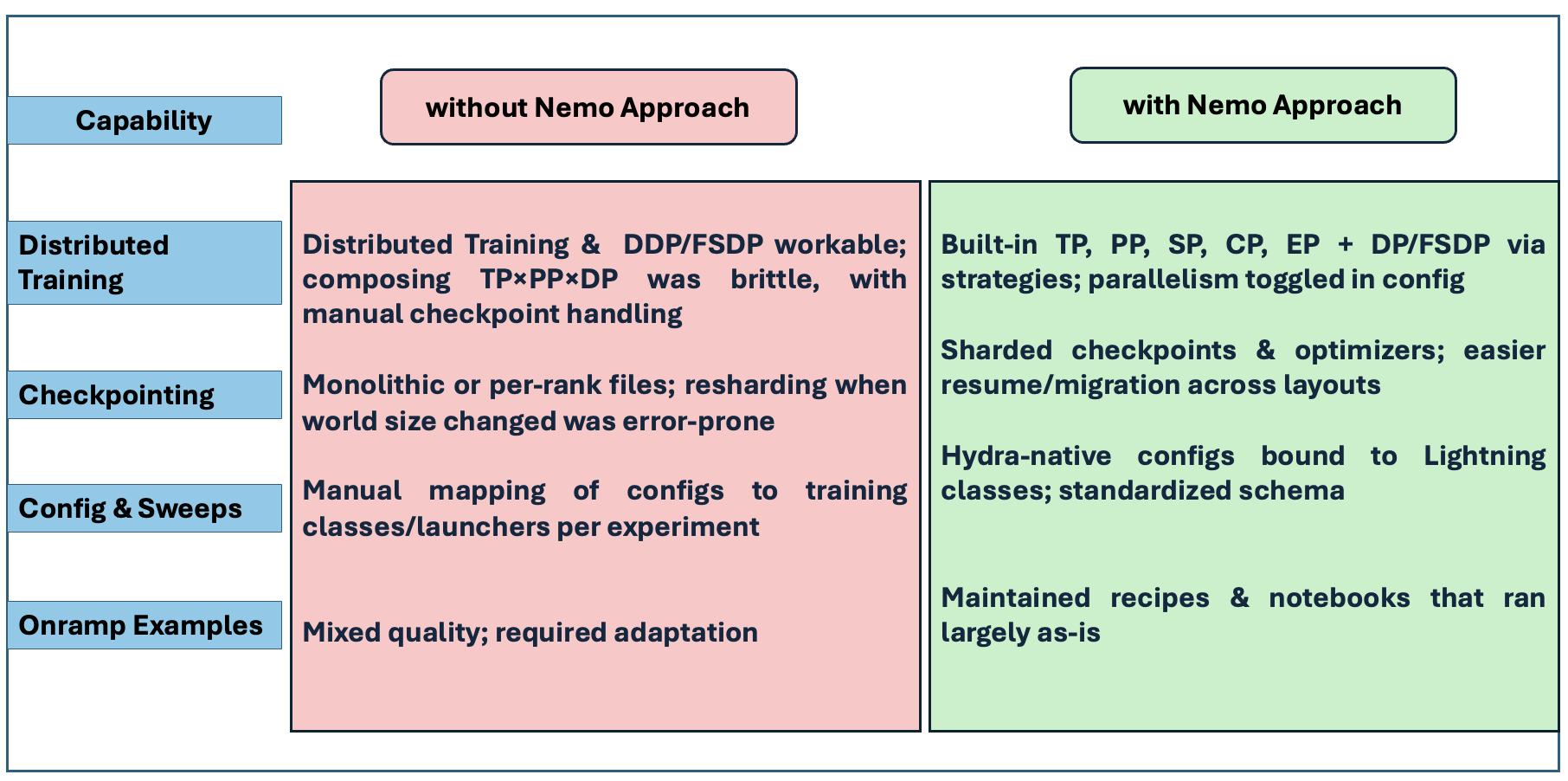
- Enterprise dev productivity boost via NeMo training recipes
- Sector: Software/ML, Enterprise IT
- Tools: Hydra-first config management; PEFT recipes; distributed optimizers; checkpoint portability
- Dependencies: Team skills on NeMo; GPU cluster availability; experiment tracking (e.g., MLflow/W&B)
Long-Term Applications
The following applications require further research, scaling, or development before broad deployment.
- Autonomous agentic commerce with sub‑2s end‑to‑end performance at global scale
- Sector: Retail/e-commerce
- Tools: Fully optimized multi-agent workflows; dynamic model selection; global session/state management; caching strategies
- Dependencies: Robust cross-region infrastructure; multi-tenant scaling; advanced observability; SLAs
- Cross-domain adaptation of retrieval‑optimized SLMs
- Sector: Healthcare, Education, Finance, Enterprise Knowledge Management
- Tools: Domain-specific SFT/DPO pipelines; HyDE-style structured retrieval over regulated corpora (e.g., formularies, curricula, product specs)
- Dependencies: Domain data access and compliance (HIPAA, FERPA, financial regulations); ontology/taxonomy alignment; subject-matter expert evaluation
- Privacy-preserving personalization (federated and on-device learning)
- Sector: Retail/e-commerce, Policy/Regulatory, Software
- Tools: Federated fine-tuning; differential privacy; secure enclaves; consent management
- Dependencies: Legal frameworks; device heterogeneity; robust privacy guarantees; auditability
- Multimodal agentic commerce (text + vision + speech)
- Sector: Retail/e-commerce, Assistive technologies
- Tools: Vision models for image-based search; speech ASR/TTS; multimodal NeMo workflows
- Dependencies: Image metadata quality; multilingual speech support; real-time inference scaling; UX design for multimodal interactions
- Adaptive inference planners for energy-aware cost/latency optimization
- Sector: Energy/Green AI, Software/ML Ops
- Tools: Automatic engine/hardware selection based on traffic and cost; smart TP/PP/DP orchestration; carbon-aware scheduling
- Dependencies: Accurate telemetry; policy constraints; fleet diversity; dynamic workload prediction
- Standardized evaluation and governance frameworks for agentic commerce
- Sector: Policy/Regulatory, Industry consortia, Academia
- Tools: Open benchmarks (latency, cost, quality, fairness, safety); red-team protocols; explainability metrics; audit trails
- Dependencies: Stakeholder alignment (platforms, regulators, researchers); shared datasets; continuous updates to standards
- Negotiation and post‑purchase autonomous support agents
- Sector: Retail/e-commerce, Finance (offers, refunds), Customer service
- Tools: Multi-step reasoning and constraints; integration with returns/exchange, dispute resolution, dynamic pricing
- Dependencies: Clear business policies; risk controls; human-in-the-loop escalation; compliance with consumer protection laws
- Merchant/partner onboarding assistants with catalog normalization
- Sector: Retail/e-commerce, B2B marketplaces
- Tools: LLM-driven attribute extraction, taxonomy mapping, deduplication; quality scoring
- Dependencies: Merchant data variation; taxonomy governance; conflict resolution; bulk processing at scale
- Robust safety, bias, and fairness systems for personalized commerce
- Sector: Policy/Regulatory, Retail/e-commerce
- Tools: Guardrailing APIs; bias audits (e.g., gender alignment logic in the paper); content filters; fairness-adjusted ranking
- Dependencies: Transparent criteria; legal compliance; periodic audits; diverse evaluation cohorts
- Cross-merchant knowledge graphs and session-level reasoning
- Sector: Retail/e-commerce, AdTech/MarTech
- Tools: Unified product graph; persistent memory across sessions; intent evolution tracking; cross-sell/upsell reasoning
- Dependencies: Data-sharing agreements; identity resolution; privacy controls; graph maintenance at scale
- Academic research programs on agentic planning and retrieval
- Sector: Academia
- Tools: Public variants of SFT/DPO workflows; ablation studies of PEFT ranks, schedulers, optimizers; LLM-as-a-Judge reliability research
- Dependencies: Accessible datasets; ethical review; reproducibility infrastructure; funding and compute access
- Integrated commerce + payments agents (PayPal-native)
- Sector: Finance, Retail/e-commerce
- Tools: End-to-end flows from discovery → cart → checkout → financing options; risk signals; offer recommendation
- Dependencies: Secure payments integration; fraud detection alignment; regulatory compliance (KYC/AML); latency budgets
Notes on Key Assumptions and Dependencies Across Applications
- Data and privacy: Applications rely on consented, compliant use of user profiles and purchase histories; privacy-preserving techniques become critical as personalization deepens.
- Catalog/embedding quality: Effective retrieval (especially HyDE) depends on accurate product embeddings, up-to-date inventory, and clean attribute taxonomies.
- Evaluation reliability: LLM-as-a-Judge should be supplemented with human audits to mitigate rubric bias and ensure real-world quality.
- Hardware/runtime: Performance gains (e.g., B200 > H100) assume access to newer GPU architectures and compatible inference stacks (NIM/TensorRT-LLM/vLLM).
- Trade-offs: The paper shows immediate latency/cost improvements may reduce some quality metrics; DPO helps but requires careful tuning and domain-specific evaluation.
- Safety/fairness: Guardrails must be maintained and extended (e.g., gender alignment rules, illegal content avoidance) as the agent scales to new domains and modalities.
Glossary
- 3D parallelism: A training approach that combines tensor, pipeline, and data parallelism to scale model training across devices. "3D parallelism (TP/PP/DP) with sequence and context parallelism maintained stable, composable training;"
- Agent Memory Framework: A component that maintains conversation context and user state across sessions for an agent. "the Agent Memory Framework to maintain conversation context and user state across sessions,"
- Agent Orchestration Framework: An infrastructure layer that coordinates multiple agents and tools to execute complex workflows. "Agentic Commerce AI system: (1) Commerce Platform (2) Agent Orchestration Framework, (3) LLMs Integration (4) Personalization Engine."
- Agent Task Planner: A module that decomposes complex user requests into actionable sub-tasks. "and the Agent Task Planner decomposes complex user requests into executable sub-tasks."
- agentic artificial intelligence: AI systems that autonomously plan and act to achieve goals with minimal human intervention. "The emergence of agentic artificial intelligence represents a paradigm shift in how consumers interact with e-commerce platforms"
- agentic commerce: Commerce interactions powered by autonomous, goal-directed agents. "a multi-agent system designed to revolutionize agentic commerce on the PayPal platform."
- Blackwell architecture: NVIDIA’s GPU architecture (e.g., B200) designed for high-performance AI inference and training. "the NVIDIA B200 Blackwell architecture consistently outperforms the H100 across all tensor parallelism configurations"
- Conversation Planning Framework: A module that manages multi-turn dialogue structure and flow. "the Conversation Planning Framework manages multi-turn dialogue flow,"
- cosine annealing schedules: A learning rate schedule that follows a cosine curve to improve optimization stability. "cosine annealing schedules, and LoRA ranks."
- Direct Preference Optimization (DPO): A training method that learns from pairs of preferred versus rejected outputs to align with human preferences. "Direct Preference Optimization (DPO) is a training method that learns from relative preferences rather than absolute labels."
- distributed optimizers: Optimization algorithms that run across multiple devices or nodes to scale training. "combined with sharded checkpoints and distributed optimizers, further simplified experimentation and scale-out operations."
- Domain Knowledge Center: A service that provides standardized access to product catalogs and business logic. "while the Domain Knowledge Center provides access to product catalogs and business logic through standardized protocols (API, MCP, A2A)."
- embedding space: The vector space in which items (e.g., queries and products) are represented for similarity-based retrieval. "by identifying similar real products in the embedding space, effectively grounding the generated hypothetical description to actual inventory..."
- E2E Latency: The total end-to-end time from user input to agent response. "achieves a substantial reduction in E2E Latency (), indicating faster processing speed."
- E2E Score: A composite metric evaluating overall system quality across multiple components. "and E2E Score ()"
- Generic Agent Orchestrator: The core controller that coordinates specialized agent components and tools. "At its core, the Generic Agent Orchestrator coordinates between multiple specialized components:"
- guardrailing: Safety mechanisms that constrain or monitor model outputs to prevent harmful or undesired behavior. "retrieval-augmented generation, guardrailing, data curation, and pretrained models."
- guided JSON: Constraining model outputs to structured JSON formats to streamline downstream processing. "guided JSON methods for streamlined post-processing operations."
- Hydra: A configuration management framework for organizing experiments via YAML/CLI. "Configuration management: Hydra-first YAML/CLI system enabled parallel tracking of 20 LoRA variants without manual scripting;"
- Hyperparameter sweeps: Systematic exploration of hyperparameter combinations to optimize model performance. "systematic hyperparameter sweeps across learning rates, optimizers (Adam, AdamW), cosine annealing schedules, and LoRA ranks."
- Hypothetical Document Embeddings (HyDE): A retrieval technique where an LLM generates hypothetical documents that are then used for dense retrieval. "we adopt the Hypothetical Document Embeddings (HyDE) approach for product retrieval."
- LangChain: A framework for building LLM-powered applications and agent orchestration. "utilizing the LangChain \cite{mavroudis2024langchain} agent orchestration framework to develop intelligent products"
- LLM Evaluator: A component that continuously monitors and assesses agent performance. "the LLM Evaluator continuously monitors agent performance,"
- LLM Model Gardens: Curated collections of models from which an agent can select the most suitable one. "the LLM Strategy module selects optimal models from the LLM Model Gardens (for instance: NVIDIA NIM Cloud),"
- LLM Strategy: A module responsible for selecting and configuring the optimal LLM for a task. "the LLM Strategy module selects optimal models from the LLM Model Gardens (for instance: NVIDIA NIM Cloud),"
- LLM-as-a-Judge: An evaluation paradigm where an LLM is used to assess the quality of model outputs. "Our evaluation employs LLM-as-a-Judge"
- LoRA: A parameter-efficient fine-tuning method that injects low-rank adapters into model layers. "training 20 LoRA-based model variants"
- llama3.1-nemotron-nano-8B-v1: A specific Nemotron-based 8B-parameter model variant used in experiments. "focusing on the llama3.1-nemotron-nano-8B-v1 architecture."
- Nemotron: NVIDIA’s family of LLMs used as a base for fine-tuning. "fine-tuned Nemotron SLM effectively resolves the key performance issue in the retrieval component,"
- NeMo Framework: NVIDIA’s end-to-end platform for data preparation, training, fine-tuning, and deployment of LLMs. "We collaborated with NVIDIA to solve these performance challenges by leveraging the NeMo Framework"
- NIM: NVIDIA Inference Microservices—containerized, pre-optimized inference services integrating engines like TensorRT-LLM and vLLM. "NVIDIA NIM is a containerized deployment solution that provides pre-optimized inference microservices"
- Parameter-Efficient Fine-Tuning (PEFT): Techniques that fine-tune large models by learning a small number of additional parameters. "NeMo's Parameter-Efficient Fine-Tuning (PEFT) support for LoRA/QLoRA techniques"
- QLoRA: A PEFT method that combines quantization with LoRA to reduce memory footprint during fine-tuning. "LoRA/QLoRA techniques"
- Retrieval-Augmented Generation: A method that integrates retrieved documents into the generation process to ground responses. "retrieval-augmented generation, guardrailing, data curation, and pretrained models."
- sequence parallelism: Splitting sequence dimensions across devices to scale training/inference. "sequence and context parallelism maintained stable, composable training;"
- sharded checkpoints: Checkpoints saved as multiple partitions to facilitate distributed training and flexible loading. "combined with sharded checkpoints and distributed optimizers"
- SGLang: A high-performance LLM inference engine. "including TensorRT-LLM, vLLM, and SGLang."
- Small LLM (SLM): A compact LLM tailored to specific tasks for lower latency and cost. "small LLMs (SLMs) optimized for commerce retrieval tasks."
- Supervised Fine Tuning (SFT): Fine-tuning a model using labeled examples with explicit targets. "The SFT champion model achieved a quality score of 2.49 out of 5"
- Tensor parallelism: Distributing model tensors across multiple devices to accelerate inference and training. "Tensor parallelism configurations (TP=1, TP=2, TP=4)"
- TensorRT-LLM: NVIDIA’s optimized inference engine for LLMs. "including TensorRT-LLM, vLLM, and SGLang."
- Top-K: Selecting the top K items (e.g., recommendations) based on a scoring function. "create personalized Top-K recommendations"
- vLLM: An LLM serving system optimized for high-throughput inference. "including TensorRT-LLM, vLLM, and SGLang."
Collections
Sign up for free to add this paper to one or more collections.