- The paper introduces an adaptive MoE architecture that integrates diverse bidirectional spatiotemporal Mamba modules for motion prediction.
- It achieves a 41.38% parameter reduction and 3.6x training speed-up, outperforming state-of-the-art models on multiple datasets.
- The approach demonstrates robust scalability and real-world applicability by effectively modeling complex multi-person motion dynamics.
Spatiotemporal-Untrammelled Mixture of Experts (ST-MoE) for Multi-Person Motion Prediction
Motivation and Limitations of Prior Work
Multi-person motion prediction demands not only accuracy in forecasting future joint positions but also the ability to model intricate and heterogeneous spatiotemporal dependencies. Prior models predominantly leverage either fixed positional encoding or attention-based mechanisms for spatiotemporal representation. Techniques such as temporal/spatial positional encoding (TPE/SPE), trajectory-aware relative position encoding (TRPE), and self-attention improve temporal and spatial correlation learning, yet remain fundamentally rigid and restricted in expressive power. Furthermore, self-attention and concatenation operations impose quadratic computational complexity, severely impacting scalability and efficiency.
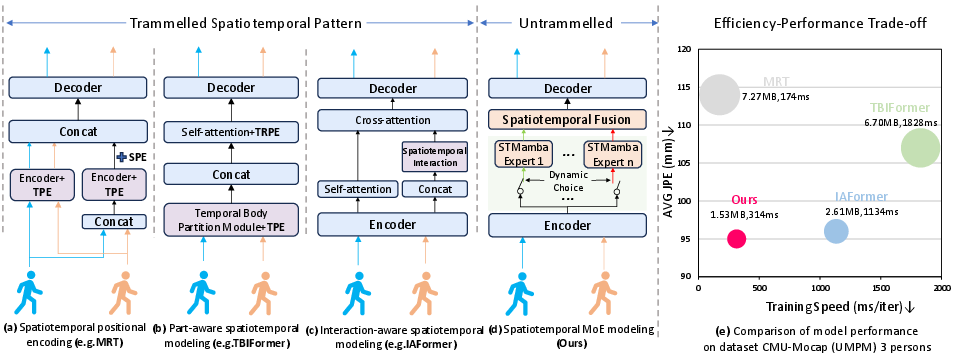
Figure 1: Overview of ST-MoE design and performance against conventional attention and encoding approaches on CMU-Mocap(UMPM); ST-MoE demonstrates optimal efficiency-accuracy trade-off via expert routing.
ST-MoE: Architecture Overview
The ST-MoE framework introduces an adaptive Mixture-of-Experts (MoE) architecture that circumvents the aforementioned limitations. Motion sequences, mapped from pose space to feature space via Discrete Cosine Transform (DCT) and a Multi-Pose Encoder, are input to an MoE layer equipped with dynamic, sparse expert selection. Crucially, each expert specializes in unique combinations of bidirectional spatial and temporal Mamba modules—state-space models designed to replace high-cost attention computations with linear-complexity selective scanning.
The routing mechanism, implemented via an MLP-based gating network, adaptively aggregates expert outputs based on input features, while sharing parameters across all experts to facilitate parameter economy. The final, aggregated representation is decoded back into pose space for future motion prediction.
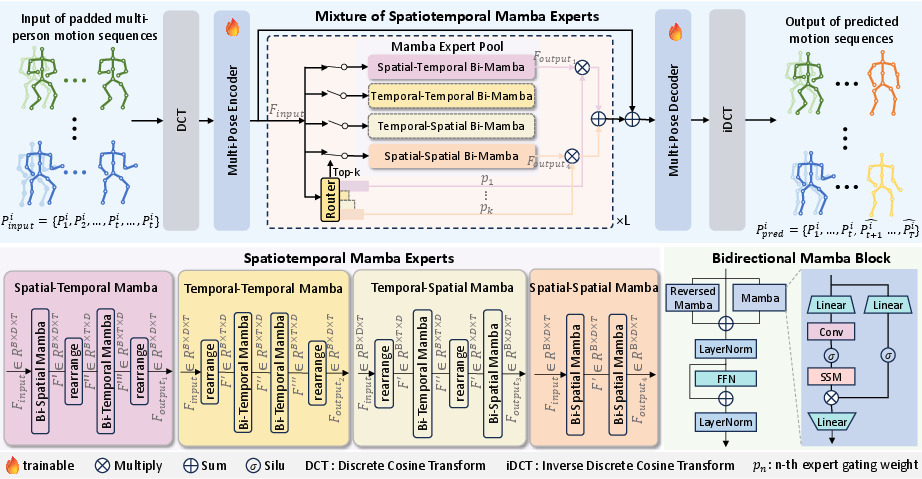
Figure 2: ST-MoE system: adaptive input routing to diverse spatiotemporal experts constructed from bidirectional temporal and spatial Mamba modules, followed by prediction decoding.
Spatiotemporal Expert Design
Four distinct expert types are instantiated by varying the order of bidirectional spatial and temporal Mamba operations—ST, TS, SS, TT—each capturing different dependency configurations. This avoids the rigidity of prior positional encoding methods, enabling comprehensive modeling of complex motion dynamics. Bidirectionality—both forward and backward passes—in the Mamba modules ensures capture of global interdependencies in both spatial and temporal domains.
Empirical ablation studies confirm that heterogeneous expert fusion outperforms homogeneous expert selection, with optimal predictive accuracy achieved when all expert types are simultaneously activated.

Figure 3: Left: Prediction accuracy vs expert activation count; Right: Influence of MoE layer stacking depth—single-layer design yields best generalization.
Numerical Results and Efficiency
Extensive evaluation on CMU-Mocap (UMPM), Mix1, Mix2, and CHI3D datasets documents statistically superior performance compared to baseline models including IAFormer, TBIFormer, and JRFormer, as measured by both Joint Position Error (JPE) and Aligned Position Error (APE). Notable is the strong generalization of ST-MoE with increasing numbers of individuals, demonstrating robust scalability in complex, real-world scenes.
ST-MoE achieves a 41.38% reduction in parameter count and a 3.6x acceleration in training speed over the state-of-the-art IAFormer, attesting to the computational efficacy of linear-time Mamba blocks. These gains are obtained without sacrificing accuracy—average JPE and APE metrics are consistently lower across all datasets and time horizons, including authentic multi-person sequences from CHI3D.
Qualitative Analysis of Spatiotemporal Representation
Comparative visualizations highlight ST-MoE’s ability to model nontrivial transitions between dynamic and static motion with minimal drift, in contrast to attention-based methods (e.g., IAFormer) which exhibit error accumulation and poor transition modeling.

Figure 4: ST-MoE recovers complex, multi-person movements with high fidelity, closely matching ground truth sequences on CMU-Mocap (UMPM).
Further t-SNE analyses of expert feature spaces reveal distinctly separated clusters, evidencing the specialization and complementary nature of expert representations.
Figure 5: t-SNE visualization of expert-learned features: four distinct experts yield highly separable spatiotemporal embeddings on CHI3D and Mix2.
Adaptive gating weight visualizations demonstrate dynamic expert selection consistent with spatiotemporal complexity: static scenes primarily activate ST/TT experts, while spatially dynamic actions such as running allocate higher weights to SS/TS experts.
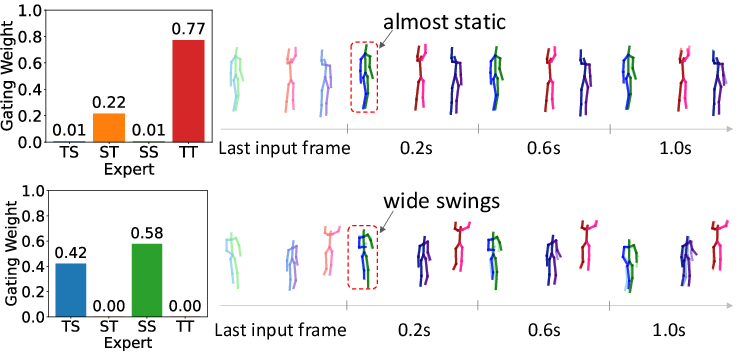
Figure 6: Gating weights are adaptively modulated based on spatiotemporal context, effecting specialized motion prediction across scenes.
Theoretical and Practical Implications
ST-MoE reconceptualizes multi-person motion prediction as an adaptive, expert-driven spatiotemporal modeling problem, leveraging state-space models for scalability and efficiency. It fundamentally addresses limitations in representational flexibility and computational cost found in prior attention/encoding paradigms.
This approach signals a trajectory toward lightweight, modular architectures—highly relevant for edge deployment, real-time inference, and cross-modal applications where low-latency is critical. The fusion of MoE and state-space modeling also opens prospects for scalable spatiotemporal understanding in domains beyond motion prediction, such as video understanding, behavior forecasting, and interactive autonomous systems.
Future Directions
Deterministic modeling constitutes ST-MoE’s primary focus; extension to stochastic multi-person motion prediction, integrating generative components for diversified trajectory synthesis, is a natural progression. Incorporating uncertainty quantification, conditional dynamics, and hierarchical temporal abstraction within the MoE framework can further improve adaptability to real-world, unpredictable motion patterns.
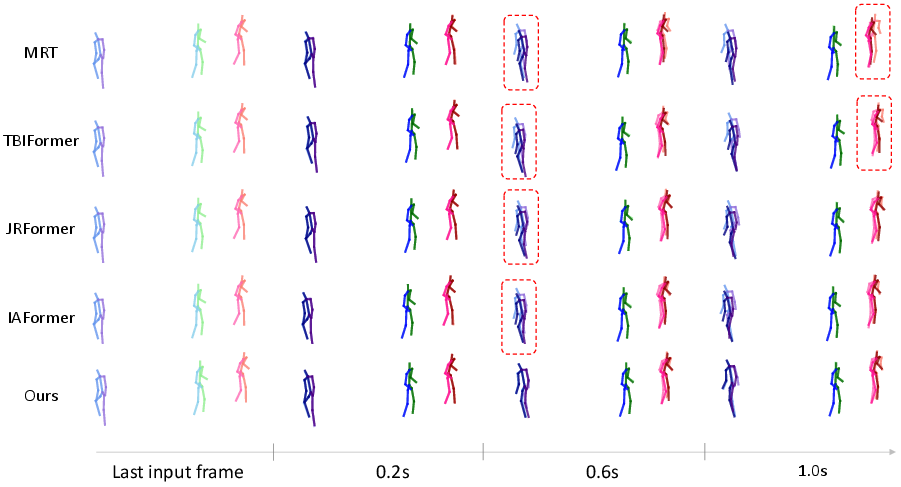
Figure 7: Additional qualitative comparisons highlight ST-MoE’s ability to capture fine-grained spatiotemporal details under modality and trajectory complexity.
Conclusion
ST-MoE introduces a formal, lightweight Mixture-of-Experts model equipped with bidirectional spatiotemporal Mamba modules for multi-person motion prediction. It achieves a strong balance between predictive accuracy and computational efficiency, validated across multiple standardized benchmarks. The model’s modular expert architecture, adaptive routing, and efficient state-space backbone have significant implications for spatiotemporal sequence modeling in applied and theoretical contexts. Further research into probabilistic modeling and broader domain adaptation is warranted.
