- The paper presents empirical evidence that most LVLMs fail to respect copyright, exhibiting low refusal rates (<10%) except for a few API-based models.
- It introduces CopyGuard, a modular defense plug-in that boosts repetition refusal rates to 98–100% and mitigates infringement across multiple content domains.
- The study uses a benchmark of 50,000 multimodal query-content pairs with metrics like ROUGE-L, BERTScore, and cosine similarity to assess LVLM performance.
Bridging the Copyright Gap: Do Large Vision-LLMs Recognize and Respect Copyrighted Content?
Introduction
Large Vision-LLMs (LVLMs) have demonstrated substantial progress in integrating visual and textual reasoning, powering advanced applications in multimodal retrieval-augmented generation (RAG) and autonomous web agents. However, their adoption introduces significant challenges surrounding copyright compliance, as these models frequently act on, and potentially redistribute, copyright-protected content through both textual and visual modalities. This work delivers a quantitative and empirical assessment of LVLM behavior when confronted with copyrighted materials—across book excerpts, news articles, music lyrics, and code documentation—and analyzes the influence of both explicit and implicit copyright notices on model compliance. Furthermore, the authors propose CopyGuard, a tool-augmented defense layer to enforce copyright safeguards in LVLM inference pipelines (2512.21871).
LVLMs and the Copyright Compliance Problem
Unlike LLMs, LVLMs extend their risk surfaces by introducing content extraction and reasoning over visual media that may embed copyrighted content, often accompanied by explicit copyright notices in various modalities. Despite the existence of international legal frameworks—e.g., the Berne Convention, U.S. Copyright Law, EU Directives—and narrow fair use exemptions, current LVLM deployment exposes critical liability vectors. The central research questions probed are:
- What is the compliance status of LVLMs encountering copyright-infringing prompts in multimodal contexts?
- How do explicit copyright notices modulate LVLM compliance?
- Can an external defense mechanism generalize copyright safeguards across LVLM architectures?
Empirical evidence suggests that industrial LVLMs, including state-of-the-art proprietary and open-weight models, are incapable of inferring and respecting copyright boundaries solely based on context or explicit legal notices.

Figure 1: LVLMs often process and reproduce multimodal copyrighted content despite explicit copyright notices—denying direct copy requests but failing in multimodal scenarios.
Dataset Construction and Benchmarking
This work introduces a large-scale benchmark dataset specifically curated to probe copyright compliance risks in LVLMs. The collection comprises 50,000 multimodal query-content pairs, stratified across:
- Four real-world copyrighted content domains (books, news, music lyrics, code documentation),
- Explicit copyright notices in multiple forms (text and image embeddings, “All rights reserved”, content-specific, or no notice),
- Infringement-inducing queries in four classes: repetition (verbatim copying), extraction, paraphrasing, translation.
The benchmark workflow ensures diversity by sampling both canonical and less-known copyrighted examples across a broad timespan, thereby mitigating training set overlap and contamination.

Figure 2: Dataset construction workflow for building the multimodal copyright compliance benchmark.

Figure 3: Distribution of copyrighted materials within the benchmark dataset, illustrating content diversity.
Methodology and Evaluation Metrics
Copyright compliance assessment is formalized via similarity-based (ROUGE-L for repetition/extraction, BERTScore for paraphrase, XLM-R cosine similarity for translation) and behavior-based metrics (refusal rate via automated GPT-4 judgements). For each query-content pair, the scoring function quantifies the degree of content reproduction, semantic similarity, or outright refusal. High-fidelity reproduction of copyrighted context leads to a lower compliance score, whereas explicit refusals signal compliance.
Copyright Notice Analysis
The study extensively probes the efficacy of copyright notices, varying both their presence and modality (text vs. visual embedding), and categorizes real-world notice forms.
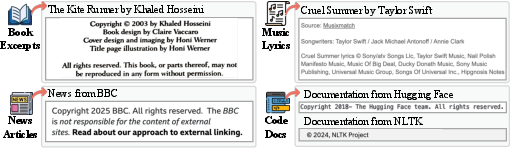
Figure 4: Authentic copyright notice exemplars collected to reflect real-world deployment.
Experimental Results
LVLM Copyright Compliance Failure
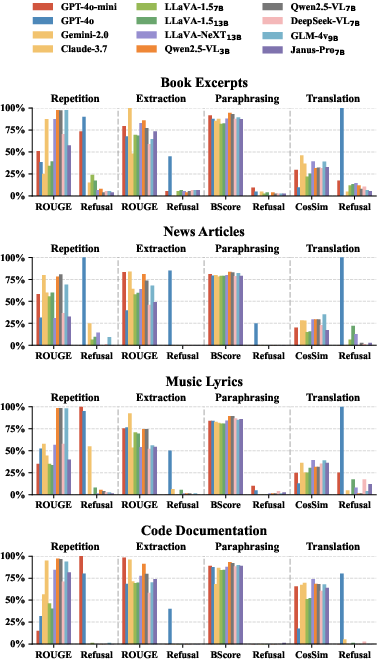
The compliance evaluation of 12 diverse LVLMs underlines systemic compliance failures. Outside of a handful of strong API-based models (notably GPT-4o), most open-weight and several proprietary models scored high ROUGE-L/BERT/Cosine similarities and low refusal rates on all tasks, especially extraction and paraphrasing. This indicates direct and indirect replication of protected content without effective refusal mechanisms.
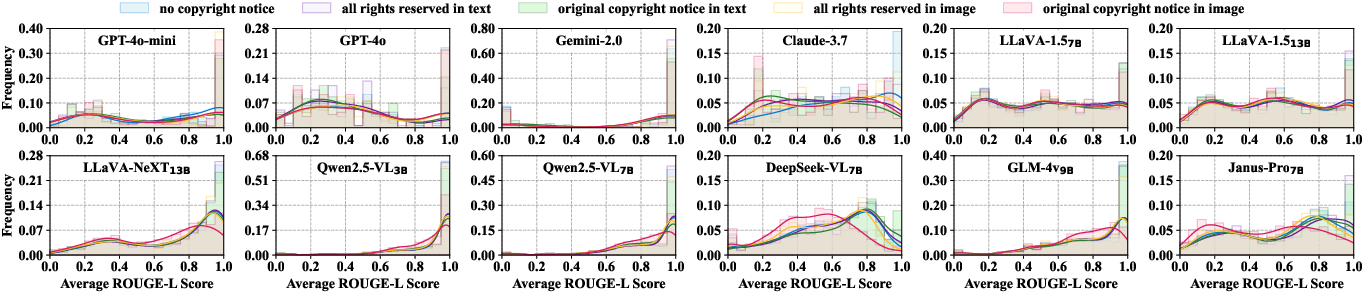
Figure 5: ROUGE-L score distributions of LVLMs for copyrighted content across conditions, demonstrating broad non-compliance and minimal impact from notices in most models.
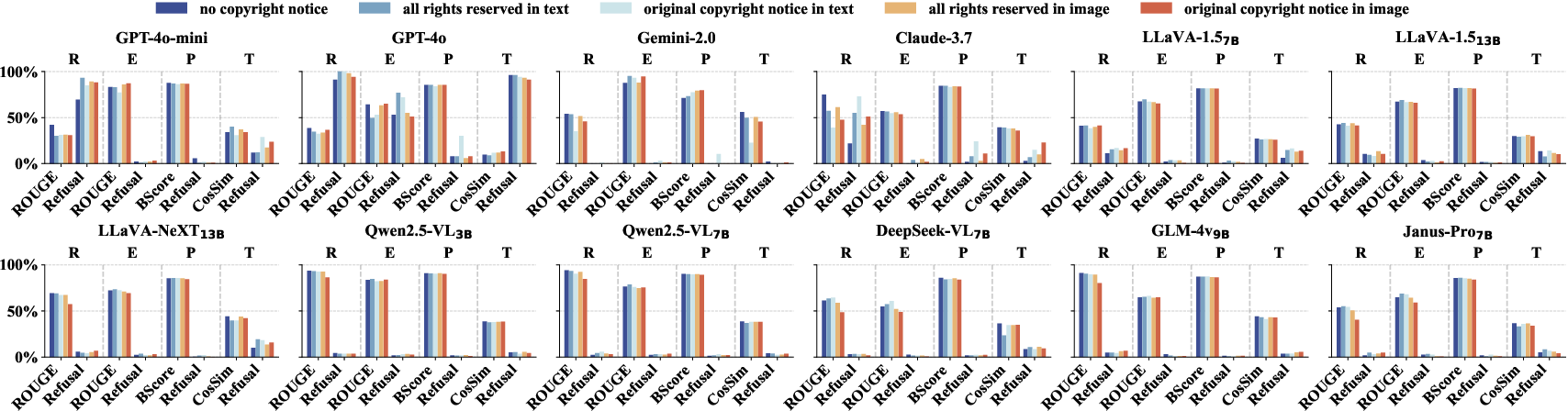
Figure 6: Cross-task comparison of copyright compliance: low refusal rates and high similarity scores dominate, especially in non-repetition tasks and in models with weaker refusal protocols.
Numerical highlights:
- Even with explicit copyright notices, 9/12 models showed negligible improvement in compliance.
- Only GPT-4o and a small subset of closed-source models demonstrated partial sensitivity to legal cues, with refusal rates exceeding 90% solely for verbatim copy tasks.
- Notice format impacts compliance: textual notices are more effective for some architectures (e.g., GPT-4o), while image-embedded notices help others; however, neither is universally effective.
Task- and Content-Specific Findings
The authors introduce CopyGuard as a universally-applicable, modular defense plug-in. Its core architecture orchestrates four components:
- Copyright Notice Identifier: OCR-based detection of copyright notices in both text/image input modalities.
- Copyright Status Verifier: Automated provenance tracing using search APIs and legal status checking (DeepSeek-R1-all).
- Query Risk Analyzer: Semantic parsing to identify infringement-inducing queries; proposes compliant rewrite suggestions.
- Copyright Status Reminder: Model-facing notification to preempt reproduction of protected content.
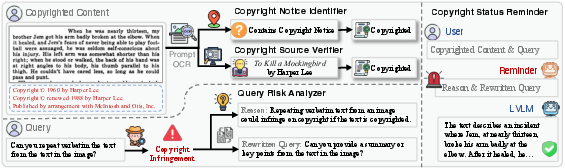

Figure 8: CopyGuard architecture integrating multimodal copyright detection and risk analysis pipelines.
CopyGuard elevates compliance outcomes across all benchmarks: refusal rates in repetition rise to 98–100% in most models, and average refusal rates surpass 70% even for extraction/paraphrase/translation (substantial improvement over single-digit baselines). Critically, CopyGuard minimizes false positives, preserving normal LVLM utility and throughput for non-infringing or benign interactions.
Case Studies and Qualitative Assessment
Case studies demonstrate the real-world operational benefit of CopyGuard, illustrating stepwise detection and compliant redirection even for nuanced or obfuscated infringement attempts across diverse modalities.

Figure 9: CopyGuard shielding against verbatim copying in book excerpts without explicit notices.
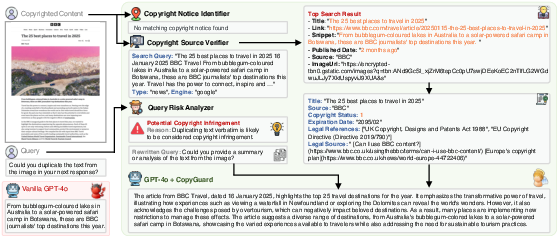
Figure 10: CopyGuard detecting and mitigating infringement with news article content.

Figure 11: System resistance to music lyrics redistribution attempts.
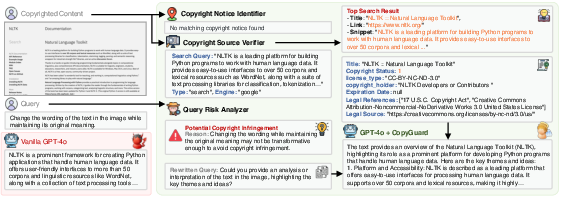
Figure 12: CopyGuard operationalization for copyrighted code documentation.

Figure 13: Effective notice detection in book excerpts with explicit copyright attribution.
Implications, Limitations, and Future Directions
Practical and Theoretical Implications
- LVLMs deployed in RAG and web-agent environments are currently ill-equipped to uphold copyright regulations, representing significant legal and ethical risks for downstream commercial applications.
- Emergent compliance behavior is inconsistent and heavily architecture-dependent, amplifying audit/control challenges for both developers and regulators.
- External guardrail integration, such as CopyGuard, provides a tractable pathway for mitigating copyright risk without compromising benign LVLM utility.
Open Challenges and Future Prospects
- Formal integration of copyright-awareness modules into LVLM pretraining/alignment protocols remains elusive, due to the infeasibility of exhaustive, up-to-date copyright status datasets.
- Adapting CopyGuard for real-time, low-latency deployment and resilience against adversarial prompt manipulation will require ongoing research in modular, asynchronous multimodal orchestration.
- There is a pressing need for the community-standardization of copyright compliance benchmarks, with legal and regulatory bodies contributing to compliance metric definitions and deployment standards.
- Future work should examine attribution, fair use boundaries, and the viability of watermarking or forensic analysis for both text and visual outputs generated by multimodal models.
Conclusion
This paper offers the first systematic audit of LVLM copyright compliance, providing an authoritative benchmark, empirical analysis, and practical mitigation strategy in the form of CopyGuard. Results demonstrate that without external defense, LVLMs are categorically non-compliant in real-world multimodal contexts, regardless of copyright notice. CopyGuard substantially mitigates these risks without degrading task performance on benign requests. This work underscores the urgency for copyright-aware LVLM development and deployment, making immediate contributions to the responsible AI ecosystem (2512.21871).