- The paper establishes formal equivalence among NMF, PLSA, LBA, EMA, and LCA by mapping their factorization solutions to a unified framework.
- It demonstrates that identifiability, the uniqueness of latent factors, is critically shaped by geometric and algebraic constraints across models.
- The work proposes sufficient conditions like separability and minimum volume to ensure uniqueness, offering robust, cross-disciplinary insights into latent decomposition.
Unified Frameworks and Identifiability in NMF, PLSA, LBA, EMA, and LCA
Introduction
This paper synthesizes the landscape of five major low-rank nonnegative matrix models—Nonnegative Matrix Factorization (NMF), Latent Budget Analysis (LBA), End-Member Analysis (EMA), Probabilistic Latent Semantic Analysis (PLSA), and Latent Class Analysis (LCA)—with a primary focus on the identifiability of their solutions. Despite their independent developments across machine learning, social science, geology, and signal processing, these models share a deeply related mathematical understructure. This essay delineates the core equivalence results, the geometric and theoretical underpinnings of identifiability, and the model-specific and unified algorithmic strategies discussed in "A review of NMF, PLSA, LBA, EMA, and LCA with a focus on the identifiability issue" (2512.22282).
A fundamental contribution is the precise characterization of model equivalences. LBA (social sciences, for compositional/time budget data), EMA (geology, for compositional sediment mixtures), and asymmetric PLSA (machine learning, for document-word co-occurrences), all adopt the factorization
Π=WG
with nonnegativity and per-row sum-to-one constraints on matrices. LCA in statistics and symmetric PLSA in machine learning are formally equivalent, differing only in parameter arrangements, and can be rewritten into the above form.
NMF generalizes all these settings, relaxing the sum-to-one constraints. The paper establishes, with explicit constructive mappings, that LBA, EMA, and asymmetric PLSA factorization solutions are special cases of NMF under appropriate normalization, and vice versa. Theorem 1 in the paper gives the formal convertibility between these models, ensuring the transferability of theoretical results, especially those concerning uniqueness/identifiability.
Identifiability: Geometric and Algebraic Perspectives
Identifiability—the condition under which latent factors are determined uniquely (up to allowable indeterminacies: scaling, permutation)—is the central property analyzed. The ubiquity of non-identifiability is shown explicitly in illustrative cases.
Given the basic NMF factorization, for some invertible K×K matrix S, there is always a family of decompositions:
Φ=MH=(MS−1)(SH)
However, the structured constraints (nonnegativity, stochasticity) strongly restrict valid S. With only nonnegativity, there can be considerable ambiguities, but with sum-to-one constraints (LBA/EMA/PLSA), additional transformation restrictions arise.
Toy Examples and Geometric Visualization
To concretize non-uniqueness, the paper employs geometric illustrations using contingency tables and their simplex-normalized versions. For both basis and coefficient matrices, distinct configurations yield identical reconstructions, with rows of the observed matrix contained in convex hulls (for LBA/EMA/PLSA) or convex cones (for NMF) of the basis matrices.
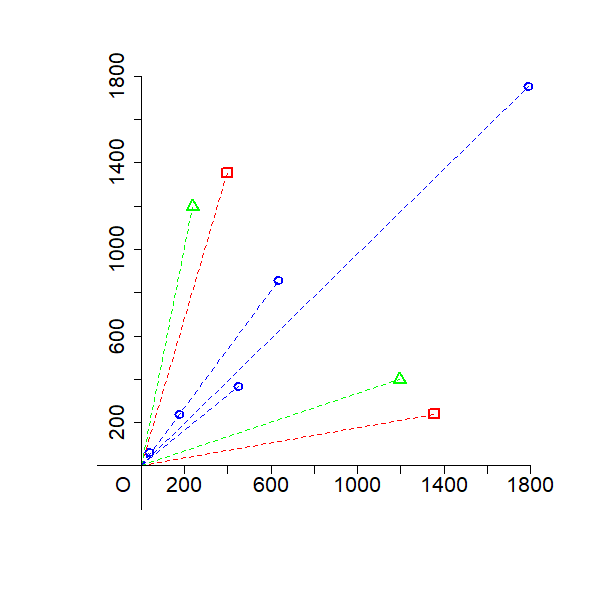
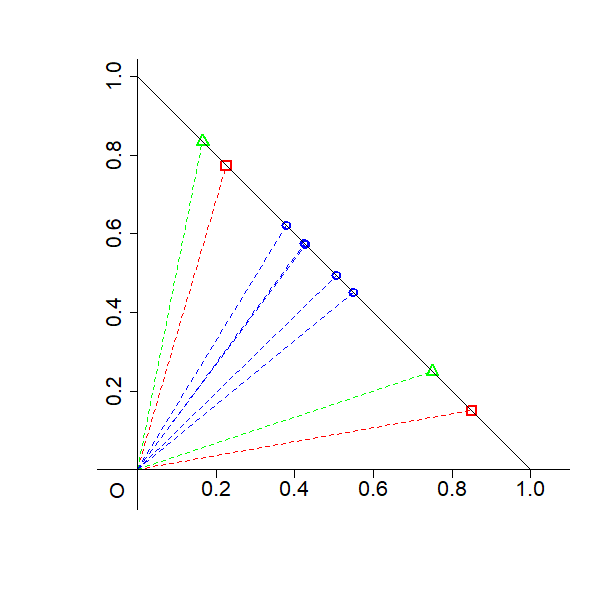
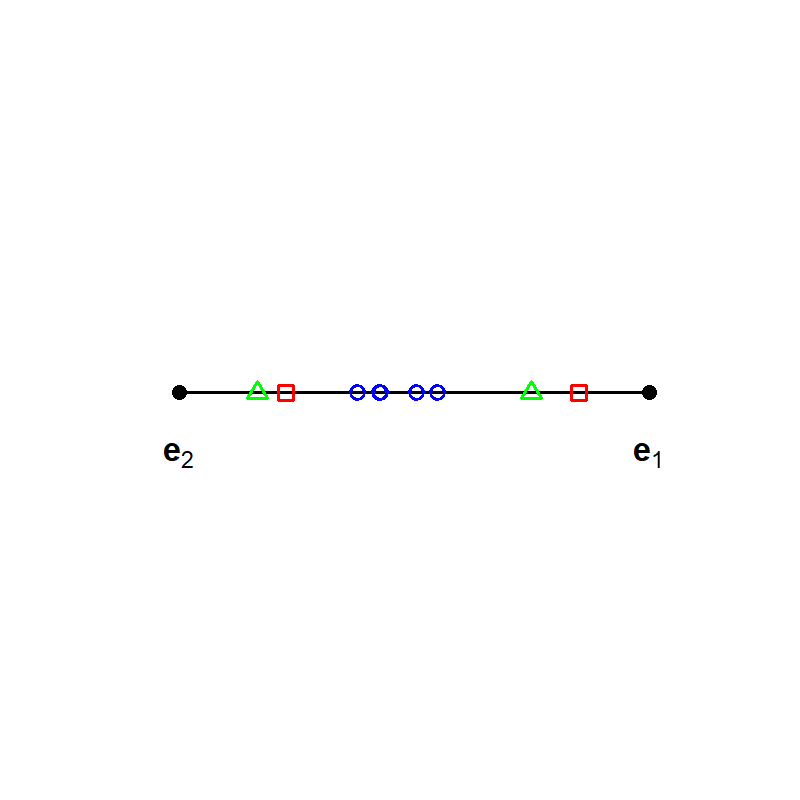
Figure 1: Geometric illustration that the solutions of NMF, LBA, EMA, and asymmetric PLSA are not unique using a two-way contingency table.
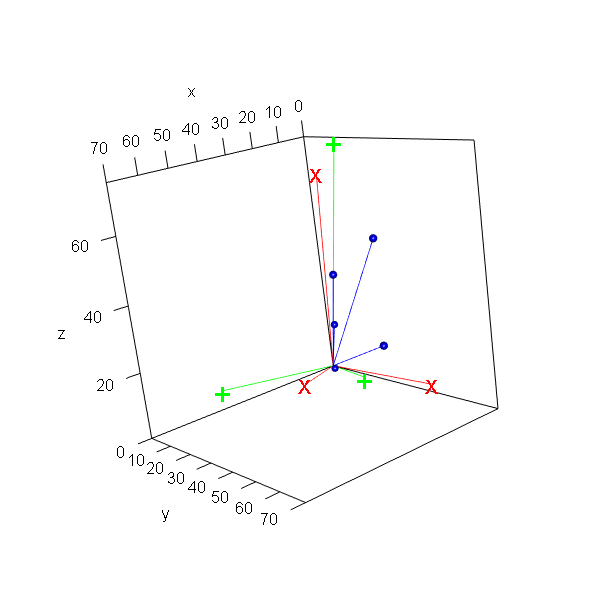
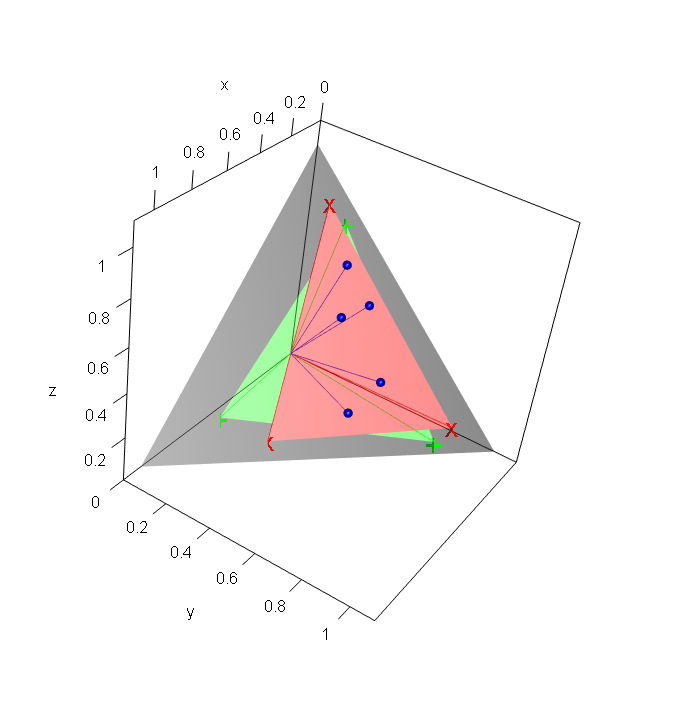
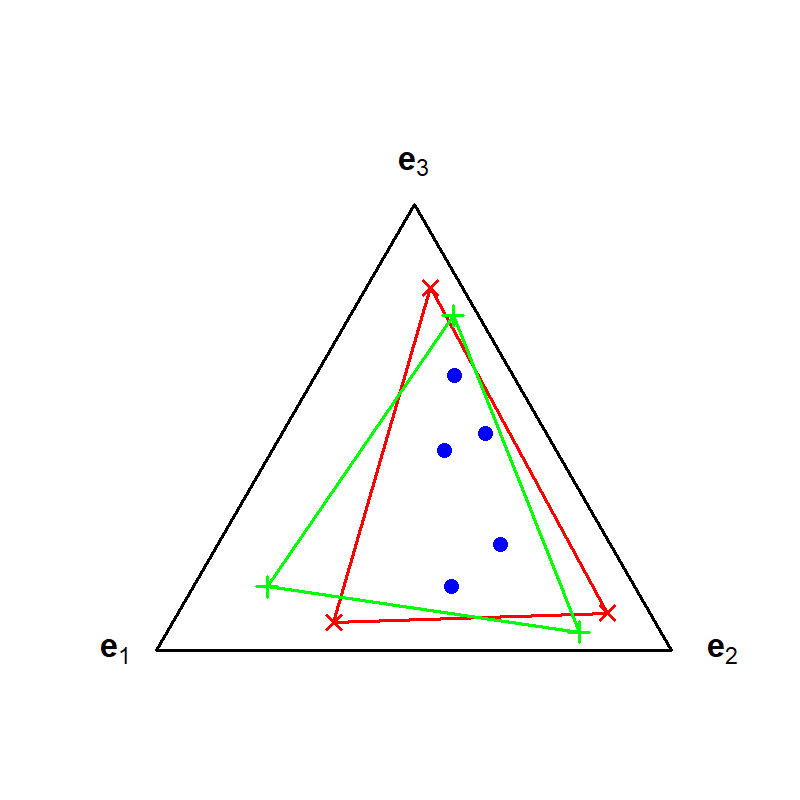
Figure 2: Geometric illustration that the solutions of NMF, LBA, EMA, and asymmetric PLSA are not unique in a 3-class compositional context.
These figures reveal that the choice of basis is not unique—a central identifiability challenge.
Main Theoretical Result: Identifiability Transfer
The essential theoretical result is: the solution of NMF is unique if and only if the corresponding solution of LBA, EMA, and asymmetric PLSA is unique. This is proved by constructing explicit mappings: if a transformation creates non-uniqueness in NMF, an analogous transformation exists in the other models given their constraints.
This result operationally allows the transfer of extensive identifiability theory from the NMF literature—where the problem is much more developed—to LBA/EMA/PLSA, and by extension, to LCA and symmetric PLSA.
Sufficient Conditions for Identifiability
Because non-uniqueness is generic, practical usage demands conditions that guarantee uniqueness.
Separability
A strong, well-studied sufficient condition in NMF is separability: the coefficient matrix contains, possibly permuted, K×K identity blocks. In this case, each basis vector corresponds exactly (up to scaling/permutation) to some observed data row, ensuring uniqueness.
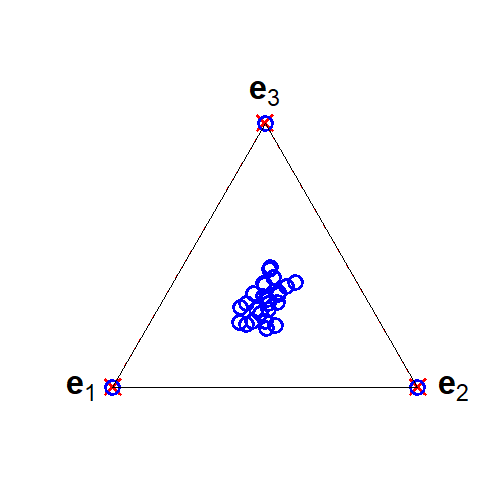
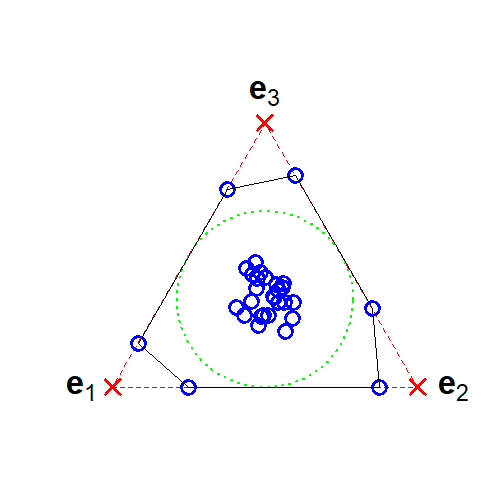
Figure 3: Geometric illustration of separability: basis vectors are present in the observed data (blue dots)—the corner points of the nonnegative simplex (red crosses).
However, separability rarely holds in real data as generative processes are typically much more mixed.
Minimum Volume/Sufficient Scatteredness
A more relaxed but intricate sufficient condition is minimum volume or sufficient scatteredness: the simplex generated by the basis vectors must have minimum volume enclosing the data (or, in algebraic terms, the convex hull of basis vectors tightly wraps the data cloud, and the set of coefficient vectors spans a second-order cone).
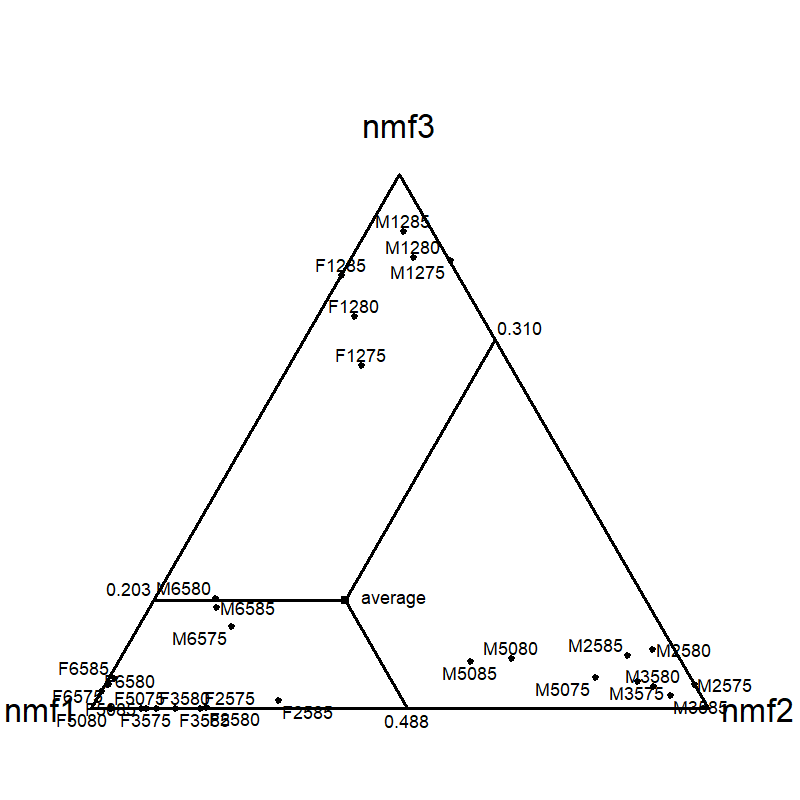
Figure 4: Simplex about time budget dataset for NMF with K=3; empirical points (activities) reside inside the simplex formed by the basis vectors.
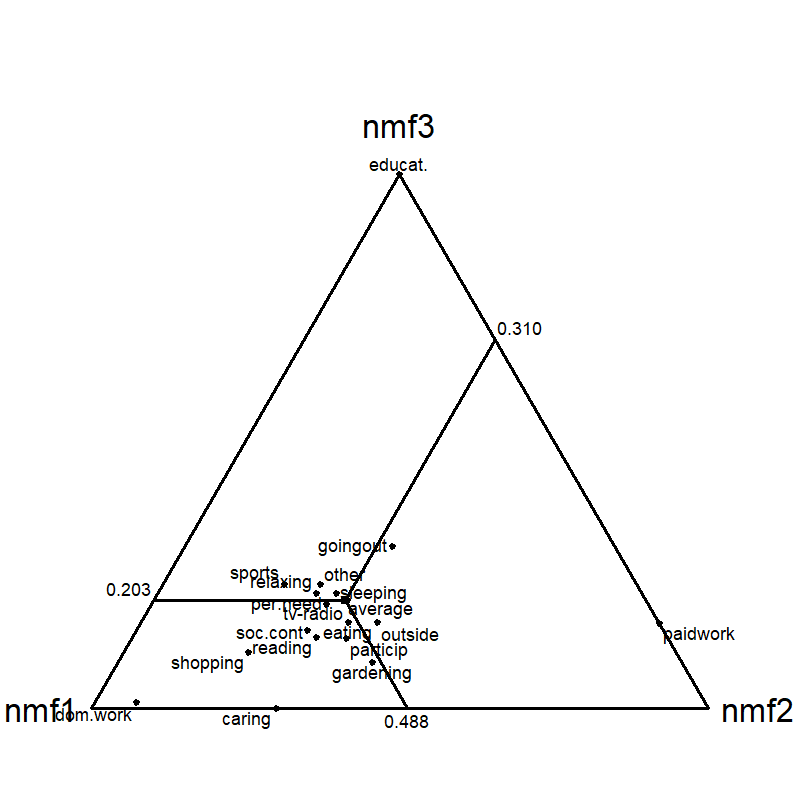
Figure 5: Simplex about time budget dataset for NMF with K=3; projection onto columns reveals the relationships among dimensions.
Under these conditions, uniqueness extends to the LBA/EMA/PLSA context via the established equivalence.
LBA Extreme Solutions
For LBA (and EMA), identifiability has also been addressed geometrically by "inner extreme" (minimum total distance/volume, leading to most similar basis) and "outer extreme" (maximum difference, maximally distinct basis) solutions. For K=2, these solutions are unique, but for higher rank, multiple extreme simplexes may exist with equal minimum or maximum measures.
Algorithmic Frameworks
Algorithm selection depends on the factorization model and the distributional assumptions:
- NMF: Wide variety of algorithms, including alternating least squares (ALS), projected gradient, and regularized/minimum-volume approaches. Modern methods incorporate robust regularization (e.g., log-determinant of Gram matrices) and are implemented in major toolkits (e.g., MATLAB, Python).
- LBA: EM and majorization algorithms tailored for multinomial data, as well as constrained weighted least squares for model misspecification or distributional agnosticism.
- EMA: Two-stage approaches with SVD or NMF-based initialization, followed by simplex-expansion or constrained optimization for achieving nonnegativity and sum-to-one constraints.
- PLSA, LCA: EM algorithm is standard, with temperature (annealing) methods to mitigate overfitting. LCA solutions may be obtained from LBA via parameter transformations.
The connection of these algorithms allows cross-fertilization; for example, regularization methods or identifiability-enforcing strategies developed in NMF can inform improved estimation in LBA, EMA, or PLSA contexts.
Empirical Example: Time Budget Decomposition
The paper provides empirical decomposition of a Dutch time-budget dataset, demonstrating the operational equivalence of LBA, EMA, and NMF, and verifying that—when identifiability-enhancing criteria are imposed (inner extreme/minimum volume)—the resulting components are robustly aligned across models. Triangle plots (ternary diagrams) illustrate the affinity of demographic groups to each latent component (e.g., paid work, domestic work, education) and confirm the effectiveness of the approach in real compositional data.
Theoretical and Practical Implications
The demonstration of formal equivalence and identifiability transfer has significant consequences:
- Theory Consolidation: It unifies disparate literatures, enabling direct translation of results and techniques (especially identifiability criteria) across disciplines—e.g., from ML to geology or sociology.
- Algorithm Design: Algorithmic strategies and regularization crafted in the NMF ecosystem (e.g., minimum volume, sufficient scattered criteria) can be leveraged to improve estimation in fields previously reliant on less developed tools.
- Model Selection and Error Analysis: Understanding how and when solutions are unique (or non-unique) informs robustness/uncertainty analyses of latent decompositions, crucial for scientific inference.
- Extensions: The framework interfaces with more complex models such as archetypal analysis, topic models (LDA), and blind source separation, fostering further cross-domain developments.
Future Directions
Relaxation of the sufficient conditions for identifiability (beyond separability and strong sparsity) remains crucial for practical applications, as real data rarely satisfy idealized constraints. Advances in regularized and probabilistic matrix factorization, scalable numerical algorithms, and interpretable uncertainty quantification are anticipated. Similarly, the extension and refinement of identifiability results for outer extreme/unmixing formulations are open avenues, especially for higher-rank, highly mixed compositional data.
Conclusion
This paper systematizes the mathematical and algorithmic relationships among NMF, LBA, EMA, PLSA, and LCA, with a rigorous treatment of identifiability. The bidirectional uniqueness equivalence, geometric and algebraic visualizations, and unified algorithmic review form a robust foundation for cross-disciplinary research and methodological innovation in latent structure discovery in nonnegative compositional data (2512.22282).