Act2Goal: From World Model To General Goal-conditioned Policy
Abstract: Specifying robotic manipulation tasks in a manner that is both expressive and precise remains a central challenge. While visual goals provide a compact and unambiguous task specification, existing goal-conditioned policies often struggle with long-horizon manipulation due to their reliance on single-step action prediction without explicit modeling of task progress. We propose Act2Goal, a general goal-conditioned manipulation policy that integrates a goal-conditioned visual world model with multi-scale temporal control. Given a current observation and a target visual goal, the world model generates a plausible sequence of intermediate visual states that captures long-horizon structure. To translate this visual plan into robust execution, we introduce Multi-Scale Temporal Hashing (MSTH), which decomposes the imagined trajectory into dense proximal frames for fine-grained closed-loop control and sparse distal frames that anchor global task consistency. The policy couples these representations with motor control through end-to-end cross-attention, enabling coherent long-horizon behavior while remaining reactive to local disturbances. Act2Goal achieves strong zero-shot generalization to novel objects, spatial layouts, and environments. We further enable reward-free online adaptation through hindsight goal relabeling with LoRA-based finetuning, allowing rapid autonomous improvement without external supervision. Real-robot experiments demonstrate that Act2Goal improves success rates from 30% to 90% on challenging out-of-distribution tasks within minutes of autonomous interaction, validating that goal-conditioned world models with multi-scale temporal control provide structured guidance necessary for robust long-horizon manipulation. Project page: https://act2goal.github.io/


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
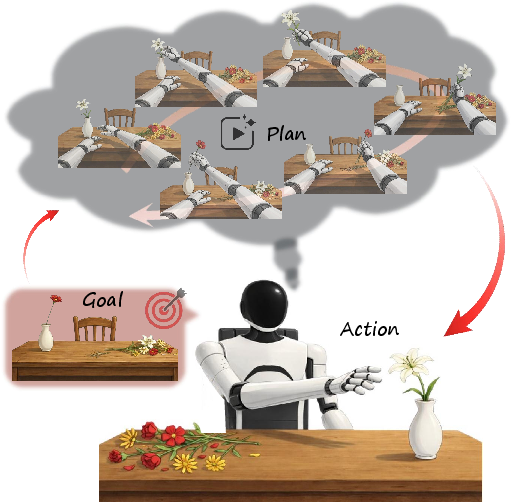
This paper introduces Act2Goal, a new way to control robots using pictures of what the final result should look like. Instead of telling a robot what to do with words or step-by-step rules, you give it a “goal image” (a picture of the goal). The robot then imagines the steps needed to get from what it currently sees to that goal, and uses that plan to act smoothly over many steps. The big idea is to make robots better at long, multi-stage tasks in the real world, even with new objects or environments they haven’t seen before.
What questions are the researchers trying to answer?
- How can we tell a robot exactly what we want without confusing language instructions?
- How can a robot handle long tasks that need many small steps, not just one quick action?
- Can a robot “imagine” a path from now to the goal and use that plan to act better?
- Can a robot keep improving by learning from its own attempts, without a teacher or reward scores?
How does Act2Goal work?
Think of Act2Goal like a person using a GPS with a live camera:
- The “goal image” is the destination (what the final scene should look like).
- The robot’s “world model” is its imagination: it predicts a series of in-between pictures showing how the world should change on the way to the goal.
- The robot’s “action expert” turns that imagined plan into precise arm and hand movements.
- A special trick called Multi-Scale Temporal Hashing (MSTH) helps the robot pay attention both to short-term details and the long-term plan at the same time.
Here are the main parts, explained with everyday language:
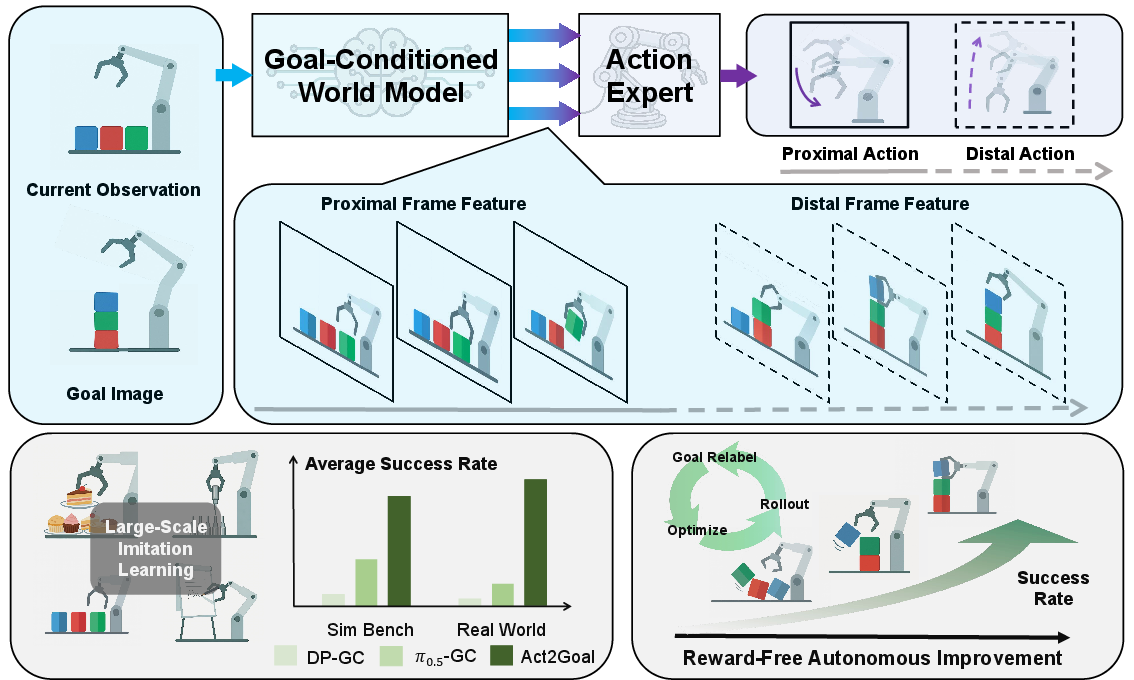
- Goal-conditioned world model (the robot’s imagination)
- Given what the robot sees now and a goal image, it creates a possible sequence of future images that gradually transform the current scene into the goal scene.
- You can picture this like un-blurring a future movie: starting from noisy frames and sharpening them step by step into a smooth plan.
- Multi-Scale Temporal Hashing (MSTH) (near-and-far planning)
- The robot splits its imagined future into two kinds of snapshots:
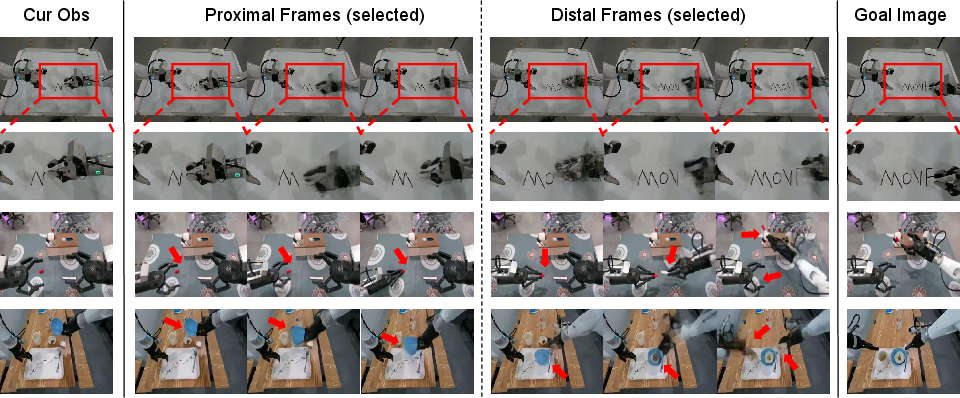
- Proximal frames: close-up, frequent frames for the next few moments. These help the robot control its movements precisely and react to small changes.
- Distal frames: sparser, farther-in-time frames that act like anchors, keeping the robot aligned with the big-picture goal.
- This is like walking while checking your feet placement (near) and occasionally looking up to make sure you’re still headed to the right landmark (far).
- Turning the plan into actions
- The robot uses “attention” to focus on the most useful parts of the imagined plan while deciding what to do with its motors.
- Only the near-term actions are executed at each moment, but the far-term plan keeps the overall behavior consistent.
- Training and self-improvement
- Stage 1: Train the imagination and the action maker together, so imagined futures are useful for action.
- Stage 2: Fine-tune the whole system to copy expert behavior more closely.
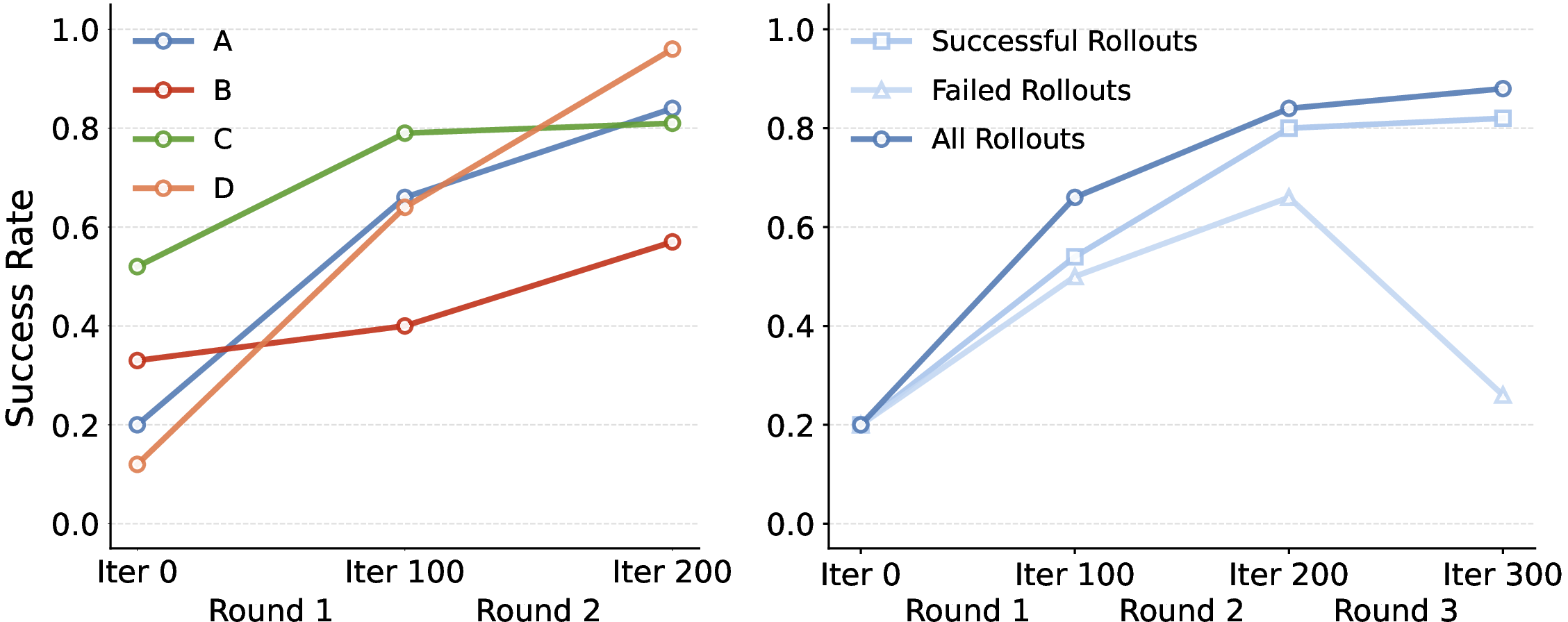
- Stage 3 (optional): Online self-improvement with no rewards or human labels. The robot learns from its own attempts using a trick called Hindsight Experience Replay (HER):
- Even if it fails the original goal, it treats whatever it actually achieved as a “goal” and learns how to reproduce that. This lets it extract lessons from both successes and failures.
- It updates itself quickly using a lightweight method called LoRA, which tweaks only small parts of the model so on-robot learning is fast.
What did they find, and why does it matter?
- Strong performance on long tasks: Act2Goal handled multi-step manipulation better than other methods that only predict single-step actions.
- Generalizes to new situations: It worked well on new objects, layouts, and environments it hadn’t seen during training (called “zero-shot generalization”).
- Real robot gains: In real-world tasks such as:
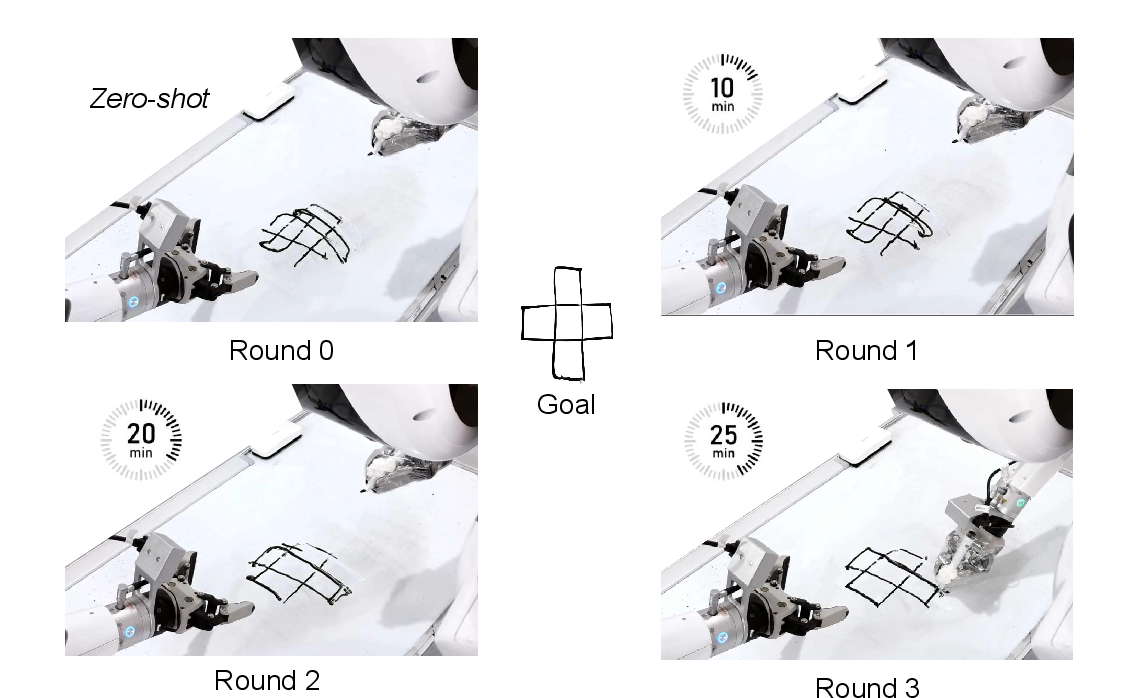
- Whiteboard word writing (drawing letters accurately),
- Dessert plating (arranging items to match a goal image),
- Plug-in operation (inserting a part into a slot),
- Act2Goal significantly outperformed other approaches. After learning online from its own attempts, it improved success rates on tough, unfamiliar tasks from around 30% to about 90% within minutes.
- MSTH is key: Without MSTH, performance dropped sharply on longer tasks (like writing long words). With MSTH, the system stayed accurate on both short and long tasks, including unseen words.
Why this matters:
- Many real-world robot jobs are long and complex: cleaning a table, assembling parts, organizing shelves. They require staying on track for many steps while staying flexible to small changes. Act2Goal’s imagined plans plus near-and-far control help handle both.
What’s the potential impact?
- Easier instructions: You can show a robot what you want with a picture, not a complicated script or vague language.
- More robust robots: The robot can imagine a path to the goal, stick to the big plan, and still react to surprises.
- Fast on-the-job learning: Without human labels or explicit reward scores, the robot can get better by analyzing its own attempts and updating itself quickly.
- Scales to real-world tasks: This approach could make robots more useful in homes, factories, hospitals, and kitchens—anywhere precise, multi-step manipulation is needed with minimal setup.
In short, Act2Goal shows that giving robots a visual goal, teaching them to imagine the steps to get there, and blending short-term control with long-term anchors can make them much better at long, tricky tasks—and able to improve themselves over time.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concise list of what remains missing, uncertain, or unexplored in the paper, framed to be directly actionable for future research.
- Dataset transparency and reproducibility: The paper does not report dataset composition, scale, diversity, camera setups, action modalities, or train/test splits for offline imitation learning, making it difficult to assess generalization breadth, reproduce results, or compare fairly to baselines.
- Baseline parity and evaluation fairness: Training budgets, data access, hyperparameters, and architecture capacities for baselines (DP-GC, HyperGoalNet, π0.5-GC) are not detailed; it is unclear whether baselines received comparable visual goal conditioning or multi-view inputs.
- Limited task coverage: Real-world evaluation spans only three tasks and one robot platform; it is unknown how Act2Goal performs across broader manipulation taxonomies (e.g., deformables, assembly, tool use), multi-object coordination, or tasks requiring high-precision contact.
- Sensitivity to MSTH hyperparameters: The impact of proximal horizon P, stride r, distal count M, and total horizon K on performance is not analyzed; there is no study of robustness to different spacings or learned schedules versus fixed logarithmic spacing.
- Adaptivity of temporal abstraction: MSTH is presented as “horizon-adaptive,” yet the sampling scheme appears static given K and M; there is no mechanism or analysis for task-dependent or online-adaptive temporal abstraction learned from data.
- Role and training of distal actions: Distal actions are predicted but never executed; the paper does not clarify how distal actions contribute to learning (loss weighting, consistency constraints), nor whether they are necessary relative to distal visual frames alone.
- Visual plan quality and fidelity: The goal-conditioned world model is evaluated primarily with qualitative clips; there are no quantitative metrics (e.g., FVD, pixel/feature reconstruction, trajectory consistency) or alignment measures between imagined and executed trajectories.
- Partial observability and occlusion robustness: The world model is “purely vision-based” and relies on compressed VAE latents; there is no analysis of performance under severe occlusion, changing viewpoints, or multi-view fusion strategies beyond a generic “multi-view” mention.
- 3D geometry and depth: The paper does not report whether depth, point clouds, or 3D scene representations are used or beneficial; it is unclear how the approach handles tasks that require explicit 3D reasoning or precise spatial constraints.
- Contact dynamics and force feedback: Tactile/force sensing and contact modeling are absent; the ability of the visual-only world model to anticipate and control contact-rich dynamics (e.g., insertions, tight tolerances) remains untested.
- Closed-loop execution specifics: The frequency of replanning, receding horizon strategy, and how proximal frames/actions are recomputed under disturbances are not described; the controller’s stability and responsiveness under real perturbations are not quantified.
- Inference efficiency and deployability: There are no measurements of inference latency, throughput, memory footprint, or energy usage on the edge device during world-model generation and action refinement (flow matching), nor an analysis of real-time viability.
- Flow matching details and ablations: The number of steps N, vector field architectures, noise schedules, and loss weighting across layers are not specified; there are no ablations comparing flow matching to diffusion or autoregressive alternatives for actions and visuals.
- Cross-attention coupling analysis: The action expert uses layer-wise cross-attention to world-model features, but there is no interpretability study (e.g., attention maps), alternative coupling mechanisms, or ablations quantifying this design choice’s contribution.
- Online adaptation stability and safety: HER + LoRA finetuning lacks discussion of safe exploration, rollback strategies, or guardrails against unsafe policies during adaptation on real hardware.
- Catastrophic forgetting and skill retention: LoRA-only updates may induce drift; the effect of online finetuning on previously mastered tasks is not evaluated, nor are strategies (e.g., replay mixing, regularization) to preserve prior competence.
- HER relabeling granularity: The online loop relabels each transition’s goal as the immediate next observation o′; it is unclear whether selecting final or subgoal states (or learned goal proposals) would yield better long-horizon credit assignment.
- Rollout selection policies: While three simple strategies (success-only, failed-only, all) were compared, more principled selection (e.g., uncertainty-based, curriculum scheduling, diversity constraints) remains unexplored.
- Success detection and metrics: The paper relies on binary success rates without success detectors or graded metrics; there is no evaluation of trajectory smoothness, accuracy relative to goal geometry, or error accumulation over long horizons.
- Generalization boundaries: OOD tests vary primarily in visuals and a few object/geometry changes; the approach’s limits under extreme domain shifts (lighting, camera placement, clutter, adversarial distractors, dynamic scenes) are not characterized.
- Goal specification practicality: The method assumes access to a precise “visual goal” image; the paper does not discuss how goals are specified in practice (e.g., partial goals, multi-goal sequences, uncertain or implicit goals) or how to generate goals when final states are unknown.
- Multi-view calibration and alignment: The architecture ingests “multi-view input frames,” yet camera calibration, synchronization, and their impact on planning accuracy are not addressed.
- Multi-robot and morphology transfer: Performance across different robot embodiments, kinematics, grippers, and control interfaces is untested; action representations’ portability is unclear.
- Failure modes and recovery: Common errors (e.g., misaligned imagined trajectories, hallucinated unreachable states, compounding errors in long tasks) are not cataloged; there are no recovery strategies (e.g., visual re-localization, waypoint re-sampling).
- Safety and ethics in autonomous improvement: The paper does not discuss operator oversight, risk mitigation, or protocols for safe autonomous adaptation in real environments.
- Theoretical grounding of MSTH: There is no formal analysis linking MSTH’s temporal hashing to performance guarantees, nor conditions under which distal anchoring improves or degrades long-horizon consistency.
- Comprehensive ablation coverage: Key components (GCWM vs. direct policy, MSTH on/off, distal-only vs. proximal-only, cross-attention depth, LoRA ranks/placement) need systematic ablations to isolate their individual contributions.
- Scalability and sample efficiency: The offline “large-scale” training lacks sample-efficiency analysis; it remains unclear how performance scales with data size, task diversity, or synthetic data generated by world models.
- Integration with language or higher-level planning: The paper removes language conditioning; potential benefits or trade-offs of combining visual goals with language (e.g., constraints, subgoal descriptions) or symbolic planners are not explored.
- Quantitative sim-to-real gap: Despite Robotwin 2.0 use, a formal sim-to-real transfer analysis (gap quantification, calibration techniques, domain randomization parameters) is missing.
Practical Applications
Immediate Applications
Below are concrete, deployable applications that follow directly from the paper’s demonstrated capabilities (goal-image control, long-horizon execution via MSTH, and reward-free, on-device HER+LoRA adaptation). Each item includes sectors, potential tools/workflows, and feasibility notes.
- Flexible insertion and assembly rework
- Sectors: manufacturing, electronics, automotive
- Potential tools/products/workflows:
- “Goal-to-Insert” cell: operator captures a target photo of a mated pair (e.g., plug seated in socket); Act2Goal generates intermediate visual states and executes insertion.
- On-robot Auto-Improve module: HER+LoRA loop runs during low-utilization periods to adapt to new part tolerances or fixtures.
- Controller plugin for common cobots (UR, FANUC, ABB) exposing a “set goal image → execute” API.
- Assumptions/dependencies:
- Adequate vision (calibrated multi-view or well-placed single view), rigid fixturing, end-effector with appropriate compliance/force limits, on-edge GPU for flow-matching inference and LoRA finetuning, safety interlocks for online learning.
- Kitting, sorting, and shelf/tote arrangement by visual reference
- Sectors: warehousing, retail logistics, e-commerce fulfillment
- Potential tools/products/workflows:
- “Pack-to-Photo” workstation: a reference photo defines final layout; Act2Goal rearranges items to match.
- Rapid SKU onboarding: capture a few goal photos per kit; HER+LoRA improves handling of packaging variations within minutes.
- Assumptions/dependencies:
- Stable lighting, reachable workspace, grippers matched to item spectrum, fallback/reset procedure for failed placements, throughput requirements compatible with inference latency.
- Food presentation and light food assembly by example
- Sectors: food service, hospitality
- Potential tools/products/workflows:
- “Plate-to-Photo” robot: use menu images as visual goals; MSTH maintains long-horizon plating sequence fidelity while reacting to slips.
- On-the-fly adaptation to new plating styles using self-relabelled rollouts (no human labels).
- Assumptions/dependencies:
- Food-safe end-effectors and surfaces, regulatory compliance (hygiene), reliable visual contrast between items and plate, limited deformable-food handling.
- Automated signage, labeling, and drawing
- Sectors: retail marketing, education, facilities
- Potential tools/products/workflows:
- Whiteboard/marker plotter: input a word or vector graphic rendered as a goal image; Act2Goal traces with stable long-horizon strokes (validated in paper).
- Site-specific fine-tuning: rapid on-device improvement for new fonts or pen-tip friction conditions.
- Assumptions/dependencies:
- Suitable pen holder, flat surface calibration, visual feedback on drawn contrast, collision-safe motion constraints.
- “Conform-to-image” quality rework and fixture resetting
- Sectors: manufacturing QA, rework cells
- Potential tools/products/workflows:
- Visual conformance step: robot nudges/rotates parts to match a golden-image pose.
- Continuous improvement loop: system learns from small misalignments with hindsight relabeling.
- Assumptions/dependencies:
- Clear visual features for pose alignment, small-force manipulation capability, robust detection of completion state.
- Home/office assist for simple object rearrangement and cable plugging
- Sectors: consumer and workplace robotics
- Potential tools/products/workflows:
- “Show-and-Do” app: user captures a target photo of a desk or cable plugged state; robot matches it.
- Periodic self-improvement: LoRA updates on-device from daily interactions, no cloud labels.
- Assumptions/dependencies:
- Safe interaction policies, confined work envelope, suitable compute on robot/base, simple end-effectors.
- Research and teaching baseline for long-horizon visuomotor control
- Sectors: academia, robotics R&D
- Potential tools/products/workflows:
- Act2Goal reference implementation to study goal-conditioned world models and MSTH temporal abstraction.
- Curriculum and benchmarks: reproduce reported Robotwin tasks; ablate MSTH and HER+LoRA to teach structured planning vs. reactivity.
- Assumptions/dependencies:
- Access to datasets or ability to collect demonstrations, compatible simulators/robots, GPU resources for training and inference.
- Developer tooling for visual-goal robotics
- Sectors: software tooling, robotics integrators
- Potential tools/products/workflows:
- Goal Studio: UI to capture/curate goal images, visualize imagined trajectories, and schedule online adaptation cycles.
- MSTH Controller Library: drop-in module exposing proximal/distal frame interfaces to existing action stacks.
- Assumptions/dependencies:
- Camera calibration pipeline, data/version management for LoRA deltas, rollback and safety gating for on-device updates.
Long-Term Applications
Below are high-impact applications that are plausible extensions of the paper’s methods but need additional research, scaling, or integrations (e.g., richer sensing, safety guarantees, dexterity).
- Dexterous, bimanual assembly and cable routing from visual goals
- Sectors: advanced manufacturing, electronics
- Potential tools/products/workflows:
- Multi-arm MSTH policies coordinating distal anchors across hands; world model augmented with haptics/force.
- Visual goal creation from CAD or AR overlays specifying multi-stage assembly checkpoints.
- Assumptions/dependencies:
- High-fidelity tactile/force feedback, precise calibration across arms, richer contact modeling, safety certification for in-hand manipulation.
- Surgical and clinical assistive robotics with image-specified outcomes
- Sectors: healthcare
- Potential tools/products/workflows:
- Goal-conditioned policies for instrument setup, draping, or standardized tray layouts; imagined trajectories vetted by clinicians.
- Online adaptation tightly sandboxed with verifiable constraints.
- Assumptions/dependencies:
- Regulatory approval (FDA/CE), formal safety/verification, sterile hardware, integration with clinical imaging and electronic records.
- Generalist home robots with “photo-as-program” interfaces
- Sectors: consumer robotics, elder care, accessibility
- Potential tools/products/workflows:
- User points phone camera at desired end state (set a table, make a bed); robot executes multi-stage plan with MSTH.
- Federated, privacy-preserving sharing of LoRA updates across households for continual improvement.
- Assumptions/dependencies:
- Robust perception in clutter, reliable grasping of varied objects, navigation + manipulation integration, privacy and safety policies.
- Construction and field operations guided by visual blueprints
- Sectors: construction, energy O&M
- Potential tools/products/workflows:
- AR/blueprint-defined goals (e.g., place anchors, route cables) translated into long-horizon action via world model forecasting.
- On-site adaptation to material and layout variability using HER-style relabeling.
- Assumptions/dependencies:
- Robust outdoor perception, 3D spatial world models, higher payload/tool diversity, compliance with site safety protocols.
- Mobile manipulation with integrated navigation and goal-conditioned control
- Sectors: warehousing, hospitals, hospitality
- Potential tools/products/workflows:
- Joint world models predicting both locomotion and manipulation states; MSTH spanning room-scale goals and fine end-effector control.
- Assumptions/dependencies:
- Unified SLAM + manipulation stack, long-horizon collision avoidance, dynamic human-aware planning.
- Tool-use generalization from visual outcomes
- Sectors: manufacturing, home, maintenance
- Potential tools/products/workflows:
- Planner that selects and wields tools (screwdrivers, spatulas) to produce a goal image, using distal frames to enforce global task structure.
- Assumptions/dependencies:
- Reliable tool perception and affordance learning, grasp/tool-change hardware, force/torque-aware control.
- Human-in-the-loop AR goal specification and verification
- Sectors: industrial HRC (human–robot collaboration), training
- Potential tools/products/workflows:
- Operators sketch desired intermediate waypoints in AR; MSTH uses them as distal anchors; on-device learning refines execution.
- Assumptions/dependencies:
- Robust AR registration, intuitive UI, latency budgets that preserve safety and responsiveness.
- Cross-modal goal setting (language-to-image-to-policy)
- Sectors: software, education, consumer
- Potential tools/products/workflows:
- LLM+image generator produces goal images from textual instructions; Act2Goal executes toward visual goals.
- Assumptions/dependencies:
- Reliable grounding to prevent ambiguous or unsafe image-goal generation, guardrails for hallucinations.
- Fleet-level, privacy-preserving continual improvement
- Sectors: platform robotics, multi-site operations
- Potential tools/products/workflows:
- Federated sharing of LoRA deltas across robots/sites; centralized validation and rollout with drift monitoring and rollback.
- Assumptions/dependencies:
- Secure update pipelines, evaluation sandboxes, policy governance and audit trails.
- Standards and policy for on-device autonomous adaptation
- Sectors: policy/regulation, safety certification
- Potential tools/products/workflows:
- Testing protocols for HER-based online learning (e.g., capped update budgets, safety envelopes, conformance tests with goal images).
- Procurement guidelines for “adaptable” robotic cells and required monitoring/telemetry.
- Assumptions/dependencies:
- Cross-industry consensus on metrics for stability, generalization, and post-update validation; incident reporting frameworks.
Cross-cutting assumptions and dependencies (common to most applications)
- Sensing: reliable monocular/multi-view cameras, calibration procedures, sufficient lighting/contrast, occasional depth sensing for occlusions.
- Hardware: end-effectors tailored to task (compliance for insertion, food-safe grippers), controllers that can stream dense proximal actions, safety interlocks and e-stop.
- Compute: on-edge GPU (or equivalent) for world-model inference and LoRA finetuning; model compression or distillation for embedded targets.
- Data/ops: mechanisms for safe online learning (buffering, goal relabeling, capped update steps, rollback), logging and evaluation harnesses, periodic human-in-the-loop resets for hard failures.
- Environment: bounded workspaces, reachable goals, manageable clutter; constraints specified when visual goals are insufficient (e.g., prohibited zones).
- Governance: privacy of captured goals and rollouts; compliance with sector-specific regulations; transparent update/version control for adapted policies.
Glossary
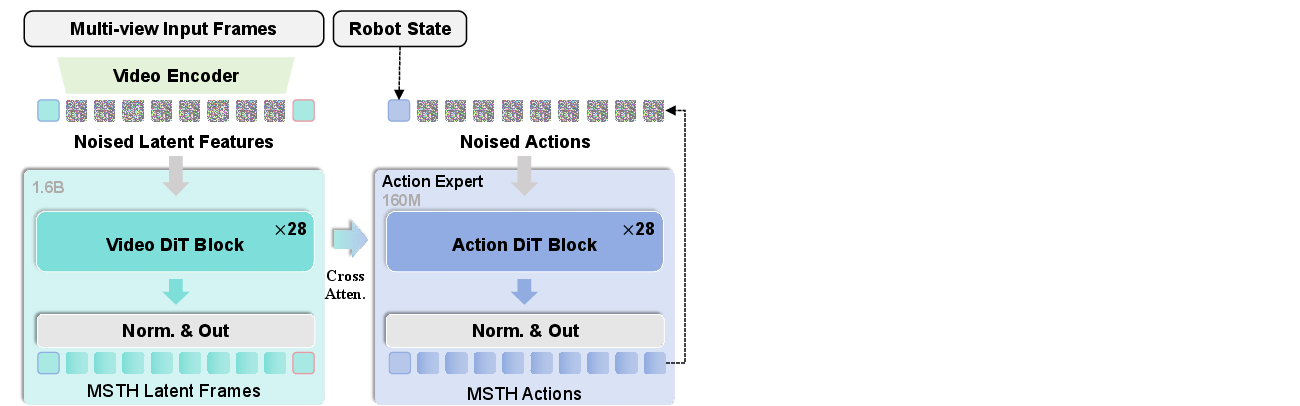
- Action expert: A policy module specialized in predicting low-level actions from state or visual features. Example: "our action expert employs a network architecture that is isomorphic to the world model"
- Behavioral cloning: Supervised learning of a policy by mimicking expert demonstrations. Example: "we employ behavioral cloning to fine-tune the entire model end-to-end"
- Closed-loop execution: Control that continually uses feedback from observations to adjust actions during task execution. Example: "reacting quickly to local disturbances during closed-loop execution."
- Cross-attention: An attention mechanism that conditions one representation on another to fuse information across modalities or layers. Example: "via layer-wise cross-attention"
- DAgger: A dataset aggregation method for interactive imitation learning that iteratively collects expert corrections. Example: "interactive imitation learning such as DAgger"
- DiT blocks: Diffusion Transformer blocks used as the backbone for video or action generation. Example: "Video DiT blocks"
- Distal frames: Sparsely sampled future visual states that provide long-horizon guidance. Example: "sparse distal frames that anchor global task consistency."
- Flow matching: A generative modeling technique that learns a vector field to transform noise into data through a continuous flow. Example: "employs a continuous flow matching approach"
- Goal-conditioned policy (GCP): A policy that maps the current state and a specified goal to actions. Example: "Goal-conditioned policies (GCPs) map the current observation and a target visual goal directly to actions"
- Goal-conditioned world model (GCWM): A predictive model that generates intermediate states leading from the current observation to a specified goal. Example: "Goal-Conditioned World Model (GCWM)"
- Hindsight Experience Replay (HER): A relabeling technique that treats achieved states as goals to learn from failures or suboptimal trajectories. Example: "Hindsight Experience Replay (HER)"
- In-context learning (ICL): Adapting behavior from examples at inference time without updating model weights. Example: "in-context learning (ICL)"
- Isomorphic (architecture): Having a network architecture with the same structural form as another model. Example: "employs a network architecture that is isomorphic to the world model"
- Latent frames: Compressed representations of visual states in a learned latent space. Example: "The completed latent frames can be decoded into visual states"
- Logarithmic spacing: A sampling strategy where indices are spaced according to a logarithmic function to cover long horizons. Example: "logarithmic spacing:"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that adds trainable low-rank adapters to freeze base weights. Example: "LoRA-based finetuning"
- Multi-Scale Temporal Hashing (MSTH): A temporal decomposition that partitions trajectories into dense proximal and sparse distal components for control and planning. Example: "Multi-Scale Temporal Hashing (MSTH)"
- Online autonomous improvement: On-device self-improvement of a policy during deployment without external supervision. Example: "online autonomous improvement"
- Out-of-domain (OOD): Test conditions that differ significantly from the training distribution. Example: "out-of-domain (OOD) scenarios"
- Proprioceptive state: Robot internal sensing of its own configuration and motion (e.g., joint angles, velocities). Example: "proprioceptive state "
- Proximal frames: Densely sampled short-horizon visual states for fine-grained control. Example: "dense proximal frames for fine-grained closed-loop control"
- Proximal horizon: The short-term window length within which dense control or prediction is performed. Example: "a proximal horizon "
- Replay buffer: A storage of collected transitions used for training or fine-tuning. Example: "replay buffer"
- SigLIP features: Visual features from the Sigmoid Loss version of CLIP used for policy conditioning. Example: "conveys the SigLIP features of both the current observation and the goal image"
- VAE-compressed latents: Encoded representations produced by a Variational Autoencoder to compress visual inputs. Example: "VAE-compressed latents of the current observation and goal"
- Vector field: The learned directional field that guides the flow-based denoising or action refinement process. Example: " is the learnt vector field that guides the denoising process"
- Visual goals: Goal specifications provided as images depicting desired end states or configurations. Example: "visual goals provide a compact and unambiguous task specification"
- Visual world model: A world model that operates on visual inputs to predict future visual states. Example: "integrates a goal-conditioned visual world model with multi-scale temporal control"
- World model: A learned model that simulates environment dynamics to predict future states. Example: "World models have become a powerful tool in robotic control"
- Zero-shot generalization: Performing well on unseen tasks or environments without task-specific fine-tuning. Example: "demonstrates strong zero-shot generalization across unseen objects, rearrangements, and environments."
Collections
Sign up for free to add this paper to one or more collections.