Divergent-Convergent Thinking in Large Language Models for Creative Problem Generation
Abstract: LLMs have significant potential for generating educational questions and problems, enabling educators to create large-scale learning materials. However, LLMs are fundamentally limited by the ``Artificial Hivemind'' effect, where they generate similar responses within the same model and produce homogeneous outputs across different models. As a consequence, students may be exposed to overly similar and repetitive LLM-generated problems, which harms diversity of thought. Drawing inspiration from Wallas's theory of creativity and Guilford's framework of divergent-convergent thinking, we propose CreativeDC, a two-phase prompting method that explicitly scaffolds the LLM's reasoning into distinct phases. By decoupling creative exploration from constraint satisfaction, our method enables LLMs to explore a broader space of ideas before committing to a final problem. We evaluate CreativeDC for creative problem generation using a comprehensive set of metrics that capture diversity, novelty, and utility. The results show that CreativeDC achieves significantly higher diversity and novelty compared to baselines while maintaining high utility. Moreover, scaling analysis shows that CreativeDC generates a larger effective number of distinct problems as more are sampled, increasing at a faster rate than baseline methods.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping AI tools (LLMs, or LLMs) make more creative and varied educational problems, especially programming tasks. The authors noticed that many AI-generated problems end up sounding very similar, which can be boring and limit students’ thinking. They propose a new way to prompt the AI, called CreativeDC, that guides the model to first brainstorm wild ideas and then carefully pick and shape one idea into a solid, useful problem.
What are the main questions?
The researchers wanted to find out:
- Can a two-step thinking process (brainstorm first, refine later) make AI-generated problems more diverse and original?
- Will these more creative problems still be useful and clear for students?
- Does this approach scale well—meaning, does it keep producing many distinct problems as you generate more and more?
How did they do it?
The core idea: Two-phase thinking
Think of creativity like building a story:
- Divergent phase: First, you brainstorm lots of unusual, surprising ideas without worrying about rules. It’s like throwing paint on a canvas to see what patterns appear.
- Convergent phase: Next, you pick the best idea and shape it carefully to fit the rules (like the required programming concept). If it doesn’t fit, you try another idea.
CreativeDC tells the AI to:
- Explore the theme freely (e.g., “Superheroes”) and list unconventional ideas.
- Choose one idea and turn it into a valid programming problem that matches the required concept (e.g., “Lists”), including a description, tests, and a solution.
They also tried “persona simulation,” which is like asking the AI to write from different points of view (wearing different “hats”) to boost variety—like thinking as a historian, a comedian, or a game designer.
What did they measure?
To judge creativity and usefulness, they used simple, practical checks:
- Diversity: How different the problems are from each other.
- Lexical (word-level) diversity: Do they use varied wording?
- Semantic (meaning-level) diversity: Do the ideas differ in substance, not just wording? They measure this by turning each problem into numbers (embeddings) and checking how far apart they are, like measuring distance between planets in space.
- Novelty: How different the problems are from problems made by other methods.
- Lexical novelty: Do the problems use fresh phrases not found in others?
- Semantic novelty: Is each problem meaningfully far from its most similar neighbor in the other methods’ outputs?
- Utility (quality): Are the problems valid, relevant to the theme and required concept, and understandable? They use a strong AI “judge” and code tests to check this.
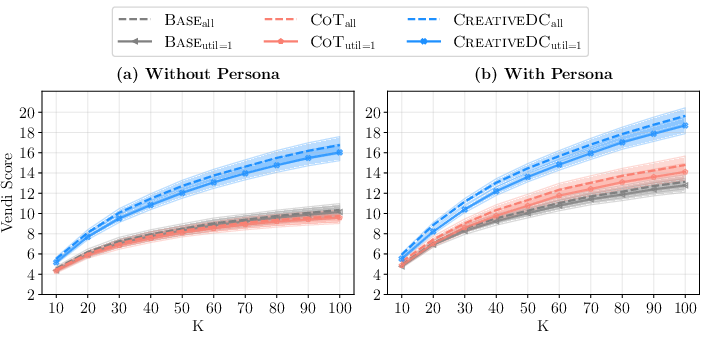
They also used a “Vendi score,” which is like asking, “How many truly distinct problems are in this set?” A higher Vendi score means more unique ideas, not just slight variations.
What did they test?
- Themes: Cooking, Science Fiction, Superheroes, Board Games.
- Programming concepts: Variables, Selection Statements (if/else), Loops, Lists, Strings.
- They generated 100 problems per theme–concept pair for each method and compared CreativeDC to two baselines: a standard prompt (“Base”) and a “think step by step” prompt (Chain of Thought, “CoT”).
What did they find and why is it important?
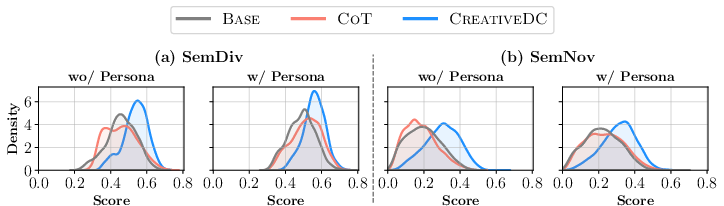
- CreativeDC made problems that were more diverse and more original than the baselines—both in wording and in meaning. This held true even without personas, and got even better with personas.
- Importantly, utility (quality and correctness) stayed high and about the same as the baselines. So the problems weren’t just weird—they were usable and clear.
- As they generated more problems, CreativeDC kept producing more truly distinct ones. Its Vendi score grew faster than the baselines, meaning it scales well for large sets of exercises.
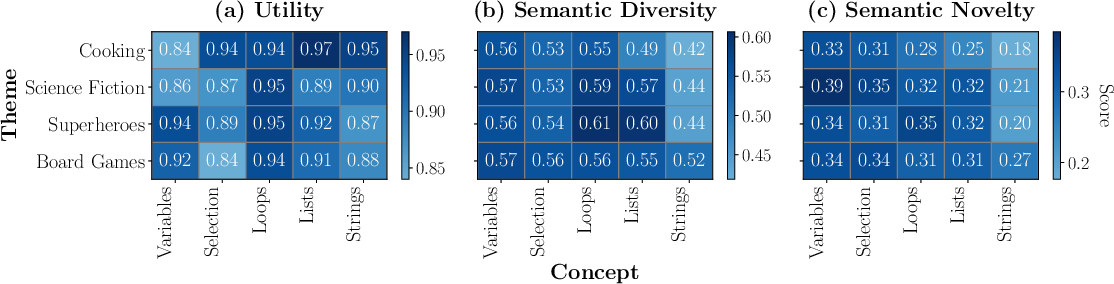
- Themes and concepts matter:
- Familiar themes like Cooking had higher utility but lower diversity/novelty (likely because they’re more constrained and predictable).
- Creative themes like Science Fiction or Superheroes boosted diversity and novelty.
- Simpler concepts (like Variables) gave more room for creativity than more complex ones (like Loops or Lists).
This is important because it shows a simple change in how we prompt AI—separating brainstorming from rule-following—can beat the “Artificial Hivemind” effect (where AIs tend to produce similar answers) and keep educational content fresh.
What does this mean going forward?
- For teachers and course creators: Using CreativeDC can help build large collections of programming problems that feel different and interesting, keeping students engaged and encouraging creative thinking.
- For AI design: Structuring the model’s thinking (first explore, then refine) can improve creativity without retraining the model or needing expensive datasets.
- Beyond programming: The same idea could help in story writing, design tasks, or art prompts—anywhere you want both creativity and usefulness.
The authors note a few next steps: test this approach on more kinds of AI models, run human studies to confirm that students find the problems creative and helpful, and try it in other creative domains.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies what remains missing, uncertain, or unexplored in the paper, framed as concrete items future researchers can address:
- Generalizability across models: The approach is evaluated with a single generator (Qwen3-235B). It is unknown whether CreativeDC’s gains hold across different architectures (decoder-only vs MoE), sizes, pretraining corpora, and RLHF alignment levels.
- Cross-model “Artificial Hivemind” mitigation: The paper cites cross-model homogeneity but measures only one generator; there is no evidence that CreativeDC reduces homogeneity across multiple LLMs used as generators.
- Domain transfer beyond programming: Applicability to creative tasks in story writing, poetry, design, or math word problems is untested; it is unclear what prompt adaptations are required, and whether gains in novelty/diversity persist.
- Human-grounded evaluation: Creativity and utility are judged primarily by automated metrics and an LLM-as-a-judge; there is no human study to validate perceived originality, educational value, clarity, and appropriateness.
- Robustness of semantic metrics: Semantic diversity/novelty rely on a single embedding model; sensitivity analyses with alternative embeddings (e.g., multilingual, code-aware, sentence vs document-level) are missing.
- Metric scope ambiguity: It is unclear which components are embedded or n-grammed (problem description only vs description+tests+solution vs reasoning traces), risking confounds if CreativeDC’s divergent/convergent traces are included.
- n-gram settings and preprocessing: The paper does not specify n values, tokenization, case normalization, or stopword handling; results may be sensitive to these choices.
- Novelty reference corpus choice: Novelty is computed against other methods’ outputs for the same context; performance against real-world corpora (e.g., public programming problem banks, textbooks) is untested.
- Utility verification rigor: “Requires only concept X” is judged by an LLM; there is no static analysis or automated code instrumentation to enforce/disallow constructs (e.g., dicts, classes), nor coverage analysis for test suites.
- LLM-as-a-judge reliability: No calibration, agreement analysis, or benchmarking of judge model decisions against human annotations; error modes (false positives/negatives in validity and context relevance) are unknown.
- Pre-filtering bias and cost: The generation consistency check discards inconsistent problems until K=100, but acceptance rates, retries, and computational cost per method are not reported; this may bias comparisons or mask efficiency trade-offs.
- Efficiency and latency: Token counts, runtime, and inference cost for the two-phase process vs baselines are not measured; real-world feasibility in classroom-scale generation remains unclear.
- Decoding hyperparameters: Only temperature=1.0 is used; interactions between CreativeDC and sampling strategies (top-k/top-p, repetition penalties) are unexplored.
- Divergent-phase design: The number, breadth, and structure of brainstormed ideas are not controlled or ablated; the impact of idea count, prompt framing, and time spent in divergence on final creativity is unknown.
- Convergent-phase selection mechanism: There is no explicit criterion or re-ranking strategy for choosing the “best” idea; integrating self-evaluation, multi-idea synthesis, or external scoring might improve outcomes, but is untested.
- Persona simulation effects: Personas are uniformly sampled, but the per-persona impact on creativity/utility is not analyzed; potential bias, stereotyping, or inappropriate content arising from certain personas is not assessed.
- Context sensitivity and control: While some themes increase novelty at the cost of utility, there is no mechanism to adjust the “creativity intensity” (a controllable knob) or to adapt prompts to specific contexts to balance the trade-off.
- Educational impact: The claim that diversity benefits learners is not empirically validated; effects on engagement, learning gains, cognitive load, and fairness are unmeasured.
- Language and platform coverage: The study focuses on Python and English; transfer to other programming languages, paradigms (functional, object-oriented), and non-English instructions/problems is untested.
- Multi-concept and complexity: Only single-concept problems are evaluated; performance on multi-concept tasks, data structures, algorithmic complexity, and open-ended project briefs is unknown.
- Safety and appropriateness: There is no analysis of potentially harmful, biased, or age-inappropriate content, especially when using personas or creative themes; content filters or guardrails are not discussed.
- Statistical reporting: Significance tests are provided, but effect sizes, confidence intervals for key differences, and corrections for multiple comparisons are absent; reproducibility of random persona sampling and seeds is unclear.
- Release and reproducibility: The paper references prompt templates, but does not state whether full code, prompts, seeds, and generated datasets are released to enable replication and independent evaluation.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s LLMs by wrapping existing generation workflows with the paper’s divergent–convergent (DC) prompting and by adopting its diversity/novelty/utility evaluation stack.
- Diverse programming exercise generation in LMS/EdTech
- Sector: education, software
- Use case: Auto-generate large, diverse sets of programming problems (description + test suite + sample solution) that practice specific concepts (e.g., loops, lists) while avoiding repetition.
- Tools/products/workflows: LTI plugin for Canvas/Moodle; GitHub Classroom and CodeRunner integration; API that returns N distinct items per concept/topic using CreativeDC; built-in utility checks via code execution and LLM-as-judge.
- Assumptions/dependencies: Access to a capable LLM and a code execution sandbox; light content review for curriculum fit; per-student data handling compliant with privacy policies.
- Question bank diversification and de-duplication audits
- Sector: education, assessment/psychometrics
- Use case: Audit existing item banks for “Artificial Hivemind” collapse; remove near-duplicates; backfill gaps with high-novelty items measured by SemDiv/SemNov and Vendi.
- Tools/products/workflows: One-click “diversity audit” dashboard; embeddings-based clustering; Vendi score targets; CreativeDC sampler to fill clusters with sparse coverage.
- Assumptions/dependencies: Embedding model availability; item ownership/IP cleared for transformation; psychometric re-calibration may be needed after edits.
- Secure multi-form exam variant generation
- Sector: education, assessment
- Use case: Create many parallel forms of the same assessment constraints to reduce item exposure and cheating risk without sacrificing utility.
- Tools/products/workflows: CreativeDC-controlled generation with utility gating (pass/fail on tests); SemNov thresholds to ensure non-overlap; export to QTI/CSV.
- Assumptions/dependencies: Human validation for high-stakes exams; policy alignment with test security standards.
- Corporate L&D technical training content
- Sector: HR/L&D, software
- Use case: Scenario-based coding katas and knowledge checks tailored to tech stacks; produce diverse practice to improve engagement.
- Tools/products/workflows: Team portal that ingests learning objectives, emits batches of varied exercises; persona augmentation to mirror different user profiles or industries.
- Assumptions/dependencies: Domain customization prompts; internal review; data governance for proprietary contexts.
- Coding challenge platforms and hackathons
- Sector: software, developer platforms
- Use case: Generate fresh, non-redundant challenges with validated tests, reducing content authoring bottlenecks.
- Tools/products/workflows: Scheduled CreativeDC jobs; novelty thresholds; automatic difficulty tagging using solution telemetry; moderation queue.
- Assumptions/dependencies: Execution sandbox; abuse/malware checks in sample solutions; fairness/clarity review.
- Instructor co-pilot for creative problem authoring
- Sector: education
- Use case: Teachers brainstorm unusual contexts in a divergent pass, then converge to a constrained, solvable exercise—mirroring the paper’s scaffold.
- Tools/products/workflows: Authoring UI that displays divergent idea lists, supports “try another idea,” and shows live utility checks; persona toggles to broaden perspectives.
- Assumptions/dependencies: Teacher time and preferences; local content standards.
- Student-facing daily practice with novelty protections
- Sector: education, consumer learning
- Use case: Personalized “problem of the day” streams that minimize repetition over weeks; track personal Vendi scores to ensure variety.
- Tools/products/workflows: Mobile/app integration; novelty budget per learner; lightweight judge model for on-device or server-side validation.
- Assumptions/dependencies: Cost controls for daily generation; safe-mode filters for themes; opt-in telemetry.
- Editorial/content teams: diversified copy within constraints
- Sector: content marketing, media
- Use case: Generate many distinct but on-brief variations (headlines, blurbs, calls-to-action) by decoupling ideation and requirement satisfaction.
- Tools/products/workflows: CreativeDC prompt wrappers for briefs; semantic novelty targets to avoid near-duplicates; A/B testing harness.
- Assumptions/dependencies: Brand safety/approval workflows; legal review for claims.
- Requirements and user-story ideation
- Sector: software/product
- Use case: Divergent exploration of solution concepts/user stories followed by convergent filtering against engineering constraints or acceptance criteria.
- Tools/products/workflows: Backlog assistant that proposes varied user stories; semantic clustering to reduce redundancy; “converge” step produces INVEST-compliant stories.
- Assumptions/dependencies: Team calibration; integration with Jira/Linear.
- Creativity metrics as a quality gate in AI pipelines
- Sector: platform engineering, MLOps
- Use case: Add SemDiv/SemNov/Vendi thresholds to CI/CD for content generation; block deploys that regress diversity/novelty; track utility rate.
- Tools/products/workflows: Embedding service; nightly regression tests; dashboard with per-batch creativity KPIs.
- Assumptions/dependencies: Stable embedding model choice; monitoring and alerting infra; acceptance thresholds tuned to domain.
- Lightweight “Diversity-as-a-Wrap” API
- Sector: software, AI tooling
- Use case: A drop-in wrapper around any LLM provider that runs the two-phase prompt, batches generation, and returns filtered, diverse outputs with metrics.
- Tools/products/workflows: REST/SDK; persona sampling; rate-limit and cost controls; retry-on-utility-fail.
- Assumptions/dependencies: Provider-agnostic prompt compatibility; token budget and latency acceptable for batch generation.
- Faculty/research lab dataset creation
- Sector: academia
- Use case: Generate creative, diverse benchmarks (e.g., programming tasks) with built-in ground truth to study LLM problem solving and creativity trade-offs.
- Tools/products/workflows: Reproducible CreativeDC scripts; published SemNov/SemDiv/Vendi statistics per release; open-source evaluation harness.
- Assumptions/dependencies: Model access; compute budget; licensing for dataset release.
Long-Term Applications
These scenarios require further validation, scaling, or standardization, but are natural extensions of the paper’s findings.
- Diversity standards for AI-generated educational content
- Sector: policy, education
- Use case: Procurement/accreditation guidelines that mandate creativity audits (e.g., minimum Vendi/SemNov) for large-scale item banks in public education.
- Tools/products/workflows: Third-party audit services; compliance reports; reference thresholds per grade/subject.
- Assumptions/dependencies: Consensus on metrics and thresholds; stakeholder adoption; fairness and accessibility reviews.
- Personalized creativity coach for learners and creators
- Sector: education, consumer apps, writing/design tools
- Use case: An interactive tutor that teaches divergent–convergent thinking by scaffolding human ideation (not just the model’s), offering novelty feedback and iteration.
- Tools/products/workflows: Mixed-initiative UI; creativity rubrics; reflections on idea breadth; gamified “novelty streaks.”
- Assumptions/dependencies: Human-subjective measures of creativity; UX research; content safety and age appropriateness.
- Cross-domain DC generation (stories, design briefs, math proofs, hypotheses)
- Sector: media, design, science
- Use case: Use CreativeDC to generate story arcs, visual briefs, proof sketches, or research hypotheses that first explore many directions before converging to constraints.
- Tools/products/workflows: Plugins for Figma/Notion/Docs; domain-specific utility checks (e.g., logical consistency, citation grounding).
- Assumptions/dependencies: Domain validators beyond code execution; stronger reasoning and fact-checking models.
- Psychometrics-aware, diversity-constrained adaptive testing
- Sector: assessment/psychometrics
- Use case: CAT systems that factor novelty/diversity when selecting items, controlling exposure while maintaining IRT properties.
- Tools/products/workflows: Dual-objective item selection (information + SemNov); post-generation calibration; secure item lifecycle pipelines.
- Assumptions/dependencies: Sufficient item volumes; rigorous calibration; regulatory acceptance.
- Agentic content factories with closed-loop creativity control
- Sector: AI platforms, EdTech
- Use case: Autonomous agents that generate, judge, execute, filter, and curate content at scale, maintaining diversity metrics over time.
- Tools/products/workflows: Multi-stage pipelines; cost-aware sampling; drift detection on diversity; human-in-the-loop escalation.
- Assumptions/dependencies: Reliable LLM-as-judge; robust sandboxing; governance to prevent error propagation.
- Creativity-aware RLHF/fine-tuning
- Sector: AI research, foundation models
- Use case: Train models to internalize DC reasoning and optimize for novelty/diversity without utility loss.
- Tools/products/workflows: Preference datasets for creativity; multi-objective RLHF; evaluation on SemDiv/SemNov/Vendi.
- Assumptions/dependencies: High-quality human preference data; careful trade-off tuning to avoid unsafe or incoherent outputs.
- Curriculum planning via “idea-space maps”
- Sector: education
- Use case: Visualize clusters/gaps in generated problems across themes/concepts; plan coverage and spiral learning with diversity-aware sequencing.
- Tools/products/workflows: Embeddings-based maps; coverage analytics; generator that targets underrepresented clusters.
- Assumptions/dependencies: Robust clustering; teacher adoption; alignment with standards (e.g., CS curricula).
- Simulation scenario generation for safety-critical domains
- Sector: robotics/autonomous driving, cybersecurity
- Use case: Generate diverse corner-case scenarios (creative adversarial situations) via divergent exploration, then converge to simulatable constraints.
- Tools/products/workflows: Scenario language templates; simulators-in-the-loop; novelty thresholds to avoid near-duplicate cases.
- Assumptions/dependencies: High-fidelity simulators; domain-specific validators; safety governance.
- Diversity certification and auditing services
- Sector: policy, enterprise compliance
- Use case: Certify vendors’ AI content for diversity/novelty/utility; periodic re-audits to prevent homogenization over time.
- Tools/products/workflows: Standard test suites; reference corpora; signed reports; remediation playbooks.
- Assumptions/dependencies: Market demand; regulator or industry body endorsement.
- Marketplace for diversity-guaranteed content packs
- Sector: EdTech, content marketplaces
- Use case: Sell vetted “problem packs” or content sets with published Vendi/SemNov scores and utility rates for transparent quality.
- Tools/products/workflows: Metadata manifests; versioning; buyer-side importers to LMS/platforms.
- Assumptions/dependencies: IP rights; shared metric standards; curation labor.
- Research benchmarks for measuring LLM creativity
- Sector: academia, AI evaluation
- Use case: Standardized tasks and metric suites for creativity that stress-test models’ tendency toward premature convergence.
- Tools/products/workflows: Public corpora; leaderboards; cross-model comparisons; ablations on DC scaffolding.
- Assumptions/dependencies: Community adoption; careful dataset design to avoid leakage.
- Organization-wide “anti-hivemind” policies for AI content
- Sector: enterprise policy
- Use case: Internal guidelines that require two-phase prompting and creativity audits for generated learning, support, or marketing content.
- Tools/products/workflows: Prompt libraries; governance checklists; periodic diversity score reporting.
- Assumptions/dependencies: Change management; toolchain integration; training for content teams.
Notes on feasibility across applications
- Model access and cost: Batch generation plus judging/embedding incurs tokens and latency; budget controls and caching are essential.
- Reliability: Utility checks (LLM-as-judge, code execution) reduce but do not eliminate errors; high-stakes use requires human review.
- Data privacy and safety: When personal or proprietary contexts are used, ensure compliant handling and robust safety filters.
- Metrics choice: SemDiv/SemNov/Vendi depend on embedding models; metric drift can occur if embeddings change—pin versions and monitor.
- Persona simulation: Improves diversity but may impact utility; tune persona mix and apply guardrails for sensitive contexts.
Glossary
- Artificial Hivemind effect: A phenomenon where LLMs produce repetitive and homogeneous outputs across prompts and models. "LLMs are fundamentally limited by the ``Artificial Hivemind'' effect, where they generate similar responses within the same model and produce homogeneous outputs across different models."
- CoT: Short for Chain-of-Thought prompting; a technique that elicits step-by-step reasoning before final answers. "The {CoT} adds a "Think step by step" instruction to the {Base} prompt."
- Convergent thinking phase: The phase where ideas are narrowed and refined to meet constraints and produce a single solution. "(2) Convergent thinking phase: narrowing down to one idea and align it with the constraints (required programming concept) in the given context."
- Cosine distance: A measure of dissimilarity between vectors based on the angle between them; used to quantify semantic differences. "To capture diversity beyond surface lexical overlap, we evaluate the semantic diversity of the set as the average pairwise cosine distance between problem embeddings."
- Cosine similarity: A measure of similarity between vectors given by their normalized dot product. "where is the cosine similarity between and ."
- Decoding temperature: A sampling parameter controlling randomness in generation; higher values increase variability. "A naive method is to use a high decoding temperature, which increases surface-level diversity but does not improve originality and can even reduce creativity~\cite{lu2024discussion}."
- Divergent thinking phase: The phase focused on generating many varied, unconventional ideas without early constraint satisfaction. "(1) Divergent thinking phase: exploring diverse and novel ideas related to the theme."
- Eigenvalues: Scalars characterizing a matrix’s linear transformation in eigendecomposition; used in diversity metrics like Vendi. "where are the eigenvalues of ."
- Functional fixedness: A cognitive bias that restricts creative use of familiar concepts or tools. "One of the reasons for this lack of creativity is ``functional fixedness,'' a cognitive bias that limits unconventional thinking."
- Gaussian kernels: Smooth bell-shaped kernel functions used in nonparametric density estimation. "Figure \ref{fig:evaluation_semantic} visualizes the distribution of per-problem scores using kernel density estimation (KDE) with Gaussian kernels, where each method's distribution is independently normalized."
- Greedy decoding: A deterministic decoding strategy that selects the highest-probability token at each step. "For utility evaluation, we use Gemini 2.5 Flash-Lite \cite{DBLP:journals/corr/abs-2507-06261} as the judge model with greedy decoding (i.e. temperature )."
- Kernel density estimation (KDE): A nonparametric method to estimate a probability density function from samples. "Figure \ref{fig:evaluation_semantic} visualizes the distribution of per-problem scores using kernel density estimation (KDE) with Gaussian kernels, where each method's distribution is independently normalized."
- LLM-as-a-judge: An evaluation paradigm where an LLM assesses outputs for quality criteria. "We evaluate utility using an LLM-as-a-judge approach by using a strong LLM to assess context relevance and comprehensibility, and generates a solution program that we execute against to verify validity, following prior work~\cite{DBLP:conf/nips/ZhengC00WZL0LXZ23,hivemind,DBLP:conf/aied/NguyenPGTS25,padmakumar2025measuringllmnoveltyfrontier}."
- Mann-Whitney U test: A nonparametric statistical test for comparing differences between two independent distributions. "In the without persona setting, {CreativeDC} achieves 16.7\% higher semantic diversity and 63.5\% higher semantic novelty than {CoT} (all p < 0.001, Mann-Whitney U test)."
- Mixture-of-experts model: An architecture that routes inputs to specialized expert subnetworks for improved capacity and efficiency. "We use an open-source model, Qwen3-235B-A22B-Instruct-2507 \cite{DBLP:journals/corr/abs-2505-09388}, a state-of-the-art mixture-of-experts model as our generation model."
- n-grams: Contiguous sequences of n items (e.g., tokens) used to analyze lexical patterns. "We measure lexical diversity as the ratio of unique -grams to the total number of -grams across the set."
- Persona augmentation: Adding persona instructions to prompts to diversify outputs. "In our experiments in Section \ref{sec:evaluation}, we conduct an experiment to evaluate the effect of persona augmentation by applying the same persona simulation to all evaluated methods."
- Persona simulation: Instructing an LLM to adopt a specific persona to influence its perspective and style. "To further enhance the diversity of generated problems, we augment {CreativeDC} with persona simulation."
- Reinforcement Learning from Human Feedback (RLHF) alignment: Training/aligning LLMs using human preference signals via RL, often leading to safer but more average outputs. "Moreover, Reinforcement Learning from Human Feedback (RLHF) alignment amplifies this convergence toward statistically average responses, reducing creativity~\cite{DBLP:conf/iclr/LuSHM0HEJCD025} and producing lower-entropy distributions~\cite{zhang2025noveltybench}."
- Semantic diversity: Variation in meaning across outputs, typically measured via embedding-space distances. "To capture diversity beyond surface lexical overlap, we evaluate the semantic diversity of the set as the average pairwise cosine distance between problem embeddings."
- Semantic novelty: The degree to which an output is semantically distinct from a reference corpus. "Semantic Novelty. To capture novelty beyond surface level, we compute the minimum cosine distance between a problem embedding and the embeddings of all problems in the reference corpus: $\text{SemNov}(\mathcal{P}, \mathcal{R}) = \min_{\mathcal{P}' \in \mathcal{R} d_{\cos}(\mathbf{e}(\mathcal{P}), \mathbf{e}(\mathcal{P}')).$"
- Vendi Score: A diversity metric equal to the exponential of the entropy of the similarity matrix’s eigenvalue distribution; interpretable as the effective number of distinct items. "We report the Vendi Score~\cite{DBLP:journals/tmlr/FriedmanD23}, which can be interpreted as the effective number of distinct problems in a set."
- Wilcoxon Signed-Rank Test: A nonparametric statistical test for paired samples to assess median differences. "In both settings without and with persona simulation, {CreativeDC} significantly outperforms all baselines on all lexical and semantic diversity and novelty metrics (all , Wilcoxon Signed-Rank Test), while maintaining utility comparable to the baselines ()."
Collections
Sign up for free to add this paper to one or more collections.