- The paper introduces an adaptive prompting strategy that incrementally processes retrieved document chunks to mitigate noise and reduce hallucinations.
- It demonstrates that a sliding window over retrieval results achieves computational efficiency (≈1.5x token reduction) while maintaining or slightly improving answer accuracy.
- Experimental results reveal the critical challenge of LLMs admitting ignorance, with unsupported answers occurring in over 50% of negative context cases.
Retrieval-Augmented Question Answering: Adaptive Prompting and the Ignorance Admission Problem
Introduction
The paper "Retrieval Augmented Question Answering: When Should LLMs Admit Ignorance?" (2512.23836) interrogates the effectiveness of long-context retrieval-augmented generation (RAG) pipelines for open-domain question answering with LLMs, focusing on the impact of context length and the critical problem of hallucination under insufficient evidence. Although expanded context windows ostensibly enable more comprehensive retrieval, the authors empirically validate that excessive irrelevant information can degrade answer quality and exacerbate model hallucinations. Addressing these limitations, the work introduces and evaluates an adaptive prompting strategy utilizing a sliding window over retrieved documents, thus restricting the injection of noise and optimizing resource efficiency.
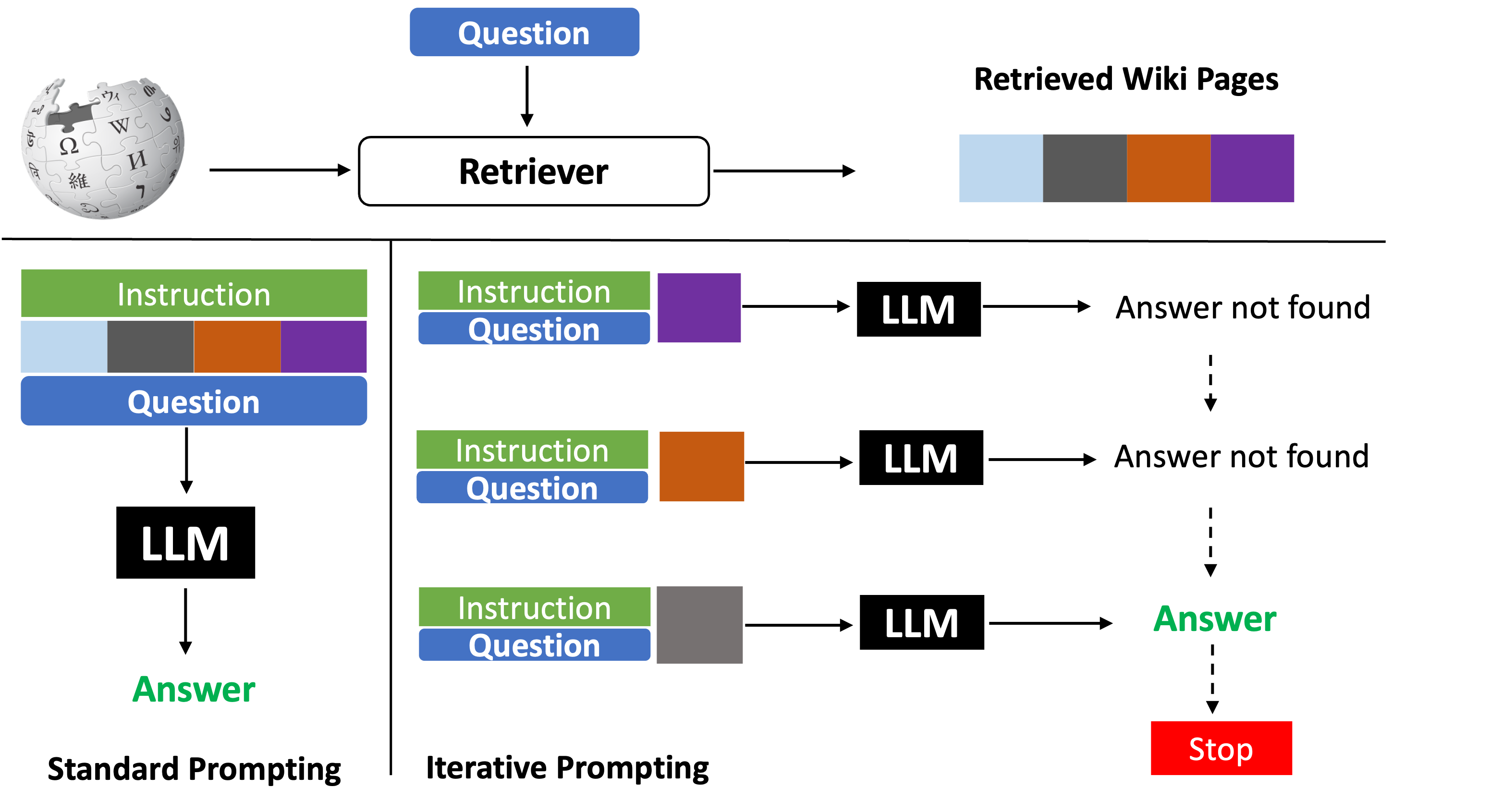
Figure 1: Architecture of standard vs. adaptive prompting strategies, illustrating full-context ingestion contrasted with sequential chunk-based inference.
Methodology
The standard RAG approach consists of retrieving top-K Wikipedia pages via BM25; these pages are collectively presented to the LLM alongside the query and system instructions, tasking the model to generate a grounded answer. As context length scales, so does the irrelevance ratio, yielding a detrimental signal-to-noise disparity. To remedy this, the adaptive prompting method segments the retrieved set into smaller windows and traverses these chunks sorted by retrieval confidence. At each iteration, the LLM is tasked to answer based solely on the limited context, either producing the answer (when sufficient evidence is found) or abstaining and advancing to the next window.
The prompts are meticulously designed, explicitly instructing the model to ground answers strictly in the provided context and to highlight the supporting passage, thus implicitly leveraging the LLM as both reranker and interpreter. The pipeline's division into positive windows (containing the relevant page) and negative windows (all irrelevant) forms the basis for subsequent evaluation of abstention and hallucination.

Figure 2: Illustration of zero-shot prompting, showing model behavior when confronted with unseen retrieval results.
Experimental Results
Empirical evaluation is performed on three open-domain QA datasets (NQ, TriviaQA, and HotpotQA) using Wikipedia as the retrieval corpus and Gemini 1.5 Pro for inference. BM25 retrieval efficacy, as measured by Recall@K, demonstrates robust coverage across all datasets, establishing a solid foundation for document selection.
Main results highlight several quantitative findings:
- The adaptive (iterative) approach matches or slightly outperforms standard fixed-K baselines, with an observed inverted-U behavior in EM as window size increases: performance peaks at moderate window size (100), but degrades when extended further (200) due to cumulative noise.
- The sliding window method achieves ∼1.5x reduction in token usage relative to standard prompting, yielding substantial computational efficiency without loss of accuracy.
- Crucially, models fail at negative window abstention: in zero-shot evaluation, Gemini 1.5 Pro outputs an unsupported answer in 54.3% of negative cases.
Sliding window directionality is pivotal: with relevant content presented first (forward sliding), the system mitigates hallucination, encountering fewer negative windows. When the context is reversed (retrieving from low- to high-confidence), the model is forced to blaze through irrelevant content, resulting in marked drops in exact match accuracy and refusal rate.
Ablation studies of window size, order, and in-context learning shot count reveal no statistically significant improvement in abstention from hallucination, even as the number of in-context negative examples increases. This observation underlines the persistence of the "answer bias" inherent in instruction-finetuned LLMs.
Discussion and Implications
These results expose a clear practical challenge: scalable retrieval-augmented QA demands not just context efficiency but reliable epistemic uncertainty calibration from LLMs. The inability to consistently admit ignorance, especially when supplied with irrelevant or insufficient evidence, implies robust refusal capability cannot be trivially imparted via prompt engineering or few-shot ICL alone. The findings call for foundational changes in modeling objectives—potentially including fine-tuning with explicit abstention signals, regularizing with synthetic negative constraints, or restructuring loss functions to penalize unsupported generations.
From an operational perspective, the adaptive prompting method presents a viable means of reducing inference cost and computational load via token economy, especially as LLMs with massive context windows become more prevalent. However, retrieval order, scorer calibration, and abstention behavior remain open research problems.
In terms of future directions, the integration of learned refusal predictors, adversarial negative sampling during pretraining, and robust uncertainty quantification may be required to reach reliable and trustworthy RAG pipelines. Exploration of cross-model differences, scaling effects, and hybrid ensemble architectures could further inform the development of epistemically sound open-domain question answering systems.
Conclusion
This paper establishes that chunked, adaptive prompting within RAG facilitates more efficient and accurate QA in LLMs while exposing the acute brittleness of current models in handling insufficient context. A persistent tendency toward hallucination and poor refusal behavior suggests abstention must be explicitly encoded in model training, not merely targeted via prompt design. Future advances in open-domain QA will require deeper solutions to the ignorance admission problem, guiding AI systems toward more trustworthy, context-aware, and computationally tractable inference.