- The paper introduces CPE, a self-supervised contrastive learning framework that mimics human skimming to efficiently capture long document context.
- It segments documents into chunks and employs an NLI-inspired contrastive loss to strengthen intra-document relationships, achieving notable gains in macro- and micro-F1 scores.
- The method reduces computational complexity and minimizes fine-tuning needs, making it a promising solution for applications in legal and medical domains.
"Skim-Aware Contrastive Learning for Efficient Document Representation"
Introduction
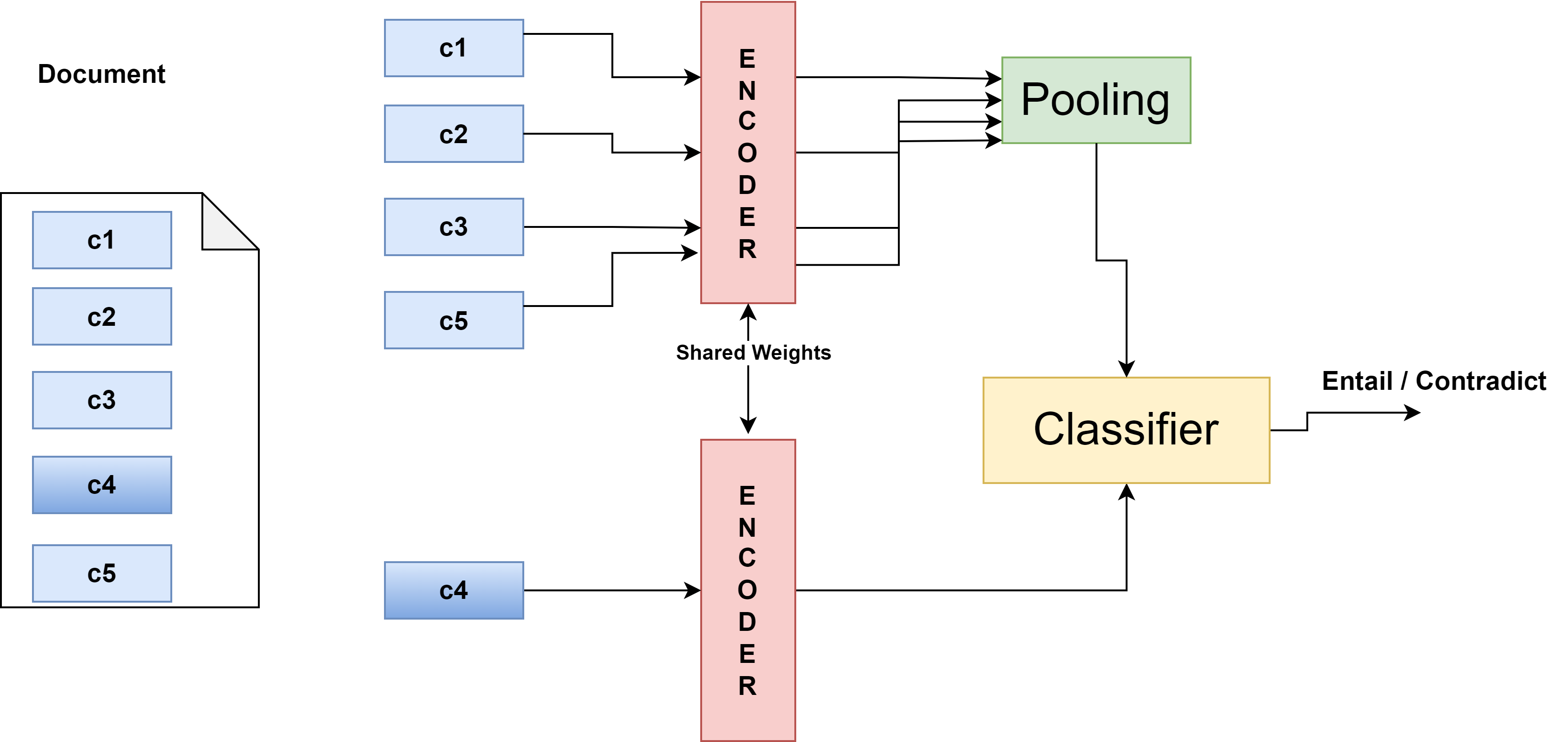
The paper "Skim-Aware Contrastive Learning for Efficient Document Representation" (2512.24373) addresses the persistent challenge of generating meaningful representations for long documents, particularly in domains like legal and medical texts. Traditional transformer-based models, although effective at word- and sentence-level tasks, struggle with long documents due to computational inefficiencies and inability to fully capture document context. This work introduces a novel self-supervised contrastive learning framework—Chunk Prediction Encoder (CPE)—designed to simulate the human approach of skimming, emphasizing important text fragments to enhance document representations.
Challenges in Document Representation
Long document representation poses significant hurdles due to the complexity and resource constraints associated with existing models. Sparse attention mechanisms, while capable of handling longer inputs, often fail to capture the nuanced context of an entire document. Hierarchical transformers offer improved efficiency but lack clarity in how they relate different document sections. The paper underscores the need for document encoders that can efficiently produce high-quality embeddings without necessitating extensive fine-tuning, a pivotal requirement in domains with specialized terminology.
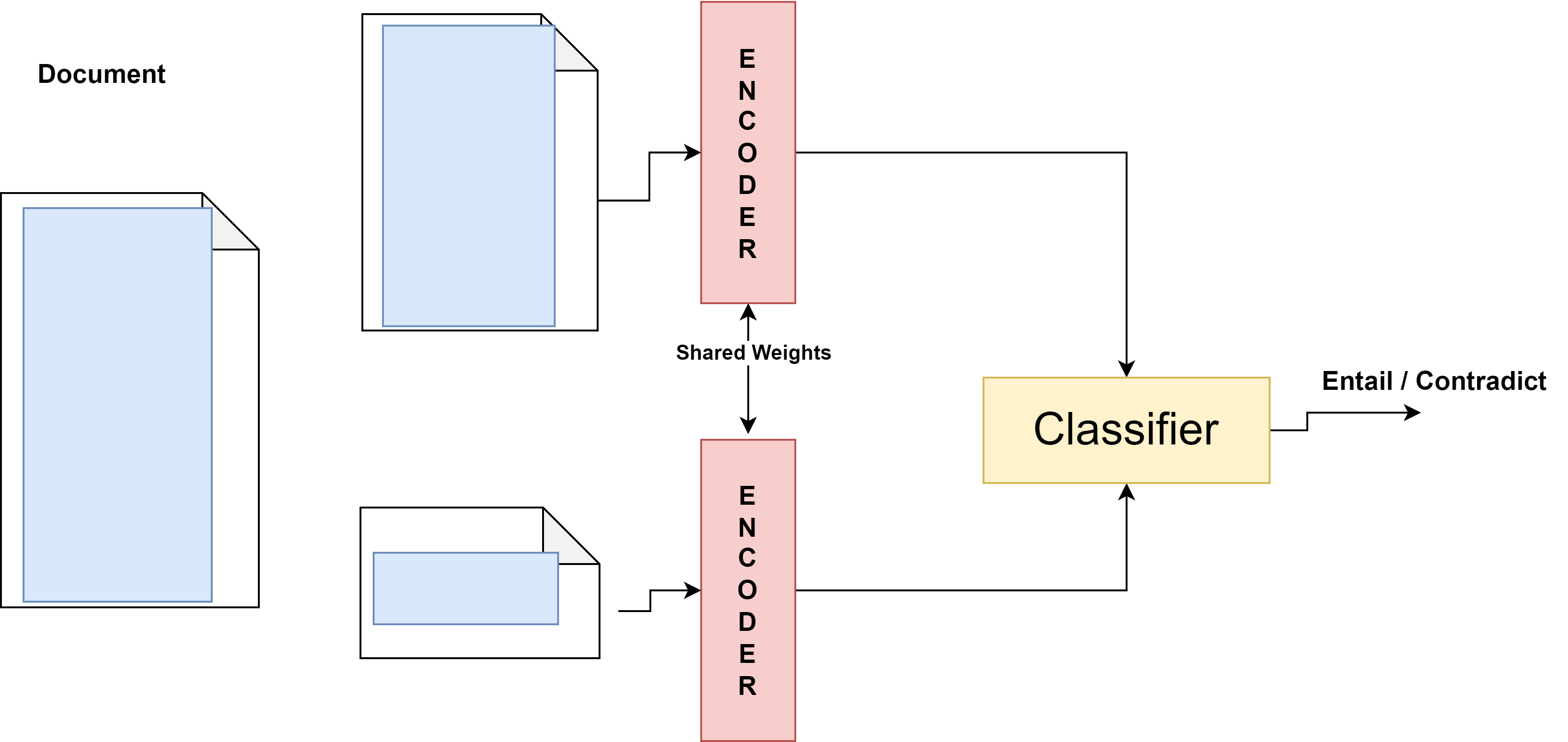
Methodology: Skim-Aware Contrastive Learning Framework
The proposed CPE framework innovatively harnesses a self-supervised learning approach by randomly masking document sections and utilizing a natural language inference (NLI)-based contrastive objective. This design aligns masked sections with relevant parts of the document while distancing from unrelated ones, thereby mimicking human skimming strategies:
Experimental Results
The framework's efficacy was validated through extensive experiments on datasets within the legal and biomedical domains:
Implications and Future Work
The findings from this study have profound implications for enhancing document understanding in specialized fields:
- Practical Application: By simplifying downstream task integration and minimizing the need for task-specific fine-tuning, the CPE framework can significantly expedite the deployment of NLP solutions in legal and medical contexts.
- Theoretical Insights: The alignment of CPE's methodology with human cognitive processes of information synthesis provides a novel perspective on machine learning strategies for document understanding.
- Future Research Directions: The exploration of CPE compatibility with multilingual and cross-domain datasets represents a promising avenue for extending its applicability. Moreover, advancing the underlying architecture to capture even deeper interconnections between document sections could further enrich document representations.
Conclusion
The paper presents a robust approach to long document representation with the introduction of the CPE framework. By adopting a contrastive learning paradigm inspired by human information-processing strategies, this research advances the capabilities of NLP models in handling extensive textual data in complex domains. The methodological innovations and empirical successes mark a crucial step towards more efficient and context-aware document representations, potentially paving the way for future developments in the domain.