Can Small Training Runs Reliably Guide Data Curation? Rethinking Proxy-Model Practice
Abstract: Data teams at frontier AI companies routinely train small proxy models to make critical decisions about pretraining data recipes for full-scale training runs. However, the community has a limited understanding of whether and when conclusions drawn from small-scale experiments reliably transfer to full-scale model training. In this work, we uncover a subtle yet critical issue in the standard experimental protocol for data recipe assessment: the use of identical small-scale model training configurations across all data recipes in the name of "fair" comparison. We show that the experiment conclusions about data quality can flip with even minor adjustments to training hyperparameters, as the optimal training configuration is inherently data-dependent. Moreover, this fixed-configuration protocol diverges from full-scale model development pipelines, where hyperparameter optimization is a standard step. Consequently, we posit that the objective of data recipe assessment should be to identify the recipe that yields the best performance under data-specific tuning. To mitigate the high cost of hyperparameter tuning, we introduce a simple patch to the evaluation protocol: using reduced learning rates for proxy model training. We show that this approach yields relative performance that strongly correlates with that of fully tuned large-scale LLM pretraining runs. Theoretically, we prove that for random-feature models, this approach preserves the ordering of datasets according to their optimal achievable loss. Empirically, we validate this approach across 23 data recipes covering four critical dimensions of data curation, demonstrating dramatic improvements in the reliability of small-scale experiments.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at how AI teams choose the best training data for big LLMs (like GPT). Because training huge models is very expensive, teams first run small “practice” trainings with tiny models, called proxy models. The problem the paper found is that these small tests can give the wrong answer if you don’t set the training settings (like learning rate) carefully. The authors show a simple fix: train the small proxy models with a tiny learning rate. Doing this makes the small tests much more reliable and better at predicting which data will work best for the big, fully tuned model.
The main questions the paper asks
Here are the key questions the authors try to answer:
- Can results from small proxy models reliably tell us which training data recipe is best for large models?
- Why do small tests sometimes disagree with what works best at full scale?
- Is there a simpler way to run small tests so they match big-model results more closely?
- Does training proxy models with a tiny learning rate keep the data rankings consistent across different model sizes?
How they approached the problem (in everyday terms)
To make this understandable, think of training a model like baking cakes:
- The “data recipe” is the mix of ingredients (which websites, how much of each domain, how much to filter or deduplicate).
- The “hyperparameters” are the oven settings (temperature, time). Different recipes bake best with different settings.
- A “proxy model” is a small oven you use to test recipes cheaply before using the big, expensive oven.
What often happens today:
- Teams use the small oven with one fixed temperature for all recipes to “be fair.”
- But different recipes really need different temperatures.
- So a recipe that looks “best” at that one temperature might not be best once you use the big oven and tune the settings properly.
The paper’s simple idea:
- When you test in the small oven, use a very low temperature (tiny learning rate) for all recipes.
- This “slow and steady” testing reduces weird effects and keeps the rankings of data recipes consistent with what you’d see after fully tuning the big oven.
What they did:
- They trained small and larger LLMs (like GPT-2, Pythia, OPT) on 23 different data recipes.
- These recipes covered different choices: mixing domains (e.g., StackExchange vs. ArXiv), filtering based on quality scores, removing duplicates, and comparing major datasets (like C4, RefinedWeb, DCLM).
- They compared how recipes ranked when using standard learning rates versus tiny learning rates, and checked if those rankings matched the big, tuned models.
- They also provided theory for a simple kind of model (a “random feature model”) showing that tiny learning rates preserve the correct ordering of datasets as models get wider.
Technical terms explained simply:
- Hyperparameters: training settings you choose (like how fast the model learns).
- Learning rate: how big a step the model takes each time it updates itself. A tiny learning rate means small, careful steps.
- Validation loss: a score showing how well the model does on data it hasn’t seen during training. Lower is better.
- Deduplication: removing repeated or nearly repeated text so the model doesn’t overfit.
- Rank correlation (Spearman): a measure of how similar two rankings are; 1.0 means the rankings match perfectly.
What they found and why it matters
Key findings:
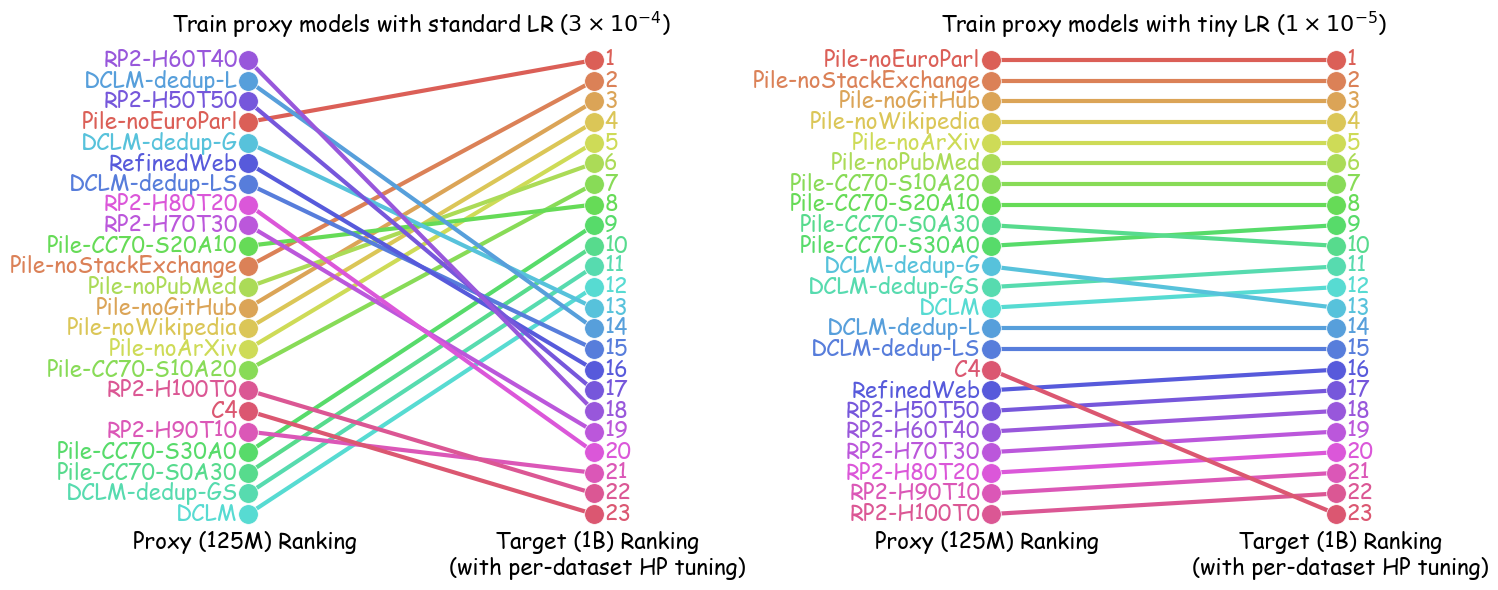
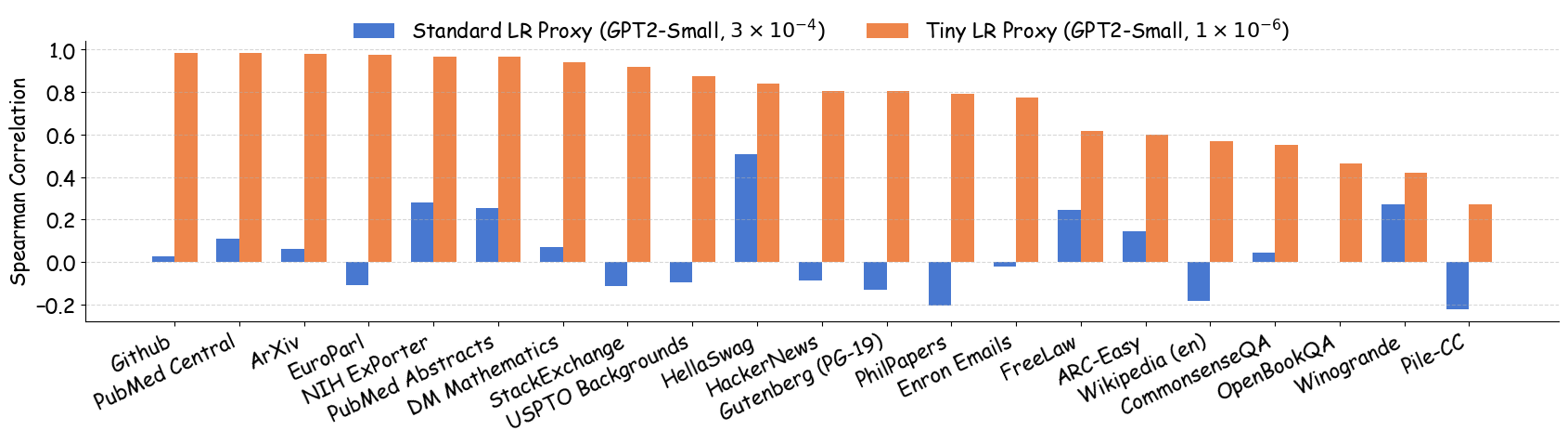
- Small changes in learning rate can flip which data recipe looks “best” in proxy model tests. That means fixed settings can give misleading results.
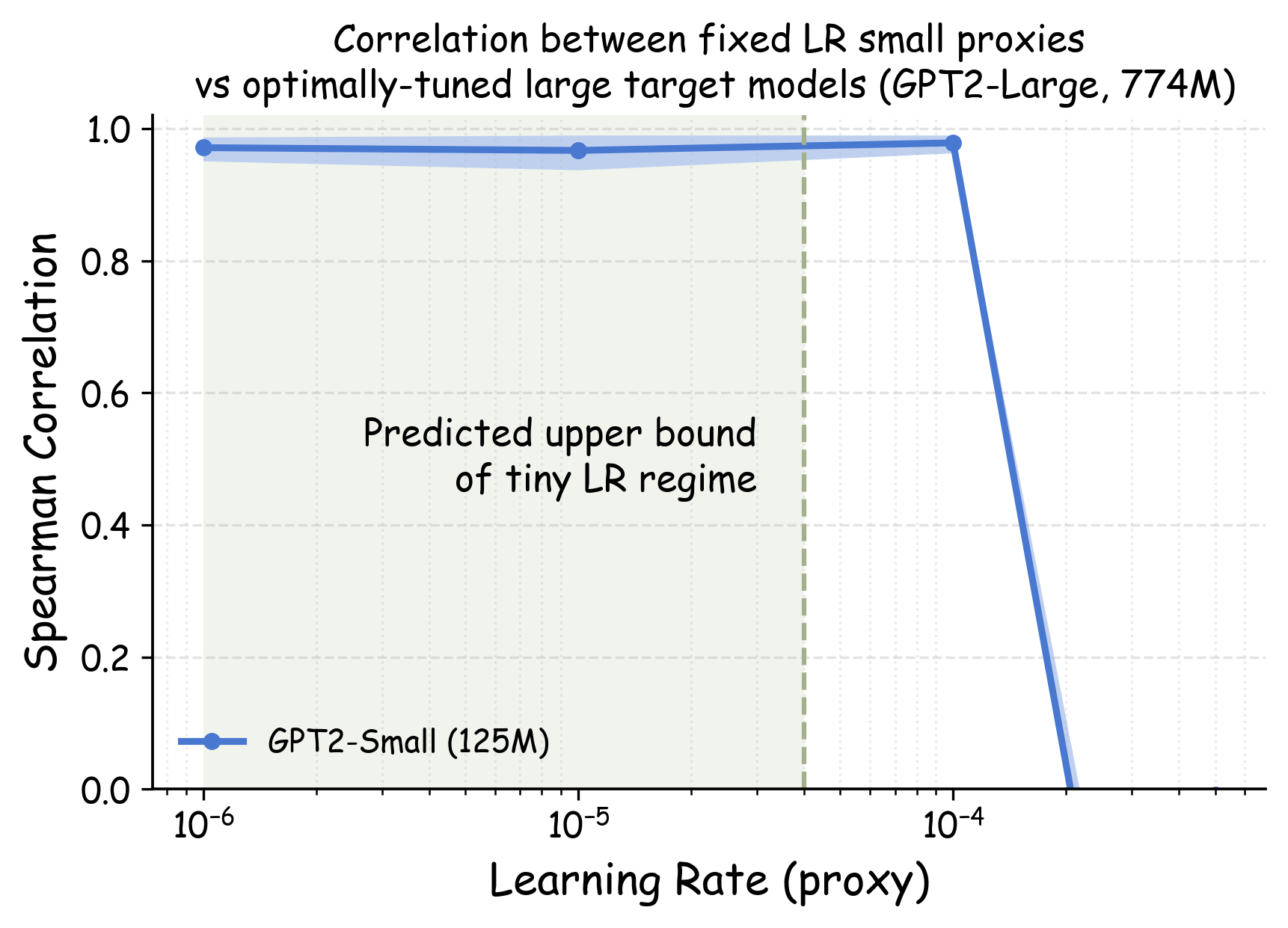
- Training proxy models with tiny learning rates (about 10⁻⁵ to 10⁻⁶) makes the rankings of data recipes much more consistent with what you get from large models after proper tuning.
- Across 23 data recipes and multiple model families (GPT-2, Pythia, OPT from ~70M to 1B parameters), tiny learning rate training produced very high agreement between small and large model rankings (often above 0.92–0.95 in rank correlation).
- In practice, this means data teams are far more likely to pick the right top candidates for full-scale training, reducing wasted time and compute.
Why it matters:
- Big AI training runs are extremely expensive. If small tests push teams toward the wrong data, that’s a huge waste.
- Using tiny learning rates in small tests helps teams quickly and cheaply identify the truly best data, even before the big model gets its own custom-tuned settings.
- The authors give both empirical evidence and theoretical support for this approach, making it a trustworthy, drop-in improvement.
What this could change in the future
Implications:
- Data teams should avoid comparing datasets with one fixed training setup. Instead, their goal should be: which dataset does best once the big model’s settings are tuned for it?
- As a practical patch, train proxy models with tiny learning rates. This simple change makes small-scale tests align much better with full-scale reality.
- Rule of thumb: use learning rates that are 10–100 times smaller than standard choices (around 10⁻⁵ to 10⁻⁶ for LLM pretraining).
- Longer term, the best solution is to jointly optimize both data and training settings together, rather than optimizing them in separate steps.
Limitations and future directions:
- The paper focuses on single-epoch (one pass) pretraining. Extending to multi-epoch or curriculum learning (changing data order over time) needs more work.
- Fully tuning everything (data plus hyperparameters) is still compute-heavy; finding efficient ways to evaluate proxy-to-target transfer would help.
In short: Small practice runs can guide big decisions—but only if done carefully. Training proxy models with a tiny learning rate is a simple, powerful way to make small tests reliably predict big-model success.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances a practical patch—training proxy models with tiny learning rates—to improve the reliability of small-scale data recipe ablations. However, several aspects remain underexplored or uncertain. Future research could address the following gaps:
- Scope beyond decoder-only LLM pretraining:
- Transferability of the tiny-learning-rate proxy protocol to encoder-only, sequence-to-sequence, and multimodal architectures (e.g., vision-language, speech).
- Applicability to downstream fine-tuning regimes (instruction tuning, RLHF, supervised tasks) where optimization dynamics and validation targets differ from pretraining.
- Training regime coverage:
- Extension from single-epoch pretraining to multi-epoch training, where repetition dynamics and curriculum effects may alter dataset rankings.
- Interaction of tiny learning rates with common production practices such as LR warmup, cosine decay, and adaptive schedules rather than fixed LRs.
- Optimizer and regularization choices:
- Robustness of the proposed ranking stability under different optimizers (AdamW vs. Adafactor vs. SGD), gradient clipping thresholds, momentum/β-parameters, and optimizer epsilons—particularly important in the tiny-LR regime where optimizer numerics can dominate updates.
- Sensitivity to weight decay, dropout, and other regularization settings beyond the limited sweeps reported in the appendix.
- Compute and efficiency trade-offs:
- Quantifying wall-clock and token-efficiency costs of tiny-LR proxy runs versus standard configurations; identifying minimal training length (steps/tokens) needed to achieve stable rankings.
- Designing efficient evaluation protocols that retain dataset-specific tuning while dramatically reducing the >20,000-run scale required in this study.
- Hyperparameter tuning realism and coverage:
- Systematic evaluation of how the choice of tuning budget, search space, and tuner (random/BO/evolutionary) influences the “ground-truth” target rankings used for correlation and regret metrics.
- Interactions between LR and batch size (e.g., linear scaling rules) and their effect on dataset ordering; whether tiny-LR rankings persist under large-batch regimes typical in frontier training.
- Theory–practice alignment:
- Extending theoretical guarantees beyond random-feature/NTK regimes to feature-learning transformers, where finite-width and representation learning are critical.
- Formalizing multi-step dynamics (beyond one-step Taylor expansion) to bound when higher-order effects invalidate the ranking stability at practical tiny LRs and training horizons.
- Defining and calibrating the “tiny LR”:
- Architecture- and scale-dependent procedures for estimating safe upper bounds on tiny LRs, including reliable Hessian approximation pipelines and accounting for mixed-precision numerics.
- Automatic selection of tiny LR per dataset/model pair without relying on heuristic ranges (e.g., 1e-5 to 1e-6).
- Validation target representativeness:
- How to choose validation sets that reflect intended downstream use (reasoning, long-context, code, multilingual), given current reliance on The Pile validation and five common benchmarks.
- Risks of domain mismatch: whether tiny-LR rankings on one validation distribution transfer to business-critical evaluation suites (e.g., instruction-following, tool use).
- Data recipe coverage and generality:
- Broader curation dimensions beyond the four studied (domain composition, filtering, deduplication, corpus choice): toxicity/safety filters, multilingual balance, document length/formatting, metadata quality, code and math data, synthetic data inclusion.
- Generalization of findings beyond Common Crawl–derived corpora (C4, DCLM, RefinedWeb) and Pile-based mixtures.
- Failure modes of tiny-LR ranking:
- Identifying datasets whose benefits manifest through feature learning or optimization-path effects that tiny LR suppresses, leading to underestimation of their true potential.
- Characterizing conditions (data heterogeneity, curvature profiles, optimizer state) under which tiny-LR rankings diverge from tuned large-scale results.
- Token-per-parameter ratio and overtraining:
- Systematic study across compute-optimal and overtraining regimes (beyond limited ablations) to test whether tiny-LR ranking stability persists with different tokens-per-parameter ratios and training lengths.
- Statistical robustness:
- Increasing seeds and reporting confidence intervals for rank correlations and regrets to assess variance due to initialization and data ordering; analyzing stability across runs beyond the 3-seed setting.
- Practical constraints and non-performance objectives:
- Integrating licensing, safety, fairness, and privacy constraints into the “high-quality dataset” definition and assessing whether tiny-LR proxies can incorporate or predict these dimensions.
- Cost-aware selection: combining performance rankings with data acquisition/storage/processing costs under realistic budgets.
- Cross-architecture transfer:
- Testing ranking stability when proxy and target architectures differ more substantially (e.g., GPT2→LLaMA-like transformer variants, different normalization layers), and with larger target scales (>1B parameters).
- Data size and sampling controls:
- Clarifying and standardizing per-recipe token budgets, sampling strategies, and domain mixing ratios to isolate curation effects from dataset size differences.
- Effects of sample repetition and dedup strategy on rankings when training spans multiple epochs.
- Alternative proxies to training:
- Evaluating whether direct data-scoring methods (e.g., gradient alignment, representational similarity, influence functions) can replace tiny-LR training while preserving rank fidelity and lowering cost.
- Benchmark standardization:
- Designing community benchmarks that allow dataset-specific hyperparameter tuning for targets (unlike fixed-config suites), with shared protocols to compare proxy methods without overfitting to one configuration.
- Numerical stability in tiny-LR regimes:
- Assessing mixed-precision (FP16/BF16) artifacts, gradient accumulation, and optimizer state drift at tiny LRs; establishing safe defaults and diagnostics to detect instability.
Glossary
- Chinchilla's compute-optimal ratio: A heuristic from the Chinchilla paper that sets the optimal number of training tokens per model parameter to maximize performance given a compute budget. "Following standard practices, we primarily set the token-per-parameter ratio to 20, adhering to Chinchilla's compute-optimal ratio \citep{hoffmann2022training}."
- data recipe ablation: An experimental procedure that compares different data curation strategies by training models on each candidate dataset and evaluating performance. "Data recipe ablation aims to identify the optimal dataset that maximizes model performance on a validation set $$."</li> <li><strong>dataset-specific hyperparameter optimization</strong>: Tuning training settings (e.g., learning rate, batch size) tailored to the particular dataset to achieve best performance. "Crucially, target models undergo dataset-specific hyperparameter optimization to align with our proposed methodology, with tuning budget held constant across all experiments."</li> <li><strong>deduplication</strong>: The process of removing repeated or near-duplicate content from datasets to improve training data quality. "DCLM-dedup-GS is a variant of the DCLM dataset constructed with more stringent deduplication thresholds (see Table \ref{table:dataset-recipes} for details)."</li> <li><strong>gradient alignment</strong>: A measure of how well gradients computed on training data align with those computed on validation data, often used to assess dataset usefulness. "When the learning rate is low, their ranking primarily depends on the first-order gradient alignment terms: $\nabla () \cdot \nabla \ell_i()\nabla () \cdot \nabla \ell_j()$."</li> <li><strong>Gradient Noise Scale (GNS)</strong>: A statistic that quantifies the stochasticity of gradients, often used to set batch size for efficient training. "For instance, GPT-3 \citep{brown2020language} determines the batch size based on the gradient noise scale (GNS) \citep{mccandlish2018empirical}, a data-specific statistic."</li> <li><strong>Hessian</strong>: The matrix of second-order derivatives of a loss function; it characterizes curvature and affects optimization dynamics. "where $H_{}$ is the Hessian of the validation loss."
- Hyperparameter optimization: The process of searching over training hyperparameters to maximize model performance. "Moreover, this fixed-configuration protocol diverges from full-scale model development pipelines, where hyperparameter optimization is a standard step."
- infinite-width limit: A theoretical regime where neural network width tends to infinity, enabling analytic characterization of training dynamics and optimal solutions. "the relative ordering of the two validation loss values at the infinite-width limit."
- kernel regression: A non-parametric regression method using kernel functions; in the infinite-width limit, certain neural models reduce to kernel regression. "In the infinite-width limit, training random feature models is equivalent to solving a kernel regression problem, and the obtained solution captures the optimal validation loss achievable within the function class."
- Neural Tangent Kernel (NTK): A kernel that describes the training dynamics of wide neural networks under gradient descent, relating them to kernel methods. "The random feature model is also closely related to the Neural Tangent Kernel (NTK), a key concept in the theory of deep neural networks that has often yielded valuable insights for developing data-centric techniques \citep{arora2019exact,wang2024helpful}."
- proxy model: A smaller, cheaper-to-train model used to estimate the relative utility of datasets for large-scale training. "A common practice to mitigate this issue involves using smaller ``proxy models" ... to predict data quality and determine which data curation recipe to use in large-scale training runs."
- random feature model: A model that uses fixed random features with a linear readout; often employed to analyze and approximate neural network behavior. "We choose the random feature model because it is one of the simplest models whose training dynamics at different learning rates and scales can be approximately characterized mathematically."
- Spearman rank correlation: A non-parametric measure of monotonic association between two rankings. "the Spearman rank correlation for data recipe rankings between GPT2-125M and Pythia-1B improved to across data recipe pairs when using a tiny learning rate () to train GPT2 instead of a commonly used learning rate ()."
- Stochastic Gradient Descent (SGD): An optimization algorithm that updates parameters using noisy gradient estimates from mini-batches. "Our theoretical analysis (detailed in Appendix \ref{appendix:eta-upper-bound}) establishes an upper bound for what constitutes a ``tiny" learning rate in the context of one-step mini-batch SGD."
- token-per-parameter ratio: The number of training tokens per model parameter, used to balance dataset size and model capacity. "Following standard practices, we primarily set the token-per-parameter ratio to 20, adhering to Chinchilla's compute-optimal ratio \citep{hoffmann2022training}."
- Top-k Decision Regret: A metric quantifying the performance shortfall when selecting the best dataset from the top-k candidates identified by a proxy, versus the truly optimal dataset. "Top- Decision Regret. This addresses the practical question: if a data team selects the top- data recipes ranked by the proxy model for full-scale evaluation, how suboptimal might their final choice be compared with the best data recipe?"
- weight decay: A regularization technique that penalizes large weights to reduce overfitting, often implemented via decoupled weight decay in optimizers. "Through sweeps of critical training hyperparameters—including batch size, weight decay, and token-per-parameter ratios—we find that dataset rankings are most sensitive to learning rate."
Practical Applications
Below is a concise mapping from the paper’s findings to practical, real-world applications. Each item names a concrete use case and includes sectors, potential tools/workflows, and feasibility assumptions.
Immediate Applications
- Tiny-learning-rate proxy protocol for data recipe ablations [Sectors: software/AI labs, cloud; Tools/Workflows: add 1e-5–1e-6 LR presets to proxy training jobs, report Spearman correlation and top-k regret; Assumptions: single-epoch pretraining, AdamW-like optimizers, validated up to ~1B params, stable numerics at 1e-5–1e-6]
- Procurement and vendor benchmarking for pretraining data [Sectors: enterprise AI, data marketplaces; Tools/Workflows: require tiny-LR proxy evaluations in RFPs, standardize validation sets and reporting templates; Assumptions: representative validation corpus, access to comparable proxy architectures]
- MLOps feature: “Proxy-eval” stage in data pipelines [Sectors: MLOps platforms; Tools/Workflows: pipeline node to auto-train a 70–125M proxy with tiny LR, rank recipes, surface top-k with confidence intervals; Assumptions: reproducible seeds, budget for 2–3 runs per recipe]
- Risk reduction in large-run scheduling [Sectors: cloud/compute management; Tools/Workflows: gate large pretraining runs on tiny-LR proxy rankings to cut wasted runs; Assumptions: proxy scale correlates with tuned target performance as in paper]
- Update academic benchmarks and leaderboards [Sectors: academia/benchmarking; Tools/Workflows: add tiny-LR condition to DataComp-LM/DataDecide-style suites, report both fixed-config and tiny-LR results; Assumptions: organizers adopt refined objective (dataset performance under dataset-specific tuning)]
- Open-source starter kits for reliable data ablations [Sectors: OSS, education; Tools/Workflows: publish minimal configs for GPT2-125M at LR=1e-6, scripts to compute rank correlations/top-k regret; Assumptions: standard token-per-parameter ratios, single-epoch runs]
- Internal governance for data quality decisions [Sectors: regulated industries (healthcare, finance), enterprises; Tools/Workflows: document “tiny-LR proxy” as required QA step before model-scale training; Assumptions: audit logs and reproducibility standards in place]
- Auditing and assurance of data selection claims [Sectors: AI assurance, third-party auditors; Tools/Workflows: independent replication of proxy rankings with tiny LR; Assumptions: access to candidate data recipes or controlled samples]
- Curriculum for data-centric AI courses and trainings [Sectors: education; Tools/Workflows: lab modules contrasting fixed-LR vs tiny-LR ablations, small-scale replications; Assumptions: modest GPU availability (e.g., single 24–48GB GPU)]
- Lightweight evaluation for sensitive or restricted data [Sectors: healthcare/biomed, finance, legal; Tools/Workflows: constrained tiny-LR proxies on de-identified or synthetic subsets to compare filters/dedup; Assumptions: privacy-compliant subsets approximate production data distributions]
- Data marketplace listing enhancements [Sectors: data platforms; Tools/Workflows: include “tiny-LR proxy performance” badge/score alongside datasets; Assumptions: common proxy baselines accepted by buyers/sellers]
- Rapid triage of curation knobs (filtering, dedup, domain mix) [Sectors: AI data engineering; Tools/Workflows: sweep curation variants, downselect via tiny-LR proxies before fine-grained HPO; Assumptions: the 23-recipe evidence generalizes to similar curation dimensions]
- Early-stop/multi-fidelity selection using tiny LR [Sectors: AutoML/MLOps; Tools/Workflows: use tiny-LR results as low-fidelity signal to prune recipes before high-fidelity tuning; Assumptions: monotone relationship holds over short training windows]
- Documentation standards for data recipe ablations [Sectors: industry/academia; Tools/Workflows: require reporting of LR, rank correlations, top-k regret, and tuned vs proxy alignment; Assumptions: community buy-in to refined objective]
Long-Term Applications
- Joint optimization of data curation and training hyperparameters [Sectors: AutoML, software; Tools/Workflows: differentiable data pipelines + gradient-based HPO/algorithm unrolling; Assumptions: scalable bilevel optimization, stable gradients through data ops]
- Standardization and policy for data selection protocols [Sectors: policy/governance; Tools/Workflows: best-practice standards mandating dataset-specific tuning objective and tiny-LR proxy baselines; Assumptions: consensus in standards bodies and major labs]
- Cross-modal expansion (vision, speech, robotics) [Sectors: vision, audio, robotics; Tools/Workflows: adapt tiny-LR proxy regimen to CLIP pretraining, ASR corpora, robot policy data; Assumptions: small-LR regime preserves rankings beyond NLP, architecture/optimizer dependencies addressed]
- Theoretical guarantees beyond random feature models [Sectors: academia; Tools/Workflows: proofs for deep transformers/CNNs, finite-width regimes, optimizer variants; Assumptions: tractable approximations, broader empirical confirmation]
- Adaptive tiny-LR selection via curvature diagnostics [Sectors: software/MLOps; Tools/Workflows: estimate Hessian top eigenvalue from short warmup to set LR << 1/λmax automatically; Assumptions: reliable online spectrum estimation, minimal overhead]
- Multi-epoch and curriculum-aware proxy design [Sectors: AI labs; Tools/Workflows: proxy subsampling that models repetition/curricula, schedule-aware tiny-LR protocols; Assumptions: principled mapping from multi-epoch dynamics to single-epoch proxies]
- Compute-efficient multi-fidelity selection with BO [Sectors: AutoML; Tools/Workflows: Bayesian optimization where tiny-LR proxy acts as a low-fidelity oracle, escalates promising recipes; Assumptions: strong correlation structure across fidelities]
- Data marketplace scoring and insurance underwriting [Sectors: finance/insurance, data platforms; Tools/Workflows: actuarial risk/pricing tied to proxy-validated data utility and uncertainty; Assumptions: accepted risk models, reliable uncertainty estimates from proxies]
- Safety and compliance reporting for foundation models [Sectors: policy/regulatory; Tools/Workflows: require reporting of data selection robustness (rank stability across LR, seeds, scales) in model cards; Assumptions: regulatory frameworks mature to recognize data-selection risk]
- Enterprise-grade proxy evaluation SDK and dashboards [Sectors: software; Tools/Workflows: packaged services for recipe registration, proxy training, rank/uncertainty analytics, auto-tuned target handoff; Assumptions: integration with major training stacks and data lakes]
- Personalized fine-tuning data selection for SMEs and individuals [Sectors: education, SMEs, daily-life developers; Tools/Workflows: tiny-LR proxies to pick best instruction/fine-tuning subsets before running LoRA/QLoRA; Assumptions: transferability extends sufficiently from pretraining to fine-tuning contexts]
- Cross-silo collaboration protocols (federated/consortia) [Sectors: healthcare, finance; Tools/Workflows: privacy-preserving tiny-LR proxy evaluations across silos to co-design shared corpora; Assumptions: secure aggregation and legal frameworks enabling cross-organization evaluation]
Notes on key dependencies across applications:
- The tiny-LR regime (typically 1e-5–1e-6) assumes AdamW-like optimizers, standard token-per-parameter ratios, and single-epoch pretraining; different architectures or multi-epoch/curriculum settings may require recalibration.
- Rank transferability has been validated up to ~1B parameters and on 23 English text recipes; generalization to larger scales, other languages/modalities, or heavily code/multilingual corpora should be re-validated.
- Validation set choice (e.g., The Pile val) must match deployment domains; domain shift can affect rankings.
- To reduce variance, use multiple seeds and report confidence intervals; ensure numerical stability for very small LRs.
Collections
Sign up for free to add this paper to one or more collections.