SynRAG: A Large Language Model Framework for Executable Query Generation in Heterogeneous SIEM System
Abstract: Security Information and Event Management (SIEM) systems are essential for large enterprises to monitor their IT infrastructure by ingesting and analyzing millions of logs and events daily. Security Operations Center (SOC) analysts are tasked with monitoring and analyzing this vast data to identify potential threats and take preventive actions to protect enterprise assets. However, the diversity among SIEM platforms, such as Palo Alto Networks Qradar, Google SecOps, Splunk, Microsoft Sentinel and the Elastic Stack, poses significant challenges. As these systems differ in attributes, architecture, and query languages, making it difficult for analysts to effectively monitor multiple platforms without undergoing extensive training or forcing enterprises to expand their workforce. To address this issue, we introduce SynRAG, a unified framework that automatically generates threat detection or incident investigation queries for multiple SIEM platforms from a platform-agnostic specification. SynRAG can generate platformspecific queries from a single high-level specification written by analysts. Without SynRAG, analysts would need to manually write separate queries for each SIEM platform, since query languages vary significantly across systems. This framework enables seamless threat detection and incident investigation across heterogeneous SIEM environments, reducing the need for specialized training and manual query translation. We evaluate SynRAG against state-of-the-art LLMs, including GPT, Llama, DeepSeek, Gemma, and Claude, using Qradar and SecOps as representative SIEM systems. Our results demonstrate that SynRAG generates significantly better queries for crossSIEM threat detection and incident investigation compared to the state-of-the-art base models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Big companies use special tools called SIEMs to watch over their computer systems. These tools collect tons of “logs” (records of what happened on computers) and help spot cyberattacks. Different SIEMs speak different “query languages,” which are like different styles of asking questions. That makes life hard for security analysts, who must learn many languages to investigate threats.
This paper introduces SynRAG, a system that acts like a universal translator. An analyst writes one simple, high-level description of a possible threat, and SynRAG automatically turns it into the right, executable query for each SIEM platform. The goal: faster, easier, and more accurate threat hunting across different tools.
What the researchers wanted to find out
- Can we let analysts describe a threat once (in plain, structured text) and automatically generate correct queries for different SIEMs?
- Can we reduce mistakes caused by AI “making things up” (hallucinations) when writing technical queries?
- Will this approach produce better, more executable queries than strong, general AI models (like GPT or Llama) working on their own?
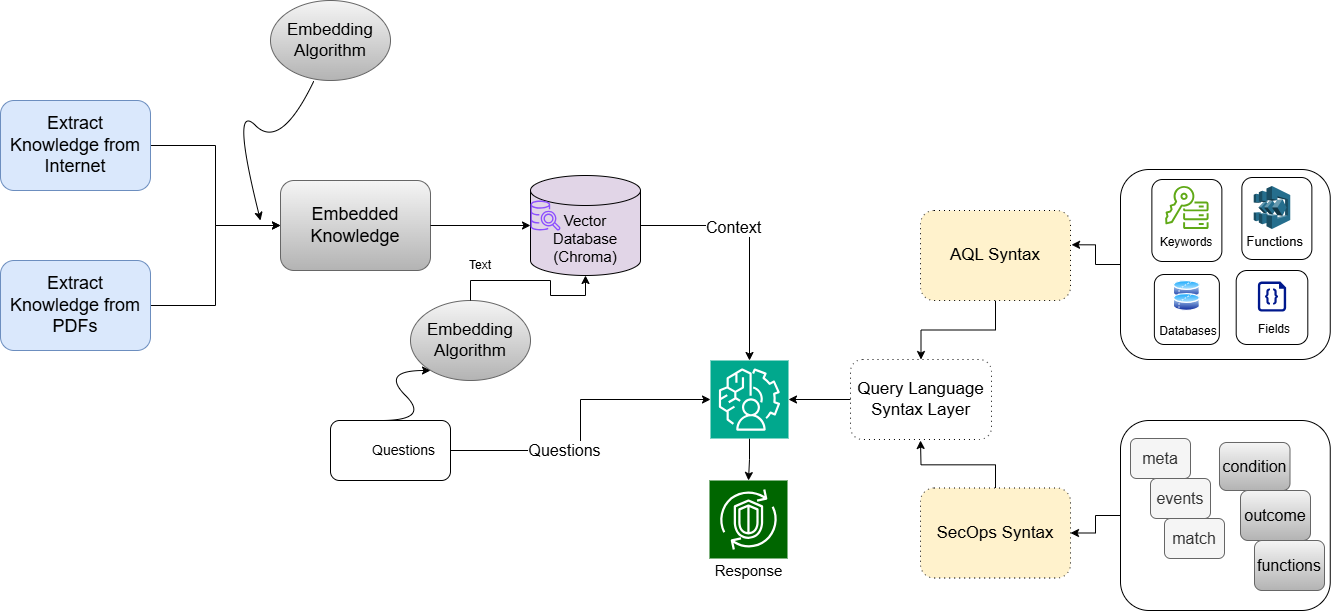
How SynRAG works (everyday explanation)
Think of SynRAG as three helpers working together: a translator, a librarian, and a grammar coach.
- The analyst writes a simple “threat recipe” in a YAML file (YAML is just a clean, human-readable list format). Example idea: “If a user tries to log in 20 times within 5 minutes during the last 5 hours, that’s suspicious.”
- The librarian part (RAG: Retrieval-Augmented Generation) looks up the official rules and examples for each SIEM’s query language. It’s like checking the manual before writing.
- The grammar coach (Syntax Service) supplies a strict list of allowed words, field names, and functions for each SIEM. This keeps the AI from inventing wrong terms.
- The translator (a LLM) uses the librarian’s notes plus the grammar coach’s allowed words to write a clean, correct query for each SIEM.
Here’s the process step by step:
- Write the threat once in YAML (what to look for, which fields matter, time windows, etc.).
- Retrieve the most relevant official docs and examples for the target SIEM (so the AI has the right “cheat sheet”).
- Enforce allowed syntax with a curated list of keywords and field names (to avoid made-up terms).
- Generate the query in the SIEM’s own language (for example, AQL for QRadar, YARA-L for Google SecOps).
- Run the queries in their platforms to check they work.
A few useful terms in plain language:
- SIEM: A security dashboard that collects and analyzes activity from computers and networks.
- Log/Event: A timestamped record of something that happened (like a login).
- Query language: The way you “ask” the SIEM to find certain events (each SIEM has its own).
- LLM: An AI that can read, write, and follow instructions.
- RAG (Retrieval-Augmented Generation): The AI first looks up trusted info, then writes—like checking a textbook before answering.
- Vector database: A smart index that helps the AI quickly find the most relevant documentation chunks, similar to a super-fast library catalog.
What they found (results in simple terms)
- SynRAG was tested against top AI models (like GPT-4o, Llama, DeepSeek, Gemma, and Claude) on creating queries for two SIEMs: QRadar (AQL) and Google SecOps (YARA-L).
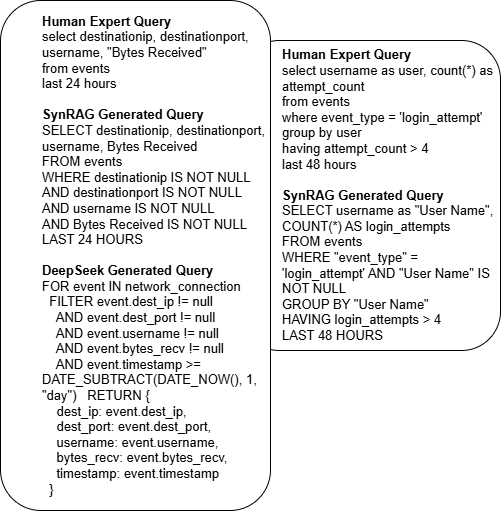
- SynRAG’s queries matched expert-written queries more closely and were more often ready to run without fixes.
- In their tests, about 85% of SynRAG’s queries ran successfully right away. The rest needed only small fixes (like adding missing quotes).
- Competing models usually needed edits before their queries would even run, often because they used wrong field names or incorrect syntax.
How they measured “goodness”:
- BLEU and ROUGE-L are scoring methods that compare the AI’s output to an expert’s version. Higher scores mean “closer match.” SynRAG scored the best across runs, showing both better structure (syntax) and meaning (semantics).
Why this matters
- Saves time: Analysts don’t need to rewrite the same idea in many different SIEM languages.
- Fewer errors: The syntax coach and the documentation lookup reduce AI mistakes.
- Easier training: New analysts can focus on “what to look for” rather than memorizing every platform’s query language.
- More consistent security: Teams can investigate threats across different systems in a unified way.
Final thoughts and impact
SynRAG shows that one clear threat description can become correct, executable queries for multiple SIEMs automatically. This can make security teams faster and more reliable, especially in big organizations that use many tools. The current version supports QRadar and Google SecOps, with plans to add more (like Splunk, Elastic, and Microsoft Sentinel). As the system expands and the library of threat descriptions grows, SynRAG could become a key tool for cross-platform security investigations.
Knowledge Gaps
Below is a concise list of knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Limited platform coverage: SynRAG currently supports only QRadar (AQL) and Google SecOps (YARA-L 2.0). It is unclear how the approach generalizes to Splunk SPL, Elastic ES|QL, Microsoft Sentinel (KQL), and other SIEMs with different grammars and data models.
- Unspecified expressiveness of the YAML specification: The paper does not define a formal schema for YAML (e.g., support for joins, multi-event sequences, correlation across sources, nested fields, windowed aggregations, subqueries, regex, custom macros/functions), leaving unclear which detection patterns can be represented.
- Field/ontology mapping is ad hoc: Guidance is limited to “closest logical match or TODO,” with no robust mechanism for reconciling differing schemas (UDM vs AQL vs Splunk CIM). A formal cross-SIEM ontology and automated field mapping are not described or evaluated.
- Lack of functional correctness evaluation: Results focus on BLEU/ROUGE-L and syntactic executability, but do not assess whether generated queries retrieve the correct events (precision/recall/F1 on ground-truth labeled logs).
- No end-to-end threat detection validation: The paper does not test whether SynRAG-generated queries detect real attacks or incidents in operational SIEM environments (e.g., controlled red-team exercises or synthetic datasets).
- Baseline fairness and ablations: It is unclear whether baselines received similar domain context (RAG) or syntax constraints. No ablation studies isolate the contribution of RAG vs syntax service vs prompt design.
- Small, non-public benchmark: The 40 YAML threat specifications are manually curated and not publicly benchmarked for diversity across ATT&CK techniques, platforms, or complexity; lack of a standardized dataset hinders reproducibility and comparison.
- Execution success rate lacks detail: The reported 85% executability lacks a breakdown by failure types, platforms, or detection categories; there is no quantitative taxonomy of errors and their root causes.
- Performance and scalability unmeasured: There are no latency, throughput, or cost measurements (API usage, retrieval time, generation time) to assess viability in real-time SOC workflows.
- Maintenance of the syntax service is manual: The curated token lists and grammar components require continuous updates as vendor languages evolve; automated grammar extraction/versioning and drift monitoring are not addressed.
- Knowledge base freshness and versioning: The RAG corpus (scraped docs/PDFs) may become stale as platforms update; no process is described for continuous ingestion, version tracking, and re-embedding with minimal operational overhead.
- Environment-specific schemas and custom fields: Enterprises often have custom event schemas and enrichment; SynRAG’s reliance on fixed allowed fields does not accommodate dynamic field discovery via SIEM APIs or per-tenant schema variability.
- Standardized output format is unspecified: The paper claims standardized results returned to analysts but does not define the schema, normalization strategy, or cross-platform result reconciliation.
- Query optimization and cost control: There is no assessment of query efficiency (index utilization, runtime, cost impact), nor guardrails to prevent resource-intensive or disruptive queries on production SIEMs.
- Robustness to ambiguous or erroneous specs: The system’s behavior on incomplete, conflicting, or poorly specified YAML inputs is not studied; no interactive error feedback or validation is described.
- Security and governance concerns: The paper does not address safeguards against unsafe queries, prompt injection, or misuse; approval workflows, audit logging, and static analysis of generated queries are absent.
- Privacy and deployment constraints: Using GPT-4o via API may raise data confidentiality concerns; options for on-prem/offline models and their performance trade-offs are not explored.
- Multilingual and non-English documentation: Retrieval and generation are limited to English; generalization to multilingual docs/specs is not discussed.
- Cross-SIEM correlation not demonstrated: While queries are generated per platform, the paper does not show unified aggregation/correlation across platforms or deduplication of events for a single incident view.
- Comparative mapping to existing DSLs: The paper does not evaluate integration with or translation from common detection languages like Sigma or vendor data models (UDM/CIM) to reduce duplication of rule authoring.
- Retrieval configuration sensitivity: The choice of embedding model, chunking (size/overlap), and top-k (e.g., 5) is not justified; no sensitivity analysis shows how these parameters affect query quality.
- Confidence and human-in-the-loop: There is no mechanism to estimate confidence/uncertainty of generated queries or to guide when human review is required; no user study quantifies analyst trust, time saved, or error reduction.
- Versioning and provenance of generated queries: The paper does not describe how queries are versioned, traced back to inputs and context, or validated over time as SIEMs and detection logic evolve.
- Rule deployment and automation: The framework addresses one-off queries but does not extend to generating and managing persistent detection rules/playbooks across SIEMs, including testing, rollout, and monitoring.
Glossary
- Ariel Query Language (AQL): The proprietary query language used by QRadar for searching and analyzing security events. "Palo Alto Networks QRadar uses AQL (Ariel Query Language) which is previously owned by IBM,"
- BLEU: An automated metric that evaluates text generation quality by measuring n-gram overlap between a generated output and a reference. "The BLEU (Bilingual Evaluation Understudy) score measures the degree of n-gram overlap between the generated query and a reference query."
- Chroma: An open-source vector database used to store embeddings for semantic retrieval in RAG pipelines. "stored in a persistent vector store using the Chroma database."
- DBpedia: A large-scale, RDF-based knowledge graph extracted from Wikipedia, commonly used in semantic web tasks. "over RDF-based knowledge graphs like DBpedia."
- Elastic Stack: A suite of tools (Elasticsearch, Logstash, Kibana) for search, analytics, and logging in IT systems. "Microsoft Sentinel and the Elastic Stack, poses significant challenges."
- ES|QL (Elasticsearch Query Language): The query language used by the Elastic Stack to search and analyze data in Elasticsearch. "Elastic Stack uses ES|QL (Elasticsearch Query Language)."
- Few-shot adaptation: A learning approach where models adapt to new tasks with minimal examples. "performs few-shot adaptation via pseudo-task creation based on question similarity."
- Google SecOps: Google’s security operations platform (Chronicle) for analyzing and investigating security events. "Google SecOps uses YARA-L 2.0,"
- Gradient updates: Parameter updates performed during optimization to minimize loss in machine learning models. "it relies on gradient updates and is less suited for real-time applications in security contexts."
- Headless Chromium: A mode of the Chromium browser that runs without a GUI, often used for automated web scraping. "launched a headless Chromium browser to extract content within the <article> tag,"
- HuggingFaceEmbeddings: A library interface for generating dense vector representations (embeddings) using Hugging Face models. "The resulting text chunks were embedded using HuggingFaceEmbeddings, configured with the pre-trained model sentence-transformers/all-MiniLM-L6-v2."
- Information retrieval: The process of obtaining relevant information from large collections of data or documents. "domains such as knowledge base question answering, information retrieval, and program synthesis."
- Knowledge base question answering: Techniques that generate answers to questions using structured or semi-structured knowledge bases. "domains such as knowledge base question answering, information retrieval, and program synthesis."
- Learning-to-rank: Machine learning methods that learn ranking functions to order items (e.g., documents) by relevance. "applies learning-to-rank strategies."
- LLM: A machine learning model trained on vast text corpora to generate and understand natural language. "The LLM models are not specially trained to generate SIEM queries."
- Meta-learning: A paradigm where models learn to learn, enabling rapid adaptation to new tasks. "Huang et al.~\cite{huang2018metalearning} developed a meta-learning-based SQL generation system, PT-MAML,"
- Microsoft Sentinel: A cloud-native SIEM and SOAR platform by Microsoft for threat detection and response. "Microsoft Sentinel and the Elastic Stack, poses significant challenges."
- Playwright: An automation library for browser-based web scraping and testing. "An asynchronous web scraping pipeline, built with Playwright, was used to extract documentation from Google SecOpsâs portal."
- Program synthesis: Automatically generating executable programs or queries from high-level specifications or natural language. "domains such as knowledge base question answering, information retrieval, and program synthesis."
- PyMuPDF (fitz): A Python library for extracting and manipulating content from PDF documents. "using a custom Python script built with the PyMuPDF (fitz) library."
- QRadar: A SIEM platform (now associated with Palo Alto Networks) used for security analytics and incident investigation. "QRadar AQL documentation in PDF format"
- RAG (Retrieval-Augmented Generation): A technique that combines external knowledge retrieval with language generation to improve accuracy. "RAG\cite{lewis2020retrieval} is a technique that enhances LLM outputs by first retrieving relevant external knowledge and then using it as context during text generation."
- RDF (Resource Description Framework): A standard model for data interchange on the web, enabling structured, linked data. "over RDF-based knowledge graphs like DBpedia."
- RecursiveCharacterTextSplitter: A document splitting strategy that creates overlapping text chunks to preserve context for embedding and retrieval. "documents were segmented using the RecursiveCharacterTextSplitter, with a chunk size of 500 characters and an overlap of 100 characters."
- ROUGE-L: An evaluation metric based on the longest common subsequence to assess semantic similarity in generated text. "ROUGE-L, on the other hand, focuses on the longest common subsequence between the generated and reference queries."
- Search Processing Language (SPL): Splunk’s query language for searching, filtering, and aggregating log data. "Splunk uses Search Processing Language (SPL),"
- Security Information and Event Management (SIEM): Centralized systems that collect, analyze, and correlate security events and logs to detect threats. "Security Information and Event Management (SIEM): SIEM is a centralized system that collects and analyzes log and event data from an organizationâs IT infrastructure."
- Security Operations Center (SOC): A team and facility responsible for monitoring, detecting, and responding to security incidents. "Security Operations Center (SOC) analysts are tasked with monitoring and analyzing this vast data to identify potential threats"
- Semantic retrieval: Retrieving documents based on semantic similarity using embeddings rather than exact keyword matches. "used to perform semantic retrieval over the Chroma vector database."
- sentence-transformers/all-MiniLM-L6-v2: A pretrained transformer model used to generate sentence embeddings for semantic tasks. "configured with the pre-trained model sentence-transformers/all-MiniLM-L6-v2."
- SPARQL: A query language for RDF data used to retrieve and manipulate information stored in knowledge graphs. "for generating SPARQL queries from natural language questions over RDF-based knowledge graphs"
- Syntax Service: A curated constraint layer that restricts generated queries to valid tokens and grammar of a target language to prevent hallucinations. "To prevent this, we introduced our Syntax Service."
- TF-IDF: A weighting scheme (term frequency–inverse document frequency) used to evaluate how important a word or phrase is in a document set. "uses tf-idf-weighted noun phrases from selected patent fields"
- Tree-LSTMs: Neural network architectures that extend LSTMs to tree-structured data for syntactic/semantic modeling. "Their approach uses Tree-LSTMs to rank candidate queries based on syntactic and semantic alignment,"
- Unified Data Model (UDM): A standardized schema used in Google Security Operations to represent event data consistently. "based on the Unified Data Model (UDM)."
- UnstructuredMarkdownLoader: A loader component that ingests Markdown documents into a processing pipeline for embedding and retrieval. "loaded using the UnstructuredMarkdownLoader module from the langchain_community.document_loaders package."
- Vector database: A database optimized for storing and querying high-dimensional embeddings for similarity search. "stored in a Chroma vector database."
- Vector store: A storage layer that holds embeddings and supports nearest-neighbor search in RAG systems. "stored in a persistent vector store using the Chroma database."
- YAML: A human-readable data serialization format often used for configurations and specifications. "SynRAG allows security analysts to define potential threat scenarios using a platform-agnostic, structured YAML specification."
- YARA-L 2.0: Google Security Operations’ query language for analyzing events in its Unified Data Model. "Google SecOps uses YARA-L 2.0,"
Practical Applications
Immediate Applications
The following applications can be deployed now using the SynRAG framework as described in the paper. They focus on QRadar and Google SecOps, leverage the YAML-based detection-as-code approach, and use the RAG plus syntax-constrained generation workflow.
- Cross-SIEM query generation assistant for SOC analysts (industry: software, finance, healthcare, energy)
- What: Convert platform-agnostic YAML detection descriptions into executable queries for QRadar (AQL) and Google SecOps (YARA-L 2.0) to support threat hunting and incident investigation.
- Tools/products/workflows:
- “SynRAG Analyst Assistant” as a web service or SIEM-side plugin to paste YAML and receive queries.
- On-demand, one-time queries for incidents; exportable runbook snippets.
- Assumptions/dependencies:
- Accurate YAML specifications; access to platform schemas/field lists; current documentation ingested into the RAG index; correct scoping of LAST/time windows; reliable LLM API access.
- MSSP multi-tenant unification of detection engineering (industry: managed security services)
- What: Standardize detection logic across diverse client SIEMs and generate platform-specific queries without deep per-platform expertise.
- Tools/products/workflows:
- Central detection YAML repository; per-client compilation job that emits QRadar/SecOps queries; batch generation for investigations.
- Assumptions/dependencies:
- Client-specific field mappings; permission to run queries across tenants; version control and change management for YAML specs.
- Detection-as-Code CI/CD pipeline (industry: software; cross-sector security teams)
- What: Treat YAML threat specifications as code; compile to SIEM-specific queries in CI and store artifacts for deployment, testing, and review.
- Tools/products/workflows:
- GitHub/GitLab pipelines; “SynRAG CLI” for compilation; query linting via the Syntax Service; pre-commit hooks to validate syntax.
- Assumptions/dependencies:
- Access to curated token sets; up-to-date platform syntax; reviewers familiar with detection semantics; test SIEM environments for validation.
- Query linting and validation in developer tooling (industry: software; education)
- What: Prevent hallucinated or invalid syntax before execution by validating against curated token lists.
- Tools/products/workflows:
- “SynRAG VS Code extension” for AQL/YARA-L linting; a local CLI for syntax checks; pre-flight validation in SOAR workflows.
- Assumptions/dependencies:
- Maintenance of syntax dictionaries; schema drift monitoring; periodic re-scraping of official docs.
- Analyst onboarding and training aids (academia; industry training)
- What: Teach AQL and YARA-L via natural language descriptions and generated queries; demonstrate correct clause order and field usage.
- Tools/products/workflows:
- Interactive notebooks/labs; curriculum modules; side-by-side human vs. SynRAG queries for learning.
- Assumptions/dependencies:
- Curated examples; safe sandboxes with sample logs; access to the knowledge base (Chroma DB) and prompt templates.
- Incident response playbook augmentation (industry: finance, healthcare, energy)
- What: Embed YAML detection steps into IR playbooks and generate ready-to-run queries during triage.
- Tools/products/workflows:
- SOAR integration to fetch YAML from a case and compile queries; ticketing system links to generated query payloads.
- Assumptions/dependencies:
- Integration with SOAR/IR platforms; authentication and RBAC to run queries; standardized result formatting.
- Compliance checks and audit queries (industry: finance—PCI DSS; healthcare—HIPAA)
- What: Rapidly generate queries to demonstrate required monitoring controls across supported SIEMs.
- Tools/products/workflows:
- Control-to-YAML mapping; “Compliance query pack” for QRadar/SecOps; scheduled audit jobs.
- Assumptions/dependencies:
- Accurate mapping of controls to data sources; environment-specific fields; legal review of data handling.
- Baseline research benchmarking for SIEM query generation (academia)
- What: Use the provided YAML specifications, prompts, and evaluation metrics (BLEU, ROUGE-L) to compare models and reproduce results.
- Tools/products/workflows:
- Public repository; small benchmark; execution validation in lab SIEMs; integrated logging for reproducibility.
- Assumptions/dependencies:
- Expanded datasets over time; consistent reference queries; availability of test SIEMs.
- SMB security uplift via assisted query authoring (industry: SMB IT; daily life for prosumer home labs)
- What: Help small teams or enthusiasts generate valid queries for supported SIEMs to investigate common threats (e.g., brute-force login).
- Tools/products/workflows:
- Lightweight local deployment; community YAML libraries; guided wizards to author detection logic.
- Assumptions/dependencies:
- SIEM access; minimal customization of field names; awareness of data privacy and credential management.
Long-Term Applications
The following applications require additional research and development, scaling to more platforms, improved datasets, and/or deeper integrations before wide adoption.
- Expansion to additional SIEM platforms (industry: cross-sector)
- What: Support Splunk SPL, Elastic ES|QL, Microsoft Sentinel KQL, and others.
- Tools/products/workflows:
- Extended Syntax Service modules per platform; automated doc scraping pipelines; schema mapping libraries.
- Assumptions/dependencies:
- Comprehensive documentation ingestion; field normalization across vendors; continuous maintenance as vendors evolve syntax.
- Unified detection marketplace and open standard (industry, policy, academia)
- What: A vendor-neutral “Detection Specification Standard” based on YAML for threat scenarios; community-curated detection libraries.
- Tools/products/workflows:
- Detection registries; governance processes; versioned schemas; peer review and provenance tracking.
- Assumptions/dependencies:
- Standards body sponsorship (e.g., NIST/ISO); stakeholder buy-in from SIEM vendors; licensing and IP considerations.
- Automated execution, normalization, and triage (industry: MSSP, enterprise SOC)
- What: Move from “generate query” to “execute, normalize to a common schema, rank risk, and enrich with context.”
- Tools/products/workflows:
- Orchestration service with secure connectors; UDM/adaptor layer; risk scoring and enrichment (e.g., threat intel); dashboards with cross-SIEM results.
- Assumptions/dependencies:
- Secure credentials and RBAC; performance and cost controls; robust UDM merging; standardized result schemas.
- Persistent rule and alert generation (“compile-to-rules”) (industry: finance, healthcare, energy)
- What: Convert YAML detection logic into deployable rules/alerts within each SIEM, including thresholds, windows, and suppression logic.
- Tools/products/workflows:
- Rule deployment pipelines; canary testing/simulation; drift monitoring; rollback mechanisms.
- Assumptions/dependencies:
- False-positive/frequency controls; sandbox validation; vendor-specific APIs for rule management.
- Cross-SIEM correlative analytics and fusion (industry: large enterprise, MSSP)
- What: Correlate signals across platforms to reduce blind spots and improve MTTD/MTTR.
- Tools/products/workflows:
- Data lake or XDR layer; cross-platform entity resolution; temporal correlation engines fed by normalized query outputs.
- Assumptions/dependencies:
- Consistent entity schemas; data sharing agreements; performance tuning to avoid alert storms.
- ChatOps-integrated SOC assistant with guardrails (industry: software; cross-sector)
- What: Slack/Teams bots that turn natural language detection descriptions into vetted queries, run them, and summarize findings.
- Tools/products/workflows:
- Policy-aware prompt templates; gated execution (approval workflows); audit logs of generated/ran queries.
- Assumptions/dependencies:
- Strong guardrails to mitigate hallucinations; rate-limited APIs; privacy and compliance controls.
- Expanded public benchmarks and competitions (academia)
- What: Large-scale, multi-platform datasets for query generation; leaderboards and shared baselines.
- Tools/products/workflows:
- Community contributions; challenge tracks (syntax accuracy, execution success, detection efficacy); standardized scoring beyond BLEU/ROUGE-L (e.g., executable correctness, precision/recall on labeled log sets).
- Assumptions/dependencies:
- Anonymized logs for research; ethical data sharing; funding and hosting.
- Policy frameworks for interoperable detection-as-code (policy; industry)
- What: Guidance and best practices for vendor-neutral detection portability, auditability, and lifecycle management.
- Tools/products/workflows:
- Compliance mappings (PCI, HIPAA, SOC 2, NERC CIP); change-control policies for YAML specs; mandatory test gates.
- Assumptions/dependencies:
- Coordination among regulators and vendors; templates for sector-specific controls.
- Application to adjacent domains (industry: cloud, endpoint, OT/ICS)
- What: Generate queries for cloud and endpoint analytics (e.g., KQL for Azure Sentinel, CloudWatch Logs Insights, EDR telemetry queries) and industrial telemetry.
- Tools/products/workflows:
- New syntax modules; cross-domain field mapping; enrichment connectors (IAM, asset inventory).
- Assumptions/dependencies:
- Broad documentation and schema availability; considerable domain ontologies; vendor API stability.
- Workforce optimization and role redesign (industry: MSSP, enterprise SOC)
- What: Reduce deep per-platform specialization needs; create “detection designers” who write YAML while tools compile and validate across SIEMs.
- Tools/products/workflows:
- Updated job descriptions; training centered on detection semantics; metrics for productivity and error rates.
- Assumptions/dependencies:
- Trust in automation; robust QA pipelines; continuous improvement programs.
- Continuous validation and safety guardrails (industry, academia)
- What: Systematically measure “executable success rate” and detection efficacy; integrate simulation and canary tests.
- Tools/products/workflows:
- Sandboxed SIEMs with synthetic logs; scenario catalogs; automated regression testing on syntax and semantics.
- Assumptions/dependencies:
- Investment in test infrastructure; high-quality synthetic datasets; disciplined release management.
Collections
Sign up for free to add this paper to one or more collections.