- The paper introduces a modular framework leveraging LLM-coordinated tool learning to enhance audio processing efficiency.
- It details a Model Context Protocol that standardizes tool management, ensuring seamless integration and scalable execution of diverse audio tasks.
- Empirical demonstrations in music creation, speech editing, and multimodal processing attest to AudioFab’s versatility in real-world applications.
Introduction
AudioFab introduces a modular, extensible framework for unified audio processing, leveraging LLMs orchestrated via tool learning. The work addresses shortfalls in prior audio agent systems—particularly limited coverage, brittle extensibility, and inefficient tool selection—by integrating a modular architecture and a specialized tool learning process. The toolkit supports a diverse range of tasks in speech, sound, and music, under a user-friendly natural language interface, positioning itself as a comprehensive solution for both non-experts and AI researchers in the audio domain.
Framework Architecture and Modular Design
AudioFab's architecture is underpinned by the Model Context Protocol (MCP), which disentangles user interactions, LLM planning, tool management, and execution into standardized, independently managed modules. The MCP Client/Server paradigm mediates between users, the LLM planner, and the tool execution environment. Each tool is isolated in its dependency environment using containerized solutions (e.g., Conda, Docker), which eliminates compatibility issues and eases the proliferation of new or updated tools in the system.
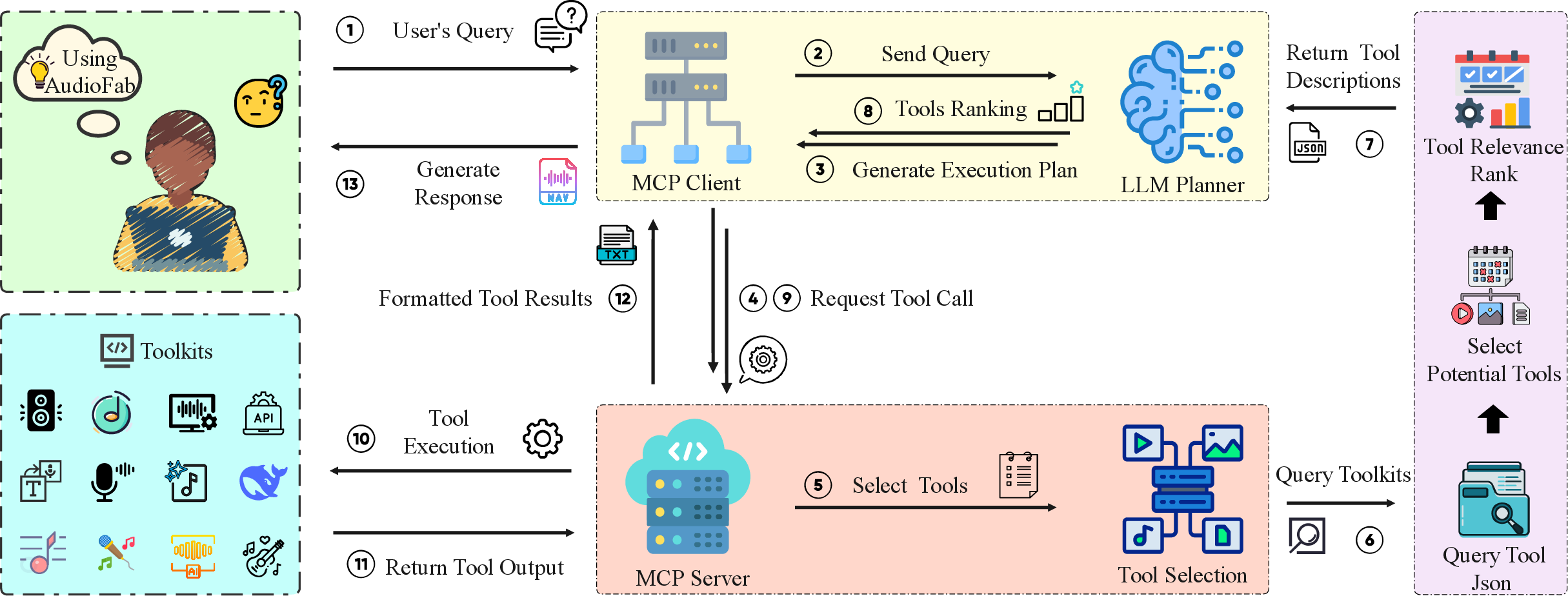
Figure 1: The AudioFab pipeline connects a modular set of audio tools to end-users, orchestrated by a LLM-centric planning and execution loop.
This modularity is not merely architectural; it enables developers to expand or substitute audio tools with minimal friction, supporting robust adaptation to the fast-evolving landscape of audio AI models and algorithms.
The tool learning protocol in AudioFab orchestrates the full lifecycle of complex audio tasks via LLM-guided planning, tool selection, invocation, and response synthesis. It embodies a four-stage process:
- Task Planning: The LLM decomposes natural language user commands into structured workflow steps, leveraging specialized prompts and real-time feedback tailored to the audio modality for robust task decomposition and planning.
- Tool Selection: Using semantic retrieval over a curated tool description set (with few-shot example augmentation), the system reduces contextual overhead in the LLM, minimizing both tool and task hallucination. Each tool's invocation schema is injected just-in-time, optimizing inference efficiency.
- Tool Invocation: Tools are executed in isolated environments, ensuring reproducibility and scalability. The LLM constructs structured invocation requests, which are dispatched by the MCP Server to the appropriate runtime containers. Result aggregation occurs post-execution.
- Response Generation: Tool outputs are collected and synthesized by the LLM to yield user-facing results, closing the loop end-to-end from query to outcome.
This approach explicitly mitigates issues endemic to prior frameworks—specifically, token inefficiency and context overload—by minimizing loaded tool contexts and leveraging dynamic retrieval conditioned on the planned workflow.
Functional Coverage and Usability
AudioFab’s tool library supports 36 audio techniques encapsulating editing, understanding, and generation tasks. Task coverage is broad, spanning speech enhancement, speech emotion recognition, music separation, style transfer, text-to-audio, audio-conditioned video/image generation, and more. The framework operationalizes both classic DSP routines and cutting-edge generative models, orchestrating them into complex multi-stage workflows.
The library is managed with a modular registry that allows plug-and-play extension—the user or developer can augment or swap tool backends by modifying a tool manifest (described in a simple JSON structure), without altering the agent core.
For non-expert users, the natural language interface delivers complex functionality with significantly lower barriers to entry than prior audio processing solutions, democratizing access to advanced multi-stage pipelines.
Empirical Demonstrations
Lacking a universally-accepted audio tool agent benchmark, the authors validate AudioFab via three representative application scenarios: music creation, speech editing, and multimodal interaction (audio-driven cross-modal generation).
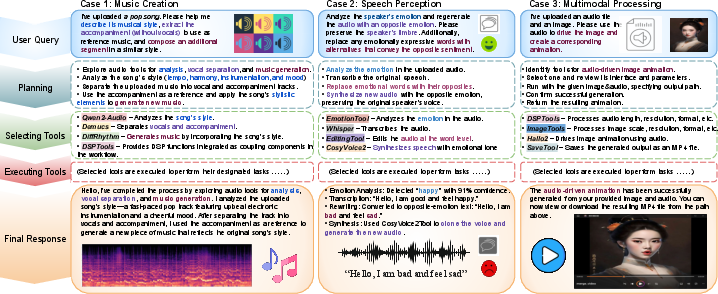
Figure 2: Prototypical workflows for (1) music creation, (2) speech editing, and (3) multimodal audio-visual interaction—demonstrating end-to-end plan generation, tool orchestration, and output synthesis.
- Music Creation: AudioFab analyzes style, separates stems, and generates AIGC-driven musical variants.
- Speech Editing: Complex emotional transformations are performed, including recognition, content editing, and voice re-synthesis preserving speaker attributes.
- Multimodal Processing: The system orchestrates cross-modal animation, matching image transformation to audio dynamics and generating video outputs.
These demos establish AudioFab’s practical versatility and seamless support for real-world audio and multimodal research tasks.
Implications and Forward Directions
The core implication of AudioFab is the establishment of a scalable, open-source substrate for the next generation of intelligent audio agents. For practical applications, it offers a frictionless integration of state-of-the-art models—covering not only basic DSP but also advanced audio generation and understanding—in a form accessible both to end-users and system developers. The theoretical framework for tool learning presented here points towards LLMs operating as general controllers, capable of meta-reasoning over environments of specialized expert models.
Looking forward, the stated roadmap includes constructing systematic benchmarks and leaderboards—filling a major gap in standardizing evaluation for audio agent frameworks and facilitating reproducible, competitive research in agent-based audio AI.
Conclusion
AudioFab delivers a technically rigorous, modular foundation for intelligent audio processing, centered on LLM-coordinated tool learning and extensible module management. By systematically overcoming the recurrent limitations of previous agent frameworks—context bloat, fragile extensibility, and lack of generality—AudioFab emerges as a platform likely to shape the research and deployment trajectory for general-purpose, audio-centric, and multimodal AI agents. Future developments centered on benchmarking and leaderboard infrastructure are poised to further consolidate and drive progress in this rapidly evolving research area (2512.24645).