AstroReview: An LLM-driven Multi-Agent Framework for Telescope Proposal Peer Review and Refinement
Abstract: Competitive access to modern observatories has intensified as proposal volumes outpace available telescope time, making timely, consistent, and transparent peer review a critical bottleneck for the advancement of astronomy. Automating parts of this process is therefore both scientifically significant and operationally necessary to ensure fair allocation and reproducible decisions at scale. We present AstroReview, an open-source, agent-based framework that automates proposal review in three stages: (i) novelty and scientific merit, (ii) feasibility and expected yield, and (iii) meta-review and reliability verification. Task isolation and explicit reasoning traces curb hallucinations and improve transparency. Without any domain specific fine tuning, AstroReview used in our experiments only for the last stage, correctly identifies genuinely accepted proposals with an accuracy of 87%. The AstroReview in Action module replicates the review and refinement loop; with its integrated Proposal Authoring Agent, the acceptance rate of revised drafts increases by 66% after two iterations, showing that iterative feedback combined with automated meta-review and reliability verification delivers measurable quality gains. Together, these results point to a practical path toward scalable, auditable, and higher throughput proposal review for resource limited facilities.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces AstroReview, an AI-powered helper that reads and judges telescope proposals—documents scientists write to ask for time on big telescopes. Because telescopes are very popular and time is limited, many proposals compete for a few spots. AstroReview aims to make the review process faster, fairer, and more consistent, and to help authors improve their proposals before they submit them.
What questions are the researchers trying to answer?
The paper focuses on three simple questions:
- Can AI help review telescope proposals in a way that is trustworthy and transparent?
- Can AI give useful feedback that actually helps authors make their proposals better and more likely to be accepted?
- What is a good step-by-step setup (a “workflow”) for using AI safely, so it doesn’t make things up and it explains its reasoning?
How does the system work?
AstroReview is a “multi‑agent” system. Think of it like a team of specialized AI helpers, each with one job. Keeping jobs separate helps prevent mistakes and makes the reasoning easier to follow.
The system works in three stages:
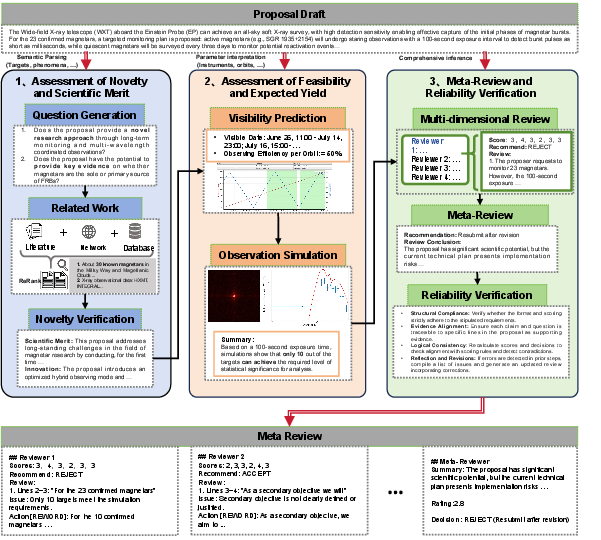
- Stage 1: Novelty and scientific value
- The AI checks if the idea is truly new and meaningful. It pulls out the key goals, searches papers and databases, and asks questions like: “Has this already been done?” and “Does this add something important?”
- Stage 2: Feasibility and expected results
- The AI looks at the practical plan: are the targets visible when needed, are the instrument settings sensible, and will the observations likely produce clear, useful data?
- Stage 3: Meta‑review and reliability check
- Multiple “reviewer” AIs score the proposal on clear criteria (like impact, uniqueness, and feasibility). A “meta‑reviewer” then combines their opinions into one final decision with reasons. Finally, a “reliability checker” looks for errors or unsupported claims and fixes them.
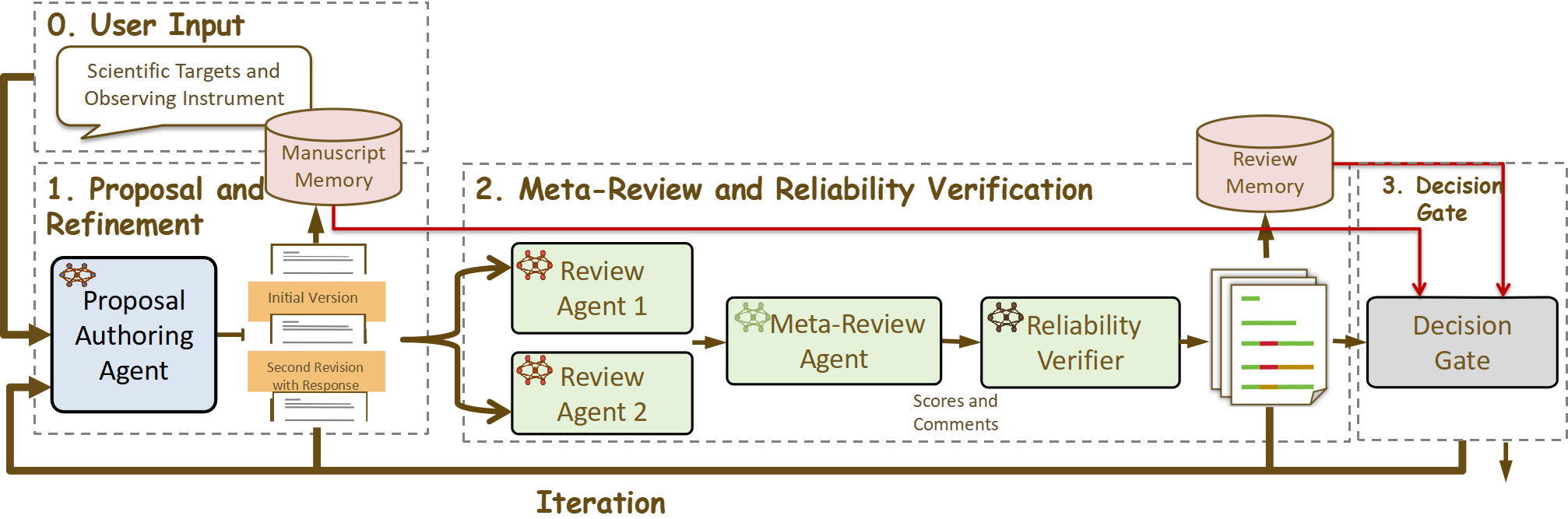
There’s also an “in action” loop that mirrors how real scientists revise their work. A “Proposal Authoring Agent” (an AI writing helper) rewrites the proposal using the reviewers’ comments, then the reviewers check it again. A “Decision Gate” stops the loop when changes are too small to matter, so time isn’t wasted.
Important note about the experiments: because full proposals (especially rejected ones) are rarely public, the tests were done using only proposal abstracts (short summaries) from accepted Hubble Space Telescope applications. That means Stages 1 and 2 couldn’t be fully tested on real data, so the paper mainly evaluates Stage 3 (the reviewing and reliability steps) and the revise‑and‑review loop.
What did they find, and why does it matter?
Here are the main takeaways:
- The reviewing stage worked well on real accepted proposals:
- Using no special training, the review setup correctly recognized truly accepted proposals 87% of the time. That suggests the AI’s reviewing decisions can align with human panels.
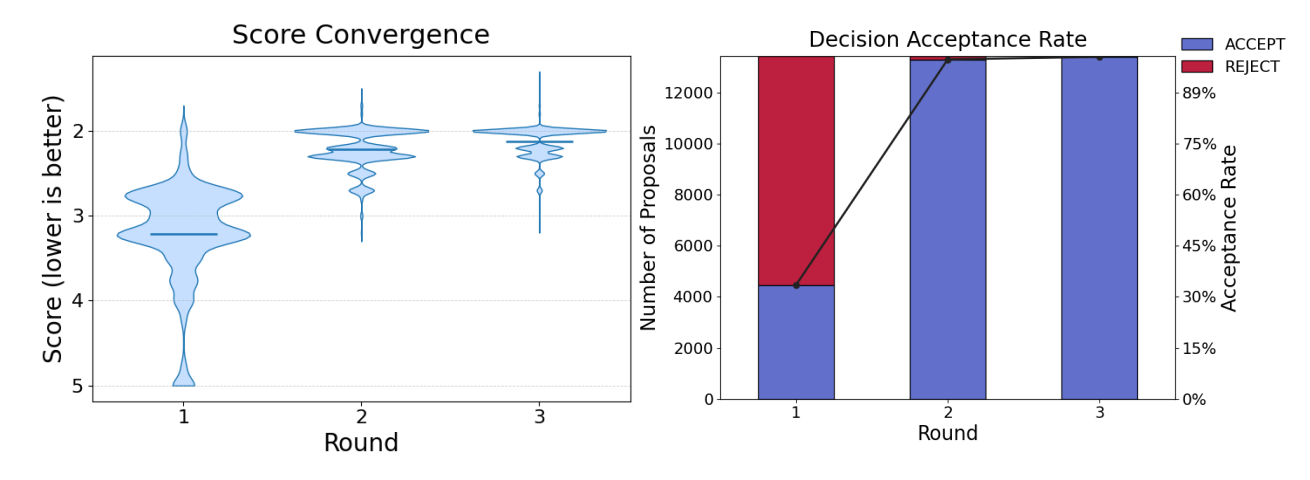
- Feedback led to big improvements when proposals were revised:
- When the Authoring Agent rewrote drafts using the reviewers’ comments, acceptance chances went way up. In one set of tests, acceptance jumped from about one‑third to almost all after revisions. This shows that clear, targeted feedback can quickly lift quality.
- The step‑by‑step, many‑eyes approach helped reliability:
- Having multiple reviewers, a meta‑reviewer, and a reliability check reduced random mistakes, bias, and “hallucinations” (AI confidently saying things that aren’t supported).
- Model choice matters:
- A strong open‑source model (Qwen‑2.5‑72B) followed instructions well and gave detailed, helpful feedback. Smaller models struggled with long reasoning and format consistency.
- A limitation to keep in mind:
- Because real rejected proposals weren’t available, the team had to create “fake bad” versions by scrambling accepted ones. These still kept good scientific ideas, so the AI found it harder to reject them. Real rejected proposals would give a better test.
Why this matters: Telescope time is precious. A tool that speeds up reviews, gives consistent reasons, and helps authors fix issues before submitting could save months of work, cut reviewer overload, and make decisions fairer and more transparent.
What’s the bigger impact?
If developed further and used responsibly, AstroReview could:
- Help observatories handle many more proposals without burning out reviewers.
- Give fairer, clearer, and more reproducible decisions by showing exactly how each judgment was made.
- Coach authors to write stronger, more feasible proposals, raising the overall quality of science.
- Be adapted to other fields where people apply for access to limited resources (like supercomputers, labs, or big research grants).
Next steps the authors plan include working with observatories to get real full proposals (both accepted and rejected) and their review notes, fine‑tuning the AI with that data, and adding full observation simulations. That would let the system judge not only the writing and logic, but also the likely scientific payoff of the proposed observations, making the reviews even more accurate and useful.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of what remains missing, uncertain, or unexplored, framed as concrete, actionable gaps for future research.
- Lack of real-world evaluation data: obtain full-text proposals (accepted and rejected) with TAC decisions and reviewer comments from multiple observatories to build a realistic benchmark beyond abstracts.
- Synthetic negatives bias: replace perturbed positives with truly rejected proposals; quantify distribution shift and its impact on false positives/negatives and calibrate decision thresholds accordingly.
- Stage 1 and Stage 2 not exercised: implement and rigorously validate the novelty retrieval and feasibility simulation stages on full proposals; measure precision/recall of semantic/parameter parsing and the accuracy of visibility/SNR predictions against mission tools.
- Circular evaluation of “acceptance”: avoid using the same Review Agent to both refine and re-score proposals; include independent human panels or separate LLM evaluators and conduct double-blind assessments.
- Meta-review effectiveness on negatives: investigate why meta-review plus reliability verification reduces negative accuracy; test alternative aggregation schemes (e.g., weighted voting, rank aggregation, Bayesian consensus) and introduce “abstain/uncertainty” options.
- Reviewer-agent diversity: systematically vary the number, model families, and prompt personas of reviewer agents to optimize diversity without redundancy; quantify effects on accuracy, bias, and calibration.
- Reliability verification quantification: develop a benchmark of known contradictions and schema violations to measure how often the verifier corrects errors versus introduces new ones; report pre/post error rates.
- Decision Gate thresholds: perform sensitivity analysis of cosine similarity > 0.90 and score-delta < 1; compare against alternative stopping criteria (e.g., KL divergence on comments, uncertainty reduction) to avoid premature or delayed termination.
- Generalization across facilities and domains: test on proposals from ground-based optical, radio, infrared telescopes (e.g., VLT, ALMA, JWST) and non-astronomy domains; adapt templates and assess cross-domain robustness.
- Realistic feasibility simulations: integrate mission-accurate simulators (visibility, exposure time calculators, background models) and validate that simulated metrics correlate with TAC feasibility judgments.
- Evidence retrieval for novelty: build a reproducible retrieval pipeline (ADS, arXiv, archives) with traceable citations; evaluate retrieval precision/recall and timeliness (handling rapidly evolving literature).
- Bias and fairness analysis: audit whether the system favors certain topics, instruments, institutions, geographies, or writing styles; measure demographic/language bias and propose mitigation (calibration, rubric normalization).
- Adversarial robustness: construct adversarial proposals (rubric gaming, citation stuffing, verbose padding, hedging language) and test detection/defense strategies (consistency checks, penalizing unsupported claims).
- Human-in-the-loop integration: design interfaces for TAC reviewers to steer, override, or annotate agent outputs; run user studies quantifying workload reduction, trust, and decision quality.
- Calibration and uncertainty: calibrate criterion scores to TAC outcomes (Platt scaling, isotonic regression) and report uncertainty/confidence per criterion and final decision; evaluate interpretability and explanation faithfulness.
- Long-context memory management: replace manual buffer injection with scalable memory (summarization, vector databases, retrieval-augmented prompting) and measure effects on precision and stability across iterations.
- Computational efficiency and scalability: report end-to-end runtime, GPU/CPU cost, energy footprint per proposal; model throughput at TAC scale (thousands of proposals) and identify bottlenecks.
- Reproducibility transparency: release prompts, seeds, code, data splits, and agent configurations; quantify variance across runs/temperatures and provide CI tests to ensure consistent results.
- Comparative baselines: benchmark against human reviewers, simple heuristics, smaller LLMs with retrieval, and instruction-tuned domain models; include ablations for chain-of-thought, self-consistency, and tool use.
- Catastrophic forgetting claim validation: empirically test trade-offs of astronomy-specific fine-tuning (LoRA/adapters vs. full fine-tune) on general reasoning and instruction-following, and evaluate retrieval-augmented alternatives.
- Template compliance impact: quantify how template adherence affects TAC-like decisions; explore guardrails and constrained generation to enforce compliance without degrading substantive content.
- Cross-checking factual claims: implement automated fact-checking against literature and archives; report rates of unsupported or contradictory claims detected and corrected.
- Metric design for “acceptance rate”: avoid ceiling effects by using external, fixed acceptance classifiers or human TAC proxies; define a consistent mapping from the six rubric dimensions to final decisions and validate it.
- Language coverage and accessibility: evaluate performance on non-English proposals and those from non-native English authors; assess translation quality and fairness implications.
- Ethics, privacy, and governance: establish policies for handling confidential proposals (consent, retention, audit trails), IP protection, and safeguards against misuse (e.g., generating deceptive proposals); consider watermarking/detection.
- Real-world impact tracking: in partnership with observatories, track downstream outcomes (awarded time, data yield, publications) to verify that agent-driven refinements lead to measurable scientific gains.
Glossary
- Ablation study: An experimental method that removes or alters components to measure their impact on system performance. "Ablation study on the Review Agent powered by Qwenâ2.5â72B."
- Astrophysics Data System (ADS): A curated digital library for astronomical and astrophysical literature used for research and retrieval. "AstroBERT \cite{grezes2021building} first adapted BERT \cite{devlin2019bert} to about 400k documents from the Astrophysics Data System (ADS), enabling deep contextual understanding and entity recognition."
- Cadence: The timing pattern or schedule of repeated observations designed to capture evolving phenomena. "whether the proposed cadence captures information unavailable from prior surveys."
- Catastrophic forgetting: A phenomenon in continual learning where fine-tuning on new data causes a model to lose previously learned knowledge. "can trigger catastrophic forgetting, severely eroding the modelâs general knowledge base"
- Continued pre-training: Further training of a pretrained model on domain-specific corpora before fine-tuning for tasks. "trained with continued pre-training, supervised fine-tuning, and model merging"
- Cosine similarity: A metric that measures the similarity between two vectors (e.g., texts) based on the cosine of the angle between them. "If the cosine similarity exceeds 0.90, the revision is considered insubstantial."
- De-identification: The process of removing identifying metadata to prevent unintended information leakage. "we perform a de-identification process."
- Few-shot prompting: Guiding an LLM with a small number of examples to induce task-specific behavior without extensive training. "primarily through few-shot prompting, self-reflection, and supervised fine-tuning techniques."
- Label leakage: Unintended exposure of target labels or correlates within data that can bias model evaluation. "which may lead to label leakage"
- Meta-review: A synthesis step that consolidates multiple reviewer assessments into a final, consensus decision. "A meta-review then synthesizes the individual reports, issuing a definitive decision accompanied by a succinct panel summary."
- Model inertia: A tendency for generative models to make superficial or repetitive changes across iterations rather than substantive revisions. "we have empirically observed as ``model inertia'': during multi-round revisions the generator sometimes responds to reviewer feedback with only superficial, near-duplicate edits"
- Model merging: Combining parameters or knowledge from multiple trained models into a single model. "trained with continued pre-training, supervised fine-tuning, and model merging"
- Multi-agent framework: An architecture where multiple autonomous LLM agents coordinate to perform complex, decomposed tasks. "The LLM-driven multi-agent astronomical assistant framework is illustrated in Figure \ref{fig:AstroReview}, which proceeds through three consecutive stages."
- Orbital constraints: Limitations arising from a spacecraft’s orbit that affect scheduling and target visibility. "A parameter parser extracts instrument settings, orbital constraints, and other scheduling details directly from the proposal."
- Parameter parser: A component that extracts structured technical parameters (e.g., instrument settings) from free-text documents. "A parameter parser extracts instrument settings, orbital constraints, and other scheduling details directly from the proposal."
- Per-orbit efficiency: The effective fraction of usable observation time or data quality achievable within a single orbital period. "Visibility prediction determines accessible windows and perâorbit efficiency for each target"
- Reliability verification: An audit step that checks outputs for consistency, evidence alignment, and template adherence, correcting errors. "Finally, reliability verification is carried out through an external audit routine that enforces template compliance, crossâchecks every claim against its supporting evidence, and immediately revises any hallucinations or logical inconsistencies it uncovers."
- Retrieve-and-rank: An information retrieval process that fetches candidate documents and orders them by relevance to queries. "These queries inform a retrieve-and-rank process conducted across scientific literature, web resources, and curated databases to gather relevant evidence."
- Score convergence: A stopping criterion evaluating whether reviewer scores stabilize across iterations. "Score convergence, measured as the absolute difference between consecutive scores."
- Semantic parser: A system that converts natural language into structured representations by extracting entities, relations, and intents. "A semantic parser first extracts key objects, phenomena, and research goals from the proposal draft."
- Signal-to-noise: A diagnostic ratio indicating measurement strength relative to background noise in observational data. "yielding signalâtoânoise diagnostics and preview frames."
- Supervised fine-tuning: Training a model on labeled data to specialize its behavior for specific tasks. "primarily through few-shot prompting, self-reflection, and supervised fine-tuning techniques."
- Template compliance: Adherence to a prescribed output format or schema required by the review process. "enforces template compliance"
- Time Allocation Committees (TAC): Panels that evaluate proposals and assign observation time on telescopes. "Time Allocation Committees (TAC) often assess hundreds to thousands of proposals per cycle under tight deadlines."
- Transients: Short-lived or rapidly evolving astronomical phenomena requiring timely observation. "especially those that target rapidly evolving transients"
- Visibility prediction: Estimating when targets are observable given scheduling and orbital parameters. "Visibility prediction determines accessible windows and perâorbit efficiency for each target"
Practical Applications
Practical, Real-World Applications
Below are actionable applications derived from AstroReview’s findings, methods, and innovations. Each item notes the sector(s), whether it is deployable now or later, potential tools/products/workflows, and key assumptions or dependencies affecting feasibility.
Immediate Applications
- TAC copilot for proposal triage and meta-review
- Sectors: academia (observatories), policy (facility governance)
- What it does: Use Stage 3 (multi-reviewer + meta-review + reliability verification) to pre-screen proposals, generate structured critiques, and produce auditable decision records; reduce reviewer fatigue and improve consistency.
- Tools/workflows: “Review Agent” + “Meta-Review Agent” + “Reliability Verifier”; standardized rubric templates; audit trail export
- Assumptions/dependencies: Access to proposal full-texts (or abstracts at minimum); human-in-the-loop oversight; calibration of score thresholds; compute availability for 70B-class LLMs
- Pre-submission “Proposal Preflight Checker” for investigators
- Sectors: academia (research groups), education (graduate training), daily life (grant/scholarship applications)
- What it does: Closed-loop authoring-review refinement using the Proposal Authoring Agent and Review Agent to improve clarity, feasibility narrative, and rubric alignment; provides explicit passage-level feedback to guide revisions
- Tools/workflows: Authoring Agent + Review Memory + Manuscript Memory + Decision Gate; template-driven drafting assistants
- Assumptions/dependencies: Templates aligned with specific facility criteria; guidance to avoid over-optimization to a single rubric; privacy controls for sensitive proposals
- Reviewer training and calibration simulator
- Sectors: academia (TACs), education (methods courses)
- What it does: Simulate multiple independent reviews and meta-reviews to train new panelists on criterion-referenced scoring and passage-anchored critiques; reduce inconsistency across panels
- Tools/workflows: Structured review templates, exemplar proposals, score-convergence dashboards
- Assumptions/dependencies: Access to representative proposal corpora; agreement on rubrics; institutional buy-in
- Automated audit and compliance checking for review outputs
- Sectors: academia (observatories), policy (oversight bodies)
- What it does: Reliability Verifier enforces template compliance, flags unsupported claims, and corrects formatting or logical inconsistencies in review reports; produces traceable reasoning artifacts
- Tools/workflows: Post-hoc audit pipeline integrated with review systems; compliance logs for internal QA
- Assumptions/dependencies: Clear schema definitions; secure storage of review artifacts; human verification of flagged items
- High-throughput abstract-level triage for oversubscribed cycles
- Sectors: academia (HST, JWST, ground-based facilities), policy (program management)
- What it does: Binary classification to prioritize likely-accept candidates for deeper human review; helps manage surges in submissions
- Tools/workflows: Lightweight “screening mode” of the Review Agent; batch processing queues; thresholding policies
- Assumptions/dependencies: The paper’s 87% accuracy was measured primarily on accepted proposals; access to truly rejected proposals is needed to calibrate false-positive/false-negative rates; bias monitoring required
- Cross-domain, text-only review support (adaptable now)
- Sectors: software (RFCs, PRDs), healthcare (IRB pre-check narrative quality), energy (project concept notes), finance (investment memos), robotics (experiment plans), education (course proposals)
- What it does: Apply the Stage 3 pipeline to generate structured, passage-referenced critiques and meta-reviews for document-centric proposals where feasibility simulations are not required
- Tools/workflows: Domain-specific rubrics; template libraries; audit trail exports
- Assumptions/dependencies: Rubric customization to local standards; domain-specific red teaming to limit hallucinations; privacy and compliance
- Proposal writing pedagogy and mentorship aid
- Sectors: education (graduate programs, fellowship offices), daily life (scholarships, grant applications)
- What it does: Interactive tutor guiding novices through structure, argumentation, and feasibility narratives; Decision Gate prevents “infinite revision” cycles while promoting substantive changes
- Tools/workflows: Workshop mode; iterative feedback checkpoints; similarity and score-convergence monitors
- Assumptions/dependencies: Faculty oversight; avoidance of over-reliance on model-generated prose; academic integrity policies
Long-Term Applications
- End-to-end, multimodal review with integrated novelty retrieval and feasibility simulation
- Sectors: astronomy (observatory operations), robotics (simulated experiments), energy (grid planning), healthcare (trial design)
- What it does: Combine Stage 1 (literature/archives retrieve-and-rank) + Stage 2 (visibility prediction and instrument simulation) + Stage 3 (meta-review and reliability verification) for full-spectrum assessment
- Tools/workflows: Connectors to mission APIs (visibility windows, S/N calculators), curated domain databases, simulation outputs embedded in reviews
- Assumptions/dependencies: API access to official tools; robust data engineering; reproducible simulation environments; cost-effective compute
- Domain-specific fine-tuning on full accepted/rejected proposals with reviewer comments
- Sectors: academia (observatories, funding agencies), policy (standards bodies)
- What it does: Improve accuracy, reduce bias, and enhance instruction following using real rejected proposals and panel notes; bolster rejection-case performance
- Tools/workflows: Secure data-sharing agreements; de-identification pipelines; continuous evaluation suites
- Assumptions/dependencies: Availability of sensitive datasets; privacy-preserving practices; avoiding catastrophic forgetting; governance for model updates
- Human-in-the-loop AI governance and fairness auditing for TACs
- Sectors: policy (research governance), academia (time allocation committees)
- What it does: Deploy dashboards for bias detection (e.g., topic, institution, PI demographics), consistency checks across cycles, and reproducibility audits of AI-assisted decisions
- Tools/workflows: Bias metrics, audit logs, counterfactual testing, appeal workflows
- Assumptions/dependencies: Ethical frameworks; legal compliance; stakeholder acceptance; ongoing monitoring
- Portfolio-level decision support and optimization
- Sectors: academia (program management), finance (analogous investment portfolio), energy (project portfolio planning)
- What it does: Predict acceptance likelihood and expected scientific yield; optimize portfolio diversity and impact under resource constraints
- Tools/workflows: Scenario simulators; multi-objective optimization; KPI dashboards
- Assumptions/dependencies: High-quality labeled data; careful calibration to avoid gaming; transparency on criteria
- Cross-sector simulation-informed review
- Sectors: healthcare (trial simulators for accrual/endpoint power), energy (grid stability simulations), robotics (task feasibility), software (performance modeling)
- What it does: Attach domain simulators to reviews to quantify feasibility and expected outcomes; standardize evidence across proposals
- Tools/workflows: Plug-in architecture for simulators; provenance tracking of results
- Assumptions/dependencies: Reliable simulators and validated models; data access; interoperability standards
- Productization as a secure SaaS or on-prem platform
- Sectors: software (enterprise), academia (institutions), policy (government labs)
- What it does: “Proposal Review Copilot” with configurable rubrics, audit trails, reviewer training, and simulation connectors; integration to submission portals
- Tools/workflows: Role-based access control; logging; API ecosystem; model lifecycle management
- Assumptions/dependencies: Cost of operating 70B LLMs; hybrid deployment (on-prem for sensitive data); licensing and support
- Advanced memory and context management for long documents
- Sectors: software (LLM infra), academia (large proposals)
- What it does: Robust memory modules beyond manual buffers to handle long context windows without truncation; improved retrieval-augmented generation
- Tools/workflows: Hierarchical summarization; chunk-linked citation; semantic caching
- Assumptions/dependencies: Model architectural advances; efficient retrieval pipelines; evaluation on long-form inputs
- Ethical and compliance add-ons (COI detection, plagiarism/duplication checks)
- Sectors: academia, policy, software
- What it does: Automate conflict-of-interest warnings, detect overlapping content with prior proposals, and spot duplicate observational plans
- Tools/workflows: Identity resolution; content similarity services; registries of prior submissions
- Assumptions/dependencies: Access to identity and historical data; privacy safeguards; false-positive mitigation
- Open datasets and benchmarks for AI-assisted peer review
- Sectors: academia, policy
- What it does: Community-maintained corpora of accepted/rejected proposals and reviews; standardized tasks for accuracy, bias, and reproducibility
- Tools/workflows: Data-sharing frameworks; de-identification standards; benchmark leaderboards
- Assumptions/dependencies: Institutional willingness to share; legal agreements; ongoing curation
- Curriculum integration and evidence-based pedagogy
- Sectors: education
- What it does: Course modules that use AI feedback in proposal writing; measure learning gains and long-term success rates
- Tools/workflows: Controlled classroom deployments; rubric-aligned assessments; longitudinal tracking
- Assumptions/dependencies: IRB approvals for educational research; faculty training; student data protections
Notes on global assumptions and constraints:
- Performance depends on access to full proposals (not just abstracts), real rejected samples, and instrument/simulator integrations.
- High-parameter LLMs (≈70B) and reliable inference hardware (e.g., H100 GPUs) significantly affect output quality, cost, and latency.
- Governance is essential: human oversight, transparency, auditability, and domain-specific rubric calibration mitigate risks of bias and hallucination.
- Fine-tuning must balance domain competence against catastrophic forgetting; retrieval augmentation and modular agents help preserve general reasoning.
Collections
Sign up for free to add this paper to one or more collections.