Basic Inequalities for First-Order Optimization with Applications to Statistical Risk Analysis
Published 31 Dec 2025 in math.ST, cs.LG, math.NA, math.OC, and stat.ML | (2512.24999v1)
Abstract: We introduce \textit{basic inequalities} for first-order iterative optimization algorithms, forming a simple and versatile framework that connects implicit and explicit regularization. While related inequalities appear in the literature, we isolate and highlight a specific form and develop it as a well-rounded tool for statistical analysis. Let $f$ denote the objective function to be optimized. Given a first-order iterative algorithm initialized at $θ_0$ with current iterate $θ_T$, the basic inequality upper bounds $f(θ_T)-f(z)$ for any reference point $z$ in terms of the accumulated step sizes and the distances between $θ_0$, $θ_T$, and $z$. The bound translates the number of iterations into an effective regularization coefficient in the loss function. We demonstrate this framework through analyses of training dynamics and prediction risk bounds. In addition to revisiting and refining known results on gradient descent, we provide new results for mirror descent with Bregman divergence projection, for generalized linear models trained by gradient descent and exponentiated gradient descent, and for randomized predictors. We illustrate and supplement these theoretical findings with experiments on generalized linear models.
The paper introduces a unified framework using basic inequalities to tightly bound optimization performance and relate iteration count with effective regularization.
It derives explicit training envelopes that align the trajectories of gradient and mirror descent with solutions from penalized objectives.
Empirical evaluations on synthetic GLMs confirm that appropriate early stopping can mimic explicit regularization to achieve optimal prediction risk.
Basic Inequalities for First-Order Optimization: Theory and Statistical Risk Applications
Framework for Implicit and Explicit Regularization
The paper establishes a unified analytical framework based on “basic inequalities” characterizing the behavior of first-order optimization algorithms. These inequalities provide tight, transparent upper bounds on the gap f(θT)−f(z) between the value at an algorithm's iterate and any reference point, expressed in terms of accumulated step sizes and the distances between initial point, final iterate, and the reference. Crucially, these bounds directly couple the regularization coefficient λ in the penalized objective to the optimization stopping time T, establishing that increasing the number of iterations corresponds to decreasing effective regularization.
For gradient descent with constant step size η and initialization at the origin, the authors isolate:
f(θT)−f(z)≤2ηT1(∥z∥22−∥θT−z∥22).
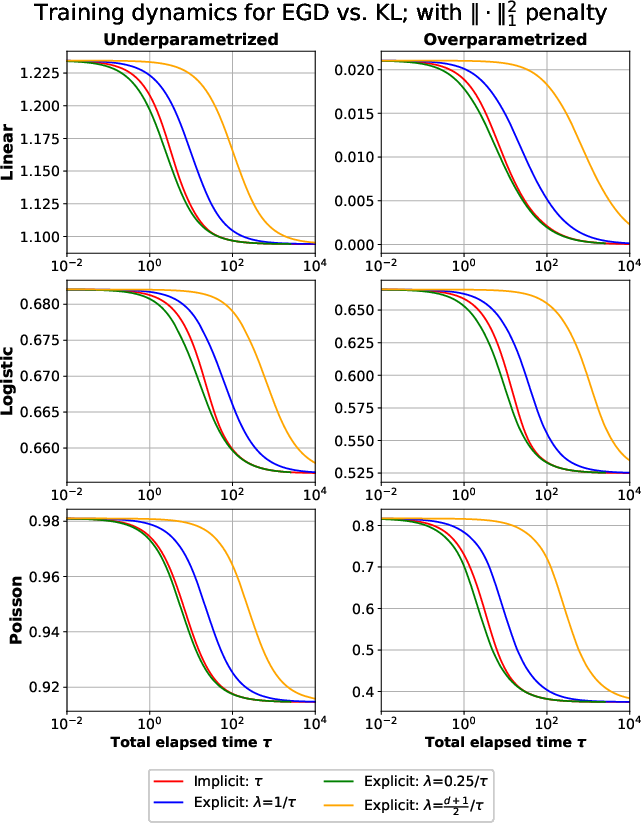
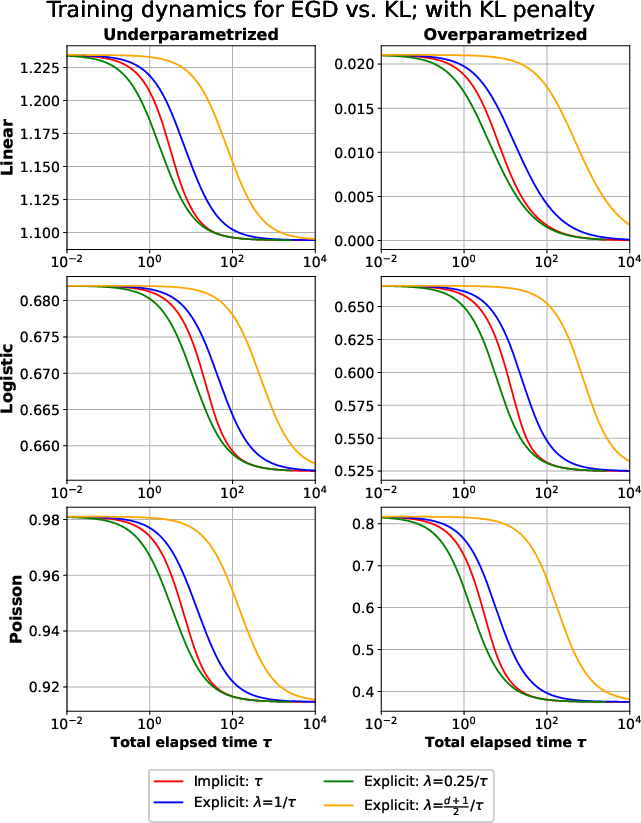
Similar forms are derived for mirror descent, capturing general geometric regularization via Bregman divergences, linking optimization geometry (e.g., negative entropy leads to KL regularization) to statistical risk properties. The analysis clarifies the precise trade-off between explicit penalties (ridge, Lasso, KL) and algorithmic inductive biases induced by early stopping.
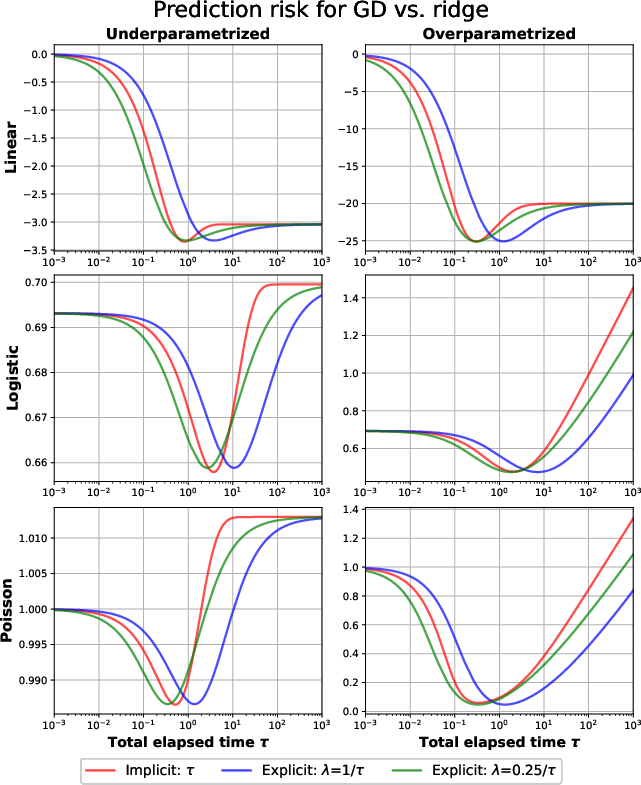
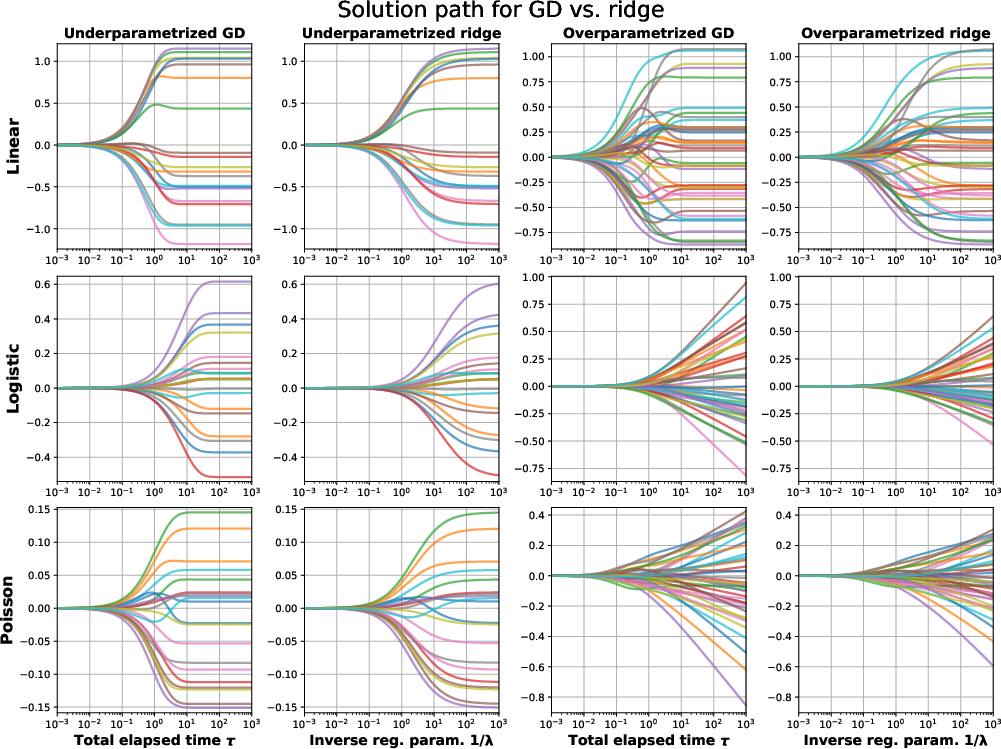
Figure 1: GD vs. ridge, plotted with ∥θ∥22 penalty, visualizing how the basic inequality envelopes the trajectory of iterates.
Training Dynamics and Solution Envelopes
From the basic inequality, the authors derive explicit training envelopes that bound the value of implicitly regularized iterates between explicit regularization objective values at different regularization strengths. For gradient descent:
with λT=1/(ηT). The bounds are extended to mirror descent with strong convexity and smoothness assumptions, showing how the algorithm's trajectory aligns with penalized minimizers as training proceeds, subject to geometric constants from the Bregman divergence structure. Notably, for certain problems (overparameterized regression), the limiting solution of gradient descent coincides with the minimum norm interpolator, demonstrating the generalized inductive bias.
Statistical Risk Analysis: Prediction Risk Bounds
Leveraging the basic inequalities, the paper provides rigorous derivations of statistical risk bounds for iterates of gradient descent, mirror descent, and exponentiated gradient algorithms, often matching optimal rates for explicit regularization. Analysis covers generalized linear models (GLMs) — linear, logistic, Poisson — and treats both well-specified and misspecified settings. Under sub-Gaussian noise and spectral assumptions on X, the excess risk bound for GD after T∗ steps is:
R(θT∗)−∥θ∥≤binfR(θ)≤O(bσnd),
where T∗ is set by the target regularization level λ∗. For exponentiated gradient descent and KL-regularized loss, bounds scale as O((blogd)/n).
Figure 2: GD vs. ridge, experiment showing envelope containment and close tracking of implicit and explicit regularization objectives across sample regimes.
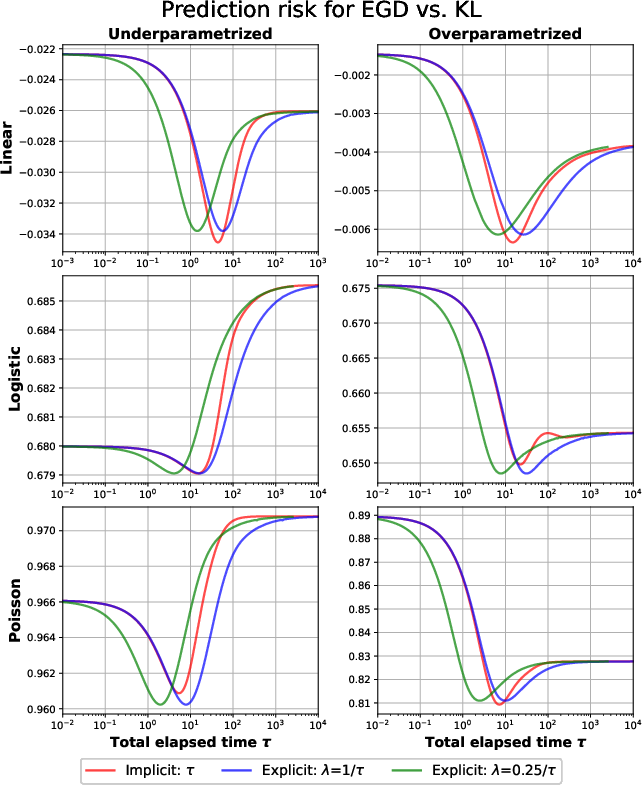
These results hold for both early stopping and fixed step size schemes, demonstrating that the algorithmic stopping time is a proxy for the explicit penalty: stronger regularization corresponds to fewer iterations. The empirical studies validate the risk bounds and the tightness of the basic inequalities. Results generalize to mirror descent, delivering oracle inequalities in terms of general Bregman divergences.
Experiments: Implicit vs. Explicit Regularization
Empirical evaluation on synthetic GLMs confirms the theoretical predictions, with comparison of solution trajectories, risk curves, and training envelope bounds. Iterates from GD and exponentiated GD closely follow the paths of penalized solutions (ridge, KL) as regularization parameters vary, both in under- and over-parametrized regimes. The minimum prediction risk is attainable by tuning either explicit regularization or early stopping.
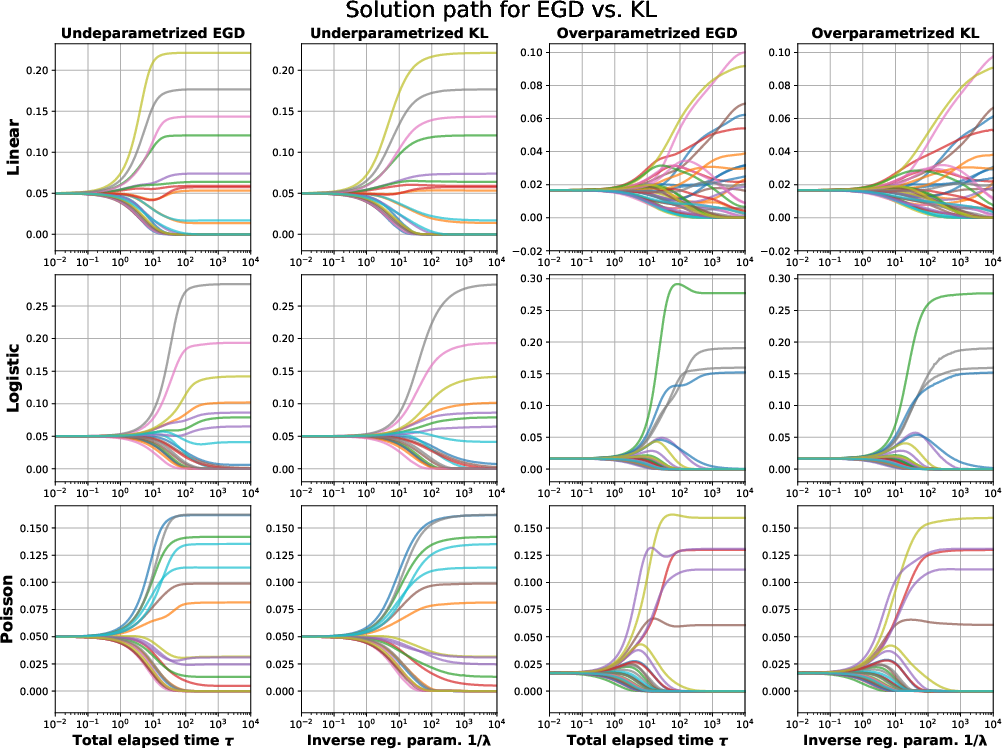
Figure 3: GD vs. ridge, solution paths visualizing coordinate convergence and implicit/explicit regularization alignment across GLMs and dimensional settings.
Visualization of solution paths reveals strong alignment between implicit (algorithmically regularized) and explicit (penalized) estimators. In some regimes (logistic, Poisson regression with separable/ill-posed data), norm divergence of iterates is observed, with limiting directionality corresponding to maximum margin solutions as in recent implicit bias literature.
Extensions to Other Algorithms
The framework is extended to proximal gradient descent and the NoLips algorithm, deriving basic inequalities under generalized smoothness assumptions (allowing composite, non-differentiable losses and non-strongly convex regularizers). For ISTA and lasso, the basic inequality recovers elastic net-style bounds, with coefficients explicitly tied to algorithm steps and penalty.
Implications and Future Directions
The basic inequality framework provides a versatile tool for joint statistical and computational analysis, connecting optimization theory and statistical risk analysis. It unifies perspectives on implicit and explicit regularization, quantifies inductive bias, and aids in algorithmic tuning. Future directions include sharpening inequalities under stronger conditions (strong convexity, restricted eigenvalue), extending to non-convex/non-smooth settings, and analyzing stochastic optimization variants (SGD).
The practical implication is direct: early stopping and hyperparameter selection can be calibrated via the derived bounds, and the geometry of the optimization algorithm determines the statistical properties of the solution. Theoretical implications include generalization of bias and risk analysis to modern high-dimensional and deep learning settings, with the potential to elucidate phenomena such as double descent and benign overfitting.
Conclusion
This work formalizes a powerful connection between first-order optimization algorithm dynamics and statistical regularization via the “basic inequality” framework. The analysis provides concrete guarantees for statistical risk, clarifies the relationship between algorithmic and explicit regularization, and extends across a spectrum of models and penalty geometries. The results contribute to a rigorous foundation for understanding implicit bias, generalization, and optimal estimator design in contemporary machine learning.