- The paper demonstrates that finite-population monotonicity is completely identifiable in design-based frameworks even though practical testing remains uninformative.
- It establishes that frequentist tests have limited power, often failing to robustly distinguish monotonicity due to minimal weighted average power, particularly with moderate sample sizes.
- The study reveals that Bayesian inference on monotonicity is critically dependent on prior selection, leading to non-updating posteriors under standard experimental designs.
Essay: An Expert Analysis of "Testing Monotonicity in a Finite Population"
Overview and Motivation
The paper "Testing Monotonicity in a Finite Population" addresses a foundational question in the causal inference literature: To what extent can data from a completely randomized experiment inform us about whether monotonicity—defined as all units having treatment effects weakly of the same sign—holds at the finite population level? Monotonicity, also known as monotone treatment response, is a central assumption underlying the interpretability of instrumental variable estimands and the validity of point-identified treatment effect bounds, but its empirical testability has significant consequences for experimental design and inference.
The novelty and central critique of the paper lie in contrasting the classical sampling-based perspective (in which the observed units are random draws from a larger, possibly infinite, superpopulation) with the design-based perspective (in which both the sample and outcomes are fixed, and randomness arises only through treatment assignment). While it is well-understood that monotonicity is untestable in the classical view, the extent to which identification and inference are feasible in the design-based view—specifically, given only one realization of the treatment allocation—has not been characterized with technical clarity or precision prior to this work.
Within a binary treatment, binary outcome setup, the finite population comprises n units, each with potential outcomes (yi(0),yi(1)) and a realized treatment allocation Di, with n1 units randomly assigned to D=1 and the rest to D=0. The population is categorized by the number of always-takers, never-takers, compliers, and defiers, following the principal stratification lexicon.
The paper defines monotonicity in the design-based context as the condition that either the number of compliers or defiers is zero for the observed units—min{θc,θd}=0, where θc,θd are the counts of compliers and defiers, respectively. The central sufficient statistic is the vector (YT,YU), denoting the numbers of treated and untreated units with outcome Y=1.
Identification in Design-Based vs. Sampling-Based Inference
A key result is the complete identification of the finite-population type vector θ from the design-based likelihood. Specifically, for any two distinct finite-population types θ1,θ0, the induced distributions fθ1(⋅),fθ0(⋅) over (YT,YU) are distinct. By contrast, the superpopulation parameter p is not identified: for every alternative p1 violating monotonicity, there exists a monotonic p0 giving rise to the same superpopulation likelihood gp(⋅), echoing the classical impossibility results [heckman_making_1997].
Nevertheless, the paper underlines a conceptual subtlety: identification in the frequentist (Kolmogorov) sense assumes repeated experimentation (changing the randomization) on the same finite units—counterfactuals that are unavailable in practice. This gap motivates a focus on properties of single-experiment inference: frequentist test power and Bayesian posterior updating.
Frequentist Testing: Limits of Power
The authors establish that, while there exist frequentist tests against monotonicity with non-trivial power for some alternatives, these tests are generally highly unsatisfactory in terms of weighted average power (WAP), especially as sample size increases. Specifically, any level-α test has WAP no greater than 2.51α, uniformly over all alternatives, and this bound approaches α as the fraction of compliers or defiers rises or as n→∞. Notably, even with moderate sample sizes, if both compliers and defiers represent a nontrivial proportion of the population, the power over alternatives close to the point of maximal power is negligible.
These results are numerically illustrated in the context of n=30, n1=15, where the maximal power of any 5% test never exceeds 31%, and is usually much lower. In fact, for alternatives near the point of maximal power, the test becomes entirely uninformative.
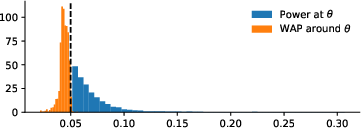
Figure 1: Power of the most powerful test for a given alternative θ∈Θ1 for n=30,n1=15.
The figure concisely captures these phenomena: while individual alternatives are formally testable, tests lack robustness to small perturbations in the parameter, and their informativeness is almost always trivial in practice.
Further, the asymptotic result for unbiased tests is even stronger: the power of such tests is asymptotically equal to the nominal size—demonstrating the impossibility of constructing powerful, generic, or uniformly most powerful tests for monotonicity in finite populations.
Bayesian Updating: Prior Dependence and Non-Convincingness
The Bayesian analysis mirrors the frequentist negative result in a different dimension. While, for some informative priors (such as two-point priors concentrated on identified alternatives), observation of the data will induce posterior updating about the validity of monotonicity, there always exist non-degenerate priors (specifically, those with support mixtures over monotonic and non-monotonic population types) for which posterior beliefs about monotonicity are unchanged after observing the data. Formally, for any c∈(0,1) there exists a prior π∗ with π∗(θ∈Θ0∣Y)=c almost surely.
Thus, inference about monotonicity depends critically on the specification of prior beliefs, and data from a single experiment will not induce consensus among subjective Bayesians. Therefore, claims or policies predicated on updated posterior probability of monotonicity are driven as much by researcher prior as by the experimental data, strongly limiting objectivity.
Implications, Limitations, and Theoretical Contributions
The strong technical findings in this paper have several substantive implications:
- Practical Inference: For empirical researchers, the results clarify that both frequentist and Bayesian analyses provide little, if any, evidence about finite-population monotonicity from a standard randomized trial, even if formal identifiability holds. This challenges any policy analyses or scientific assertions contingent on having empirically validated monotonicity by design-based testing.
- Theoretical Perspective: The work cautions that the prevailing definition of identification is insufficient to guarantee practical informativeness when only a single treatment allocation is observed—a subtlety relevant for many design-based causal inference problems.
- Generalizability: While the analysis is developed for binary outcomes and complete randomization, the issues and technical architecture readily generalize to higher-dimensional finite population inference and other non-sharp nulls.
- Future Methodology: The lack of testability motivates the field to seek new design strategies, joint testable restrictions, or alternative estimands less sensitive to monotonicity, for example, focusing on partial identification or bounds [Manski2003].
- Connection to Recent Literature: Related work [kline2025finite] revisits finite-population identification, advocating for alternative definitions and sensitivity analysis, and similar deficiencies in the applicability of standard identification are also highlighted in broader design-based contexts [abadie_sampling-based_2020, rambachan_design-based_2025].
Conclusion
This paper constitutes a rigorous technical assessment of the inferential content of experimental data concerning finite-population monotonicity. Despite complete identification in the design-based likelihood, practical, data-driven learning about monotonicity is shown to be essentially impossible: frequentist tests cannot robustly distinguish monotonicity from its natural alternatives, and Bayesian updating is prior-dependent—some agents will never update at all. This dichotomy implies that, absent additional structural or design assumptions, claims about monotonicity must be grounded in domain knowledge and not on the evidence from standard randomization-based experimentation. The findings have immediate consequences for the design, interpretation, and reporting practices in experimental and quasi-experimental economics and biostatistics. Future research can investigate classes of design-based hypotheses with better testable content or integrate ancillary information for inference.
References (selective)
- (2512.25032) "Testing Monotonicity in a Finite Population"
- Heckman, J. J., Smith, J., & Clements, N. (1997). Making The Most Out Of Programme Evaluations and Social Experiments: Accounting For Heterogeneity in Programme Impacts, The Review of Economic Studies, 64(4), 487-535.
- Manski, C. F. (2003). Partial Identification of Probability Distributions. Springer.
- Kline, B., & Masten, M. A. (2025). "Finite Population Identification and Design-Based Sensitivity Analysis" (Kline et al., 19 Apr 2025).
- Abadie, A., Athey, S., Imbens, G. W., & Wooldridge, J. M. (2020). Sampling-Based versus Design-Based Uncertainty in Regression Analysis, Econometrica, 88(1), 265–296.