- The paper demonstrates that integrating a neural network with MWPM enables adaptive edge weighting that significantly reduces logical error rates.
- The hybrid model employs a two-stage architecture combining GNN and Transformer layers to analyze local and global syndrome features.
- Experimental results show up to 50% LER reduction and threshold improvements on toric and surface codes, validating its practical effectiveness.
Neural Minimum Weight Perfect Matching for Quantum Error Codes
Problem Definition and Context
Quantum error correction (QEC) remains a central challenge for scaling fault-tolerant quantum computation. Topological codes such as the surface code and toric code are leading candidates because of their high error thresholds and locality properties. However, decoding in these architectures—the task of mapping syndrome information to correction operators—incurs significant classical overhead and directly constrains practical quantum processor throughput.
Minimum Weight Perfect Matching (MWPM) is the classical workhorse for decoding topological codes, owing to its polynomial-time optimality under certain noise models. Yet, MWPM’s assumptions—specifically, independence of errors and static, geometry-based edge weights—prohibit adaptation to correlated or hardware-specific noise, which is increasingly the norm in both simulators and experimental devices. While ML approaches have demonstrated strong performance gains in decoding, the non-differentiable nature of MWPM has impeded their seamless integration, limiting end-to-end training and hybrid methods.
The paper introduces Neural Minimum Weight Perfect Matching (NMWPM), a hybrid decoder that learns syndrome-adaptive edge weights for MWPM using a neural model trained via a differentiable proxy loss. The pipeline efficiently combines geometric deep learning tools with algorithmic decoders, yielding substantial improvements in logical error rate (LER) across both independent and depolarizing noise regimes.
Methodological Innovations
Hybrid Edge-Weight Prediction Pipeline
NMWPM constructs a fully connected syndrome graph for each error detection cycle. Each node encodes geometric and topological features, while each edge synthesizes pairwise geometric context. Node and edge representations are built via learned embeddings, MLP projections, and positional encodings, together ensuring that both local and global code structure are captured.
A two-stage neural architecture—the Quantum Weight Predictor (QWP)—is used:
- GNN Block: A stack of TransformerConv layers update node embeddings based on neighboring context. The architecture incorporates multi-head attention, residual connections, and gating mechanisms, supporting robust learning of local defect correlations.
- Transformer Encoder: For each edge, the processed representations of the node pair and their geometric/edge features are concatenated and passed to a multi-layer Transformer encoder. This mechanism allows for global, context-aware reasoning over the full syndrome graph, enabling the model to disambiguate competing candidate error chains and encode long-range correlations (Figure 1).
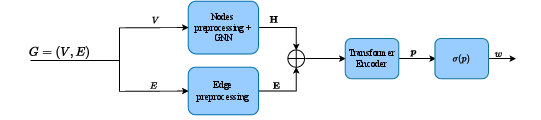
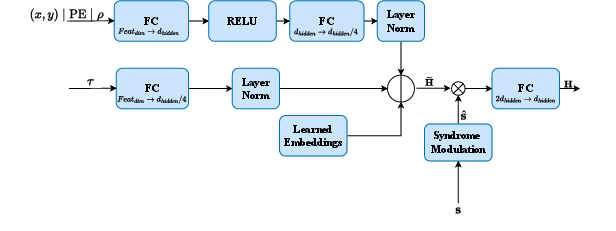
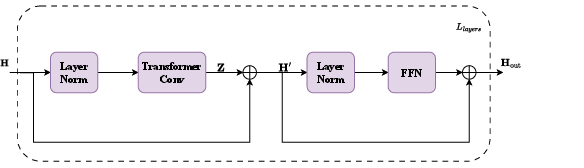
Figure 1: Overview of end-to-end weight prediction, integrating node feature encoding, local GNN processing, and global attention for syndrome-aware edge weight assignment.
Predicted probabilities are thresholded (taking the maximum of each edge and its reverse) and translated to log-likelihood edge weights, which are then supplied to a classical MWPM implementation without further modification.
Differentiable Loss and Ground Truth Construction
To enable end-to-end training despite MWPM’s combinatorial, non-differentiable objective, the authors design a proxy loss: the model is trained as an edge-wise binary classifier, with binary cross-entropy (BCE) as the primary objective and an entropy regularizer enforcing confident (sharply bimodal) predictions. This sharp polarization is crucial, as small uncertainties can accumulate in MWPM and degrade decoding quality.
For supervised training, ground truth for error chains is generated via clustering stabilizers, local MWPM within clusters, and permutation searches to ensure that corrections do not yield logical errors. This enables robust training supervision despite code degeneracy.
Experimental Evaluation
Codes, Baselines, and Setup
The authors benchmark NMWPM on the toric code and rotated surface code under both independent and depolarizing noise, with lattice distances up to L=10. Baselines include:
- MWPM with standard static weights,
- QECCT (Transformer-based decoder),
- BPOSD-2 (Belief Propagation with Order-2 Ordered Statistics Decoder).
Models share comparable hidden dimensions, layer configurations, and training protocols; complexity is managed to facilitate fair comparison.
The NMWPM delivers consistent and statistically significant reductions in LER compared to all baselines. Under depolarizing noise and L=10, it achieves up to 50% reduction in LER relative to MWPM and outperforms QECCT at larger code distances (see Figure 2 and Figure 3).
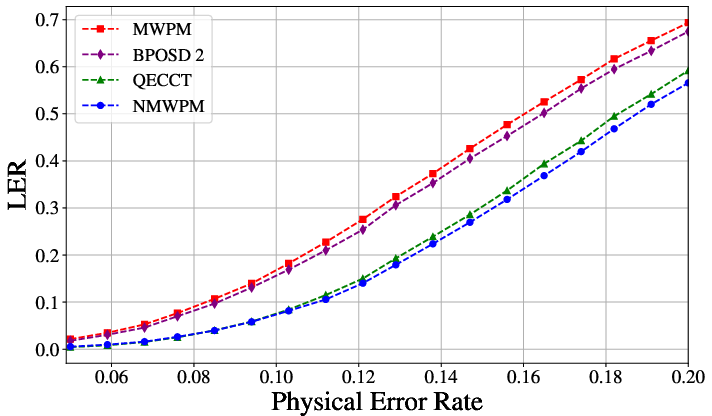
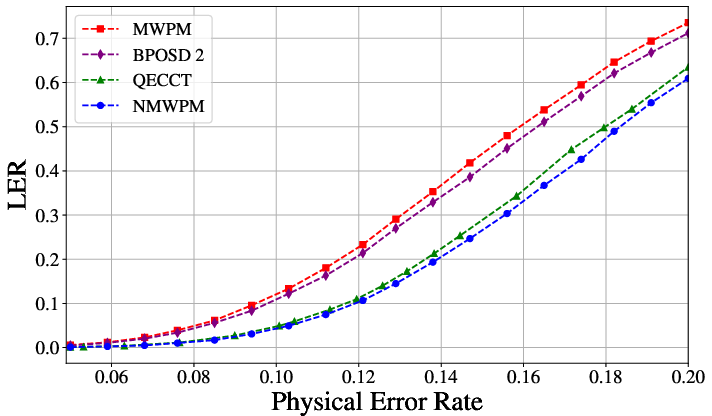
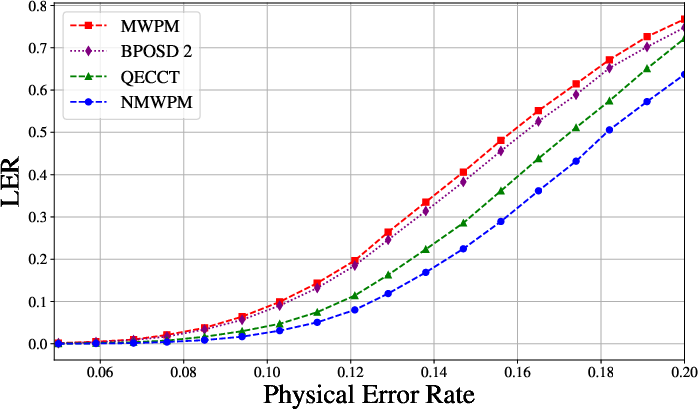
Figure 2: LER as a function of physical error rate for toric code with L=6, demonstrating the enhanced performance of NMWPM relative to static MWPM and other learning-based decoders.
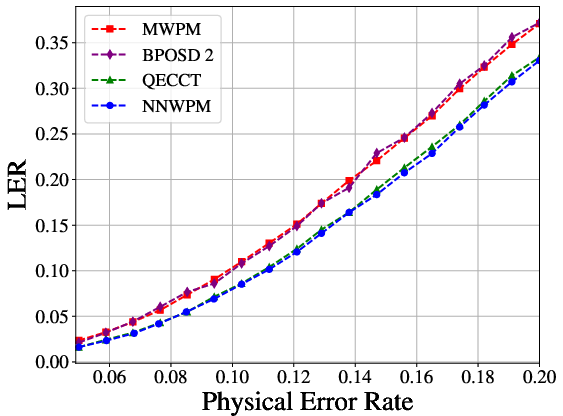
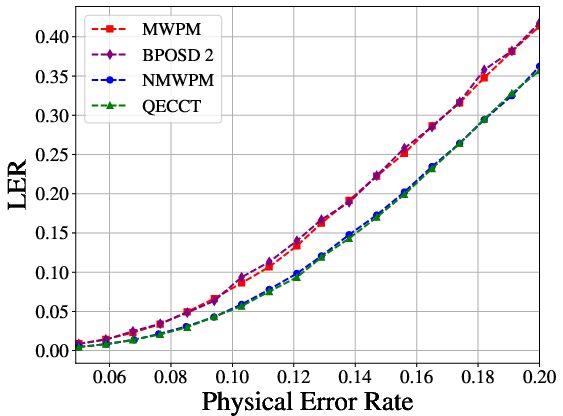
Figure 3: LER scaling for the rotated surface code at L=5, where NMWPM maintains improvements over both classical and learned baselines.
Crucially, NMWPM achieves thresholds approaching theoretical maxima:
- Under depolarizing noise on the toric code: pth=17.9%, compared to MWPM (16.0%) and QECCT (17.8%)
- Under independent noise: pth=10.95% (theoretical optimum 11.0%), outperforming all classical heuristics.
Parameter efficiency is emphasized: while QECCT scales up to 6.7M parameters at L=10, NMWPM remains efficient at ~3.9M with robust generalization, supporting deployment at larger code distances.
Weight Distribution Analysis
Post-training weight probabilities show sharp bimodality, with nearly all irrelevant edges assigned probability near zero and optimal chains near one. This polarization is essential for downstream MWPM effectiveness and is induced by NMWPM's entropy-regularized objective.
Theoretical and Practical Implications
The successful integration of learned edge weight prediction with MWPM demonstrates that hybrid approaches can circumvent optimization bottlenecks in classical-quantum decoders. The proxy loss, strongly regularized for confidence, enables differentiable training even in the presence of non-differentiable downstream solvers.
From a theoretical perspective, the architecture leverages hierarchical information processing: local GNN layers extract geometry-aware syndrome features while Transformer layers resolve lattice-scale dependencies, supporting accurate recovery of logical states even under correlated, device-specific noise.
Practically, NMWPM's consistent advantage over generic MWPM across multiple codes and noise models suggests strong robustness and adaptability for near-term fault-tolerant experiments. The architectural modularity allows for plug-and-play adaptation to alternative codes and syndrome topologies (see Figure 4 for toric code layout).
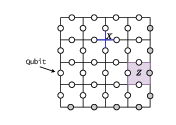
Figure 4: Toric code layout (L=4) showing the periodic topology and stabilizer assignment, underpinning syndrome graph construction in NMWPM.
Future Directions
- Generalization to Realistic Noise Models: The model architecture is readily extensible to non-Markovian, hardware-specific, and spatially correlated errors, further enhancing experimental utility.
- Scalability: The parameter-efficient design supports extension to larger lattice sizes.
- Hybrid Classical-Quantum Decoders: The differentiable surrogate approach opens the path to integrating other discrete optimization decoders (e.g., union-find, tensor-network decoders) with neural prediction engines.
- Hardware Implementation: The reduced logical error rate and parameter efficiency improve the practical prospects for real-time decoding on quantum microarchitectures or classical co-processors.
Conclusion
The Neural Minimum Weight Perfect Matching framework provides a formally principled and empirically validated approach to enhance quantum error decoding by bridging geometric deep learning and classical combinatorial optimization. The demonstrated LER improvements, threshold proximity to theoretical bounds, and efficient model scaling signal a substantive advance for hybrid AI-driven QEC. This methodology generalizes beyond surface/toric codes and provides a blueprint for developing practical, adaptable, and high-performance decoders central to the future of large-scale quantum computation.