- The paper demonstrates that a minute fraction of parallel bilingual documents is critical, as its inclusion restores up to 91% of BLEU performance lost without such data.
- Experimental results reveal that code-switched documents yield only marginal BLEU score improvements, while monolingual pretraining preserves robust sentence-level semantic alignment.
- The findings imply that curating high-quality parallel corpora is more impactful than abundant code-switched content, guiding resource allocation in multilingual LLM pretraining.
The Role of Mixed-Language Documents in Multilingual LLM Pretraining
Motivation and Problem Statement
The multilingual capabilities of LLMs pretrained on large-scale web corpora have been widely demonstrated, yet the specific mechanisms and data requirements underlying cross-lingual transfer remain inadequately disentangled. In particular, the community has typically assumed that the presence of mixed-language documents—spanning parallel translations, code-switching, and miscellaneous bilingual text—uniformly supports cross-lingual competence, especially for transfer and machine translation. However, the actual contribution of these various types of bilingual exposure during pretraining lacks systematic quantification.
This work provides a granular analysis of the role of mixed-language documents by constructing both a monolingual corpus (MonoWeb) with all multilingual documents filtered out and controlled bilingual reintroductions into this baseline. The pretraining and evaluation protocol isolates the impact of parallel and code-switched documents on machine translation, cross-lingual QA, and multilingual understanding/reasoning tasks.
Pretraining Corpus Construction and Categorization of Bilingual Data
The authors build their corpus by sampling 60B tokens per language from FineWeb-Edu (English) and FineWeb2 (German, Spanish, French), resulting in a 240B-token multilingual corpus. Bilingual documents are identified through a two-stage process: entropy-based rule filtering across sentence-level fastText language predictions, followed by a Llama-3.3-70B-Instruct classifier for semantic categorization.
Bilingual documents are subdivided into:
- Parallel: Segment-level alignment across languages (typically translations), ~14% of the bilingual subset.
- Code-switching: Natural alternation of languages within discourse, ~72%.
- Miscellaneous: Boilerplate or noise without functional semantic alignment, ~14%.
Notably, bilingual documents account for just 2% of the corpus, and most are user-generated, code-switched content, while parallel data are concentrated in academic, dictionary, and professional sources.
Experimental Design
Multilingual LLMs (1.35B parameters, Llama-2 tokenizer) are pretrained from scratch under four conditions for each language pair (en-fr, en-de, en-es):
- FineWeb: Complete corpus including all bilingual documents.
- MonoWeb: All bilingual documents removed.
- MonoWeb+Parallel: Only parallel documents reintroduced.
- MonoWeb+CodeSwitch: Only code-switched documents reintroduced.
A downstream suite covers: machine translation (WMT, FLORES), cross-lingual QA (XQuAD, MLQA), and general reasoning (XNLI, PAWS-X, HellaSwag, ARC, TruthfulQA, XStoryCloze, XWinograd).
Main Empirical Findings
Machine Translation: Critical Sensitivity to Parallel Data
Removing all bilingual data (MonoWeb) results in a 56% drop in BLEU score for machine translation (e.g., from 22.3 to 9.8 BLEU in aggregate), revealing an acute dependence on parallel documents despite their being less than 0.3% of the entire corpus. The reintroduction of parallel data (MonoWeb+Parallel) restores 91% of original BLEU performance (20.2 BLEU), while code-switching documents provide only marginal improvement (MonoWeb+CodeSwitch, 12.4 BLEU)—even though they are the majority of the bilingual subset.
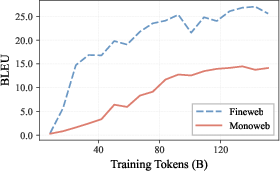
Figure 1: Machine translation performance on WMT14 is almost entirely determined by the inclusion of parallel data in pretraining.
Further analysis demonstrates profound degradation of both output language fidelity (models fail to produce target language text in 55% of cases without parallel data) and semantic adequacy (severe underspecification at the lexical level), even when the core meaning is preserved. This failure mode shows translation collapse is not just a function of modeling the target language, but of establishing robust lexical alignment.
Cross-Lingual QA and Reasoning: Minimal Sensitivity to Bilingual Documents
In stark contrast, the removal of all mixed-language data produces only a moderate (≤10%) decline in cross-lingual QA (XQuAD), with MLQA and all tested reasoning tasks (XNLI, PAWS-X, HellaSwag, ARC, etc.) showing negligible or no loss relative to the full bilingual exposure setup.
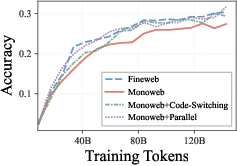
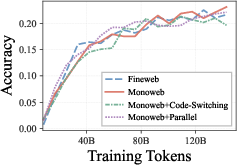
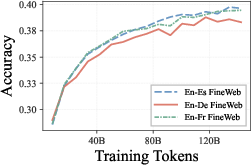
Figure 2: XQuAD (a) shows some separation by dataset, but MLQA (b) and HellaSwag (d) show nearly overlapping results, indicating limited dependence on bilingual pretraining data.
This cross-task asymmetry is underpinned by representational analyses: removing mixed-language documents disrupts lexical-level cross-lingual alignment (cosine similarity on mapped word pairs), but sentence-level semantics remain robustly aligned from monolingual data alone. This explains why high-level understanding and reasoning transfer is immune to the collapse observed in machine translation.
Implications and Theoretical/Practical Consequences
These findings invalidate the assumption that simple code-switched exposure or general mixed-language noise provides significant gains for translation capacity or for cross-lingual transfer at large. Instead, explicit token-level alignment (parallel data) is necessary and sufficient for robust machine translation, whereas most cross-lingual tasks relying on semantics, abstraction, or reasoning do not require any bilingual documents in pretraining.
From an engineering standpoint, this indicates that efforts and resources for multilingual LLM pretraining should focus on curating high-quality parallel corpora (even at small scale) to boost translation performance, rather than augmenting with more code-switched or incidental bilingual content. For interpretability, these results reinforce the notion that sentence-level representations are shaped by higher-level task objectives and can be aligned even without explicit cross-lingual supervision.
Future Directions
Open questions remain on the scaling of these effects to larger model sizes (e.g., 7B+ parameters, more general pretraining scale laws), to typologically distant or low-resource languages, and with finer-grained control of document type, domain, and noise. Extending this work to broader language families, synthetic alignment data, or other pretraining objectives could further delineate the conditional requirements for LLM cross-lingual transfer.
Conclusion
This study provides a decisive quantification of the functional roles of mixed-language documents for multilingual LLM pretraining. It demonstrates that accurate machine translation is critically dependent on a minute fraction of parallel bilingual documents, while higher-level cross-lingual understanding and reasoning tasks remain largely agnostic to bilingual exposure. The implications span both the design of multilingual corpora and the theoretical understanding of alignment phenomena in LLMs, establishing the necessity of explicit parallel data for translation while showing the surprising sufficiency of monolingual data for semantic transfer.