- The paper introduces a four-axis design framework that structures multi-hop QA by coupling retrieval and reasoning processes.
- It details various execution paradigms, such as interleaved retrieval and plan-driven strategies, linking them to improved performance on benchmarks.
- The study highlights empirical trends that reveal trade-offs between answer accuracy, computational cost, and resource constraints, guiding future research.
Retrieval–Reasoning Processes in Multi-hop Question Answering: A Four-Axis Framework and Synthesis
Introduction
Multi-hop question answering (QA) critically tests algorithmic capabilities in information retrieval and compositional reasoning, demanding systems to select, integrate, and reason over distributed evidence. The surveyed paper introduces a framework that moves beyond traditional architecture- or component-based taxonomies: it codifies the procedural coupling of retrieval and reasoning as the primary analysis unit, presenting a four-axis schema comprising (A) overall execution plan, (B) index structure, (C) next-step execution plan, and (D) stop/continue criteria. This explicit process-oriented abstraction offers a systematic lens to analyze diverse emerging approaches and highlights empirical tendencies, trade-offs, and open challenges within multi-hop QA.
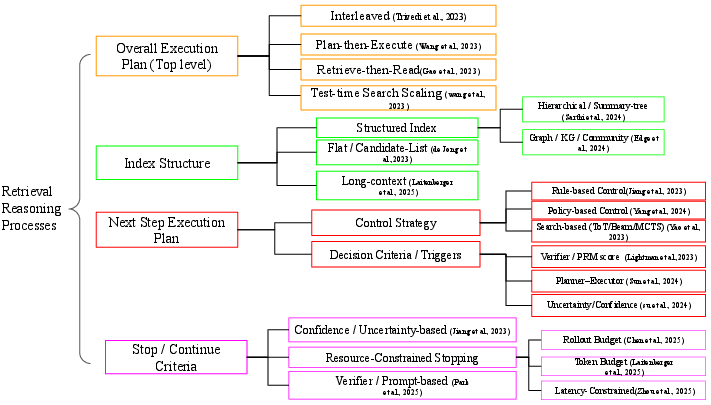
Figure 1: Overview of the four design axes used to describe retrieval–reasoning processes in multi-hop QA: (A) overall execution plan, (B) index structure, (C) next-step execution plan, (D) stop/continue criteria.
Motivation for Explicit Retrieval–Reasoning Procedures
Treating multi-hop QA as an explicit, stepwise retrieval–reasoning process addresses both empirical and conceptual gaps. A fixed, single-pass retrieval regimen often fails under adversarial distractors or hybrid evidence requirements (e.g., in HotpotQA, 2WikiMultiHopQA, MuSiQue), motivating procedural flexibility. Recent approaches—interleaving retrieval with chain-of-thought (CoT) reasoning, introducing agentic tool calls, or elevating stop/continue into learned behaviors—link observed improvements in accuracy, robustness, and evidence faithfulness directly to the structure of the retrieval–reasoning loop, rather than to static system components.
Four-Axis Design Framework
Axis A: Overall Execution Plan
The execution plan defines when retrieval is invoked with respect to reasoning. Four archetypes are prominent:
- Retrieve–then–Read: Traditional, single-pass retrieval provides all evidence to a reader/generator (e.g., DrQA, DPR+FiD, RAG). Multi-hop QA extensions like MDR still adhere to this pattern.
- Interleaved Retrieval and Reasoning: Systems alternate reasoning steps and retrievals, often prompting with intermediate sub-questions or state updates (e.g., IRCoT, ReAct, Self-Ask, DRAGIN).
- Plan–then–Execute: These methods decompose questions into sub-hops or plans which are then sequentially executed (e.g., Decomposed Prompting, Plan-and-Solve, QDMR-based QA, BEAM Retrieval, PAR-RAG).
- Test-time Search Scaling: The retrieval–reasoning process is treated as a combinatorial search problem, exploring multiple trajectories via strategies such as Tree-of-Thoughts, Monte-Carlo Tree Search (MCTS), or beam search (e.g., MindStar, MCTS-DPO, RAP, GraphRAG).
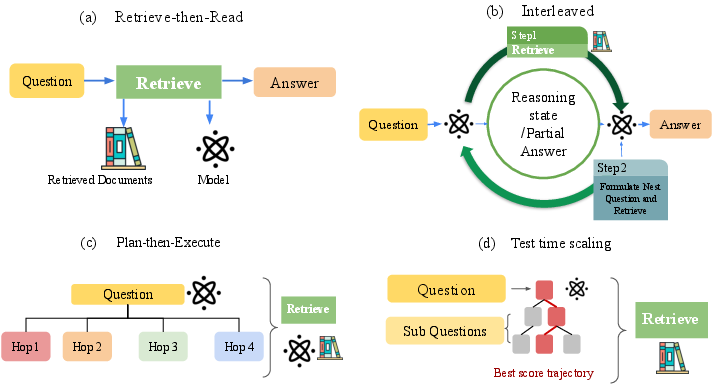
Figure 2: Major execution plans: (a) Retrieve–then–Read, (b) Interleaved, (c) Plan–then–Execute, (d) Test-time search scaling.
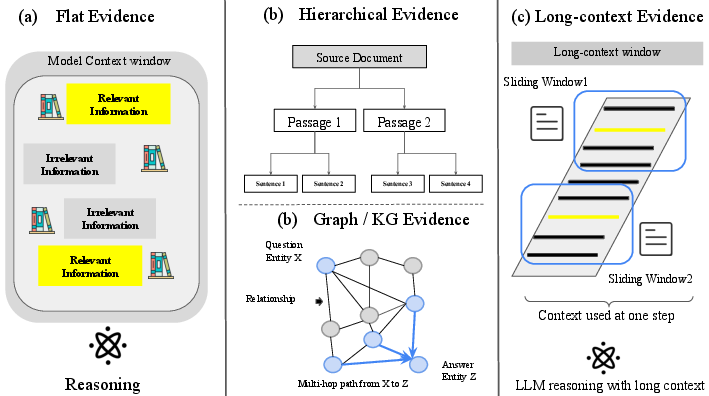
Axis B: Index Structure
The organization and accessibility of external knowledge is governed by index structure:
Axis C: Next-Step Execution Plan
Control policies governing the next action (retrieve, reason, verify, or quit) vary along a spectrum:
- Rule-based: Hard-coded reasoning rhythms, query patterns, and retrieval triggers (e.g., Self-Ask, ReAct).
- Policy-based: Learned strategies, responsive to state and history, potentially combining supervised or RL signals (e.g., BEAM Retrieval, policy-driven RAG agents).
- Search-based: Expansion and scoring of multiple candidate reasoning trees or paths (Tree-of-Thoughts, MCTS-based methods).
- Verifier/PRM-gated: Intermediate outputs are scored by verifiers (NLI/PRM models, critics); low-confidence or unfaithful solutions prompt further action.
- Uncertainty/confidence triggers: Quantitative measures (entropy, consensus variance) guide continuation or termination.
Axis D: Stop/Continue Criteria
Terminating the retrieval–reasoning sequence is typically handled by:
- Resource-based Budgets: Hard constraints on hops, tokens, or latency. Most systems (over 90% of those analyzed) employ explicit budgets.
- Confidence/Uncertainty-based: Procedures halt when answer confidence or evidence sufficiency surpasses a threshold.
- Verifier-based: Output passes an explicit evidence verifier; failing verification triggers loop continuation.
- Progress/completeness heuristics: Execution plans complete when a pre-specified decomposition or plan is exhausted.
Empirical Trends and Numerical Results
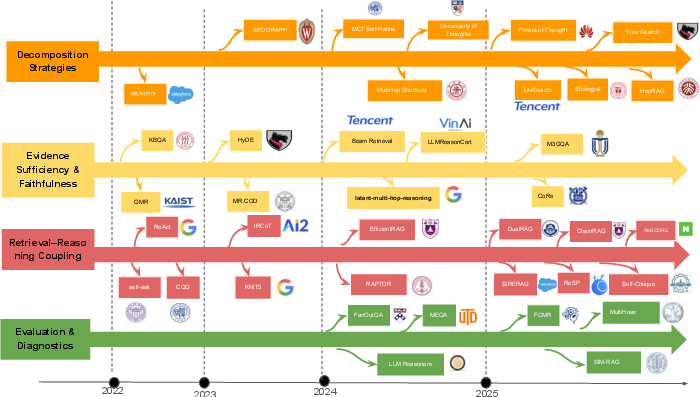
Empirical synthesis across over 100 multi-hop QA systems using these axes reveals strong tendencies:
- Interleaved and plan-driven execution plans consistently outperform retrieve–then–read baselines in both answer and support F1, notably in distractor-heavy scenarios. For example, BEAM Retrieval achieves 69.2 answer F1 / 91.4 support F1 on MuSiQue, and PAR-RAG yields HotpotQA and 2WikiEM gains of 15–30 points over non-plan-driven baselines (at matched or smaller budgets).
- Test-time search scaling—as in Tree-of-Thoughts or MCTS—boosts long-horizon QA accuracy but incurs substantial inference cost.
- Graph-/KG-style indices improve evidence coherence and joint answer+path metrics on benchmarks like GraphRAG and KG-o1, although they introduce complexity in index maintenance.
- Policy-based and verifier/PRM-based control stabilizes answer faithfulness and boosts joint answer+evidence scores, particularly in noisy/long-horizon or OOD regimes.
- Static hop/token budgets, while competitive in tuned settings, degrade under transfer/distribution shift compared to value-based or adaptive controllers.
Open Problems and Future Directions
Key unresolved challenges include:
Conclusion
This comprehensive framework recasts retrieval–reasoning procedures in multi-hop QA as a structured, multidimensional design space, abstracting from low-level architectural details to procedural regularities. Explicit axis-based analysis exposes the dependence of effectiveness and faithfulness on both procedural design and knowledge organization, justifying a shift from passive retrieval pipelines to adaptive, process-centered agents. Future research hinges on developing structure-aware, adaptive controllers and learning robust, transferable stopping/continuation mechanisms, particularly as domain, corpus, and model scale increase.
Citation: "Retrieval--Reasoning Processes for Multi-hop Question Answering: A Four-Axis Design Framework and Empirical Trends" (2601.00536)