- The paper introduces BSAT, a novel method that uses B-spline curves to adaptively tokenize time series data for improved forecasting accuracy.
- BSAT dynamically increases token density in high-curvature regions, reducing computational complexity from O(L²) to O(n²).
- Integration of hybrid positional encoding with BSAT further enhances transformer performance in capturing diverse temporal dependencies.
"BSAT: B-Spline Adaptive Tokenizer for Long-Term Time Series Forecasting" (2601.00698)
Introduction and Motivation
The challenge of long-term time series forecasting using transformers primarily lies in the quadratic complexity of self-attention and the inadequacy of uniform patch segmentation in capturing the intricacies of temporal data. Traditional methods, such as PatchTST, offer a uniform segmentation approach that inadvertently divides significant temporal patterns, thereby inefficiently allocating computational resources. This paper introduces the B-Spline Adaptive Tokenizer (BSAT), which dynamically aligns tokens with the data's semantic structure for enhanced forecasting accuracy. Leveraging B-splines, BSAT adaptively places more tokens in high-curvature regions, thus optimizing computational precision and resource allocation.
Methodology
BSAT: B-Spline Adaptive Tokenizer
BSAT presents a novel tokenization framework designed to segment time series adaptively. By fitting the time series with B-spline curves, BSAT places higher token density in regions exhibiting greater complexity. This method enables efficient representation through fixed-size tokens, facilitating a reduction in computational complexity from O(L2) to O(n2). The algorithm determines token positions via knot placement at equal curvature quantiles, increasing token density where necessary.
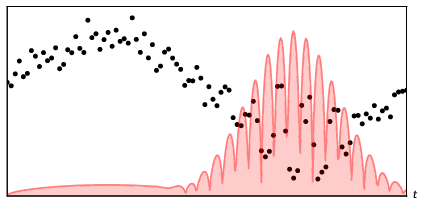
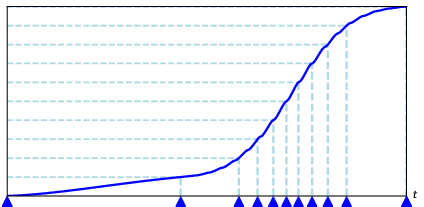
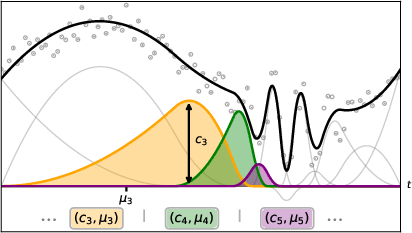
Figure 1: Visualization of BSAT mapping 100 points into 12 tokens. Knot placement is densest in high-curvature segments.
BSAT's adaptability to both densely and sparsely sampled time series is achieved via modified feature functions and adaptive clip factors for knot placement. The introduction of coefficient clipping and caching further enhances stability and efficiency.
Hybrid Positional Encoding
To complement BSAT's adaptive tokenization, the authors propose a hybrid positional encoding strategy, integrating learnable positional encoding with layer-wise rotary positional embedding (L-RoPE). This dual approach effectively captures diverse temporal dependencies, allowing each transformer layer to specialize in detecting distinct frequency patterns, thereby enhancing model performance under varying dataset structures and token budgets.
Experimental Results
The performance of BSAT was evaluated across multiple well-known time series datasets, including ETTh1, Alabama PV, and ECL. The experiments demonstrated BSAT's superior performance, especially at low token budgets, due to its effective compression and computational efficiency. BSAT consistently outperformed both Uniform Down Sampled Transformer (UDS) and PatchTST approaches, with notable gains in datasets characterized by low total variation and curvature.
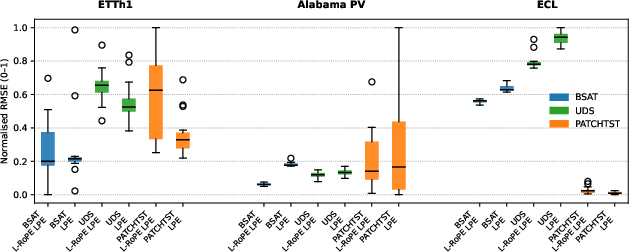
Figure 2: RMSE box-plot for token budget 45, showing the distribution of the top 15 runs for each configuration.
The hybrid positional encoding further improved accuracy, particularly in datasets with strong periodic patterns like Alabama PV. In scenarios demanding computational efficiency, BSAT substantially reduced model size while maintaining strong performance metrics.
Discussion and Implications
BSAT's adaptive tokenization and hybrid positional encoding represent a significant advancement in time series forecasting methodologies. Its ability to effectively handle long sequences with high compression rates makes it particularly suited for applications with stringent memory constraints. The research provides insights into optimizing temporal dependencies and setting a precedent for future exploration in adaptive learning mechanisms.
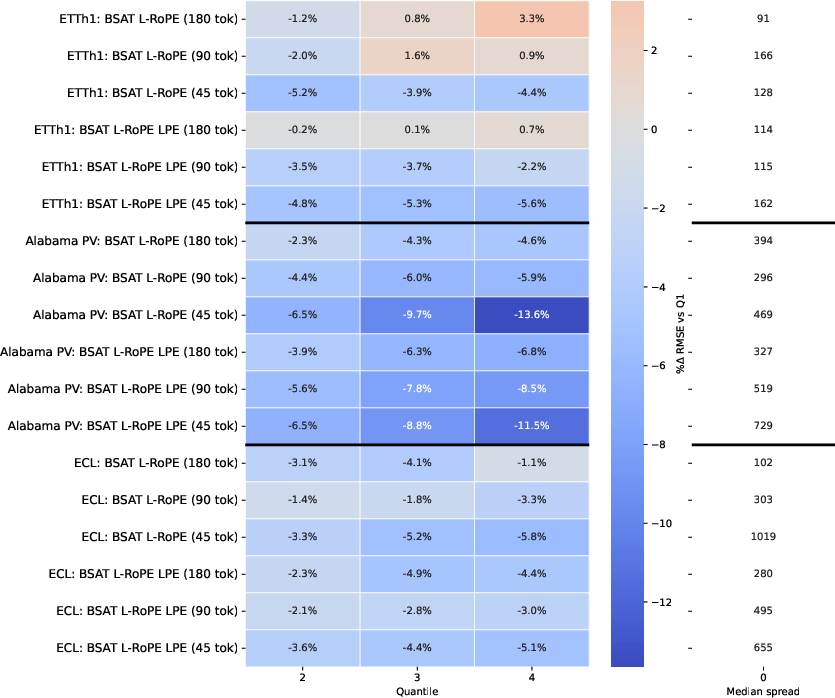
Figure 3: Effect of learned RoPE base diversity indicating performance improvements with increased variability in RoPE bases.
Future Directions
Future work could explore enhancing BSAT's numerical stability in volatile datasets further. Potential enhancements include modifications to knot placement algorithms for guaranteeing well-conditioned least-square fits and incorporating end-to-end learnability through a flexible B-spline fitting model. Additionally, the divergence behavior of RoPE base frequencies suggests further scope for optimizing attention patterns, paving the way for more sophisticated hybrid embedding schemes.
Conclusion
The introduction of the B-Spline Adaptive Tokenizer alongside a hybrid positional encoding strategy offers a robust solution to the intricacies of long-term time series forecasting. BSAT's novel approach to tokenization and positional encoding sets a new benchmark for efficiency and accuracy in transformer-based models, providing a foundation for continued research and progress in this domain.