Revisiting Weighted Strategy for Non-stationary Parametric Bandits and MDPs
Published 3 Jan 2026 in cs.LG and stat.ML | (2601.01069v1)
Abstract: Non-stationary parametric bandits have attracted much attention recently. There are three principled ways to deal with non-stationarity, including sliding-window, weighted, and restart strategies. As many non-stationary environments exhibit gradual drifting patterns, the weighted strategy is commonly adopted in real-world applications. However, previous theoretical studies show that its analysis is more involved and the algorithms are either computationally less efficient or statistically suboptimal. This paper revisits the weighted strategy for non-stationary parametric bandits. In linear bandits (LB), we discover that this undesirable feature is due to an inadequate regret analysis, which results in an overly complex algorithm design. We propose a \emph{refined analysis framework}, which simplifies the derivation and, importantly, produces a simpler weight-based algorithm that is as efficient as window/restart-based algorithms while retaining the same regret as previous studies. Furthermore, our new framework can be used to improve regret bounds of other parametric bandits, including Generalized Linear Bandits (GLB) and Self-Concordant Bandits (SCB). For example, we develop a simple weighted GLB algorithm with an $\tilde{O}(k_μ{5/4} c_μ{-3/4} d{3/4} P_T{1/4}T{3/4})$ regret, improving the $\tilde{O}(k_μ{2} c_μ{-1}d{9/10} P_T{1/5}T{4/5})$ bound in prior work, where $k_μ$ and $c_μ$ characterize the reward model's nonlinearity, $P_T$ measures the non-stationarity, $d$ and $T$ denote the dimension and time horizon. Moreover, we extend our framework to non-stationary Markov Decision Processes (MDPs) with function approximation, focusing on Linear Mixture MDP and Multinomial Logit (MNL) Mixture MDP. For both classes, we propose algorithms based on the weighted strategy and establish dynamic regret guarantees using our analysis framework.
The paper presents a unified regret analysis that simplifies bias-variance decomposition for weighted estimators in drifting linear bandits and MDPs.
It achieves tighter regret bounds across models like GLB, SCB, and MNL mixture MDPs, significantly improving computational efficiency.
Empirical results show that the weighted method outperforms restart and sliding-window schemes in gradually drifting setups.
Revisiting Weighted Strategy for Non-stationary Parametric Bandits and MDPs
Introduction and Motivation
This paper addresses the limitations and analytical complexity within weighted strategies for non-stationary parametric bandits and reinforcement learning in Markov Decision Processes (MDPs). Existing approaches—in particular for drifting environments—have commonly relied on three main strategies: sliding-window, weighted, and restart-based adaptation. Though weighted schemes are empirically effective for realistic, gradually drifting non-stationary environments, prior theoretical analysis often lags behind their window/restart-based counterparts in both regret guarantees and computational efficiency.
The central insight is that these deficiencies stem from unnecessarily involved bias-variance decompositions, often employing multiple local norms and bespoke concentration inequalities specific to the weighted setup. The paper proposes a refined framework enabling a unified and computationally efficient regret analysis for weighted algorithms, closing theoretical gaps and improving the tightness of regret bounds. The framework is then systematically applied to Linear Bandits (LB), Generalized Linear Bandits (GLB), Self-Concordant Bandits (SCB), as well as function-approximation-based MDPs including Linear Mixture MDPs and Multinomial Logit (MNL) Mixture MDPs.
Analytical Framework and Algorithmic Innovations
The authors introduce a new, streamlined analysis for weighted estimators. The key insight is to reparameterize the regret and estimation bounds so that both the bias (due to parameter drift) and variance (due to stochastic noise) can be analyzed within the same local norm (typically the inverse empirical covariance), dispensing with prior requirements for sliding-window mimicking, virtual window sizes, or multiple covariance matrices. This simplification is not only theoretically significant, but also yields tangible algorithmic efficiency.
In the canonical drifting Linear Bandit setting, the proposed estimator for θt is a weighted regularized least squares, solved recursively with a single covariance update: θ^t=Vt−1−1(s=1∑t−1wt−1,srsXs)
where weights wt,s=γt−s. Theoretically, the estimation error is bounded as: ∣x⊤(θ^t−θt)∣≤x⊤Vt−1−1(At+Bt)
with At (bias) and Bt (variance) now simultaneously controlled. This allows the practical design of weighted-UCB-type algorithms which only require one covariance matrix as state, improving runtime and memory costs.
Crucially, this approach generalizes across model classes:
For GLB, the complicated projection mechanisms of prior work (e.g., for self-concordant link functions or logistic bandits) are rendered unnecessary—the refined bias analysis means a norm-compatible projection suffices.
For non-stationary MDPs with function approximation (Linear/MNL Mixture MDPs), similar techniques enable the construction of the first weighted methods with dynamic regret guarantees that match restart-based results.
Strong Theoretical Claims
For drifting GLB, the regret improves from prior $\Ot(k_\mu^2 c_\mu^{-1} d^{9/10} P_T^{1/5} T^{4/5})$ to $\Ot(k_\mu^{5/4} c_\mu^{-3/4} d^{3/4} P_T^{1/4} T^{3/4})$.
For SCB, the dependency on the self-concordance parameter cμ drops from cμ−1 to cμ−1/2; for piecewise-stationary SCB, the influence of cμ disappears altogether.
For both linear and MNL mixture MDPs, the weighted algorithms yield the same regret scaling as the best-known dynamic regret bounds (e.g., $\Ot(Hd\Delta^{1/4}T^{3/4})$), and the latter is established for the first time in the literature.
Empirical Results
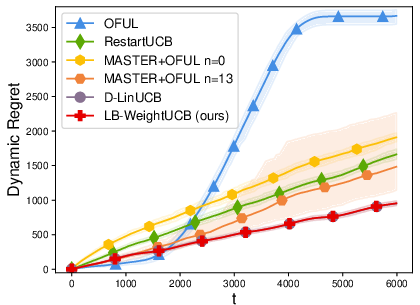
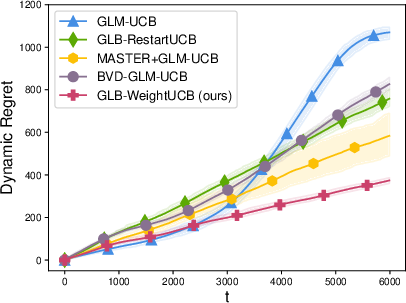
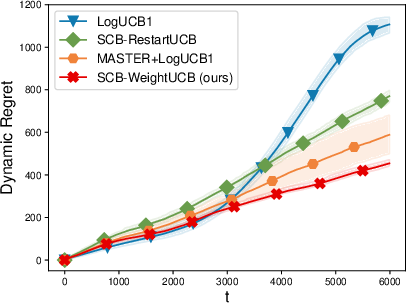
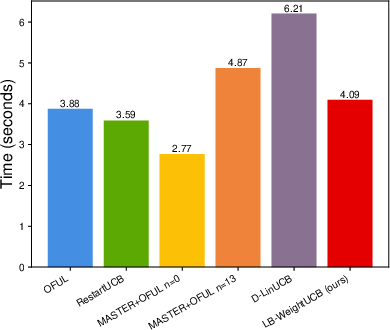
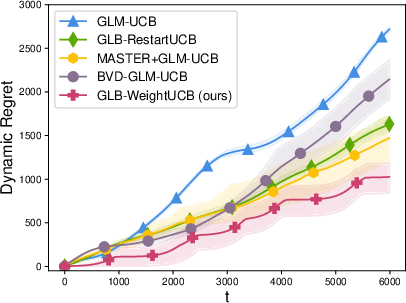
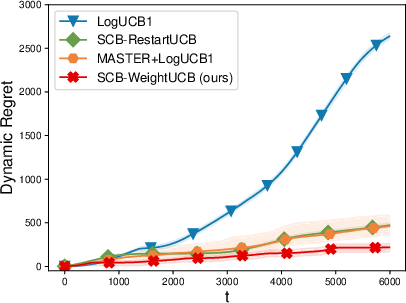
Extensive simulations corroborate the theoretical findings. On slowly drifting LB and GLB problems, the proposed weighted approach matches or outperforms restart/sliding-window schemes in cumulative regret while substantially reducing computational overhead.
Figure 1: Summary of cumulative regret and runtime profiles in generalized linear bandit and SCB experiments, showing the weighted strategy obtains lower regret with higher efficiency compared to restart-based and sliding-window methods.
Weighted methods also demonstrate robustness to the choice of drift parameters and significantly outperform restart-based methods in practical, gradually drifting setups. When the non-linearity constants of the GLB/SCB are high, the benefit in regret gap and computational efficiency grows more pronounced.
Implications and Outlook
The main theoretical implication is that weighted strategies for non-stationary bandits and MDPs can now attain regret guarantees matching those of window/restart strategies but with improved computational efficiency and analytic regularity. Additionally, the bias-variance decomposition provided here is more general—simplifying adaptation to new model classes, such as generalized bandits with complex link functions, or sophisticated MDPs with functional richness in transition and reward representations.
Despite these advances, the optimal minimax regret in the presence of unknown or varying non-stationarity (as captured by pathlength PT or other drift metrics) remains an open question for the weighted family. In particular, while MASTER and adaptive-restart strategies can achieve O(PT1/3T2/3) without prior knowledge, no such result is shown here for weighted schemes, nor for the time-varying arm set case. Designing adaptive weighted approaches that achieve these optimal rates without tuning or environmental assumptions is a compelling future direction.
Another important open issue is refining the measure of gradual drift in practical environments—the standard pathlength PT may be too coarse, and future work may benefit from leveraging higher-order regularity measures (e.g., Sobolev or Hölder regularity) or information-theoretic quantities more sensitive to truly gradual change.
Conclusion
This work provides a unifying, efficient analytic framework for weighted strategies in non-stationary parametric bandits and RL with function approximation, delivering both improved theoretical regret bounds and substantially simpler, faster algorithms. The results close substantial gaps in the literature for GLB, SCB, and MDPs, and open broad possibilities for further exploration in adaptive, environment-agnostic non-stationary learning.