RovoDev Code Reviewer: A Large-Scale Online Evaluation of LLM-based Code Review Automation at Atlassian
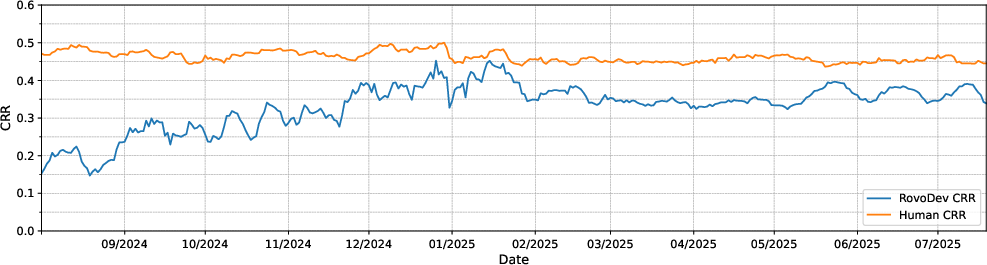
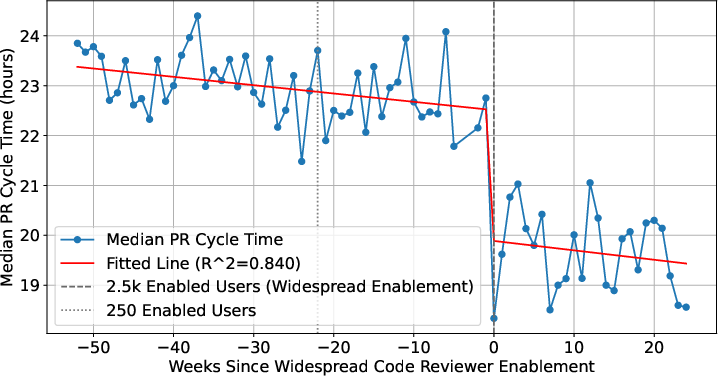
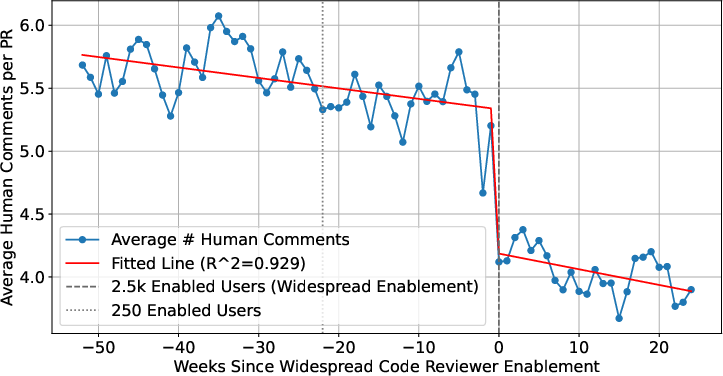
Abstract: LLMs-powered code review automation has the potential to transform code review workflows. Despite the advances of LLM-powered code review comment generation approaches, several practical challenges remain for designing enterprise-grade code review automation tools. In particular, this paper aims at answering the practical question: how can we design a review-guided, context-aware, quality-checked code review comment generation without fine-tuning? In this paper, we present RovoDev Code Reviewer, an enterprise-grade LLM-based code review automation tool designed and deployed at scale within Atlassian's development ecosystem with seamless integration into Atlassian's Bitbucket. Through the offline, online, user feedback evaluations over a one-year period, we conclude that RovoDev Code Reviewer is effective in generating code review comments that could lead to code resolution for 38.70% (i.e., comments that triggered code changes in the subsequent commits); and offers the promise of accelerating feedback cycles (i.e., decreasing the PR cycle time by 30.8%), alleviating reviewer workload (i.e., reducing the number of human-written comments by 35.6%), and improving overall software quality (i.e., finding errors with actionable suggestions).


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The study leaves several aspects unresolved. Future work could address:
- External validity beyond Atlassian: Evaluate RovoDev across other organizations, open-source repositories, and diverse development workflows to determine generalizability of observed benefits (CRR, PR cycle time, reduced human comments).
- Comparative baselines: Benchmark RovoDev against fine-tuned LLMs, RAG-based systems, static analyzers/linters, and rule-based reviewers; include head-to-head comparisons under identical conditions.
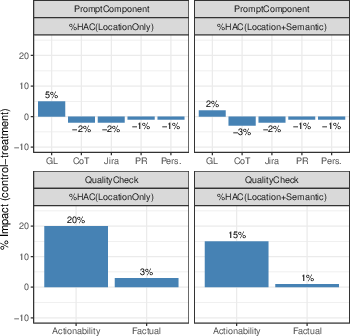
- Component ablation: Quantify the marginal impact of each pipeline element (persona, review guidelines, chain-of-thought, factual-correctness judge, actionability gate) via controlled ablation studies.
- Reliability of LLM-as-a-Judge: Validate the factual-correctness and semantic-similarity judges against expert human annotations; report precision/recall, calibration, inter-annotator agreement, and failure modes (e.g., adversarial or ambiguous code changes).
- Actionability gate performance: Provide model metrics (AUC, precision/recall, calibration curves) and cross-project generalization for the ModernBERT quality gate; assess bias introduced by training on “comments that led to resolution” and quantify false positives/false negatives (useful comments filtered out or poor comments passed).
- Definition and detection of “code resolution”: Disclose the algorithm used to link comments to subsequent code changes, handle multi-line edits, merges, reverts, and unrelated commits; quantify linkage accuracy and ambiguity.
- Causal inference on PR cycle time and human comments: Replace observational analyses with randomized A/B tests or difference-in-differences/synthetic control designs to isolate causal effects and control for concurrent process changes or tooling rollouts.
- Downstream software quality: Measure post-merge defect rates, security vulnerabilities, rework/churn, rollback frequency, and long-term maintainability to ensure accelerated cycles don’t degrade quality.
- Negative side effects and risk: Quantify harms from incorrect or non-actionable comments (e.g., wasted effort, misguidance), cognitive load, and trust erosion; establish safeguards and escalation paths for high-risk suggestions.
- Language and framework coverage: Systematically evaluate performance across programming languages, frameworks, and stacks; address misclassification (e.g., PHP vs JavaScript) with robust language detection and stack-specific prompts/models.
- Context limitations: Investigate context enrichment strategies under LLM context-window constraints (e.g., code graphs, dependency summaries, semantic slicing), and compare zero-shot prompting to lightweight RAG in cold-start projects.
- Comment type distribution and prioritization: Analyze which categories (bugs, readability, maintainability, tests, security) RovoDev handles well or poorly; tune the pipeline to avoid overemphasis on nitpicks and under-detection of high-impact issues.
- Operational cost and latency: Report inference latency, computational cost per PR, throughput under load, and the impact on developer wait times; conduct cost–benefit analyses at scale.
- Privacy and compliance trade-offs: Clarify how ModernBERT fine-tuning on proprietary data complies with privacy constraints; assess risks of data leakage, model inversion, and retention policies; provide guidance for deployments with stricter regulatory requirements.
- Prompt transparency and reproducibility: Share prompt templates (or sanitized variants), review guidelines, and configuration details to enable replication; evaluate sensitivity to prompt variations and drift over time.
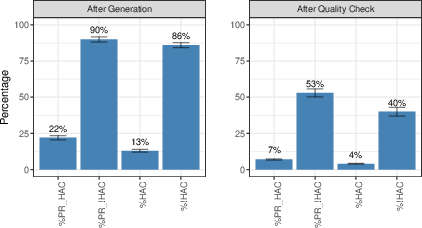
- Interpretation of low human alignment: With only ~4% HAC, investigate whether divergence from human-written comments reflects better or worse utility; develop utility-focused metrics beyond textual similarity and location matching.
- Feedback collection robustness: Improve mechanisms for gathering fine-grained user feedback (beyond low click-through on thumbs up/down), e.g., in-line rating prompts, structured surveys, and passive telemetry; address response bias.
- Security-specific effectiveness: Evaluate RovoDev’s ability to detect security vulnerabilities, insecure patterns, and compliance violations; compare against dedicated security tools and secure coding checklists.
- Cold-start vs mature projects: Empirically test performance in repos with limited history versus mature codebases; identify strategies that mitigate lack of prior context.
- Developer learning and team dynamics: Study impacts on reviewer skill development, knowledge transfer, mentoring, and psychological safety; ensure automation doesn’t erode essential human aspects of code review.
- Governance and explainability: Define processes for accountability, traceability, and explainability of automated comments; provide rationale summaries and confidence indicators to support human oversight.
Collections
Sign up for free to add this paper to one or more collections.