LANCET: Neural Intervention via Structural Entropy for Mitigating Faithfulness Hallucinations in LLMs
Abstract: LLMs have revolutionized information processing, yet their reliability is severely compromised by faithfulness hallucinations. While current approaches attempt to mitigate this issue through node-level adjustments or coarse suppression, they often overlook the distributed nature of neural information, leading to imprecise interventions. Recognizing that hallucinations propagate through specific forward transmission pathways like an infection, we aim to surgically block this flow using precise structural analysis. To leverage this, we propose Lancet, a novel framework that achieves precise neural intervention by leveraging structural entropy and hallucination difference ratios. Lancet first locates hallucination-prone neurons via gradient-driven contrastive analysis, then maps their propagation pathways by minimizing structural entropy, and finally implements a hierarchical intervention strategy that preserves general model capabilities. Comprehensive evaluations across hallucination benchmark datasets demonstrate that Lancet significantly outperforms state-of-the-art methods, validating the effectiveness of our surgical approach to neural intervention.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tackles a common problem in big text-writing AIs (called LLMs, or LLMs): hallucinations. A “hallucination” is when the AI says something that sounds confident but is wrong. The authors focus on a special kind called faithfulness hallucinations—when the AI’s answer doesn’t stick to the information it was given (like making up details not in the passage).
They propose a new method, called LANCET, to reduce these mistakes without hurting the model’s normal skills. Think of it like performing precise surgery inside the AI’s “brain” to block the paths that cause errors, while leaving the healthy parts untouched.
The main questions the researchers asked
- How can we stop the AI from drifting away from the given context (improve faithfulness) without making it worse at telling true facts (factuality), or vice versa?
- Can we find exactly where hallucinations start inside the model and how they spread through its “neural pathways”?
- Can we “turn down” only the parts that spread the error, instead of shutting off whole sections that also do useful work?
How did they study the problem?
First, a quick idea: Inside an LLM, many “neurons” (tiny units) often do more than one job. If you bluntly turn off a neuron to fix one mistake, you might also break something else it was doing well. So the authors treat hallucinations like a rumor spreading through a school: it starts somewhere, travels along certain hallways, and reaches other students. LANCET tries to trace and block those rumor paths.
Here’s the approach, explained step by step:
- The method has three main stages:
- Find the sources: The team compares the model’s behavior when it answers correctly versus when it hallucinates. They use a “gradient” signal (think of it as a “blame meter”) to spot neurons that become especially influential during hallucinations. These are the “instigators.”
- Map the spread: They build a map (a graph) showing which neurons connect to which. They measure how much each connection becomes more tightly linked during hallucinations using a score called the Hallucination Difference Ratio (HDR). Then they group neurons into modules by minimizing something called structural entropy—basically, they arrange the map so the “rumor routes” are grouped together, separate from the healthy routes. In simple terms: they find which “hallways” the rumor uses, and separate those from normal hallways.
- Apply targeted fixes: Instead of turning off whole neurons, they gently scale down the strength of the most suspicious connections—strongest near the source, weaker farther away. This is like setting up a strong quarantine around the most infected rooms and lighter measures in the nearby halls, while leaving safe areas alone.
Key terms in everyday language:
- Gradient: A signal that shows which parts of the model had the most influence on the final answer—like a heat map of responsibility.
- HDR (Hallucination Difference Ratio): A number that tells how much a connection between two neurons “lights up” more during hallucinations than during normal, correct answers.
- Structural entropy: A measure of how mixed-up or well-separated the network’s routes are. Minimizing it helps neatly separate “bad” routes (hallucination paths) from “good” routes (normal reasoning paths).
Why is this approach needed?
Many past methods try to stop hallucinations by simply muting certain neurons or applying a broad “dampening” across the model. But neurons are often “polysemantic”—they do multiple jobs. If you silence one to stop an error, you may also break useful reasoning. That’s why some methods improve truthfulness about facts but badly hurt faithfulness to the given context (a trade-off).
The paper argues we should stop targeting single neurons and instead target the specific pathways that spread errors. It’s like blocking the rumor’s route (hallways) rather than suspending students who also do a lot of good.
What did they find? Why does it matter?
They tested LANCET on two models (LLaMA2-7B-Chat and DeepSeek-7B) and two benchmarks:
- TruthfulQA: tests whether answers are factually true.
- PDTB: tests whether answers stay faithful and consistent with given text (like following logical connections in a passage).
Main takeaways:
- Other methods often improve factuality but hurt faithfulness a lot. For example, in one setup, a popular method raised factuality but caused faithfulness to drop from about 17.4% to 5.8%.
- LANCET improved both at the same time. In the same setup, LANCET increased factuality (to about 53.7%) and also raised faithfulness (to about 27.6%), beating prior methods on both fronts.
Why it matters:
- It shows you don’t have to choose between truth and sticking to the context—you can improve both if you precisely block error pathways.
- This makes LLMs more reliable for tasks where both being correct and staying aligned with the given information are important (for example, medical or legal summaries).
What could this change in the future?
If widely adopted, LANCET’s “surgical” way of fixing models could:
- Make AI assistants safer and more trustworthy by cutting down on confident-but-wrong answers.
- Help developers debug models more precisely, keeping useful skills intact while removing harmful behaviors.
- Inspire new research that treats AI problems as network flows to be isolated, rather than bluntly turning parts on or off.
The authors note a couple of practical challenges—like needing certain paired data and the extra work to build and partition the graph. In the future, they plan to make the detection more automatic and the process lighter. Still, LANCET is a promising step toward AI systems that are both truthful and faithful, without sacrificing one for the other.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and could guide future research.
- Data dependence for instigator detection: The framework requires paired “hallucinatory vs factual” datasets to compute gradient differentials and HDR, but the paper does not specify how to obtain reliable labels at scale, how sensitive Lancet is to label noise, or how to operate when only unlabeled or weakly labeled data are available.
- Ambiguity in graph node/edge scope: The HDR-weighted graph is defined over the “instigator set” but the propagation pathways likely involve broader cross-layer and cross-component nodes. It is unclear whether the graph includes all neurons across layers, only within a layer, or specific components (e.g., attention heads vs MLP units), and how inter-layer edges are constructed.
- Directedness vs correlation: The graph is described as directed, yet HDR is built from Pearson correlations, which are symmetric and non-causal. A principled method to infer edge directionality (e.g., Granger causality, temporal cross-correlation, path-integrated gradients, or interventional tests) is missing.
- HDR stability and statistical rigor: No statistical testing or confidence estimation is provided for HDR values. How stable are HDR estimates across seeds, prompts, batches, or domains, and what thresholds control false positives/negatives in edge inclusion?
- Normalization and scale effects in importance scoring: The importance metric uses |θu ⋅ ∇θu L|, which is sensitive to parameter scaling and layer norms. Alternatives (e.g., parameter-normalized gradients, Fisher information, or influence functions) and their impact on instigator selection remain unexplored.
- Conflict resolution between protected and suppressed neurons: The method sets αu=1 for instigators and αu=0 for critical reasoning neurons, but does not specify what happens when a neuron is both an instigator and belongs to the protected critical set. A deterministic tie-breaking or multi-objective resolution is needed.
- Coverage of propagation pathways beyond instigators: If the graph is constructed only on the instigator set, misinformation pathways that pass through non-instigator neurons may be missed. How to expand the graph to capture full propagation while keeping computational costs manageable?
- Multi-layer topology modeling: The paper does not detail whether and how structural entropy is minimized over multi-layer, heterogeneous graphs (attention heads, MLP neurons, residual paths). A general method for building and partitioning a full-transformer topology is missing.
- Scalability and computational overhead: Structural Entropy minimization and per-neuron αu computation are not profiled for time and memory. How does Lancet scale to 70B+ models, MOE architectures, or long-context inference? What are practical complexity bounds and possible approximations?
- Static vs dynamic intervention: Lancet appears to produce a static parameter rescaling from offline analysis. The impact of dynamic, input-conditional intervention (e.g., computing per-input HDR/αu with online activations) on both effectiveness and latency remains open.
- Robustness to distribution shift: HDR and instigator detection are trained on specific datasets (PDTB, TruthfulQA). How robust is Lancet to novel domains, languages, modalities, or unseen hallucination types without re-computing the graph?
- Generality across architectures: Evaluations are limited to LLaMA2-7B-Chat and DeepSeek-LLM-7B. Applicability to RLHF-tuned models, instruction-optimized LLMs, MoE architectures, and encoder-decoder stacks is untested.
- Interaction with retrieval-augmented generation (RAG): The method’s effect on RAG pipelines, where faithfulness hinges on grounding to retrieved context, is not evaluated. Does Lancet improve or hinder grounding and citation behavior?
- Impact on broader capabilities and safety: Beyond PDTB and TruthfulQA, effects on reasoning benchmarks (e.g., GSM8K), coding tasks, calibration (ECE), toxicity, bias, helpfulness, and preference alignment are unknown.
- Hyperparameter selection without validation: The sensitivity analysis tunes r (instigator ratio) and λ (decay) on validation data. A procedure to choose these hyperparameters without labeled validation (e.g., bilevel optimization, unsupervised criteria, or robust defaults) is missing.
- Theoretical guarantees for topology-aware mitigation: The theory establishes polysemantic neurons via non-orthogonal gradients but does not provide guarantees that SE minimization isolates misinformation pathways or that αu will not impair hidden capabilities. Formal links between SE objectives and causal isolation are absent.
- Causal verification of identified pathways: The paper does not perform causal ablations (e.g., do-interventions on modules) to confirm that partitioned pathways indeed carry hallucinations rather than correlated but harmless signals.
- Evaluation granularity and interpretability: There is no visualization or case study demonstrating specific neurons/edges suppressed, token-level effects, or semantic alignment between identified pathways and erroneous outputs.
- Token- and step-level dynamics: HDR is computed over dataset activations, but hallucinations can arise transiently at specific decoding steps. How to incorporate temporal dynamics, per-token attribution, and step-wise interventions?
- Persistence and retraining effects: After rescaling parameters, how do subsequent fine-tuning, continued pretraining, or RLHF affect the Lancet-induced topology? Will the network re-learn suppressed pathways, and can Lancet be made training-compatible?
- Statistical significance and variance reporting: Reported improvements lack significance tests and comprehensive variance analysis across seeds/runs. Establishing statistical robustness would strengthen claims.
- Fairness and comprehensiveness of baselines: Baseline methods were “reproduced using official implementations,” but it is unclear whether hyperparameters were re-tuned per model/dataset for strong baselines. A stronger ablation of decoding/intervention combinations and ensembles is missing.
- Applicability to closed-source models: Lancet relies on gradient access and internal activations. A pathway to apply similar interventions to API-only models without parameter/gradient access is not provided.
- Failure mode analysis: The paper notes a “trade-off” but lacks systematic error analysis of residual failures after Lancet (e.g., types of hallucinations that persist, contexts where faithfulness still drops, or adversarial prompts that bypass the intervention).
- HDR denominator and instability: The normalization by max(|ρfact|, ε) can inflate HDR when |ρfact| is small; guidance on ε, regularization, or robust alternatives (e.g., partial correlation controlling for confounders) is absent.
- Cross-lingual and multilingual evaluation: Faithfulness and hallucinations behave differently across languages; no tests on non-English datasets or multilingual models are provided.
- Integration with other neurosurgical techniques: How Lancet interacts with or complements head/MLP patching, causal tracing, steering vectors, LoRA-based adapters, or concept scrubbing is unexplored.
Practical Applications
Immediate Applications
Below is a set of specific, deployable use cases that leverage the Lancet framework’s structural-entropy–guided neural intervention to improve LLM faithfulness without sacrificing factuality.
- Enterprise RAG “Context-Locked Answering” — sector: software/enterprise
- Use case: Keep answers strictly grounded in retrieved documents (wikis, SOPs, product manuals) in internal Q&A, search, and chatbot workflows.
- Tool/product/workflow: Integrate a Lancet SDK into the inference pipeline of open-source LLMs (e.g., LLaMA2-7B, DeepSeek-7B). Precompute instigator sets and HDR-based partitions for the enterprise corpus; apply hierarchical modulation at inference.
- Assumptions/dependencies: Requires model weight/gradient access; domain-specific “factual vs hallucinatory” contrast data to estimate HDR; added compute for SE partitioning and parameter rescaling; hyperparameter tuning (selection ratio r, decay λ).
- Clinical document QA “Chart-Anchored Summarization” — sector: healthcare
- Use case: Patient-chart summarization and medication reconciliation that strictly adheres to provided EMR notes and lab results.
- Tool/product/workflow: Offline Lancet analysis using de-identified medical QA datasets to identify hallucination pathways; deploy as an inference-time “faithfulness guard” in hospital LLM agents.
- Assumptions/dependencies: Regulatory review; curated medical contrast datasets; clinical risk management and audit trails; open-model deployment (closed APIs may not expose internals).
- Legal assistant “Clause-Bounded Drafting” — sector: legal/policy
- Use case: Assist contract drafting and memo generation that stays within the boundaries of cited clauses and precedents.
- Tool/product/workflow: Run Lancet on firm-specific legal corpora; add a “faithfulness firewall” layer that prioritizes clause-linked reasoning pathways and suppresses off-context pathways.
- Assumptions/dependencies: Access to representative legal datasets (contrastive examples); supervision from attorneys; performance validation on firm-specific tasks.
- Code assistant “Repo-Constrained Suggestions” — sector: software/devtools
- Use case: Autocomplete and code review recommendations that remain consistent with a project’s repository (APIs, patterns, configs), avoiding invented methods.
- Tool/product/workflow: Apply Lancet over internal codebases to map hallucination-prone circuits; embed a lightweight runtime parameter rescaling for IDE-integrated assistants.
- Assumptions/dependencies: Access to model internals; activation logging on code tasks; compute overhead acceptable to keep latency low.
- Customer support “Policy-Compliant Responses” — sector: industry/customer service
- Use case: Ensure chat agents don’t invent returns or warranty policies, and stick to the official KB.
- Tool/product/workflow: Incorporate Lancet into ticketing/CRM bots; precompute patches per product line; log suppression events for compliance reporting.
- Assumptions/dependencies: High-quality KBs and contrast datasets; scalable batch preprocessing; monitoring to track trade-offs in response time.
- Personal assistant “Source-Anchored Summaries” — sector: daily life/consumer apps
- Use case: Summaries of articles, PDFs, and emails that stay faithful to highlighted selections or user-provided snippets.
- Tool/product/workflow: Mobile/desktop assistant with an optional “faithfulness mode” using prebuilt Lancet patches for general text domains.
- Assumptions/dependencies: Open-model deployment or on-device models; small-footprint approximations of SE to keep latency low.
- Misinformation auditing “Prompt Risk Scanner” — sector: academia/policy
- Use case: Offline analysis identifying prompts/topics that disproportionately activate hallucinatory pathways (risk scoring for content generation).
- Tool/product/workflow: HDR computation across factual vs hallucinatory corpora; structural-entropy partitioning to surface risky subgraphs; dashboards for red-team audits.
- Assumptions/dependencies: Access to activation traces; interpretability expertise; domain coverage to avoid blind spots.
- Topology-aware interpretability kit — sector: academia/research
- Use case: Mechanistic studies of polysemantic neurons and misinformation propagation; benchmarking intervention trade-offs.
- Tool/product/workflow: Research toolkit implementing Lancet’s contrastive sensitivity alignment, HDR graphs, SE partitioning, and hierarchical modulation for reproducible experiments.
- Assumptions/dependencies: Open-source models; datasets akin to PDTB (faithfulness) and TruthfulQA (factuality); compute for gradient/graph analyses.
Long-Term Applications
The following use cases require further research, scaling, or development (e.g., unsupervised instigator detection, efficient streaming HDR, architectural co-design).
- Dynamic hallucinatory gating “Real-Time Topology Guardrails” — sector: software/hardware
- Use case: Prompt-level, on-the-fly detection and suppression of misinformation pathways without precomputed patches.
- Tool/product/workflow: Streaming HDR estimation with lightweight SE approximations; integrated gating modules within model architectures.
- Assumptions/dependencies: Efficient online algorithms; access to intermediate activations on production systems; model–hardware co-design.
- “Faithfulness by Design” compliance standard — sector: policy/regulatory
- Use case: Develop certification criteria for topology-aware hallucination mitigation in high-stakes deployments (healthcare, finance, public services).
- Tool/product/workflow: Benchmarks and audit protocols that incorporate HDR/SE metrics and trade-off analyses (factuality vs faithfulness).
- Assumptions/dependencies: Multi-stakeholder consensus; standardized datasets; third-party auditing infrastructure.
- Domain autopatching service — sector: software/enterprise
- Use case: Managed service that builds and maintains Lancet patches for diverse domains (support, legal, research), updating as corpora evolve.
- Tool/product/workflow: Automated collection of contrastive examples; unsupervised instigator detection; continuous patch rollouts with A/B validation.
- Assumptions/dependencies: Privacy-preserving data pipelines; robust generalization across domains; cost-effective compute.
- Safety-critical AI “Control-Plane Guardrails” for embodied systems — sector: robotics/industrial automation
- Use case: Language control and instruction-following that remain faithful to sensor and state context (no invented states or goals).
- Tool/product/workflow: Cross-modal extension of Lancet to vision-language and control signals; topology-aware gating around action-critical pathways.
- Assumptions/dependencies: Multi-modal HDR/SE definitions; real-time constraints; extensive validation under distribution shifts.
- Evidence-anchored analysis for financial assistants — sector: finance
- Use case: Investment memos and risk reports that require explicit grounding in provided filings and market data; zero tolerance for fabricated figures.
- Tool/product/workflow: Lancet-enhanced report generation pipelines with evidence-check triggers; suppression logs linked to cited sources.
- Assumptions/dependencies: High-quality financial corpora; compliance approvals; tuning to avoid latency penalties.
- Entropy-regularized training and HDR-aware architectures — sector: academia/software
- Use case: Train future LLMs with objectives that minimize structural entropy for misinformation pathways or introduce HDR-aware routing layers.
- Tool/product/workflow: Novel losses and modules that bias model topology away from hallucinatory flows; evaluation suites tracking trade-offs.
- Assumptions/dependencies: Large-scale training resources; theoretical development to guarantee stability; benchmarks for longitudinal comparison.
- Low–side-effect knowledge editing — sector: software
- Use case: Edit specific facts while preserving downstream reasoning by targeting only the localized misinformation pathways.
- Tool/product/workflow: Pathway-localized model editing guided by Lancet partitions; validation harness to measure collateral damage.
- Assumptions/dependencies: Reliable pathway localization at scale; guardrails to protect critical circuits; domain-specific regression suites.
- Clinical decision support certification — sector: healthcare
- Use case: Formal evaluation of LLM-driven CDS tools that deploy topology-aware mitigation, leading to clinical-grade certifications.
- Tool/product/workflow: Trials comparing standard vs Lancet-enhanced systems on chart fidelity, error rates, and user trust; continuous post-deployment monitoring.
- Assumptions/dependencies: Institutional review and trial funding; standardized clinical tasks; integration with EMR ecosystems.
Glossary
- Ablation Study: An experimental analysis that removes components to assess their individual contributions. "Ablation Study"
- Counterfactual robustness: The ability of a model to maintain performance under counterfactual changes to inputs or conditions. "aggregates Targeted accuracy, Counterfactual robustness, and logical Consistency"
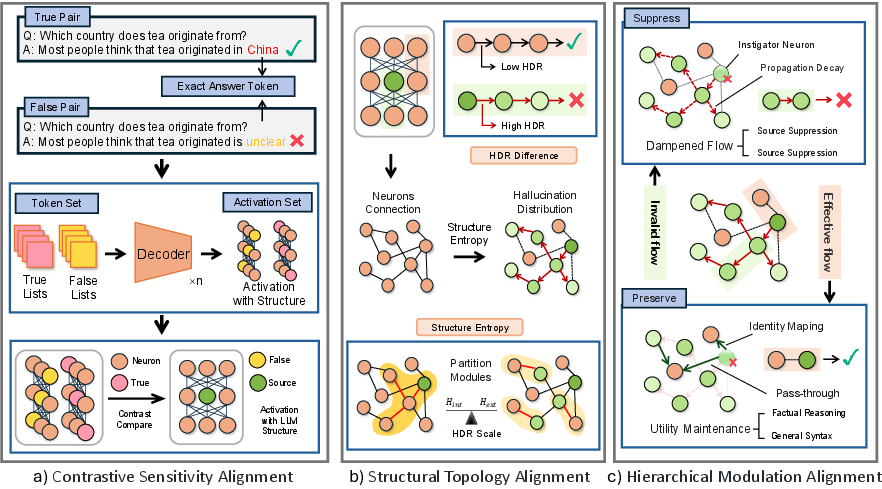
- Contrastive Sensitivity Alignment: A technique that identifies neurons whose gradient-based influence diverges between factual and hallucinatory contexts. "we employ a Contrastive Sensitivity Alignment strategy."
- DISQ metric: A composite measure for discourse faithfulness combining targeted accuracy, counterfactual robustness, and consistency. "PDTB assesses discourse faithfulness via the DISQ metric"
- External entropy: Entropy measuring uncertainty of transitions between modules in a graph partition. "the internal entropy (H_int) and external entropy (H_ext) across all modules"
- Factuality-Faithfulness Trade-off: The observed tension where improving factuality harms adherence to provided context. "Our analysis reveals a severe 'Factuality-Faithfulness Trade-off'"
- Faithfulness hallucinations: Outputs that deviate from or contradict the given context despite being plausible. "their reliability is severely compromised by faithfulness hallucinations."
- Geodesic distance: The shortest-path distance between nodes in a graph. "d_u denotes the geodesic distance from neuron u to the instigator set"
- Gradient-based importance score: A measure of a neuron's influence derived from parameter–loss gradients. "computing its gradient-based importance score."
- Gradient-driven contrastive analysis: Comparing gradient signals across contexts to locate neurons linked to hallucinations. "via gradient-driven contrastive analysis"
- Graph partitioning overhead: The computational cost associated with dividing a graph into modules. "graph partitioning overhead presents scalability challenges"
- Hallucination Difference Ratio (HDR): A metric quantifying how neuron-neuron correlation changes between hallucinatory and factual states. "We introduce the Hallucination Difference Ratio (HDR) as the affinity weight a_uv between neurons u and v."
- Hallucinatory response set: The subset of data representing model outputs produced in hallucinatory conditions. "the hallucinatory response set (I_u{hall})"
- HDR-weighted activation graph: A graph of neuron interactions whose edge weights are determined by HDR values. "Let G = (N_src, E, A) be the HDR-weighted activation graph"
- Hierarchical intervention strategy: A multi-level suppression approach that varies intensity by topological role. "implements a hierarchical intervention strategy that preserves general model capabilities."
- Hierarchical Modulation Alignment: A strategy that calibrates per-neuron suppression based on topological severity and distance. "we implement a Hierarchical Modulation Alignment strategy to surgically intervene"
- Instigator neurons: Neurons whose behavior disproportionately influences the onset of hallucinations. "specific 'instigator' neurons exhibit divergent sensitivity patterns"
- Internal entropy: Entropy capturing the stability of random walks within a graph module. "the internal entropy (H_int) and external entropy (H_ext) across all modules"
- Output logits: Pre-softmax scores manipulated during decoding to influence output distributions. "decoding strategies including CAD and DoLa that manipulate output logits"
- PDTB: The Penn Discourse Treebank, a benchmark for discourse-level faithfulness evaluation. "PDTB assesses discourse faithfulness via the DISQ metric"
- Pearson correlation coefficient: A statistic measuring linear correlation between neuron activations. "ρ_uvD denotes the Pearson correlation coefficient of activations on dataset D"
- Polysemantic neurons: Neurons that simultaneously contribute to multiple functions or objectives. "mathematically necessitating the existence of polysemantic neurons."
- Random walks: Stochastic processes traversing graph nodes, used to interpret module stability. "H_int captures the stability of random walks within a module"
- Structural Entropy: A graph-theoretic objective quantifying uncertainty in intra- and inter-module transitions. "By minimizing the Structural Entropy (SE) of the HDR-weighted graph"
- Structural Entropy minimization: The optimization process to find partitions that isolate misinformation pathways. "Structural Entropy minimization employs the standard partitioning algorithm."
- Structural Topology Alignment: Mapping and partitioning network pathways using structural entropy to align topology with function. "Structural Topology Alignment maps propagation pathways via Structural Entropy minimization"
- Subspace projections: Techniques that project activations into lower-dimensional subspaces; contrasted with entropy-based isolation. "isolates misinformation flow more precisely than subspace projections."
- Topological proximity: The closeness of a neuron to source nodes within the network graph. "based on topological proximity to the source."
- Topological quarantine zone: A region where suppression is localized around instigator nodes, decaying with distance. "establishes a topological quarantine zone controlled by the decay rate λ."
- Topological suppression factor: A per-neuron coefficient determining suppression strength based on HDR and distance. "establishing a topological suppression factor α_u for each neuron."
- Topology-aware intervention: An approach that targets pathways rather than individual neurons by leveraging network topology. "necessitates the shift to the topology-aware intervention proposed in Lancet"
- Topology-aware parameter rescaling: Modulating parameters using suppression factors derived from topological analysis. "executed as a topology-aware parameter rescaling."
- TruthfulQA: A benchmark evaluating factuality in LLMs via multiple-choice and generative metrics. "TruthfulQA evaluates factuality through multiple-choice accuracy (MC1/MC2)"
- True*Info metric: A composite score combining truthfulness and informativeness in TruthfulQA. "synthesized into the composite True*Info metric."
- Volume of the graph: The sum of weighted degrees across nodes, representing total graph connectivity. "We define vol(G) = ... as the total volume of the graph"
- Weighted degree: The sum of edge weights incident to a node. "d_i is the weighted degree of node v_i."
Collections
Sign up for free to add this paper to one or more collections.