- The paper proposes a novel two-phase training paradigm that enables 3D reasoning from 2D aerial imagery and sets new baselines in spatial grounding tasks.
- It introduces the first AirSpatial dataset with detailed 3D bounding box annotations and benchmarks for both spatial grounding and question answering.
- Experimental results demonstrate robust zero-shot vehicle attribute recognition and 3D retrieval capabilities, significantly outperforming existing methods.
AirSpatialBot: A Spatially-Aware Aerial Agent for Fine-Grained Vehicle Attribute Recognition and Retrieval
Introduction
AirSpatialBot addresses a key limitation in contemporary remote sensing vision-LLMs (VLMs): insufficient spatial understanding, particularly in 3D reasoning from 2D aerial imagery. This work introduces the AirSpatial dataset, the first to provide 3D bounding box (3DBB) annotations for drone-captured scenes, and pioneers two novel benchmarks: Spatial Grounding (SG) and Spatial Question Answering (SQA). Leveraging these resources, the authors design a two-phase training scheme to endow a VLM architecture with explicit 3D reasoning ability, and propose AirSpatialBot, an aerial agent capable of fine-grained vehicle attribute recognition—including zero-shot recognition and retrieval based on spatial and visual cues—directly from aerial RS data.
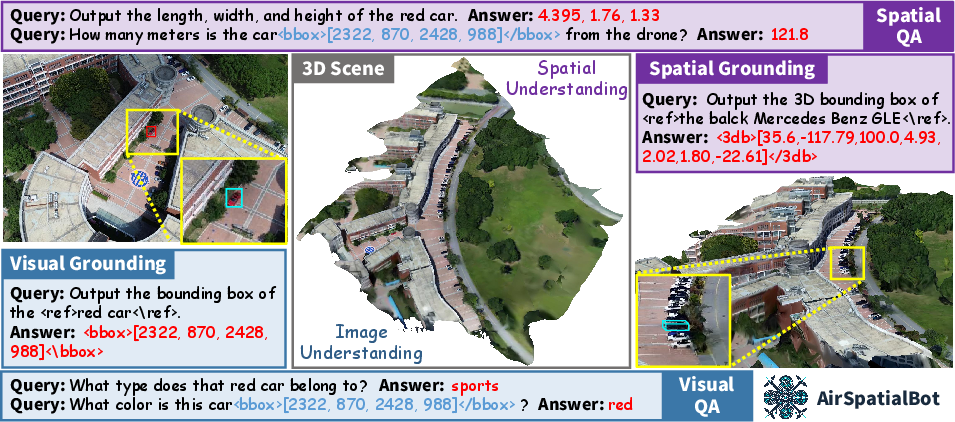
Figure 1: AirSpatialBot’s visual and spatial understanding capacities, highlighting its ability to reason beyond purely photometric cues.
AirSpatial Dataset Construction
Data Collection & Annotation
The dataset is established using high-resolution multi-view drone imagery paired with ground video, enabling robust annotation of both image geometry (intrinsic/extrinsic parameters) and fine-grained vehicle attributes. A rigorous procedure matches aerial detections with ground-truth identities, effectively labeling 814 vehicle instances at the model level across 53 brands and 211 models.

Figure 2: Frequencies of vehicle brands and models; BYD is most prevalent by brand, Tesla Model 3 by model.
Spatial annotation entails projecting oriented 2D bounding boxes into the world coordinate system, making use of camera geometry and scene metadata. An affine transformation pipeline reconstructs each vehicle’s 3DBB, enabling queries and evaluation in true 3D space.

Figure 3: 3D scene reconstructions from multi-view drone imagery provide the geometric substrate for fine-grained tasks.

Figure 4: 3D bounding boxes are derived via precise coordinate system transformations from annotated OBBs.
Benchmark Tasks
AirSpatial enables several task types:
- AirSpatial-G: 80k spatially-informative image-text-location pairs for 3D visual grounding, critically supporting 2D → 3D transfer.
- AirSpatial-QA: 126k question-answer pairs targeting spatial regression tasks (depth, distance, object dimensions) within complex scenes.
- AirSpatial-Bench: A challenging benchmark integrating VQA, fine-grained attribute recognition, and 3D retrieval—mandatory for holistic evaluation.
Model and Training Pipeline
Architecture
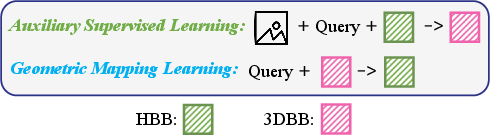
The spatially-aware VLM is built on the LLaVA paradigm, utilizing a vision encoder, a cross-modal projection interface, and a powerful LLM back-end. The two-stage training regime is pivotal: initial pre-training on 2D RSVG data transfers photometric and category-level grounding to the vision encoder, while subsequent spatial fine-tuning (using AirSpatial’s multi-modal annotation) instills explicit 3D reasoning capability.
2D → 3D Knowledge Transfer
The second training phase augments SFT with two custom objectives:
Agent Design: AirSpatialBot
The agent synergizes the VLM’s spatial abilities with an LLM planner. Upon receiving a complex query (attribute recognition, zero-shot type identification, 3D retrieval), the LLM decomposes the task into subtasks, invokes the VLM for image/spatial analysis, queries dynamic backends (e.g., vehicle parameter tables or web APIs for pricing), and finally synthesizes a comprehensive answer.
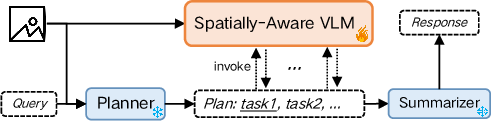
Figure 6: AirSpatialBot’s framework, orchestrating VLM-based perception and LLM-driven planning.
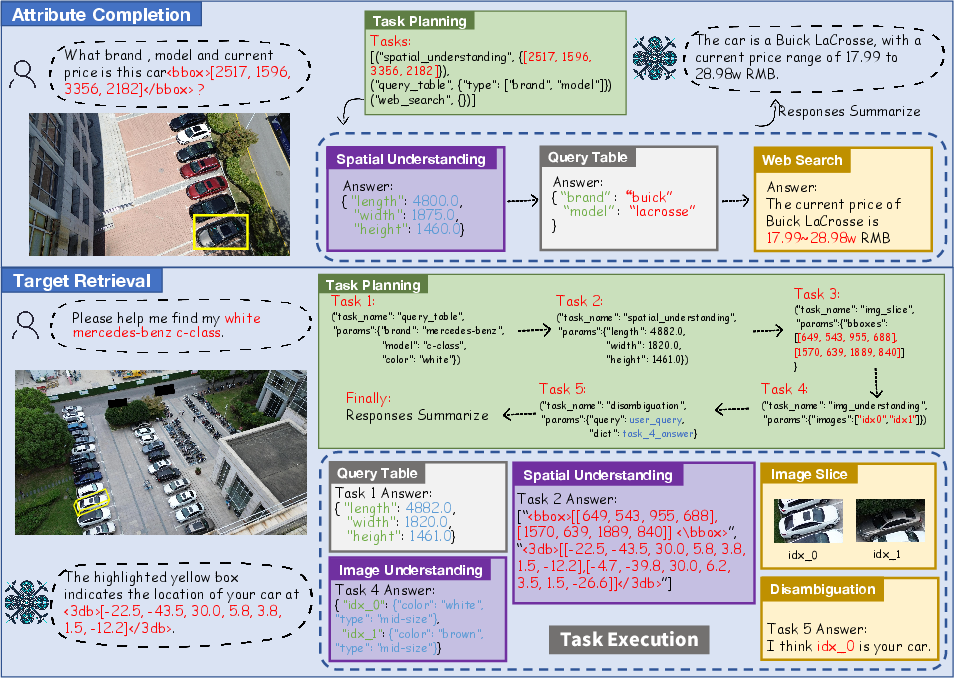
Figure 7: Workflow diagrams for attribute recognition, zero-shot recognition (leveraging spatial cues for unseen classes), and 3D target retrieval.
Experimental Analysis
On AirSpatial-G, AirSpatialBot sets a new baseline for spatially-aware visual grounding, outperforming prior art (both specialized and general VLMs) across absolute/relative size and distance tasks. Notably, the system achieves [email protected]% scores of 6.23 (Abs. Size) and 26.65 (Rel. Distance), with an average of 12.96, doubling the best alternative baselines.
2D Visual Grounding Generalization
The model maintains strong performance on established 2D RSVG datasets, confirming that the two-phase training does not compromise traditional capabilities.
3D Bounding Box Reasoning
Qualitative analysis demonstrates robust 3DBB generation for visually- and spatially-complex queries.

Figure 8: Visualization of predicted vs. GT 3DBBs for multi-vehicle queries, illustrating robust spatial understanding.
Spatial Question Answering
AirSpatialBot achieves an R-squared of 0.99 in spatial regression (vs. -0.57 for the next best VLM), indicating precise metric estimation for vehicle depth, distance, and all 3D dimension axes—a substantial leap over recent counterparts.

Figure 9: SQA answer accuracy for key numerical attributes; AirSpatialBot’s predictions align tightly with ground truth.
Fine-Grained Attribute Recognition and 3D Retrieval
In zero-shot conditions, AirSpatialBot can infer the most likely brand/model by regressing metric dimensions, cross-referencing against vehicle databases—a capability not observed in other VLMs. The agent achieves 28.53% accuracy on attribute recognition and 29.74% on 3D retrieval, while all prior baselines remain near zero on retrieval.
Ablation and LLM Pairing
Ablative experiments validate incremental benefits from 2D pre-training, use of multiple supervision signals, and particularly, the ASL/GML modules. Dual-agent configurations (VLM for perception, LLM for planning/reasoning) surpass single-model approaches, suggesting compartmentalization of logic and perception is optimal in this context.
Implications and Future Work
The key practical implication is the feasibility of deploying agents capable of fine-grained, zero-shot vehicle attribute reasoning and 3D retrieval in unconstrained, resource-limited aerial settings. This architecture reduces reliance on exhaustive per-class supervision and enables immediate adaptation to unseen vehicle types through table extension, benefiting applications such as law enforcement or disaster response where rapid, detailed situation analysis is required.
Theoretically, the modular two-phase pipeline—anchored by geometric consistency regularization—demonstrates a viable path for integrating spatial reasoning into VLMs when rich 3D supervision is scarce. The framework is extensible to other classes of ground targets (e.g., ships, aircraft) and domains (autonomous navigation, search and rescue).
Conclusion
AirSpatialBot advances spatially-aware remote sensing VLM research by (1) constructing the first aerial dataset with full 3D annotation and benchmarks, (2) devising a robust two-stage VLM training paradigm for 2D-to-3D transfer, and (3) engineering an aerial agent that pushes the boundary of fine-grained attribute recognition and 3D retrieval in RS imagery. Empirical benchmarks show strong gains in both traditional and newly-formulated spatial tasks, pointing toward a practical framework for next-generation aerial perception agents.