Logics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Abstract: We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Logics‑STEM, a way to make AI models much better at step‑by‑step reasoning in science, technology, engineering, and math (STEM). The team built two things:
- a huge, high‑quality training set of reasoning examples (about 10 million problems with detailed solutions), and
- a training method that teaches the model to focus on its mistakes and learn the missing knowledge.
They also release open models (8B and 32B sizes) and the datasets so others can build on their work.
What questions did the researchers ask?
The researchers set out to answer a few simple questions:
- How can we build an AI that reasons better on hard STEM problems?
- What kind of training data does it need, and how should we pick that data?
- After basic training, what is the best way to improve the model further: more supervised practice, reinforcement learning, or both?
- Can we make a simple, repeatable recipe the community can use?
How did they do it?
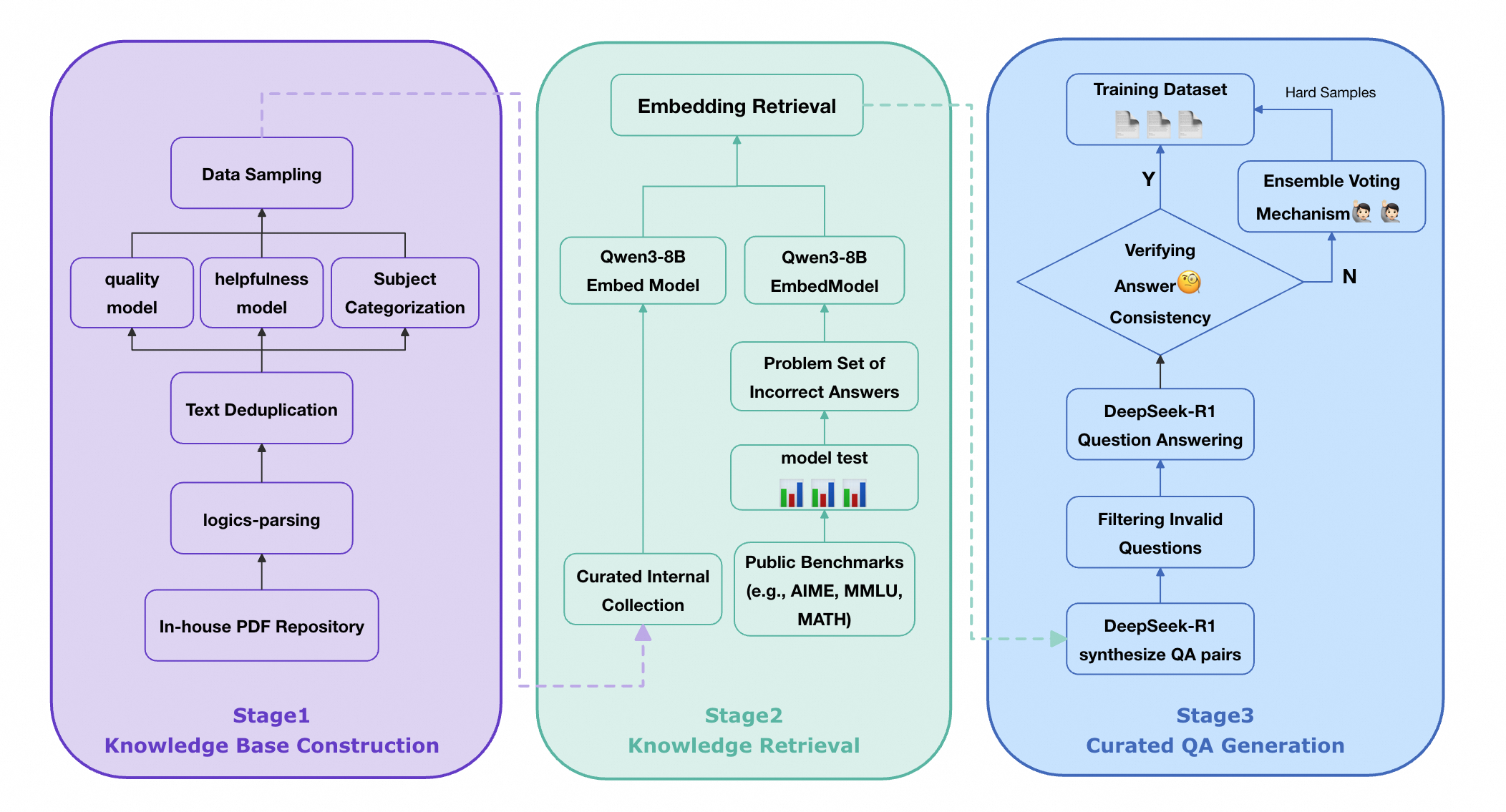
The approach has two main stages. You can think of it like preparing for a tough exam.
Stage 1: Build a great study set (Supervised Fine‑Tuning)
First, the team created a large “study guide” of problems and worked‑out solutions (long chain‑of‑thought). They carefully cleaned and organized this data so the model could learn solid basics.
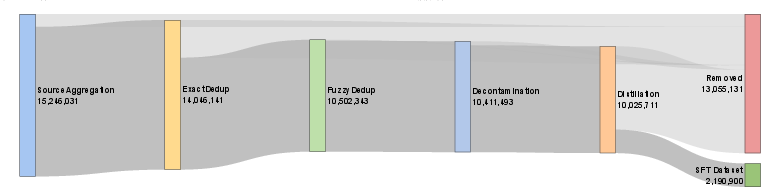
Here are the main steps they used to curate the dataset:
- They collected good questions from many trusted sources and books, and turned PDFs into clean text.
- They checked each question for clarity, topic, school level, answer type, and whether the answer can be verified.
- They removed duplicates and near‑duplicates so the model wouldn’t “over‑memorize.”
- They removed any items that overlapped with test sets (to avoid “contamination”).
- They asked a very strong teacher model to write full step‑by‑step solutions (distillation), and filtered out low‑quality or repetitive answers.
- They mixed easy and hard problems in a smart way (stratified sampling): keep more hard examples to build deep reasoning, but still include some easier ones for balance.
Result: Logics‑STEM‑SFT‑Dataset with 10 million items (and a downsampled 2.2 million version) focused on high‑quality, long chain‑of‑thought reasoning.
Stage 2: Learn from mistakes (Failure‑Driven Post‑Training)
Next, the model takes “practice tests” (benchmarks like AIME and GPQA). Wherever it gets questions wrong, the system:
- Finds those failure cases (the model’s weak spots).
- Retrieves related, trustworthy documents (like the right textbook pages).
- Generates new, targeted practice problems from those documents, double‑checks the answers, and keeps the best ones.
- Trains the model again on this focused set.
They try two ways to do this second training step:
- More supervised practice (SFT again), or
- Reinforcement learning (RL) with verified rewards (the model gets a reward when it produces a correct final answer, and small bonuses for clear, non‑repetitive reasoning).
Simple analogy: Stage 1 is learning from a well‑designed textbook. Stage 2 is a coach reviewing your mistakes, finding the right chapter, writing new custom drills, and having you practice until you fix the gap.
A key idea behind the scenes: “distribution matching.” That’s like making your practice set match the kinds of problems and solutions you really want at test time. Stage 1 builds a broad, strong base. Stage 2 shifts the model’s focus toward the tricky, important areas where it used to fail.
What did they find?
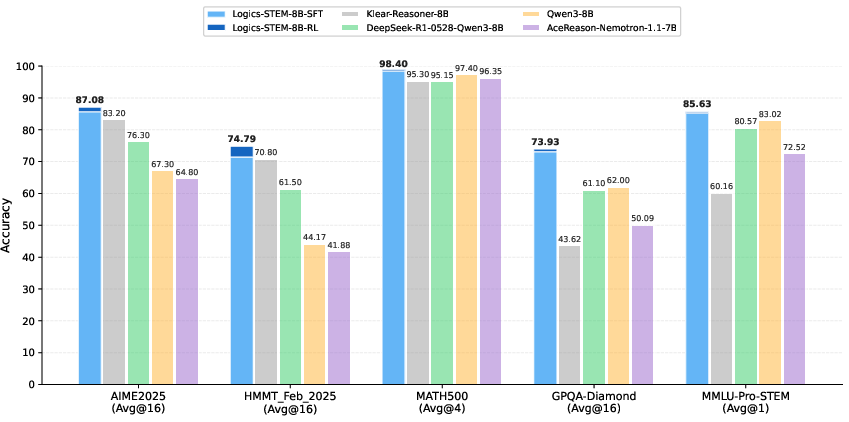
The results show strong gains on tough STEM benchmarks, especially at the 8B size (a relatively compact model):
- On math competitions: up to about 90% on AIME 2024 and about 87% on AIME 2025 (with larger context), and strong scores on HMMT 2025 and BeyondAIME.
- On broader STEM: top performance on GPQA‑Diamond (about 74%, with larger context), plus gains on other STEM tests.
Why this matters:
- The data+algorithm “co‑design” works: careful data building plus mistake‑focused training makes the model reason better.
- For smaller models, doing another round of supervised training with the right data can sometimes work as well as RL, which is useful because RL can be more complex and expensive.
- The approach is reproducible and open: models and datasets are released for others to use.
Why does this matter?
This work shows a practical, effective path to smarter reasoning in AI:
- Build large, clean, diverse, and explanation‑rich datasets.
- Then, zoom in on failures, pull in the right knowledge from documents, make targeted new problems, and train again.
- The method boosts accuracy on hard, real‑world STEM problems while staying efficient.
Potential impact:
- Better AI tutors that can explain their steps clearly.
- Stronger problem‑solving assistants for students, engineers, and scientists.
- A shared, open foundation for future research to push reasoning even further.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and research opportunities implied or left unaddressed by the paper. Each point is phrased to enable concrete follow-up work.
- Formal estimation of the target distribution: The paper frames post-training as distribution matching to an unknown target , but provides no practical method to estimate density ratios or to validate that the chosen surrogate evaluation distribution adequately approximates across tasks.
- Failure signal granularity: Failure-driven sampling uses a binary correctness indicator; it leaves unexplored whether richer signals (e.g., per-step loss, partial-credit, error-type taxonomy, verification confidence, or calibration scores) yield better second-stage training.
- Sensitivity to “Q” selection: The choice of gold-standard benchmarks forming is assumed to be representative; no analysis of how different compositions (domains, difficulty bands, distributions) affect the regions emphasized and the final performance.
- Mixing parameter and schedule: The second-stage sampling mixes and with weight , but the paper does not specify how is chosen or scheduled, nor analyze its impact on stability, convergence, and performance.
- Retrieval design ablations: The knowledge retrieval kernel (embedding model, cosine similarity, temperature , top- size, and retrieval at document vs. passage granularity) lacks ablations and sensitivity analyses; it remains unclear which settings maximize signal quality and training efficiency.
- Chunking and structure in retrieval: Documents are retrieved at the document level; the effect of passage-level chunking, hierarchical retrieval, or reranking (e.g., cross-encoder) on synthesis quality and downstream gains is not explored.
- Quality of synthetic data: Dual-pass verification and majority voting are proposed for synthesis acceptance, but error rates, failure modes (e.g., spurious agreement), and residual hallucination rates are not quantified; stronger verifiers (symbolic solvers, unit checks, formal proof verification) are not evaluated.
- Scale of second-stage data: The second-stage synthetic dataset (~30K pairs) is relatively small; there is no study of scaling laws relating synthetic set size, diversity, and difficulty to downstream gains or diminishing returns.
- Attribution of gains: No component-level ablation separates the effects of failure-driven sampling, retrieval, synthesis, and RL rewards; it is unclear which elements contribute most under different model sizes or domains.
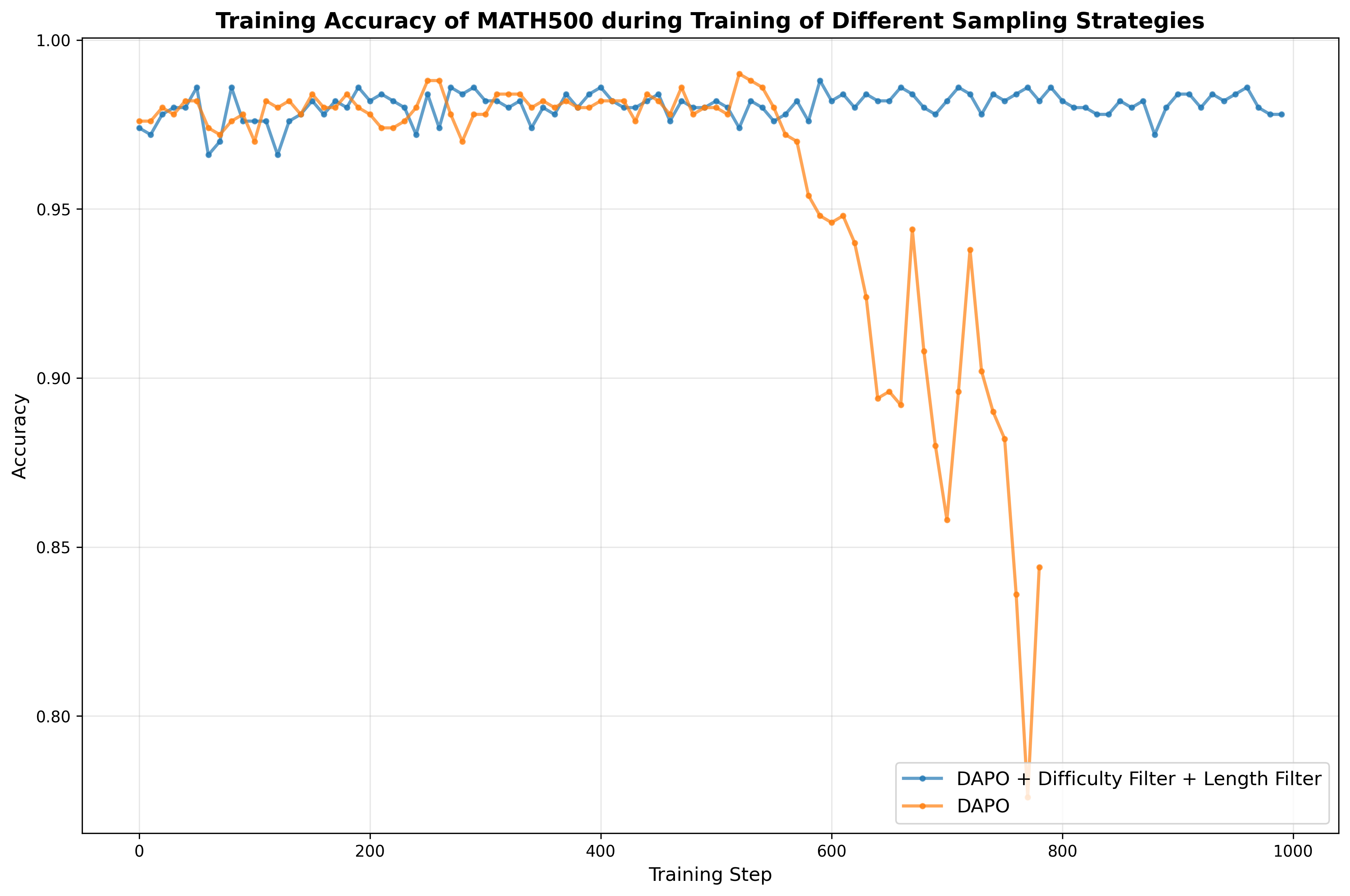
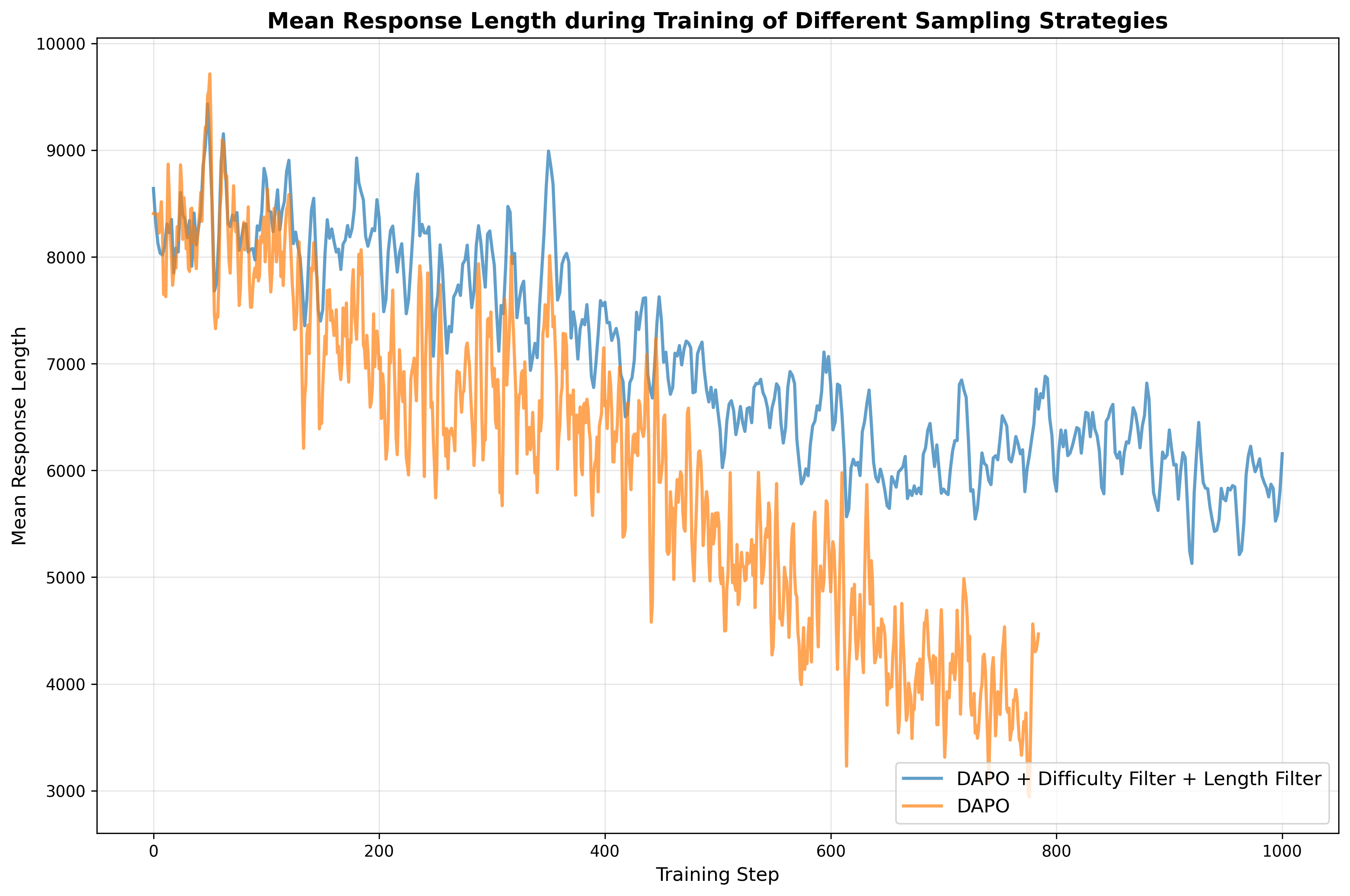
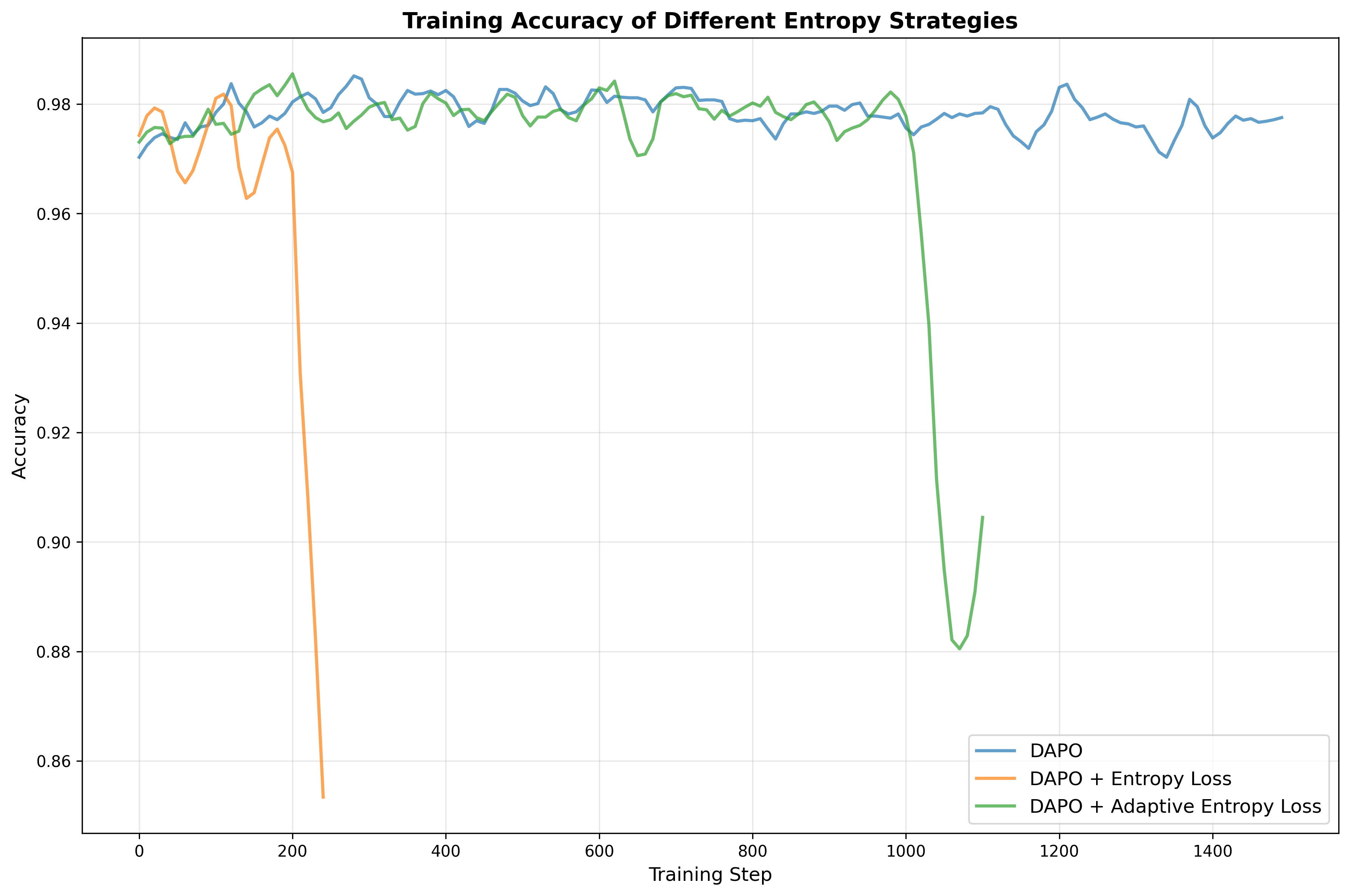
- RL reward shaping risks: Length-based rewards and repetition penalties may incentivize verbosity or reward gaming; the paper lacks ablations, threshold details (e.g., -gram sizes), and analyses of unintended behaviors and trade-offs.
- RL algorithm choice: GRPO vs. DAPO usage and outcomes are not systematically compared; criteria to choose between RL and SFT for second-stage training (task types, data regimes, model sizes) remain unspecified.
- Verification coverage beyond math/MCQ: RLVR relies on math-verify and MCQ option matching; the approach for open-ended non-math STEM tasks without verifiable answers is not detailed, limiting generality of RLVR beyond math and MCQ.
- Decontamination sufficiency: MinHash and 13-gram decontamination can miss paraphrased or structurally transformed contamination; no residual contamination audit or quantitative assessment is provided, especially for high-stakes small benchmarks (e.g., AIME).
- Evaluation comparability: Reported scores mix different generation counts (Pass@1 vs. Pass@K/Majority@N) and inference budgets (e.g., 64k context), with partial reliance on developer-reported baselines; standardized, controlled comparisons are needed for fair benchmarking.
- Reproducibility and compute: Training hyperparameters, optimizer settings, compute budgets (GPUs, training time, token counts), and stability metrics are not reported, limiting reproducibility and making “efficiency” claims hard to evaluate.
- Internal knowledge base opacity: The internal multi-source PDF corpus and Logics-Parsing pipeline are not released; licensing, coverage, and domain balance are unspecified, hindering replication of the retrieval-and-synthesis stage.
- Knowledge base curation criteria: “Text quality,” “usefulness,” and subject classification models used to filter the knowledge base are not described or validated; their biases and coverage effects are unknown.
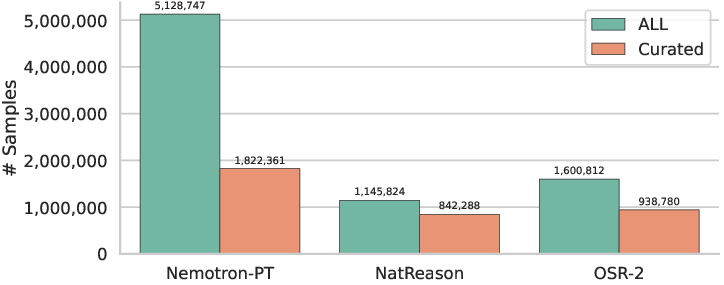
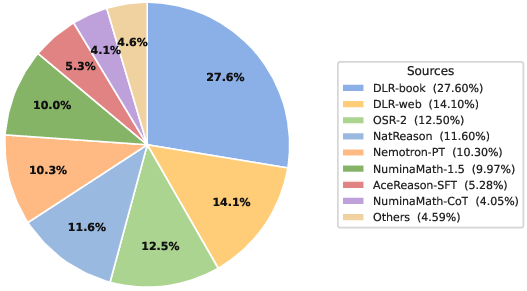
- Dataset composition transparency: The broader-STEM portion (1.14M) lacks a detailed breakdown (discipline, subdomains, language), difficulty distributions, and per-source quality metrics; this impedes targeted improvements and bias analysis.
- Sampling strategy generality: Stratified length-based sampling thresholds (e.g., 75th percentile retention) are heuristic; there is no exploration of adaptive or domain-aware sampling, nor evidence that these settings generalize across tasks and model sizes.
- Teacher model bias: Distillation from Qwen3-235B-Thinking may impart teacher-specific biases; the impact of alternative teachers, ensemble teachers, or self-consistency sampling on student performance and error modes is untested.
- Scaling with model size: Although 32B models are mentioned, results, scaling laws, and resource-performance trade-offs across 8B and 32B (and beyond) are not provided.
- Cross-lingual and non-English coverage: Aside from CMMLU-STEM, the paper does not analyze language distribution of training data, cross-lingual reasoning, or performance in non-English STEM contexts.
- Safety, bias, and ethics: There is no assessment of domain biases, fairness across subfields and educational levels, safety in scientific advice, or licensing compliance for internal documents; mitigations and evaluation protocols are absent.
- Generalization beyond STEM: The method is tuned for STEM; its transfer to non-STEM reasoning, multi-modal tasks, code reasoning, or formal proofs remains an open question.
Practical Applications
Immediate Applications
Below are concrete ways the paper’s methods, models, and dataset can be deployed today. Each item notes the target sector(s), potential tools/workflows, and key dependencies or assumptions.
- Enterprise STEM copilot with continuous improvement
- Sectors: engineering, energy, manufacturing, finance
- What: Deploy Logics-STEM-8B/32B as an internal reasoning assistant for calculations, standards lookup, and analysis-heavy tasks; wrap it in the failure-driven loop to automatically identify failure cases, retrieve relevant internal documents, synthesize targeted training data, and conduct a second-stage SFT/RL cycle.
- Tools/workflows: Logics-Parsing for PDF→HTML, Qwen3-8B-Embedding for dense retrieval, failure-driven synthesis using a strong generator (e.g., DeepSeek-R1), SFT or RLVR (GRPO/DAPO) with ROLL/math-verify for verifiable signals.
- Dependencies/assumptions: Access rights to internal documents; compute budget for periodic post-training; availability of verifiers (math and multiple-choice are ready; others may be limited); long-context inference hardware if using 64k budgets.
- STEM tutoring and exam-prep solutions
- Sectors: education, edtech
- What: Build personalized tutors and problem-practice apps using Logics-STEM’s strong chain-of-thought (CoT) capabilities; auto-generate diverse, difficulty-calibrated problem sets via the length-based stratified sampling and dual-pass answer consistency filter.
- Tools/workflows: Logics-STEM-SFT-Dataset-2.2M as foundation; length-quantile sampling; acceptance filters (two-pass answer consistency, majority vote) to ensure reliability; LMS integration.
- Dependencies/assumptions: Teacher model access for additional synthesis; human-in-the-loop review for high-stakes curricula; exam decontamination practices.
- Benchmark-ready reasoning evaluation harness
- Sectors: academia, AI/ML R&D
- What: Adopt the paper’s zero-/multi-sample evaluation protocol (Pass@1/Best@N/Majority@N) to standardize reasoning evaluation on STEM benchmarks (AIME 2024/2025, GPQA-Diamond, etc.).
- Tools/workflows: The released models and dataset, standardized generation configs, decontamination via MinHash and 13-gram matching to protect test integrity.
- Dependencies/assumptions: Access to the released SFT/RL checkpoints and curated datasets; careful contamination control for new benchmarks.
- Failure-driven data generation service for domain teams
- Sectors: software (ML Ops), platform engineering
- What: Package the “evaluation → failure mining → document retrieval → synthetic QA → SFT/RL” loop as an internal service to upgrade any specialized LLM’s reasoning in targeted areas.
- Tools/workflows: Embedding-based top-k retrieval kernel, temperature-tuned retrieval distributions, acceptance filters (consistency checks, n-gram repetition penalties), length-aware reward shaping in RL.
- Dependencies/assumptions: Strong base or teacher models for synthesis; documented APIs for post-training; monitoring for data drift and redundancy.
- Curriculum and item bank construction for STEM publishers
- Sectors: education publishing, assessment
- What: Generate large, diverse, and verified question banks with solved, explainable solutions; balance difficulty with weighted length-based sampling; ensure de-duplication and quality with the paper’s curation steps.
- Tools/workflows: Deduplication (MD5 + MinHash), distillation from 235B teacher to produce clean CoT traces, length-based sampling to shape difficulty profiles.
- Dependencies/assumptions: Rights to source materials; editorial QA for sensitive content; maintain decontamination w.r.t. public exams.
- Verified-reward RL training for math and multiple-choice reasoning
- Sectors: academia, AI product teams
- What: Use RLVR with binary correctness signals (math-verify, MCQ answer extraction) to sharpen policies post-SFT, improving sample efficiency and correctness concentration.
- Tools/workflows: GRPO/DAPO implementations, ROLL for reward computation, clip-higher and batch-level normalization, length-aware rewards with repetition penalties.
- Dependencies/assumptions: Verifiable tasks (math, MCQ) are available; correctness checkers performant at scale; compute for RL sampling.
- Document-to-training-data pipeline for knowledge base QA
- Sectors: knowledge management, enterprise IT
- What: Convert corporate/technical document repositories to structured training data and high-fidelity QA pairs to “ground” reasoning models in company-specific knowledge.
- Tools/workflows: Logics-Parsing for robust PDF parsing; subject classifiers/usefulness/fluency filters; retrieval and synthesis over doc chunks; consistency acceptance filters.
- Dependencies/assumptions: Clean, high-quality document corpora; classification pipelines; legal/PII constraints.
- Open-source baseline for reproducible reasoning research
- Sectors: academia, open-source community
- What: Use Logics-STEM models and the 10M/2.2M datasets as strong, transparent baselines for research on distribution matching, CoT quality, and post-training.
- Tools/workflows: Public checkpoints, curation scripts, sampling strategies, and evaluation code.
- Dependencies/assumptions: Licensing aligns with research goals; compute to replicate SFT/RL runs.
Long-Term Applications
These opportunities require further research, domain-specific verifiers, larger-scale deployment, or policy development before broad adoption.
- Cross-domain verified-reward learning beyond math/MCQ
- Sectors: healthcare, law, scientific research
- What: Extend RLVR to domains with formal verifiers (e.g., clinical guideline checks, legal citation consistency, formal proofs, or chemistry/physics simulators) so models receive reliable reward signals.
- Dependencies/assumptions: Domain verifiers and curated gold standards; regulatory compliance; robust extraction of structured answers from CoT.
- Self-improving enterprise assistants with continuous failure-driven training
- Sectors: enterprise software, knowledge management
- What: Always-on pipelines that log failures in real usage, retrieve internal knowledge, synthesize new training examples, and push safe updates after automated and human review.
- Dependencies/assumptions: Strong MLOps governance; drift/quality monitors; rollback/AB testing; data privacy and audit trails.
- National-scale AI for STEM education and assessment
- Sectors: public education, testing agencies
- What: Large-scale generation and curation of high-quality, diverse item banks with transparent chain-of-thought, difficulty stratification, and contamination controls; adaptive tutoring at population scale.
- Dependencies/assumptions: Publicly accepted standards for decontamination and verifiability; human oversight and fairness audits; procurement of compute and data infrastructure.
- Scientific literature copilots that reason over papers and generate verifiable exercises/hypotheses
- Sectors: academia, pharma, R&D
- What: Use the document-enhanced pipeline to convert scientific corpora into trusted, testable QA and proposal templates; e.g., creating mechanistic questions from papers with dual-pass verification and expert-in-the-loop validation.
- Dependencies/assumptions: Access/licensing for large paper repositories; domain-specific correctness checks beyond math; provenance tracking.
- Robotics and autonomous systems with verifiable multi-step planning
- Sectors: robotics, logistics, manufacturing
- What: Marry chain-of-thought planning with simulator- or constraint-based verifiers to give RLVR reward signals for plans; use failure-driven synthesis from manuals/specs to cover rare scenarios.
- Dependencies/assumptions: High-fidelity simulators/constraints as verifiers; robust plan-to-action grounding; safety certifications.
- Finance and engineering decision support with auditable reasoning
- Sectors: finance, civil/mechanical/electrical engineering
- What: Apply failure-driven enhancement on domain standards, pricing models, or design codes; integrate numeric/verifier checks (solvers, unit tests) to provide verifiable reward signals.
- Dependencies/assumptions: Availability of solvers and test oracles; regulatory acceptance of AI-assisted decisions; robust PII/confidentiality handling.
- Privacy-preserving or federated failure-driven training
- Sectors: healthcare, finance, government
- What: Execute the retrieval-synthesis-SFT loop locally over sensitive corpora (federated or on-prem) so improvements accrue without sharing raw data.
- Dependencies/assumptions: Federated learning infrastructure; secure enclaves/data governance; on-device distillation/synthesis efficiency.
- Multilingual/low-resource STEM reasoning expansion
- Sectors: global education, NGOs
- What: Adapt the curation pipeline, decontamination, and failure-driven training to create high-quality long-CoT datasets and tutors in under-resourced languages.
- Dependencies/assumptions: High-quality multilingual parsing/embeddings; culturally aligned curricula; local benchmark development.
- Formal verification and program synthesis integrations
- Sectors: software, safety-critical systems
- What: Combine chain-of-thought with proof assistants, theorem provers, or property-based testing to create verifiable reward signals for code reasoning and formal methods.
- Dependencies/assumptions: Toolchain integration (e.g., Lean/Coq/SMT solvers); scalable reward computation; developer workflow fit.
- Data provenance marketplaces for long-CoT reasoning
- Sectors: AI ecosystem, data vendors, policy
- What: Standardize provenance, de-duplication, and contamination tags for chain-of-thought datasets; enable transparent licensing and quality metrics for post-training data trades.
- Dependencies/assumptions: Community standards and policy frameworks; robust dedup/decontam tooling; incentive-aligned licensing.
Notes on Key Assumptions and Dependencies
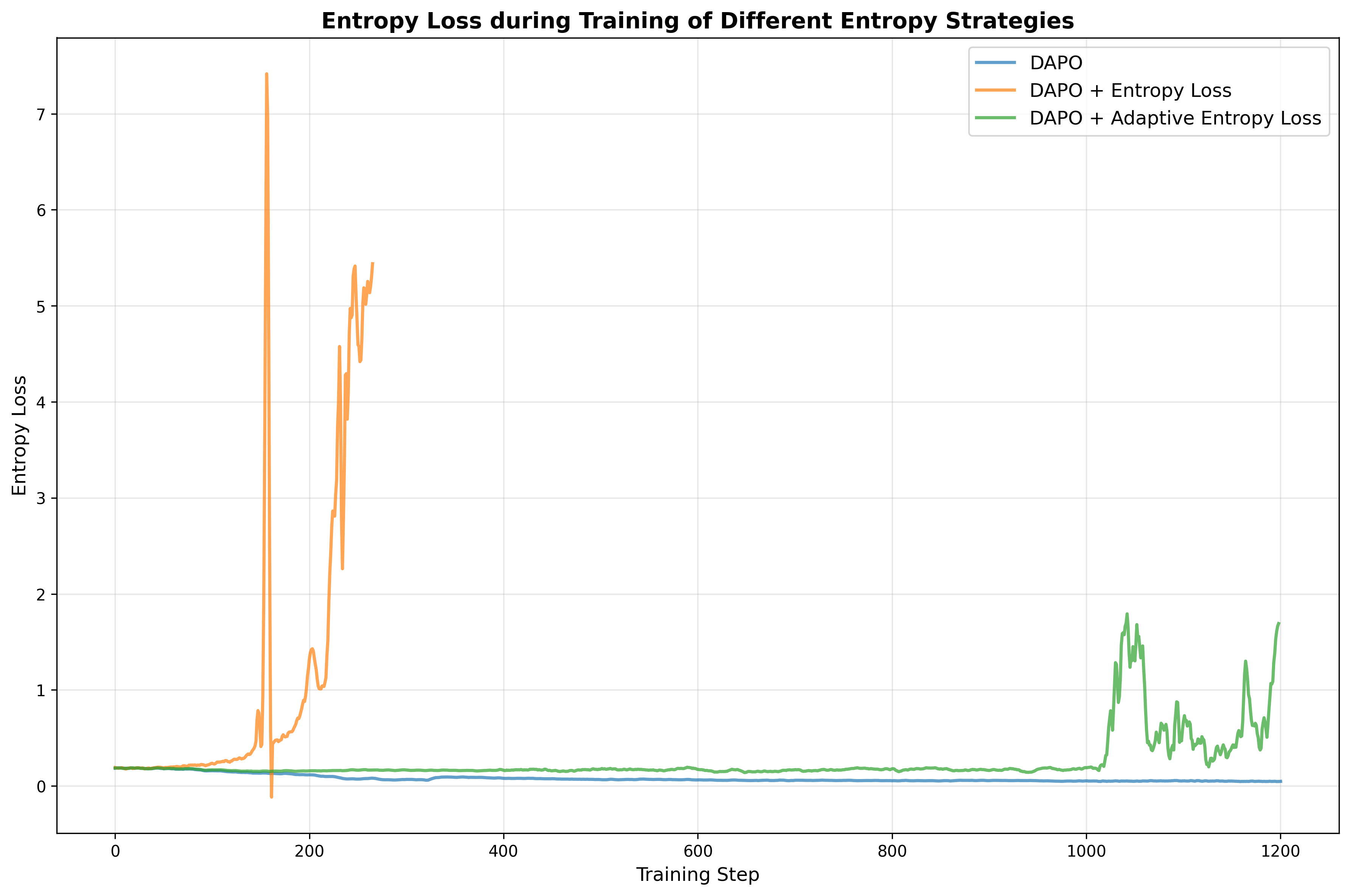
- Compute and infrastructure: Both first-stage SFT and second-stage SFT/RL (GRPO/DAPO) require substantial compute, especially for long-context inference and multi-sample RL.
- Teacher/synthesizer models: The pipeline assumes access to strong generators (e.g., Qwen3-235B-Thinking, DeepSeek-R1) for high-quality distillation and synthesis.
- Verifiers: Math and MCQ verifiers are available now; other domains need robust, scalable verifiers to unlock RLVR and large-scale acceptance filters.
- Data rights and privacy: Document parsing and knowledge-base construction depend on licensing and compliance; enterprise deployments must enforce PII and IP safeguards.
- Evaluation hygiene: Decontamination (MinHash/N-gram) and benchmark discipline are essential to maintain credible reported gains and avoid leakage.
- Quality controls: Acceptance filters (two-pass consistency, majority vote), repetition penalties, and length-aware rewards are critical to suppress degeneracy and maintain reasoning density.
Glossary
- acceptance filter: A binary criterion that determines whether a synthesized training example is kept based on validity checks. "apply an acceptance filter "
- advantage function: A signal in reinforcement learning that measures how much better an action is compared to a baseline, guiding policy updates. "a vanilla policy gradient can be considered as fitting a distribution depending on the advantage function "
- Chain-of-Thought (CoT): Explicit step-by-step reasoning traces generated by a model to solve a problem. "SFT is typically used to familiarize the model with long chain-of-thought (CoT) reasoning traces"
- clip-higher strategy: An RL training heuristic that clips policy updates, often to stabilize training and avoid overly large updates. "We adopt the clip-higher strategy alongside batch-level reward normalization."
- cosine similarity: A metric measuring the cosine of the angle between two vectors, used here to compare embeddings for retrieval. "define similarity (via cosine similarity) as s(x,d)=\langle (x),(d)\rangle"
- data-algorithm co-design: Jointly designing data pipelines and algorithms so the model’s training distribution aligns with desired behavior. "the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training."
- data curation engine: A structured pipeline that collects, filters, and prepares datasets to ensure quality and diversity. "constructed from a meticulously designed data curation engine with 5 stages"
- decontamination: The process of removing training samples that overlap with evaluation benchmarks to avoid data leakage. "We perform decontamination against the evaluation benchmarks"
- deduplication: Removing exact and near-duplicate items from a dataset to improve diversity and reduce redundancy. "deduplication is performed at multiple granularities, including both exact and near-duplicate removal."
- density ratio: The ratio between target and training data distributions indicating underrepresented but important regions. "high density ratio "
- DAPO: A specific reinforcement learning algorithm used for post-training LLMs. "We test GRPO~\citep{shao2024deepseekmathpushinglimitsmathematical} and DAPO~\citep{yu2025dapo} for our framework,"
- embedding model: A model that maps inputs (e.g., text) into dense vector representations for similarity and retrieval. "Let be an embedding model"
- expected risk: The expected loss over the (ideal) target data distribution that training seeks to minimize. "\text{(Expected Risk)}\quad *(\theta)=\mathbb{E}_{(x,y)\sim P*}\big[\ell_\theta(x,y)\big]"
- failure-driven post-training: A training paradigm that focuses data synthesis and updates on cases where the model fails. "our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions"
- failure-driven resampling: Reweighting or resampling training prompts toward those the current model gets wrong to better match the target distribution. "we introduce a failure-driven resampling for second-stage post-training"
- failure region: Areas in the data space where the model performs poorly and thus needs focused training. "Once the failure region is found, we retrieve from external documents for knowledge enhancement"
- gold-standard distribution: An idealized target distribution reflecting correct, high-quality reasoning or outputs. "align the model with the gold-standard reasoning distribution."
- GRPO: A reinforcement learning objective/algorithm variant (related to PPO) used for LLM post-training. "We test GRPO~\citep{shao2024deepseekmathpushinglimitsmathematical} and DAPO~\citep{yu2025dapo} for our framework,"
- importance sampling: A variance-reduction technique that reweights samples to estimate expectations under a target distribution. "We consider an importance sampling formula and reformulate~\cref {eq:pop_risk} as"
- kernel: Here, a probabilistic mechanism defining how to sample related documents given a query (for retrieval-augmented training). "We formalize retrieval as sampling via a kernel."
- knowledge base: A curated corpus of documents used to retrieve relevant information for data synthesis and model enhancement. "every document in the knowledge base is embedded"
- majority-voting mechanism: Aggregating multiple model outputs and selecting the most frequent answer to improve reliability. "applied a majority-voting mechanism to determine a consensus answer;"
- MinHash: A technique for estimating Jaccard similarity efficiently, used here for near-duplicate detection. "we apply MinHash-based deduplication using 24 bands with a bandwidth of 10"
- Monte Carlo sampling: Random sampling method used to estimate expectations when analytical computation is intractable. "the overall post-training procedure can be viewed as optimizing an expected objective estimated via Monte Carlo sampling."
- negative log-likelihood (NLL): A common supervised loss that penalizes the model for assigning low probability to the correct output. "the supervised loss as the negative log-likelihood, NLL"
- Pass@1: An evaluation metric indicating the accuracy of the first (single) generation attempt. "we report Pass@1 as the primary evaluation metric"
- policy distribution: The probability distribution over outputs induced by the model’s current parameters in RL terminology. "or sharpens the policy distribution to produce more satisfactory responses with fewer samples"
- policy gradient: A class of reinforcement learning algorithms that update model parameters in the direction of performance improvement. "a vanilla policy gradient can be considered as fitting a distribution"
- policy ratio: The ratio of new to old policy probabilities for sampled tokens, used in clipped RL objectives. "which defines the policy ratio "
- proposal distribution: An approximate distribution used to generate or weight samples before shifting toward the target distribution. "the first stage SFT is trying to fit the model to a good proposal distribution "
- reinforcement learning (RL): A learning paradigm where models learn to maximize rewards through interaction or sampling. "SFT followed by RL has become a widely adopted recipe for improving LLMs’ reasoning ability"
- reinforcement learning with verified reward (RLVR): An RL setup where rewards are computed via deterministic, verifiable checks (e.g., answer correctness). "the subsequent RL with verifiable reward (RLVR) stages"
- response distillation: Training a smaller/target model on outputs generated by a stronger teacher to transfer reasoning quality. "serves as the teacher model to distill reasoning responses for each question."
- stratified sampling: Sampling that preserves the distribution across predefined strata (e.g., difficulty buckets) to balance diversity and difficulty. "we employ a difficulty-based weighted stratified sampling strategy"
- teacher model: A larger or stronger model whose outputs are used to supervise training of another model. "the teacher model is employed to regenerate the response once more."
- temperature: A scaling parameter controlling the sharpness of a sampling distribution; higher values yield flatter distributions. "where is the temperature to adjust the distribution."
- top-k (retrieval): Restricting selection to the k most similar items for efficiency and focus. "we use a top- truncated variant looks like:"
- vector retrieval: Using vector similarity over embeddings to retrieve semantically relevant documents. "Leveraging a vector retrieval algorithm, we retrieve the top-30 semantically most relevant documents"
- verified reward: A reward computed by checking whether an output meets a verifiable criterion (e.g., correct answer). "receives a verified reward as the advantage function "
Collections
Sign up for free to add this paper to one or more collections.