SingingBot: An Avatar-Driven System for Robotic Face Singing Performance
Abstract: Equipping robotic faces with singing capabilities is crucial for empathetic Human-Robot Interaction. However, existing robotic face driving research primarily focuses on conversations or mimicking static expressions, struggling to meet the high demands for continuous emotional expression and coherence in singing. To address this, we propose a novel avatar-driven framework for appealing robotic singing. We first leverage portrait video generation models embedded with extensive human priors to synthesize vivid singing avatars, providing reliable expression and emotion guidance. Subsequently, these facial features are transferred to the robot via semantic-oriented mapping functions that span a wide expression space. Furthermore, to quantitatively evaluate the emotional richness of robotic singing, we propose the Emotion Dynamic Range metric to measure the emotional breadth within the Valence-Arousal space, revealing that a broad emotional spectrum is crucial for appealing performances. Comprehensive experiments prove that our method achieves rich emotional expressions while maintaining lip-audio synchronization, significantly outperforming existing approaches.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
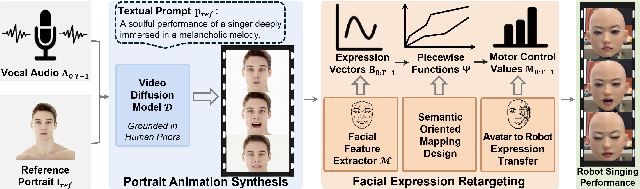
This paper introduces SingingBot, a system that helps a robot’s face “sing” in a natural, emotional, and lip-synced way. Instead of trying to control the robot directly from the audio, the system first creates a realistic singing video of a human-like avatar, then uses that avatar’s facial movements to guide the robot’s motors. The goal is to make robotic performances feel more expressive and lifelike, especially during songs where emotions and smooth movement matter a lot.
Key Questions and Objectives
The researchers set out to answer a few simple questions:
- How can we make a robot’s face sing with clear, synchronized lip movements and believable emotions?
- Can we use a realistic, AI-made singing avatar to guide a physical robot’s face?
- How do we measure “how emotional” a robotic performance is, not just whether the lips match the sound?
How the System Works (Methods)
The approach has three main steps. Think of it like using a very realistic cartoon (the avatar) as a “coach” for the robot’s face.
Step 1: Create a singing avatar video with AI
- The system uses a pre-trained video AI model (a “video diffusion model” called Hallo3) that has learned a lot from many real human videos. You can think of this as an AI with a deep understanding of how faces move and show feelings.
- Given a song’s vocal audio, a single reference portrait (who the avatar should look like), and a short text description (the style), the AI makes a 2D video of a person singing with rich emotions and good lip movements.
Step 2: Read the avatar’s facial movements
- The system extracts facial “blendshape” values from the avatar video. Blendshapes are like 52 sliders that control face muscles (for example, “jaw open” or “mouth smile”). This is a standard way to describe facial expressions used in animation.
- It smooths these values to avoid jitters, so the robot won’t make tiny, shaky moves.
Step 3: Translate those movements to the robot’s motors
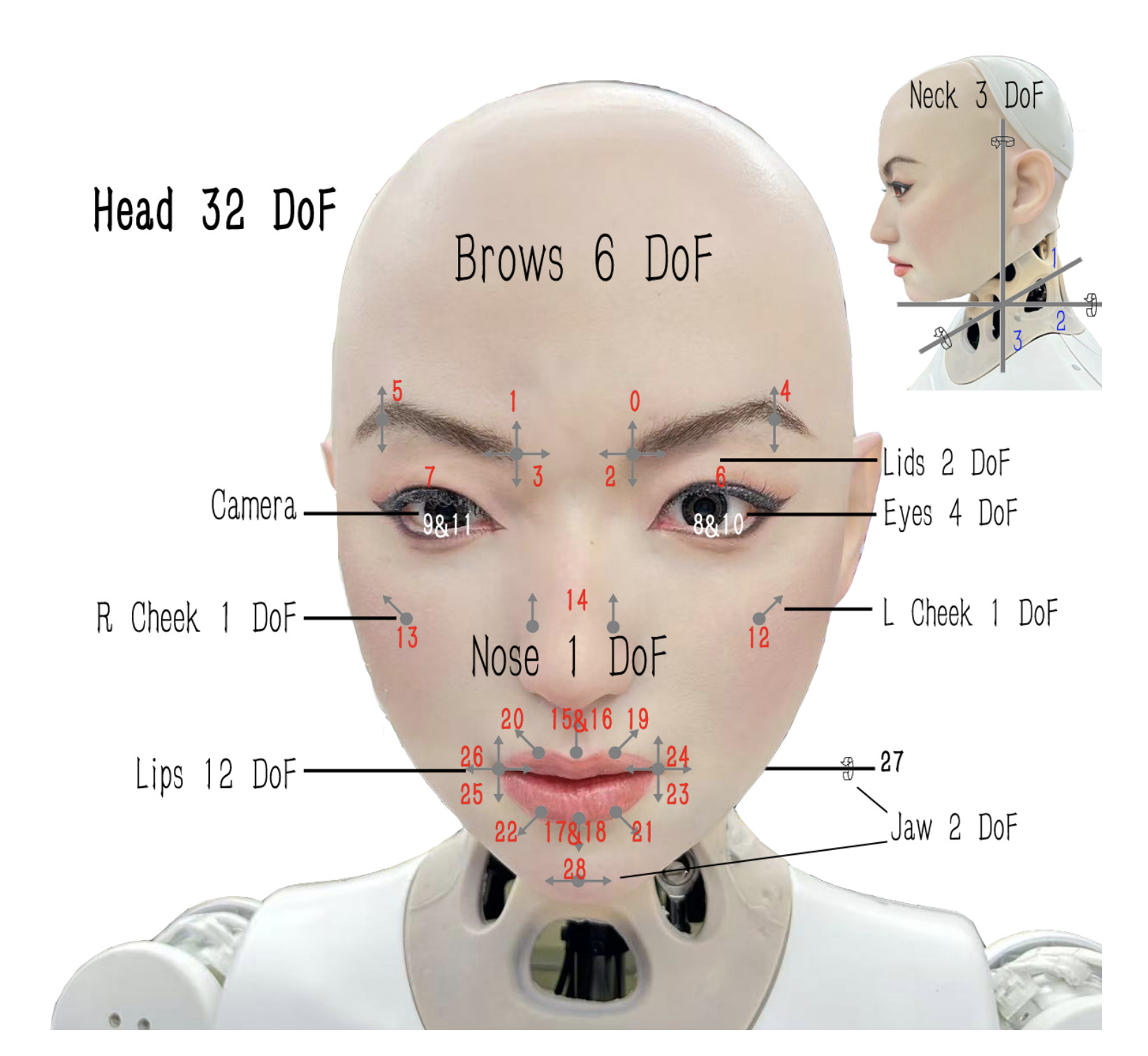
- The robot has 32 moving parts (Degrees of Freedom), including motors for the mouth, eyes, eyebrows, and neck. A robot doesn’t have real muscles or the exact same parts as a human face, so the team designed special “mapping rules.”
- These rules are “piecewise” and “semantic,” which means they:
- Connect each facial slider (like “jaw open”) to one or more robot motors.
- Use simple lines or segments to say “if the avatar opens the jaw a little, turn motor X a little; if the jaw opens a lot, turn motor X more.”
- Combine or skip features that the robot can’t physically do (for example, if the avatar has left/right nose movement but the robot only has one nose motor, they merge them).
- Neck movements are also mapped so the robot can move its head naturally.
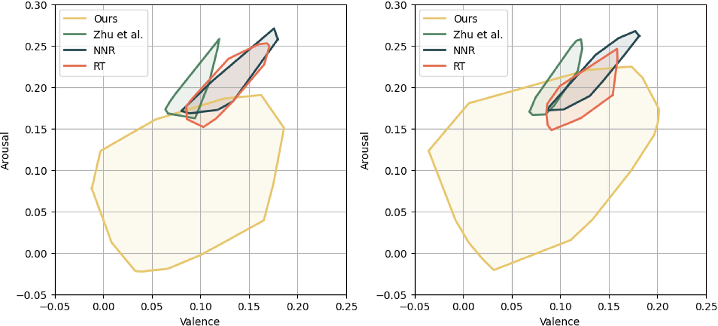
Measuring emotions: Emotion Dynamic Range (EDR)
- The paper doesn’t just check lip-sync; it also measures emotional richness.
- They use the “Valence-Arousal” space, which you can think of as a simple 2D map:
- Valence: how pleasant or unhappy the emotion is (sad to happy).
- Arousal: how energized the emotion is (calm to excited).
- As the robot sings, its emotions move around this map. EDR draws a shape around that path and measures its area. A bigger area means the robot covered a wider range of emotions, which usually feels more engaging and expressive.
Main Findings and Why They Matter
The team compared SingingBot to other methods:
- Random movements can be big and noticeable, but they look strange and don’t match the song.
- Methods that copy the closest example from a small dataset or directly predict robot motor values from blendshapes often make conservative, bland expressions and don’t handle singing well.
- SingingBot, guided by the realistic avatar and smart mapping rules, did best at both:
- Lip-sync: the robot’s mouth matches the audio more accurately.
- Emotion: the robot shows a much wider range of believable feelings during the song (much higher EDR).
In user studies, people rated SingingBot as more realistic, more emotionally resonant, and better at lip-sync than the other systems. The researchers also ran “ablation” tests showing that:
- Removing the avatar step hurts performance a lot.
- Using a simpler animated source without the diffusion model’s human knowledge also reduces emotional quality and lip-sync.
Implications and Potential Impact
This work is a step toward robots that feel more engaging and empathetic—important for companionship, reception, entertainment, and any situation where a robot interacts with people. It shows that:
- Using a realistic avatar as a “bridge” between AI and hardware can make physical robots act more human-like.
- Emotional richness matters. Measuring it (with EDR) helps researchers design and improve systems that don’t just move correctly—but feel expressive.
- With controllable avatars, robots can perform in different styles just by changing the reference portrait or prompt, opening the door to customizable performances.
In short, SingingBot makes robotic singing more natural, expressive, and fun to watch, and it offers a practical way to bring digital animation quality into the real world of human-robot interaction.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points identify what remains missing, uncertain, or unexplored in the paper and suggest concrete directions for future research.
- Validation of blendshape extraction accuracy: No ground-truth evaluation of MediaPipe ARKit blendshape coefficients on singing-specific motions (e.g., wide vibrato, extreme mouth openings, rapid articulations), under varying lighting, occlusions, or head poses.
- Intraoral articulation absence: The system does not model teeth/tongue dynamics, which are critical for phoneme accuracy in singing; feasibility of adding intraoral sensors/actuators or proxies remains unexplored.
- Robustness of emotion recognition on robotic faces: The EDR metric relies on a human-trained emotion recognizer applied to robot faces; its validity, bias, and failure modes on non-human facial morphology are not assessed.
- EDR metric construct validity: EDR (convex hull area in VA space) may conflate noise with expressiveness and ignores appropriateness, temporal coherence, and alignment with musical/emotional intent; alternative or complementary metrics are not investigated.
- Lip-sync metrics suitability for singing: LSE-D/LSE-C are trained/evaluated primarily on speech; their sensitivity to singing-specific phenomena (prolonged vowels, melisma, tempo changes) is unvalidated on robotic faces.
- Long-duration stability and wear: Only short clips (3–4 s) and a ~30 s demo are shown; there is no quantitative analysis of drift, actuator heating, skin hysteresis, or cumulative mechanical wear during extended performances.
- Latency and throughput: The real-time viability is unclear given remote diffusion generation (GPU) and local mapping (RK3588); end-to-end latency, failure recovery, and network constraints are not reported.
- Mapping generalization across robots: The manually crafted piecewise mappings are tailored to one 32-DoF platform; portability to different morphologies/DoFs and required calibration effort are not studied.
- Automatic calibration and adaptation: No method is provided to automatically learn or calibrate semantic mappings per robot (e.g., via self-supervised vision feedback, optimization, or reinforcement learning).
- Conflict resolution in motor blending: The additive piecewise design may produce actuator conflicts (e.g., competing expressions, saturation) without global constraints or optimization; strategies to avoid physically infeasible poses are absent.
- Trade-off between smoothing and articulation: Gaussian temporal smoothing may suppress high-frequency lip motions needed for clear singing; the optimal filtering design and its impact on intelligibility are not quantified.
- Evaluation breadth and baselines: Baselines are limited and may be mismatched to the task (e.g., EmoTalk for blendshapes, speech-focused systems); strong recent methods (diffusion-driven robot control, physics-aware controllers) are not compared.
- Dataset transparency and availability: The 10K training pairs and the 40-clip test set lack detailed description (collection protocol, labels, distributions), and the dataset is not released, limiting reproducibility.
- Biases in diffusion priors: The portrait video generator (Hallo3) may encode demographic and stylistic biases; their downstream impact on robot expressiveness and fairness is not analyzed.
- Cross-language and genre coverage: The test set includes “multiple languages,” but performance differences across languages, singing styles (opera, rap, vibrato, belting), and tempos are not dissected.
- Control over time-varying emotion: While style can be changed via a reference portrait/prompt, there is no mechanism or evaluation for time-scheduled emotional trajectories aligned to musical structure.
- Alignment between emotion and audio content: The appropriateness of expressed emotions relative to lyrics/prosody is not evaluated; metrics and protocols to assess semantic-emotional alignment are missing.
- Head/neck motion modeling: Head pose is linearly mapped from MediaPipe; coordinated head–eye–facial synergies and rhythmic gestures (common in performance) are not modeled or evaluated.
- Perceptual thresholds for micro-expressions: Claims of micro-expression transfer are qualitative; sensitivity analyses to determine the minimal actuator changes detectible by viewers are absent.
- Closed-loop feedback: The system is purely feedforward; using vision/proprioception to correct deviations (e.g., lip-sync errors, actuator lag) and maintain performance quality is not explored.
- Safety and ethics in HRI: Potential for emotional manipulation, uncanny valley effects, and cultural differences in affect perception is not addressed; user study lacks diverse populations and longitudinal assessments.
- Mechanical constraints and failure handling: Strategies for handling actuator limits, silicone skin nonlinearity, backlash, and fatigue are not formalized; health monitoring and graceful degradation are not described.
- Energy and thermal considerations: Power draw, thermal management during intensive singing motions, and their effects on performance fidelity are unreported.
- Prompt and style control evaluation: The influence of text prompts on generated avatar emotions/styles is not quantified; a systematic interface and evaluation for prompt-to-performance fidelity are missing.
- Cross-modal inputs: The system uses audio only; incorporating lyrics, score/tempo, or expressive performance annotations to guide emotion and articulation remains an open direction.
- Generalization beyond singing: Applicability to spoken dialogue with emotive prosody, storytelling, or multi-party interaction scenarios is not investigated.
- Human–robot co-performance: Interaction with live musicians or audiences (e.g., call-and-response, tempo following) and real-time adaptation to external cues are unaddressed.
- Intellectual property and licensing: Use of third-party diffusion models/data raises licensing and IP questions; guidelines for deployment and compliance are not discussed.
Glossary
- Actuators: Mechanical components (e.g., motors) that produce movement in the robot by executing control signals. "where represents the contributing motion control value to the robot's actuators."
- Affective computing: An interdisciplinary field focused on recognizing, interpreting, and simulating human emotions using computational methods. "Drawing inspiration from affective computing, we leverage the Valence-Arousal (VA) space derived from the Circumplex Model of Affect"
- Animatronic: Relating to lifelike robotic systems designed to mimic biological motions, especially facial expressions. "Animatronic Robotic Face Control."
- ARKit: Apple’s augmented reality framework that defines a standard set of facial blendshape coefficients for animation and tracking. "We adopt the 52-dimensional blendshape coefficient vector that complies with the ARKit standard~\cite{arkit} as the parameterized representation of facial expressions."
- Articulated linkages: Mechanical joints and linkages used to transmit motion from motors to the robot’s facial surface. "The motors are faim connected CNA to silicone skin NB through articulated linkages." Wait, the previous line is wrong text. Correction: " sop ".
Practical Applications
Below is a structured synthesis of practical, real-world applications enabled by the paper’s findings, methods, and innovations. The items are grouped by deployment horizon and include sector links, potential tools/workflows/products, and key assumptions or dependencies.
Immediate Applications
These applications can be deployed now on existing animatronic/robotic face hardware with the proposed avatar-driven pipeline and the EDR metric.
- Entertainment animatronics and live venues: emotionally rich, lip-synced robot singing
- Sector: entertainment, arts/culture, events
- Tools/products/workflows:
- “SingingBot Studio” pipeline: audio + reference portrait + prompt → portrait video → ARKit blendshapes → BS2Action mapping → servo trajectories
- Show control integration: schedule pieces; preview with EDR to tune emotional breadth; deploy to stage robots (e.g., 30–32 DoF facial rigs)
- Assumptions/dependencies:
- Access to a robot head with sufficient facial DoFs and compliant skin (similar to the Hobbs platform)
- Remote or on-prem GPU for diffusion portrait generation; reliable network between server and robot
- Manual calibration of the piecewise semantic mapping per robot model
- Retail/hospitality experience robots: seasonal or promotional singing and customer engagement
- Sector: retail, hospitality, marketing
- Tools/products/workflows:
- Content packs (holiday songs, brand jingles) with prompt-controlled styles aligned to brand personas
- EDR-based A/B testing to select performances with desired arousal/valence envelopes
- Assumptions/dependencies:
- Venue-safe operation; compliance with noise and safety standards
- Rights management for music and consent for reference portraits
- Museum and cultural exhibits: historically themed, expressive robot performances
- Sector: museums/cultural heritage, education
- Tools/products/workflows:
- Curator-guided prompts to achieve era-specific affect; batch-generate performances; EDR used as a curatorial metric for emotional scope
- Assumptions/dependencies:
- Historical likeness permissions; controlled lighting for reliable feature extraction
- QA and benchmarking for facial animation systems using EDR
- Sector: academia, software/animation, robotics QA
- Tools/products/workflows:
- “EDR Gauge” evaluation tool: compute VA trajectories and convex-hull area to quantify emotional breadth; pair with LSE-D/C for lip-sync QA
- Assumptions/dependencies:
- Validity of the chosen emotion recognition model for the target demographics and lighting; awareness of bias in affect estimators
- Research in empathetic HRI: repeatable, data-efficient robot expressivity studies
- Sector: academia (HRI, affective computing), robotics
- Tools/products/workflows:
- Avatar-driven retargeting avoids large paired datasets; reproducible benchmarks (LSE-D/C + EDR); ablations with/without diffusion priors
- Assumptions/dependencies:
- Access to diffusion portrait models and pre-trained emotion recognition models
- Ethics review for affective experiments with human participants
- Music and language education aids: demonstrating mouth articulation for vowels and lyrics
- Sector: education (music, speech therapy), EdTech
- Tools/products/workflows:
- Lesson content: slow-tempo, clearly articulated singing with adjustable style prompts
- EDR used to ensure target affect (e.g., low arousal for calming practice)
- Assumptions/dependencies:
- Classroom-safe hardware setup; synchronization with curricula
- VTubing/streaming pre-recorded segments on physical puppetry
- Sector: creator economy, media production
- Tools/products/workflows:
- Batch creation of expressive lip-synced puppet segments driven by audio and prompts; preview on virtual avatar; deploy servo trajectories for shoot days
- Assumptions/dependencies:
- Pre-recorded workflow (not low-latency live); studio safety and maintenance of silicone skins/actuators
- Standardized ARKit-to-robot control interfaces for OEMs
- Sector: robotics manufacturing, middleware/software
- Tools/products/workflows:
- BS2Action configuration kits: ARKit 52 blendshape → servo mappings per robot model; developer SDKs for Unity/Unreal pipelines
- Assumptions/dependencies:
- Vendor-specific calibration; shared specification of control ranges and mechanical limits
Long-Term Applications
These require further research, productization, real-time optimization, scaling, or policy frameworks.
- Real-time interactive singing and karaoke with audience feedback
- Sector: entertainment, consumer robotics
- Tools/products/workflows:
- Low-latency audio-to-portrait diffusion; continuous blendshape extraction and mapping; on-robot or edge inference; live EDR monitoring to adapt emotion
- Assumptions/dependencies:
- Significant optimization of diffusion models and on-device compute; low-latency audio capture and robust streaming
- Personalized music therapy robots with affect-aware adaptation
- Sector: healthcare (geriatrics, dementia care, mental health), therapy
- Tools/products/workflows:
- Closed-loop control: measure patient responses; adjust arousal/valence targets; curate emotion trajectories via EDR constraints
- Assumptions/dependencies:
- Clinical validation; safety and hygiene protocols; bias-aware affect sensing; integration with therapist workflows
- Home companion robots with expressive singing and storytelling
- Sector: consumer robotics, smart home
- Tools/products/workflows:
- “Mood-aware” content selection based on household context; scheduled performances (lullabies, birthdays); energy-efficient on-device generation
- Assumptions/dependencies:
- Cost-effective expressive heads with adequate DoFs; strong privacy and consent mechanisms for portrait prompts and audio data
- Teleperformance and telepresence: remote artists driving robot faces on stage
- Sector: performing arts, media production
- Tools/products/workflows:
- Performer audio and text prompts streamed to venue robot; director console to modulate style; EDR used to ensure the intended affect envelope
- Assumptions/dependencies:
- Network QoS guarantees; legal/union frameworks for remote performances and likeness/IP rights
- Cross-vendor plug-and-play facial control standards
- Sector: robotics manufacturing, standardization bodies
- Tools/products/workflows:
- Industry-wide adoption of ARKit-compatible facial semantics; shared mapping schemas; test suites using LSE and EDR
- Assumptions/dependencies:
- Consensus on control semantics; mechanical heterogeneity across platforms; safety certifications
- Full-body expressive performance (face + gaze + gestures)
- Sector: robotics, entertainment, education
- Tools/products/workflows:
- Extend avatar-driven retargeting to eyes, gaze, and upper-body gestures; multi-modal EDR-like metrics capturing broader affect
- Assumptions/dependencies:
- Additional sensors and actuators; coordinated control across subsystems; new metrics beyond facial VA
- Ethical and policy frameworks for emotionally persuasive robots
- Sector: policy/regulation, ethics, healthcare/education governance
- Tools/products/workflows:
- Disclosure guidelines for generated performances; consent management for reference portraits; content provenance/watermarking; emotion intensity caps for vulnerable populations
- Assumptions/dependencies:
- Multi-stakeholder engagement; standards for affective HRI; compliance with IP/copyright laws for music and likeness
- Accessibility and rehabilitation: guided facial exercises and lip-reading training
- Sector: accessibility, healthcare, education
- Tools/products/workflows:
- Programmatic control of mouth shapes and emotional cues for training exercises; EDR to tune arousal to user comfort
- Assumptions/dependencies:
- Collaboration with clinicians and accessibility experts; validation with target user groups
- Data-free cross-embodiment retargeting for expressive robots
- Sector: robotics R&D, software tools
- Tools/products/workflows:
- Generalized semantic piecewise mappings that scale to new facial morphologies with minimal manual anchors; semi-automated calibration tools
- Assumptions/dependencies:
- Robust semantic alignment across different skin and linkage mechanics; simulation-to-reality tools for faster mapping
- Integrated creative pipelines for animation/VFX and animatronics
- Sector: film/TV, live events
- Tools/products/workflows:
- Unified DCC plugins (Unity/Unreal/Blender) exporting both virtual avatar shots and synchronized servo cues; EDR as a creative dial for mood
- Assumptions/dependencies:
- Tooling integration; artist-friendly UX; synchronization with lighting and audio departments
- Robustness and safety engineering for public deployments
- Sector: safety engineering, operations
- Tools/products/workflows:
- Fail-safes for actuator limits; continuous monitoring of thermal and mechanical stress; safety-rated emotion constraints (e.g., avoid startling arousal spikes)
- Assumptions/dependencies:
- Hardware reliability; certification workflows; continuous self-diagnostics
Notes on general assumptions and dependencies across applications:
- Compute and latency: The avatar-driven approach currently assumes access to a capable GPU for video diffusion. Real-time or mobile deployments require further optimization or edge accelerators.
- Hardware capability: Effective expressivity depends on sufficient facial DoFs and high-quality elastomer skins; performance degrades on very sparse or rigid mechanisms.
- Calibration effort: The semantic-oriented, piecewise mapping must be tailored to each robot model (manual anchor design and interpolation).
- Perception robustness: Blendshape extraction and VA estimation can be sensitive to lighting, camera placement, and demographic biases in pre-trained models.
- Legal/ethical constraints: Consent for reference portraits, copyrights for music, and responsible use of emotionally persuasive behaviors are critical.
- Maintenance/operational constraints: Actuator wear, skin fatigue, and safety around audiences require planned upkeep and risk mitigation.
These application pathways leverage two unique contributions of the work: (1) avatar-driven, semantic mapping that avoids large paired datasets while scaling expressivity, and (2) the Emotion Dynamic Range metric that quantifies and steers the emotional breadth of performances.
Collections
Sign up for free to add this paper to one or more collections.