VINO: A Unified Visual Generator with Interleaved OmniModal Context
Abstract: We present VINO, a unified visual generator that performs image and video generation and editing within a single framework. Instead of relying on task-specific models or independent modules for each modality, VINO uses a shared diffusion backbone that conditions on text, images and videos, enabling a broad range of visual creation and editing tasks under one model. Specifically, VINO couples a vision-LLM (VLM) with a Multimodal Diffusion Transformer (MMDiT), where multimodal inputs are encoded as interleaved conditioning tokens, and then used to guide the diffusion process. This design supports multi-reference grounding, long-form instruction following, and coherent identity preservation across static and dynamic content, while avoiding modality-specific architectural components. To train such a unified system, we introduce a multi-stage training pipeline that progressively expands a video generation base model into a unified, multi-task generator capable of both image and video input and output. Across diverse generation and editing benchmarks, VINO demonstrates strong visual quality, faithful instruction following, improved reference and attribute preservation, and more controllable multi-identity edits. Our results highlight a practical path toward scalable unified visual generation, and the promise of interleaved, in-context computation as a foundation for general-purpose visual creation.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces VINO, a single AI model that can both make and edit images and videos. Instead of using different tools for different jobs (one for text-to-image, one for text-to-video, another for editing), VINO handles everything in one place. The goal is to make visual creation simpler, more consistent, and easier to control.
Key Objectives (In Plain Language)
The authors set out to answer a few big questions:
- Can one model handle many visual tasks at once (making images, making videos, and editing them) without getting confused?
- How can the model follow different kinds of instructions—long descriptive prompts and short editing commands—equally well?
- When given text, images, and videos together, how can the model combine these signals correctly without mixing them up?
- How can it keep important details (like a person’s identity) consistent across images and video frames?
- Can we train this unified model without “forgetting” the strong skills it starts with?
How the Method Works (In Simple Terms)
Think of VINO as a two-part team working together:
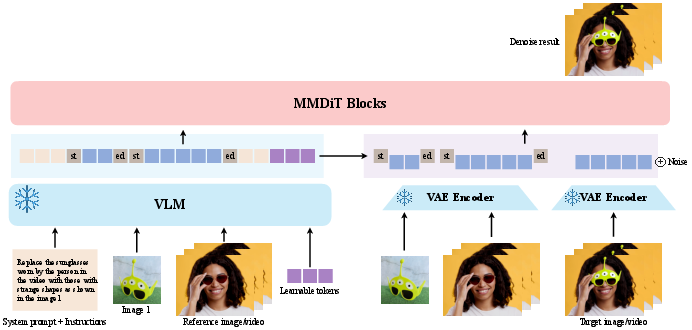
- The “Reader” (a Vision–LLM, or VLM): It understands everything you give it—text instructions, example images, and example videos. It turns them into small pieces of information called tokens, like a set of structured sticky notes the rest of the system can use.
- The “Artist” (a Diffusion Transformer, MMDiT): It is the painter/animator. Diffusion is a technique that starts with random noise and gradually “cleans” it up to form a picture or video—like a foggy window slowly becoming clear.
Here are the key ideas that make this work smoothly:
- Interleaved multimodal tokens: All inputs—your text, reference images, and reference videos—are turned into a single sequence of tokens (like lining up color-coded sticky notes). This helps the Artist see everything in context at once.
- Learnable query tokens: These are extra “blank sticky notes” the system learns to use on its own. They act like helpful prompts or reminders that improve how the Reader and Artist communicate. This stabilizes training and improves the quality of results.
- Preserving details with “latent” features: Besides the Reader’s tokens (which capture meaning), the system also passes a compressed version of the actual image/video data (called VAE latents) to keep fine details like textures and faces. Both the Reader’s tokens and these latents for the same reference are wrapped with matching “start” and “end” markers, so the Artist knows they belong together and won’t mix identities by mistake.
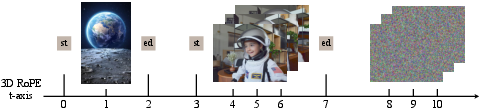
- Clear boundaries between different inputs: The model uses special boundary tokens to separate different images and videos inside the Artist’s sequence. This avoids confusion (for example, it won’t treat a still photo as if it’s part of a video timeline).
- A simple “control knob” during generation: A setting called image classifier-free guidance (Image CFG) lets you trade off between strict identity matching (stick closely to the reference image) and creative motion (more dynamic movement in video).
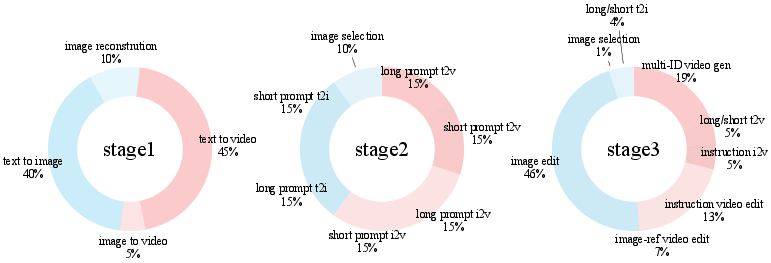
Training strategy (step by step):
- Start with a strong text-to-video model as the base “Artist.”
- Teach it to understand the Reader’s outputs by training a small connector so the two parts speak the same language.
- Mix in both long prompts and short prompts so it learns to handle both storytelling and quick edit instructions.
- Finally, train on many tasks together (image generation, video generation, and editing) so it becomes a unified, multi-task visual creator—without losing the original quality of the base model.
What They Found and Why It Matters
The authors tested VINO on many public benchmarks and tasks. In short, it works well as a “do-everything” visual model.
- Strong image and video generation: On tests like Geneval (images) and VBench (videos), VINO keeps high quality and follows prompts well—comparable to its strong starting model—showing it didn’t “forget” how to create good visuals.
- Better reference-based generation: On a subject-driven video benchmark (OpenS2V), VINO handles personal or object references more reliably. It keeps identities and attributes consistent across frames.
- Fast, effective editing skills: Even after just a small amount of editing training, VINO quickly learns to perform high-quality image edits (like adding, removing, or replacing things) and improves further with more training.
- Strong instruction following in video editing: Against another editing system (VACE-Ditto), VINO produces edits that people prefer in user studies and scores better on several video quality measures.
- Why it works (from ablations):
- Learnable query tokens make training smoother and edits more accurate.
- Boundary tokens between different inputs prevent mixing up images and videos.
- The Image CFG “knob” balances identity fidelity and motion: higher values match the reference better but can reduce movement; moderate values give a good balance.
Overall, this shows a practical way to build one model that does many creative visual tasks well.
Implications and Potential Impact
- Simpler creative tools: Instead of juggling multiple models, creators could use one tool for images, videos, and edits—saving time and making workflows more consistent.
- Better control and consistency: Because it sees all inputs together, VINO can follow complex instructions, keep faces/identities consistent across frames, and perform multi-step edits more reliably.
- Scalable foundation: The approach of interleaving text, images, and videos as a single context suggests a path toward even broader multimodal systems (for example, adding audio or 3D in the future).
Limits and What’s Next
- Text rendering is weak: The base model doesn’t draw readable text well, so tasks that need writing inside images/videos are harder.
- Editing data quality: Available editing datasets are smaller and less rich than generation datasets, which can limit some editing skills.
Future work could improve text drawing, gather better editing data, handle longer videos, and add more modalities—while also building safety features to prevent misuse (like deepfakes).
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research:
- Lack of explicit limits and scaling behavior when interleaving many references and modalities simultaneously (e.g., maximum number of images/videos before conditioning conflicts arise or quality drops).
- No quantitative analysis of long-form instruction following (multi-step, compositional prompts), despite claims of supporting such inputs.
- Absence of evaluation on complex multi-identity interactions (e.g., edits involving 3+ subjects and fine-grained attribute control), beyond anecdotal qualitative claims.
- No study of robustness to challenging real-world conditions (occlusions, fast camera motion, extreme lighting, heavy scene clutter) for both generation and editing.
- The VLM is kept frozen; the paper does not examine whether fine-tuning the VLM (or parts of it) would improve conditioning precision, edit localization, or reduce semantic conflicts.
- The learnable query tokens are shown to stabilize training, but their design space is underexplored: number of tokens, initialization schemes, masking strategy (causal vs. bidirectional), and placement within prompts.
- No sensitivity analysis of the MLP “connector” that maps VLM features to the MMDiT space (e.g., depth, width, nonlinearity choices, regularization), nor its impact on modality alignment and fidelity.
- Reuse of VLM <|vision_start|>/<|vision_end|> embeddings as boundary markers for VAE latents is not compared against alternative designs (separate learned boundary tokens, content-aware separators, or positional encodings) to assess interference or coupling effects.
- The 3D RoPE schedule for the VAE branch is introduced without ablation against alternative positional schemes (learned position embeddings, hybrid absolute/relative encodings, content- or duration-aware schedules), or analysis of sequence-length scaling.
- No characterization of failure modes when concatenating heterogeneous latent sequences at inference (e.g., variable-length videos plus multiple images) beyond a single artifact example; missing systematic tests and metrics.
- Image classifier-free guidance (Image CFG) is tuned manually; there is no method for adaptive CFG scheduling over time or content, nor evaluation of temporal CFG strategies to balance identity fidelity and motion.
- Lack of explicit edit localization mechanisms (masks, boxes, keypoints, segmentation), which limits precise spatial control; the text-only localization approach is not rigorously benchmarked against explicit controls.
- Editing of textual content (rendered text in images/videos) is unsupported due to the base model’s limitations; there is no exploration of integrating text rendering modules or specialized sub-networks.
- Progressive training curriculum design (stage boundaries, mixture ratios) is not ablated; unclear how sensitive performance is to curriculum choices or whether alternative schedules avoid catastrophic forgetting more effectively.
- Catastrophic forgetting is assessed only with Geneval/VBench; no tests on diverse, out-of-distribution prompts, ultra-long videos, or high-resolution scenes to stress retention of base-model priors.
- No explicit compute and efficiency analysis: training/inference throughput, memory footprint, latency impacts of multi-reference conditioning, and scaling to longer sequences or higher resolutions (e.g., 1080p, 4K).
- Dynamic resolution bucketing claims generalization across resolutions, but there is no quantitative evaluation on high-resolution outputs or aspect-ratio extremes.
- Limited generalization analysis across backbones: starting from a video model (HunyuanVideo) may confer advantages; the paper does not test starting from an image backbone or alternative video backbones to assess portability.
- Reliance on proprietary or distillation datasets (including from open-source models) is not audited for data contamination or overlap with evaluation sets; potential inflation of metrics due to training-test leakage is unaddressed.
- Instruction-based editing datasets are acknowledged as lower quality (limited motion, simpler structures), but the paper does not propose or evaluate strategies to mitigate dataset quality gaps (e.g., synthetic augmentation, hard-negative mining).
- Heavy reliance on VLM-based and GPT-based evaluations introduces potential biases; there is no cross-validation with human expert ratings at scale, nor robustness checks across multiple evaluators/metrics.
- The “LLM rewriter” variants (denoted by †) show improvements, yet the paper lacks analysis of dependency on rewriting, latency overheads, or how rewriting changes instruction distributions and failure modes.
- Limited analysis of identity preservation metrics over long videos (drift, swap, or attribute leakage rates across time); existing metrics (e.g., FaceSim) are insufficient for granular, time-resolved identity tracking.
- No exploration of multi-modal conflict resolution policies (priority rules, gating), beyond token boundaries; unclear how the model arbitrates contradictory cues (e.g., text says “red shirt” while reference shows “blue shirt”).
- Absence of safety, bias, and misuse analysis (e.g., deepfake risks, demographic bias, harmful content generation), despite identity-preserving and editing capabilities.
- No adversarial robustness assessment: susceptibility to prompt injection, adversarial images/videos, or deceptive references that could cause harmful edits or misconditioned generations.
- Limited transparency on reproducibility: while code is linked, trained weights, data mixture details, and complete training recipes (e.g., exact datasets, sampling policies, filtering criteria) are not fully specified.
- Missing calibration of general-purpose controllability features (e.g., strength knobs per modality, per-reference weighting, time-varying conditioning schedules) and their user-facing reliability.
- The method is termed “omnimodal,” but only text, image, and video are supported; extensions to audio, depth, segmentation maps, 3D, or motion cues (optical flow) are not addressed.
- Unclear how the system handles cross-references in instructions (e.g., “Use Image 1’s background with Video 2’s subject”) at scale; no dedicated evaluation of cross-referential comprehension and grounding accuracy.
- Lack of systematic failure-case taxonomy and countermeasures (e.g., when edits overfit to references, when motion collapses under high CFG, or when backgrounds drift).
- No analysis of temporal consistency mechanisms beyond RoPE; e.g., whether explicit temporal constraints, memory tokens, or recurrent structures could reduce flicker or drift for longer sequences.
- The impact of causal masking applied to learnable tokens (instead of bidirectional attention) is not contrasted with alternatives, leaving unclear whether masking choice limits multimodal fusion or edit precision.
- No study of content-aware or per-region conditioning (e.g., different references guiding different spatial regions), which could improve multi-identity and multi-object scene edits.
- Absence of comparison with unified closed-source generators on a standardized protocol; current comparisons mix models and metrics without controlling for prompt distributions or resolution/time budgets.
- Unclear data governance and licensing implications for using datasets like LAION and distillation outputs; ethical and legal considerations are not discussed.
- No investigation into model interpretability for conditioning: tools to inspect token attention across modalities, boundary-token utilization, and attribution of generated content to specific inputs are missing.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage VINO’s unified architecture (shared diffusion backbone + VLM with learnable query tokens, token-boundary mechanism, and VAE-latent injection) to deliver practical value today.
- Bold ad creative generation and localization
- Sectors: marketing, retail/e-commerce, media
- What it does: Generate and edit campaign assets (images/videos) from product references and concise instructions, preserve brand/product identity across shots, and quickly localize backgrounds, colors, and languages (except rendered text, see assumptions).
- Tools/workflows: “A/B Creative Explorer” to produce on-brief variations; “Batch Product Localizer” to swap backgrounds and colorways at scale; plugins for Adobe/Figma/Canva to perform instruction-based edits with multi-reference grounding.
- Assumptions/dependencies: Careful tuning of image-CFG to balance identity fidelity and motion; content/IP rights for reference media; content moderation and watermarking; base model lacks text rendering for in-frame typography.
- Continuity-aware video editing assistant
- Sectors: film/TV, social media, enterprise comms
- What it does: Instruction-based video edits (object removal/replacement, color/style adjustments) with temporal consistency using VAE latent injection and the special token boundary. Reduces manual rotoscoping/shot-by-shot work.
- Tools/workflows: “Continuity Edit Assistant” within NLEs (Premiere/Resolve) to apply scripted edits across a sequence; batch object/background edits while preserving scene identity and motion smoothness.
- Assumptions/dependencies: Requires GPU acceleration; safety review for edits that change meaning of documentary/news footage; provenance signals advised for ethical use.
- Product catalog standardization and synthetic spins
- Sectors: e-commerce, marketplaces
- What it does: Convert heterogeneous seller photos into consistent catalog imagery; generate identity-preserving 360° product spins or short showcase clips from multi-reference photos.
- Tools/workflows: “Catalog Harmonizer” for background unification; “Synthetic Spin Generator” for short product videos; automated variant creation (color/finish) from reference grounding.
- Assumptions/dependencies: Accurate color reproduction calibration; rights to use references; quality control to avoid hallucinated details.
- Concept-to-shot storyboard and previz
- Sectors: creative studios, game dev, virtual production
- What it does: Rapidly generate shot sequences with consistent characters, props, and environments from multi-reference boards and textual beats; iterate on motion/style while preserving identity via token-boundary and image-CFG controls.
- Tools/workflows: “Reference Board → Scene” previz tool; “Style Lock” toggles using image-CFG; integration with asset libraries (characters/props).
- Assumptions/dependencies: Motion diversity vs fidelity trade-off (CFG tuning); GPU costs for longer sequences.
- Instruction-based photo enhancement and object edits for consumers
- Sectors: daily life, prosumer photo/video apps
- What it does: One-click instruction edits (remove object, change sky, recolor clothing) with structure-preserving results; rapid adaptation demonstrated after 1k edit-tuning steps.
- Tools/workflows: Mobile/desktop photo apps using the unified API; “Quick Fix” and “Smart Replace” actions grounded by references (e.g., ideal background).
- Assumptions/dependencies: Responsible-use guardrails to prevent deceptive edits; device/offload strategy for compute.
- Synthetic data generation for perception and QA
- Sectors: robotics, autonomous systems, CV research
- What it does: Create identity-consistent image/video datasets with controlled attributes (lighting, backgrounds, motion) for training/testing vision models; multi-reference conditioning improves repeatability.
- Tools/workflows: “Synthetic Video Data Factory” with scenario templates; automated variation sweeps across attributes for robustness studies.
- Assumptions/dependencies: Domain gap to real data must be measured; license-compatible training/testing policies; content labeling to avoid data contamination.
- Unified visual generation API for development teams
- Sectors: software, platforms, MLOps
- What it does: Replace fractured image/video stacks with a single API for T2I, T2V, I2I, I2V, and instruction-based editing; consistent conditioning semantics across modalities.
- Tools/workflows: “VINO Service” with routing by task; SDKs for Python/TypeScript; standardized prompt schema with interleaved references.
- Assumptions/dependencies: GPU provisioning and cost management; input validation; rate limiting; safety filters.
- Research testbed for multimodal conditioning and instruction following
- Sectors: academia, applied ML labs
- What it does: Study cross-modal grounding via learnable query tokens; ablate token-boundary mechanisms and 3D RoPE scheduling; benchmark unified image/video editing/generation.
- Tools/workflows: Reproducible pipelines for progressive curriculum training; standardized prompts for long/short instruction regimes; plug-in connectors for alternative VLMs.
- Assumptions/dependencies: Dataset curation quality; reproducibility across checkpoints; responsible dataset governance.
- Accessibility-oriented visual aids
- Sectors: education, public sector, nonprofits
- What it does: Generate illustrative images/videos from succinct instructions and references to aid explanations, procedures, lab demos, or language learners.
- Tools/workflows: “Explain by Visual” assistant in LMS; teacher tools for quickly creating aligned visuals.
- Assumptions/dependencies: Bias mitigation; factuality disclaimers; avoid misuse in sensitive contexts (e.g., medical diagnosis).
- Policy prototyping: evaluation and watermark stress-testing
- Sectors: policy, standards bodies, trust & safety
- What it does: Use VINO outputs to evaluate watermarking/provenance robustness and detection pipelines across both images and videos; test instruction-following edge cases.
- Tools/workflows: “Synthetic Media Policy Lab” experiments comparing watermark schemes; curated edge-case prompt sets.
- Assumptions/dependencies: Access to watermarking/provenance tools; cross-model comparison baselines; legal/ethical oversight.
Long-Term Applications
These applications require additional research, scaling, or productization (e.g., stronger text rendering, longer context windows, safety/tooling maturity, or real-time performance).
- End-to-end creative co-pilot (script → shot list → consistent scenes)
- Sectors: media/entertainment, advertising, education
- What it could do: Turn scripts/story beats into multi-shot, identity-consistent sequences; maintain character continuity across episodes; perform global edits via long-form instructions.
- Enablers: Longer context conditioning, richer scene graphs, tighter LLM-VLM planning loops, improved temporal coherence for long videos.
- Dependencies: Scalable inference; content rights; advanced timeline/asset management; reliability for production deadlines.
- Personalized, cross-modal digital humans and avatars
- Sectors: social, gaming, customer support, virtual worlds
- What it could do: Generate consistent personas across images and videos, adapt style/motion on demand, and persist identity across sessions for storytelling or support avatars.
- Enablers: Robust multi-identity editing, improved identity preservation, controllable motion priors.
- Dependencies: Informed consent and privacy controls; bias and fairness auditing; deepfake safeguards and provenance.
- Automated privacy and compliance editing at scale
- Sectors: public sector, healthcare, enterprise platforms
- What it could do: Instruction-driven redaction (faces/plates), cultural localization, logo masking, and policy-compliant edits across long videos with temporal consistency.
- Enablers: Fine-grained, instruction-following video editing with consistent grounding; integration with detection/QA systems.
- Dependencies: High-accuracy detectors; audit logs/provenance; domain certifications; on-prem deployment options.
- Mixed-reality content generation for XR
- Sectors: AR/VR/MR, gaming, training
- What it could do: Real-time or near-real-time generation/editing of visuals conditioned by text, scene captures, and user cues; consistent objects across sessions.
- Enablers: Model compression and streaming inference; hardware acceleration; low-latency token interfaces and efficient MMDiT blocks.
- Dependencies: On-device inference constraints; safety of generated immersive content; UI/UX standards for mixed-reality edits.
- Data-centric simulation for robotics and autonomous driving
- Sectors: robotics, automotive
- What it could do: Generate long, dynamic, multi-actor scenes from reference assets and scenario instructions to augment rare events and edge cases.
- Enablers: Stronger motion dynamics, multi-entity grounding with low identity swap, controllable attribute distributions.
- Dependencies: Realism and transfer studies; safety-case documentation; large-scale validation pipelines.
- CAD/architecture and digital twins previsualization
- Sectors: AEC, industrial design, smart cities
- What it could do: From design references + instructions, produce walkthrough videos and seasonal/time-of-day variations while preserving structural identity.
- Enablers: Tighter geometry conditioning interfaces; integration with BIM/CAD metadata and depth/segmentation controls.
- Dependencies: Structural accuracy guarantees; client confidentiality; material/color calibration.
- Multilingual, multimodal educational content generation
- Sectors: education, publishers
- What it could do: Automatically create localized visual lessons with identity-consistent characters and experiments; adapt visuals to reading level and cultural context.
- Enablers: Improved instruction parsing for short vs. long prompts; compositional control across multiple references; robust evaluation for semantic fidelity.
- Dependencies: Pedagogical oversight; accessibility compliance; content veracity.
- Trusted media ecosystems with provenance-by-design
- Sectors: policy, platforms, standards
- What it could do: Integrate standardized watermarking/provenance for both image and video outputs, support automated disclosures, and facilitate platform-level detection.
- Enablers: Cross-vendor standards, robust watermarking against common edits, unified metadata across modalities.
- Dependencies: Interoperable C2PA-like standards for video; regulatory alignment; user education.
- Real-time telepresence and productivity video filters
- Sectors: enterprise productivity, communications
- What it could do: Live, instruction-based background replacement, style changes, and lighting adjustments with temporal stability and identity preservation.
- Enablers: Low-latency diffusion variants; efficient token and latent processing; hardware support.
- Dependencies: Privacy/consent controls; resilience to motion and bandwidth; corporate IT/security constraints.
Notes on Feasibility and Dependencies
- Compute and latency: Video diffusion is GPU-intensive; productization needs batching, model distillation, or streaming inference. Real-time use cases require optimization or specialized hardware.
- Data and rights: Training and inference with reference images/videos require IP compliance and explicit consent. Synthetic data must be labeled to avoid contamination of downstream training corpora.
- Safety and governance: Essential to implement content moderation, watermarking/provenance, and usage policies (especially for identity-preserving edits). Consider user disclosures and audit logs.
- Model limits: The base model currently lacks text rendering; tasks involving in-frame text generation/editing will lag without an auxiliary renderer.
- Prompt quality and tooling: Performance benefits from prompt engineering and LLM prompt rewriters; UI scaffolding (reference indexing, CFG sliders) helps non-experts manage fidelity/motion trade-offs.
- Generalization and bias: Editing datasets are of lower quality/variety than generation datasets; monitor for distributional bias and artifacts when applying in sensitive domains (healthcare, public sector).
- Integration: VINO relies on a VLM front end (e.g., Qwen3VL-4B) and a video diffusion backbone (e.g., HunyuanVideo). Swapping components may need connector re-training and re-validation.
- Provenance and trust: For public communications, news, and education, pair outputs with provenance and disclaimers to preserve trust, and align with platform/regulatory standards.
Glossary
- 3D RoPE: Three-dimensional Rotary Position Embeddings that encode spatial-temporal positions for attention in sequences like video latents. Example: "3D RoPE strategy for the VAE branch in VINO."
- Ablation study: A systematic experiment to remove or modify components to assess their contribution. Example: "We conduct comprehensive ablation studies"
- AdamW: An optimizer that decouples weight decay from the gradient-based update to improve generalization. Example: "AdamW betas"
- Attribute leakage: Unintended transfer of attributes (e.g., color, style) from one reference to another in generation or editing. Example: "attribute leakage"
- Causal masking: Attention masking that restricts tokens to attend only to previous tokens, enforcing autoregressive behavior. Example: "using causal masking rather than granting full bidirectional attention"
- Catastrophic forgetting: Loss of previously learned abilities when training on new tasks. Example: "A primary concern in instruction tuning is catastrophic forgetting"
- DeepSpeed ZeRO-2: A memory-optimization technique for distributed training that partitions optimizer states and gradients. Example: "we train using DeepSpeed ZeRO-2"
- Denoising: The iterative process in diffusion models that removes noise to synthesize images or videos. Example: "The MMDiT model performs denoising conditioned on the full multimodal context"
- Diffusion backbone: The core denoising network in a diffusion model that learns to reconstruct data from noise. Example: "uses a shared diffusion backbone that conditions on text, images and videos"
- Dynamic resolution bucketing: Grouping inputs by similar effective area to preserve aspect ratios while balancing compute. Example: "dynamic resolution bucketing strategy"
- EMA (Exponential Moving Average): A running average of model weights used to stabilize training and improve evaluation performance. Example: "Ema decay"
- Geneval: A benchmark for evaluating text-to-image capabilities such as composition and attribute alignment. Example: "using Geneval"
- Gradient checkpointing: A memory-saving technique that recomputes activations during backpropagation to reduce GPU memory use. Example: "We further apply gradient checkpointing to the MMDiT backbone"
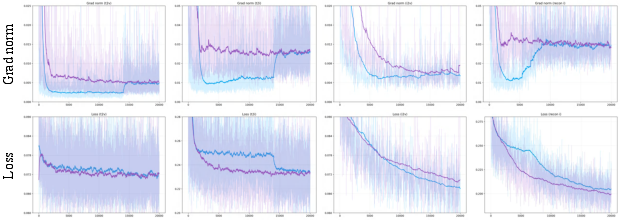
- Gradient clipping: Limiting the norm of gradients to stabilize training and prevent exploding gradients. Example: "Gradient norm clip"
- Gradient variance: The variability of gradient estimates during training; lower variance often indicates more stable optimization. Example: "lower gradient variance"
- Identity preservation: Maintaining the subject’s appearance and attributes across generated outputs. Example: "improved identity preservation"
- Identity swapping: Incorrectly exchanging identities between subjects when conditioning on multiple references. Example: "identity swapping"
- Image CFG (Classifier-Free Guidance): A guidance technique controlling the strength of reference-image conditioning during generation. Example: "Image CFG"
- In-context computation: Processing where conditioning information is interleaved with inputs so the model reasons over context directly. Example: "interleaved, in-context computation"
- Instruction following: The ability of a model to execute edits or generations that adhere closely to user-provided instructions. Example: "faithful instruction following"
- Instruction tuning: Fine-tuning a model on instruction–response pairs to improve adherence to user commands. Example: "instruction tuning"
- Interleaved omnimodal context: A sequence that mixes text, image, video, and learnable tokens to provide unified conditioning. Example: "interleaved omnimodal context"
- Learnable query tokens: Trainable tokens inserted into the input that act as an interface between high-level instructions and low-level features. Example: "learnable query tokens"
- LLM rewriter: A technique that rewrites prompts using a LLM to improve adherence or clarity before generation. Example: "LLM rewriter"
- Multimodal conditioning: Guiding generation using multiple input modalities (e.g., text, images, videos) simultaneously. Example: "improve multimodal conditioning"
- Multimodal Diffusion Transformer (MMDiT): A transformer-based diffusion architecture that operates over tokenized multimodal inputs and latents. Example: "Multimodal Diffusion Transformer (MMDiT)"
- Multi-reference grounding: Correctly associating and using multiple references (images/videos) during generation or editing. Example: "multi-reference grounding"
- Null-text inversion: A technique to invert an image into a diffusion model’s latent space without conditioning text, facilitating faithful edits. Example: "null-text inversion"
- OpenS2V: A benchmark for subject-driven, reference-based video generation and evaluation. Example: "OpenS2V"
- Special token: A marker token inserted to separate or delineate segments (e.g., different VAE latent blocks) in a sequence. Example: "special token for separating VAE latents"
- Subject-driven video generation: Video synthesis controlled by one or more reference subjects whose identity and attributes must be preserved. Example: "subject-driven, reference-based video generation"
- Temporal dynamics: The motion and temporal coherence properties in video generation. Example: "temporal dynamics"
- Token-boundary mechanism: Reusing special start/end tokens across semantic and latent streams to keep features from the same source aligned. Example: "token-boundary mechanism"
- VAE latents: Compressed latent representations produced by a Variational Autoencoder used to retain fine-grained visual details. Example: "VAE latents"
- VBench: A benchmark for evaluating text-to-video generation across quality, semantics, and consistency. Example: "VBench"
- Vision–LLM (VLM): A model that jointly processes visual and textual inputs for understanding or conditioning generation. Example: "a frozen VLM model"
Collections
Sign up for free to add this paper to one or more collections.