NitroGen: An Open Foundation Model for Generalist Gaming Agents
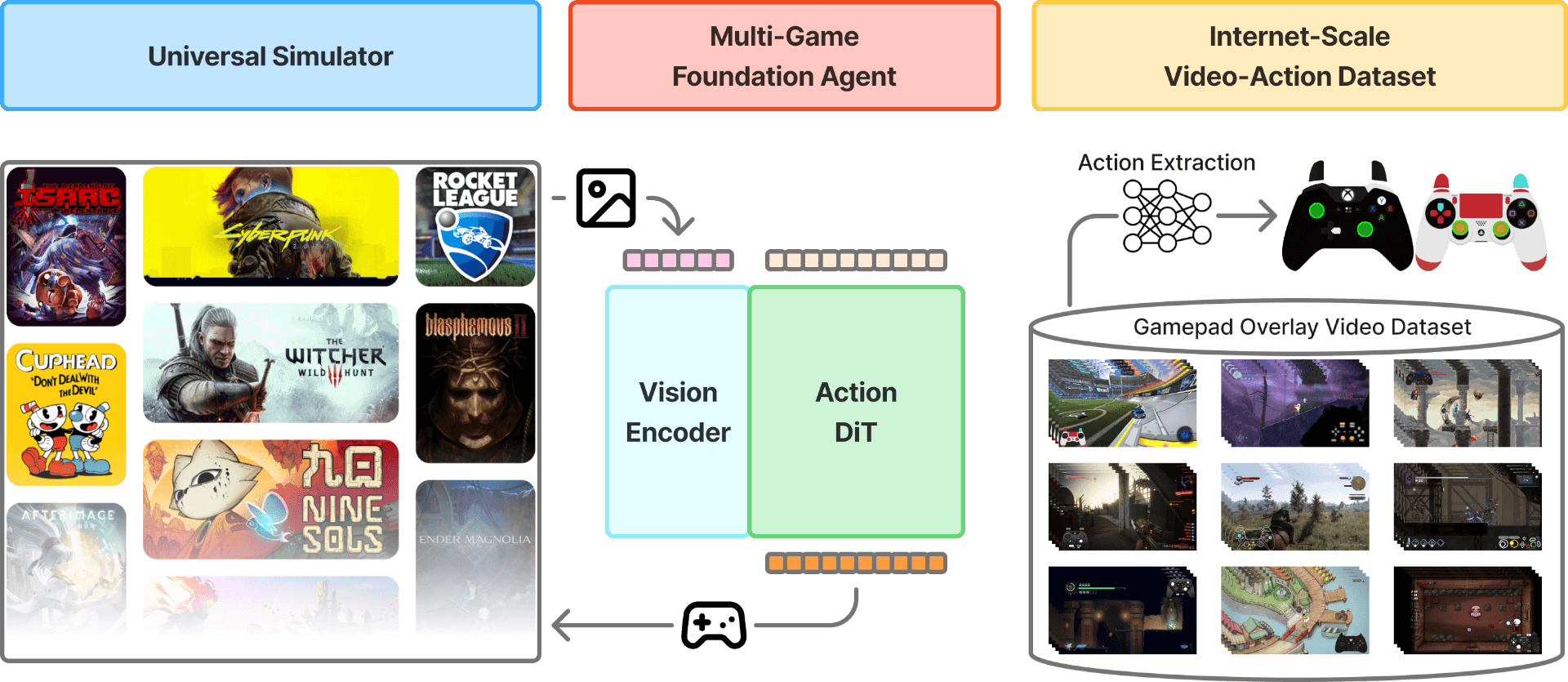
Abstract: We introduce NitroGen, a vision-action foundation model for generalist gaming agents that is trained on 40,000 hours of gameplay videos across more than 1,000 games. We incorporate three key ingredients: 1) an internet-scale video-action dataset constructed by automatically extracting player actions from publicly available gameplay videos, 2) a multi-game benchmark environment that can measure cross-game generalization, and 3) a unified vision-action model trained with large-scale behavior cloning. NitroGen exhibits strong competence across diverse domains, including combat encounters in 3D action games, high-precision control in 2D platformers, and exploration in procedurally generated worlds. It transfers effectively to unseen games, achieving up to 52% relative improvement in task success rates over models trained from scratch. We release the dataset, evaluation suite, and model weights to advance research on generalist embodied agents.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Explanation of “An Open Foundation Model for Generalist Gaming Agents” (Nitrogen)
What is this paper about?
This paper introduces Nitrogen, a computer program that learns to play many different video games by watching gameplay videos and copying what the players do. The big idea is to build a single “generalist” game-playing model that can handle lots of games and tasks—not just one game at a time.
What questions were the researchers trying to answer?
They focused on three main questions:
- Can we build a huge, diverse dataset of gameplay videos that also includes the players’ button presses and joystick moves, without paying people to label everything by hand?
- Can we make a fair test that checks whether one model can play many different games and tasks?
- If we train a single model on lots of games, will it learn useful, general skills that transfer to new games?
How did they do it?
They put together three key pieces to make Nitrogen work:
- A massive, automatically labeled video dataset
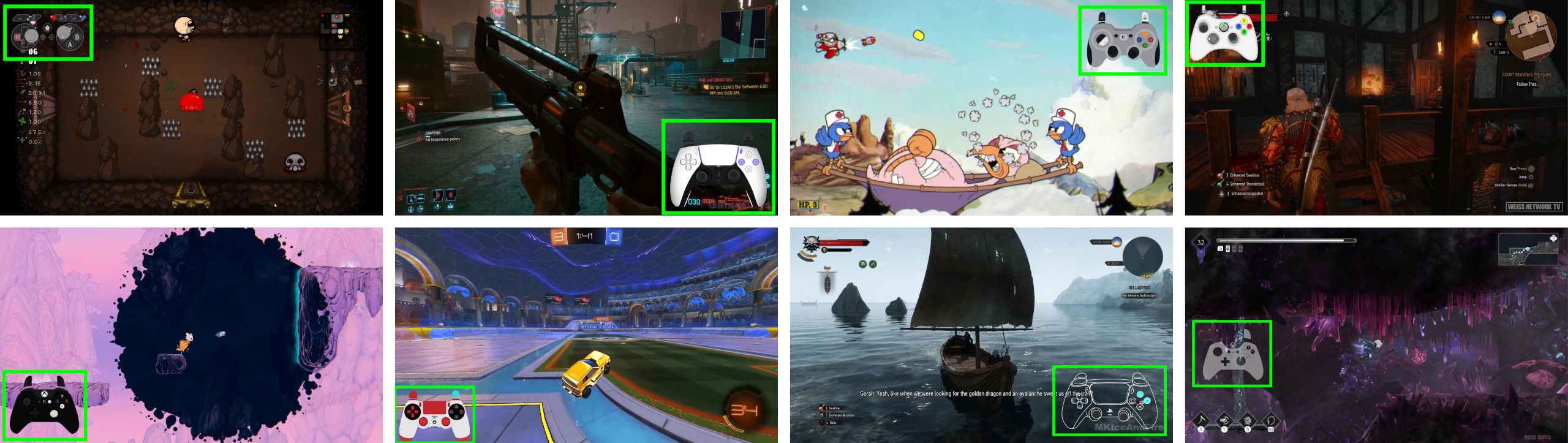
- Many gamers put an “input overlay” on their videos—a small on-screen picture of a controller that lights up to show exactly which buttons they press in real time.
- The team collected about 71,000 hours of such videos from over 1,000 games and then filtered it down to 40,000 high-quality hours.
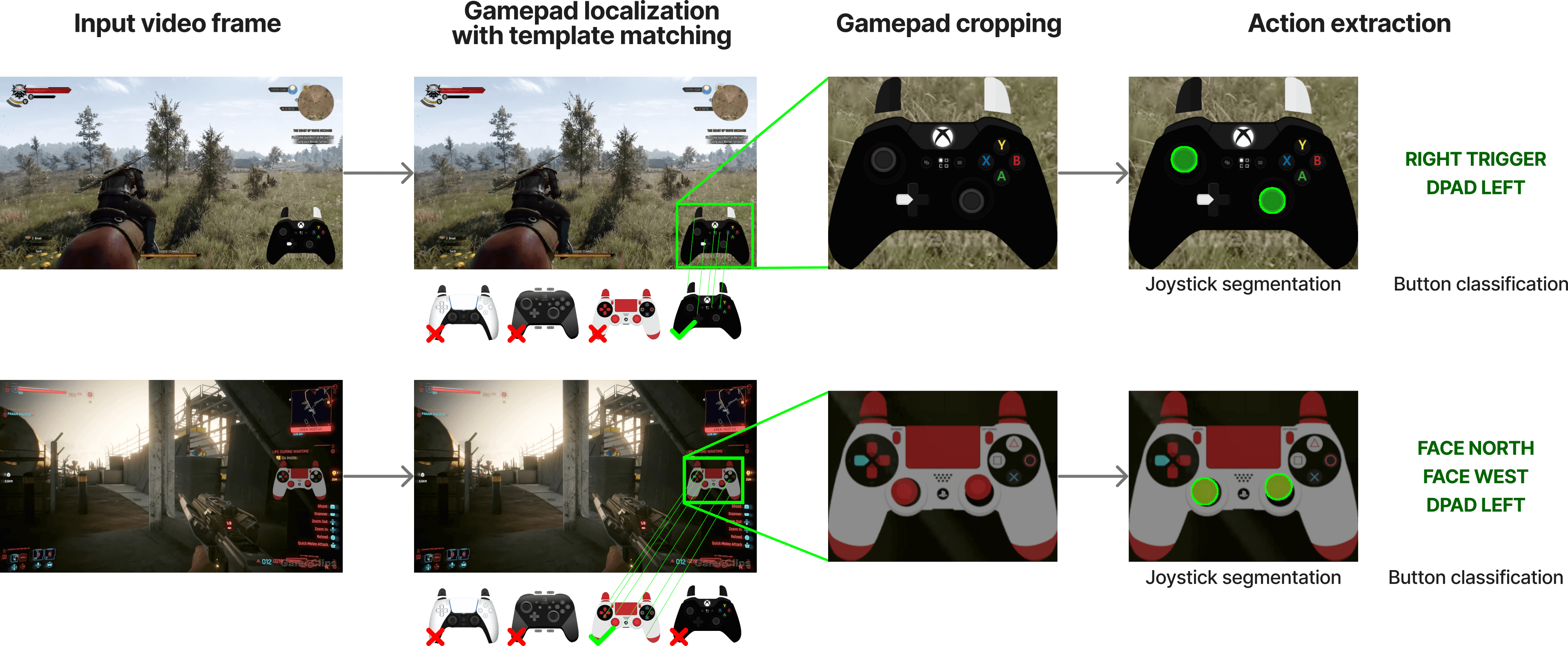
- How they read the inputs:
- First, they find the controller overlay on the screen (like spotting a familiar sticker in different photos).
- Then, they “decode” the overlay to figure out which buttons are pressed and where the joysticks are pointing. They trained a computer vision model to do this, using lots of fake-but-realistic examples to practice.
- Finally, they filter the data so it keeps parts where real actions happen (not just idle scenes). They also hide the overlay in the images so the model can’t “cheat” by looking at it.
- A universal way to control many games
- They built a tool that turns commercial games into a standard interface (think of it like a universal remote). This lets the model send the same kind of button/joystick commands to different games in a consistent way.
- They set a shared action space (16 on/off buttons + 2 joysticks), so the model’s “hands” look the same across all games.
- One unified vision-to-action model trained by imitation
- The model looks at a game frame (a single image from the screen) and predicts a short sequence of controller actions (like planning its next few moves).
- It learns by imitation (also called “behavior cloning”): it watches what humans did and tries to do the same in similar situations—like a beginner learning a sport by watching and copying.
- Under the hood, it uses modern AI techniques to make smooth, consistent action sequences, but you can think of it simply as: “see the screen → output smart controller moves.”
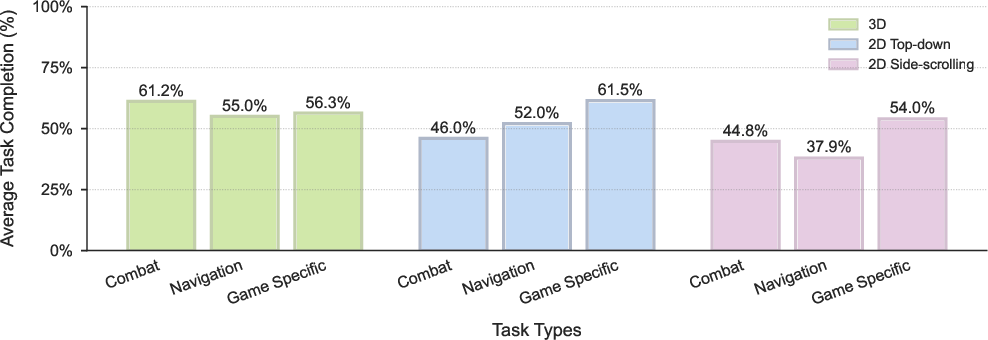
They also built a benchmark (a test suite) with 10 popular games and 30 tasks (combat, navigation, puzzles, platforming, etc.) to measure how well the model generalizes to different challenges.
What did they find, and why does it matter?
Main findings:
- The model can play many kinds of games without being fine-tuned for each one.
- It shows useful skills in 3D action games (combat), 2D platformers (precise movement), and roguelikes (exploration).
- It transfers to new games better than starting from scratch.
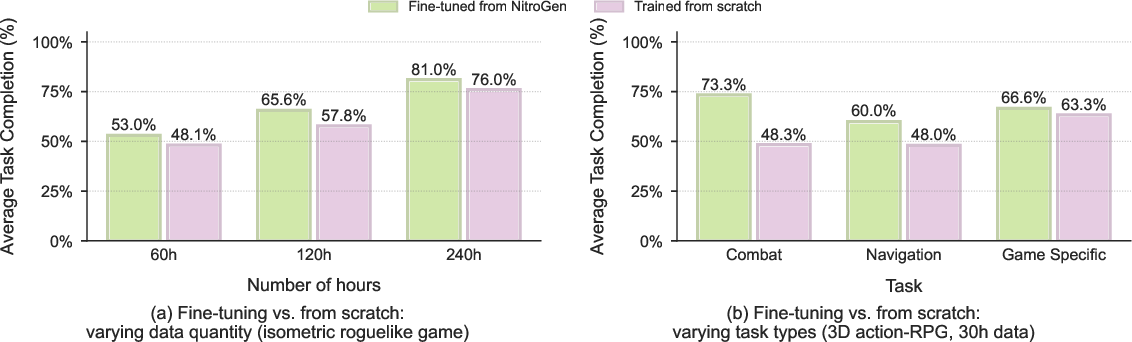
- When they fine-tuned the pre-trained model on a new, unseen game, it did much better—up to a 52% relative improvement in success rates compared to training a fresh model with the same budget.
- The automatic input-reading system is accurate.
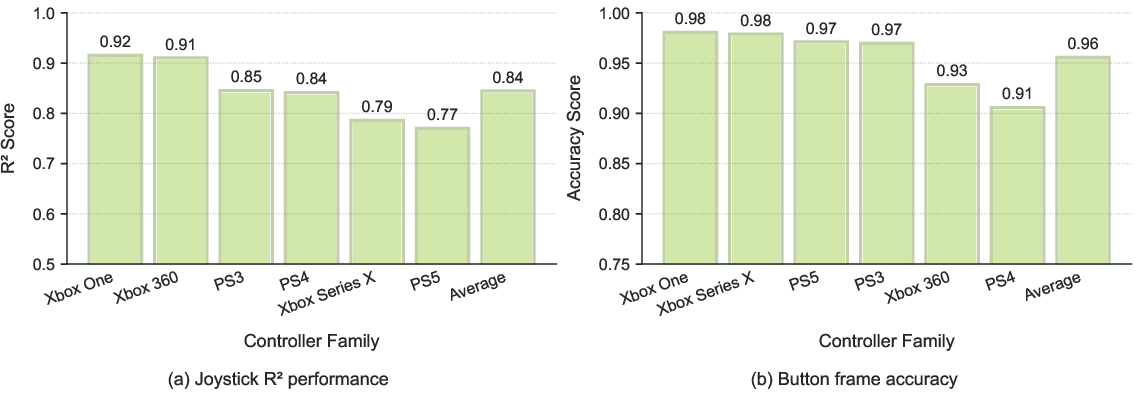
- Button detection was right about 96% of the time, and joystick positions matched human-recorded inputs closely.
Why this matters:
- It shows that “internet-scale imitation” works: you can train a general game-playing model by learning from huge amounts of real player videos, without expensive, hand-made datasets.
- Having a single model that can handle many games is a step toward more flexible, general-purpose AI that can adapt rather than start from zero each time.
What could this change in the future?
- Faster research and development: The team is releasing the dataset, the evaluation tools, and the model weights. This lowers the barrier for others to build and test generalist game agents.
- Better transfer learning: Pre-training on many games teaches reusable skills (like dodging, exploring, aiming), which makes learning new games or tasks quicker.
- Beyond gaming: The core idea—learn from lots of real-world examples with actions—could inspire progress in robotics and other areas where “see-and-do” learning is valuable.
Limitations (and what’s next)
- Short-term reactions only: The model mostly reacts to what it sees right now. It doesn’t plan far ahead or follow written instructions. Future versions could add language understanding and long-term planning.
- Dataset bias: The data mainly comes from gamepad-based action games. It may not generalize as well to strategy games, keyboard-heavy games, or tasks needing complex planning.
- Real-time play: Their simulator steps through games frame-by-frame for training and testing; making everything work perfectly in live, real-time settings is a future challenge.
In short, Nitrogen shows that a single AI can learn to play many different games by watching a massive number of gameplay videos with visible controls. It’s a strong foundation for building more general, adaptable agents that can learn new games and tasks faster.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes concrete gaps and unresolved questions that future work could address:
- Action-label noise characterization: Quantify and model the impact of overlay delays, segmentation inaccuracies (joystick ; buttons ≈0.96), and video artifacts on policy learning and downstream performance, including robustness strategies to mitigate label noise.
- Overlay template coverage: Evaluate failure modes and coverage of the ~300-template SIFT/XFeat matching (e.g., rare/novel overlays, occlusions, transparency, position changes, adaptive layouts), and develop template-free detectors that generalize across unseen overlay styles.
- Per-video localization granularity: Assess drift when localizing overlays only once per video from 25 sampled frames; investigate frame-wise or adaptive re-localization to handle moving/animated overlays or scene changes.
- Controller normalization and calibration: The 99th-percentile joystick normalization and unified 16-button/4-axes action space ignore player-specific sensitivity and custom mappings; study methods to infer or calibrate per-video/controller semantics and sensitivity to ensure consistent action meaning across games.
- Quality filtering bias: Requiring ≥50% non-null action density removes idling, aiming, waiting, and menu navigation periods; quantify how this filtering biases learned behavior and explore balanced sampling strategies that preserve realistic action sparsity.
- Gamepad-only action space: Extend beyond gamepad inputs to keyboard/mouse controls (e.g., RTS, simulation, FPS) and evaluate cross-modality transfer or unified multimodal action spaces.
- Single-frame conditioning: Demonstrate and analyze when single-frame context suffices versus when multi-frame or recurrent memory is required (e.g., partial observability, long-horizon tasks, delayed effects); explore world models or temporal encoders for planning.
- Long-horizon planning and language: Integrate and evaluate planning (e.g., model-based RL, hierarchical controllers) and language conditioning for instruction following, and quantify gains on tasks requiring multi-step reasoning.
- Benchmark breadth and representativeness: Expand beyond 10 games/30 tasks to include strategy, simulation, puzzle/UI-heavy, inventory management, and multi-agent games; study cross-genre generalization and negative transfer.
- Evaluation methodology transparency: Provide absolute success rates, variance, and confidence intervals across seeds; detail human evaluation protocols, inter-rater reliability, and success criteria to ensure reproducibility and statistical rigor.
- Baseline comparisons: Include strong baselines (e.g., VPT, SIMA, GATO, Dreamer, LLM+tool agents, latent-action pretraining) and ablations (architecture, chunk length, diffusion vs autoregressive) to contextualize gains and isolate key design contributors.
- Scaling laws: Systematically study scaling with data hours, number of unique titles, model size, and training compute to establish predictable improvements and guide resource allocation.
- Chunked action generation trade-offs: Analyze the effect of 16-step diffusion sampling (latency, temporal coherence, control smoothness), and optimize for real-time responsiveness in fast-paced games.
- Real-time/asynchronous deployment: The universal simulator relies on pausing and system clock interception; evaluate feasibility, safety, fairness, and physics fidelity in real-time or asynchronous settings, including networked/online games and anti-cheat constraints.
- Physics integrity and portability: Provide broader evidence that frequent pausing/resuming does not alter physics across engines/platforms; characterize overhead, determinism, and compatibility (Windows/macOS/Linux, engines like Unity/Unreal/Custom).
- Observation modalities: Explore adding audio, depth, and on-screen text/OCR to handle games where sonic cues, HUD text, or iconography are essential to decision-making.
- UI/navigation competence: Evaluate and train for UI-heavy tasks (inventory, crafting, dialogue trees, shop interactions) where small UI elements at 256×256 may be unreadable; study resolution requirements and specialized perception.
- Cross-game action semantics: Investigate mechanisms (e.g., meta-learning, explicit mapping layers) to handle varying button meanings across games (A=“jump” vs “attack”), reducing reliance on implicit visual conditioning alone.
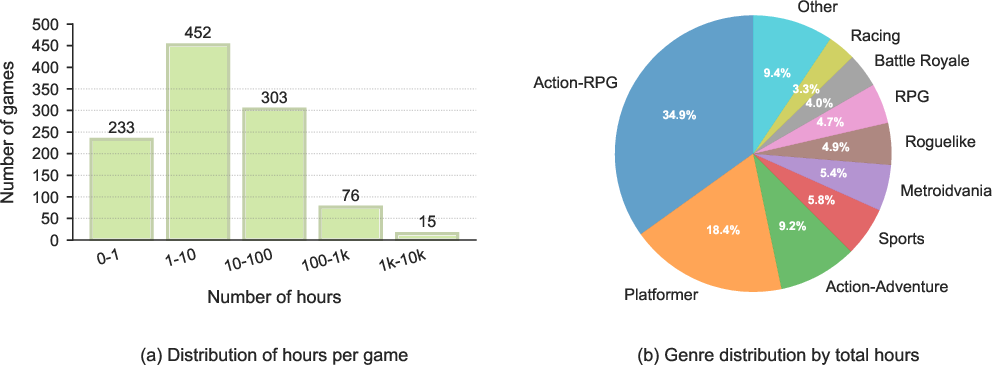
- Distribution shift and representativeness: Quantify how biases toward action/ARPG/platformers affect transfer to underrepresented genres (isometric roguelikes, strategy) and design data balancing or targeted augmentation to mitigate.
- Synthetic annotation domain gap: The SegFormer is trained on synthetic overlays; measure generalization gaps to real overlays and improve realism (e.g., rendering artifacts, motion blur, occlusions, compression) or semi-supervised fine-tuning on real labeled frames.
- Failure analysis and safety cases: Provide systematic analyses of common failure modes (e.g., camera control, targeting, traversal, timing-sensitive combos) and propose safety constraints for actions to avoid undesirable behaviors.
- Robustness to creator artifacts: Study the influence of livestream overlays (chat, alerts, subscriptions, trackers) on perception, and develop artifact suppression or attention gating to focus on task-relevant visual regions.
- Data licensing and consent: Clarify the legal/ethical framework for reusing creator videos (licensing, takedown policies, attribution, PII in chats), and establish best practices for dataset maintenance and compliance.
- Multi-agent dynamics: Extend evaluation to cooperative/competitive multi-agent environments (e.g., MOBAs, team sports) and study social coordination and opponent modeling under vision-only policies.
- Negative transfer and task interference: Assess whether training across many heterogeneous games induces interference; develop curriculum or modularization strategies to limit catastrophic forgetting or task conflicts.
- Controller family generalization: Report performance beyond popular controller families and include less common devices; investigate a unified action representation that covers analog/digital variations consistently.
- Start-state and stochasticity control: Document how task initial states are generated and randomized; provide seeds and protocols so rollouts are comparable, and evaluate generalization under procedural generation with controlled difficulty.
- Fine-tuning strategies: Compare fine-tuning regimes (data sizes, layer freezing, adapters, LoRA, selective replay) and quantify which components benefit most from pretraining across different genres and task types.
- Environment rewards and hybrid training: Explore hybrid BC+RL finetuning on the universal simulator to refine skills and handle sparse/implicit goals, measuring sample efficiency gains.
- Transfer to real-world embodied tasks: Test whether vision-action policies trained on diverse games transfer to robotics or real-world interactive systems, and identify prerequisites (e.g., embodiment gaps, sensor/action remapping).
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can leverage the paper’s released dataset, simulator, and model today, with sector links, potential tools/products, and key dependencies.
- Industry (gaming/software): Automated gameplay QA and regression testing
- Use the universal Gymnasium-based simulator to run scripted smoke tests (navigation, combat, platforming) with the pre-trained policy across builds to detect regressions and edge-case failures.
- Tools/products/workflows: “AI Test Runner” CI service that spins up wrapped titles, executes repeatable scenarios with seeded states, logs failures, and generates video diffs.
- Assumptions/dependencies: Games rely on the system clock for physics; anti-cheat and code integrity protections allow offline automation; publisher permissions for internal testing.
- Industry (gaming/analytics): Action telemetry from public videos for player behavior insights
- Apply the paper’s action-parsing pipeline to creator videos with input overlays to derive high-fidelity button/joystick logs for skill profiling, controller tuning studies, and UX feedback.
- Tools/products/workflows: “ActionLog Extractor” service that ingests YouTube/Twitch archives, exports action sequences, and powers dashboards (e.g., difficulty spikes, input ergonomics).
- Assumptions/dependencies: Legal use of publicly available content; overlay visibility; parsing accuracy (joystick R² ~0.84, button accuracy ~0.96) sufficient for analytics.
- Academia (embodied AI): Baseline and benchmark for generalist control research
- Adopt the multi-game benchmark and open weights to study cross-game generalization, behavior cloning from noisy labels, and transfer learning (demonstrated up to 52% relative improvement).
- Tools/products/workflows: Standardized experimental suite with shared observation/action space; reproducible fine-tuning protocols; leaderboards for multi-game evaluation.
- Assumptions/dependencies: Access to compute for training/fine-tuning; adherence to unified 16+4 action interface.
- Industry (tools vendors/game studios): Rapid fine-tuning for title-specific assistants
- Fine-tune the foundation model on 30–100 hours of target-game overlay data to create agents that can handle tutorial segments, traversal routes, or combat drills.
- Tools/products/workflows: “Game-Specific Assist” model packs distributed as SDKs; in-engine wrappers mapping engine inputs to the standardized action space.
- Assumptions/dependencies: Availability of overlay-labeled data; stability of engine states during frame-stepped control; offline deployment.
- Accessibility (healthcare/assistive tech, gaming): Optional co-pilot for challenging segments
- Provide an opt-in autopilot for single-player tasks (e.g., platforming jumps, navigation through cluttered scenes), with transparency and user control.
- Tools/products/workflows: “Assist Mode” toggles; partial action blending (e.g., aim assist, route following); user safeguard policies.
- Assumptions/dependencies: Offline/local play; publisher support; clear UX for handoff; ethical guidelines to avoid multiplayer/competitive misuse.
- Community (gaming/esports): Practice and coaching aids
- Generate “ghost runs” and reproducible scenario agents to help players practice boss fights or precision platforming; derive action timelines from creator content for coaching insights.
- Tools/products/workflows: Segment replay bots; action timeline overlays; skill gap analytics.
- Assumptions/dependencies: Title support for reproducible seeds/checkpoints; local sandbox mode.
- Media/software: Automated b-roll and scene traversal capture
- Use the agent to collect footage (e.g., reach scenic locations, execute camera-friendly routes) for trailers or social content.
- Tools/products/workflows: “Cinematic Capture Bot” with route presets; scheduler for batch capture.
- Assumptions/dependencies: Publisher permission for automation; determinism for repeatable shots.
- Education: Curriculum materials for embodied AI and vision-action learning
- Leverage the open dataset and simulator in courses on behavior cloning, action parsing, and generalization.
- Tools/products/workflows: Lab assignments, starter notebooks, and grading scripts that use the benchmark API.
- Assumptions/dependencies: Compute access; platform support for the simulator.
- Policy (governance/ethics): Immediate guidance for dataset use and deployment
- Draft internal/external policies on fair use of public videos, opt-out mechanisms, disclosure, and anti-cheat compliance for any agent deployment.
- Tools/products/workflows: “Responsible Use Checklist” covering licensing, content provenance, and offline-only constraints.
- Assumptions/dependencies: Legal counsel; publisher collaboration; clear user-facing disclosures.
Long-Term Applications
These use cases require further research, integration, or scaling—often combining the paper’s foundation with language, planning, or broader platform support.
- Software/gaming: Language-driven Gameplay Copilot
- Combine the reactive vision–action model with language/planning modules to follow quest instructions, multi-step goals, and player voice commands.
- Tools/products/workflows: VLA integration (LLM + vision encoder + action head); long-horizon task decomposition; safe-intervention policies.
- Assumptions/dependencies: Robust language grounding; temporal planning beyond system-1 behavior; publisher approvals.
- Gaming/analytics: Dynamic difficulty and personalized assistance
- Real-time adaptation to player skill, offering tailored hints or partial autonomy; continuous monitoring of player fatigue and frustration signals.
- Tools/products/workflows: On-device skill estimators; adaptive action blending; fairness and user consent frameworks.
- Assumptions/dependencies: Real-time inference; latency budgets; user trust and privacy safeguards.
- Software/accessibility: General computer control agents via overlay-style labeling
- Extend the overlay-labeling approach to keyboard/mouse/GUI events to train general desktop automation agents for accessibility and productivity.
- Tools/products/workflows: UI action capture and standardization layers; task libraries (e.g., form filling, file management).
- Assumptions/dependencies: Reliable UI event labeling; diverse app coverage; robust evaluation for safety and correctness.
- Robotics: Transfer of scalable behavior-cloning pipelines to teleoperation data
- Apply the internet-scale labeling and unified action-space ideas to robot teleop videos; train VLA models for manipulation and navigation.
- Tools/products/workflows: Multi-robot action schema unification; sim-to-real adaptation; safety-certified deployment.
- Assumptions/dependencies: High-quality teleop labels; domain gap mitigation; hardware variability.
- Gaming (esports/training): Sparring bots and scenario generators
- Title-specific agents for training and skill drills, with configurable behaviors and difficulty curves.
- Tools/products/workflows: Scenario authoring tools; behavior parameterization; anti-cheat-compatible training modes (publisher-backed).
- Assumptions/dependencies: Publisher partnerships; sandbox environments; fairness considerations.
- Game design/production: Autonomous NPC prototyping and behavior authoring
- Use the foundation to bootstrap context-aware NPC behaviors, reducing manual scripting; designers refine via high-level constraints.
- Tools/products/workflows: Designer-in-the-loop behavior editors; policy distillation tools for run-time efficiency.
- Assumptions/dependencies: Real-time inference optimization; interpretability and controllability of learned behaviors.
- DevOps (gaming/software): Cloud-scale testing farms for multi-platform builds
- Distributed agents running cross-platform (PC/console) to automate pre-release checks, performance regressions, and content gatekeeping.
- Tools/products/workflows: Cloud orchestration of wrapped titles; cross-build comparison metrics; failure triage pipelines.
- Assumptions/dependencies: Platform hooks on consoles; publisher/patform-holder approval; cost-effective scaling.
- Media platforms: Action-aware video experiences
- Enrich replays with synchronized action timelines; interactive learning clips (e.g., “show me the exact inputs at timestamp”).
- Tools/products/workflows: Video+action metadata pipelines; creator tools for teaching; monetization via premium analytics.
- Assumptions/dependencies: Widespread adoption of overlays or alternative input capture; licensing agreements.
- Policy/regulatory: Standards for public video training, disclosures, and opt-outs
- Establish sector-wide norms on data provenance, consent, watermarking, and transparent model reporting.
- Tools/products/workflows: Certification programs; auditing tools; data lineage registries.
- Assumptions/dependencies: Multi-stakeholder coordination; legal frameworks; international harmonization.
Cross-cutting assumptions and dependencies
- Legal and publisher constraints: Many applications require permissions, anti-cheat compliance, and offline-only deployment.
- Technical constraints: The universal simulator’s frame-stepping relies on system clock interception; real-time/asynchronous control and console integration are nontrivial.
- Data biases: The dataset is gamepad-heavy and action-game–skewed; transfer to strategy/simulation genres or keyboard-based titles may require new data.
- Model capabilities: Current model is reactive (system-1), single-frame conditioned; long-horizon planning and language-following need additional modules and training.
- Compute and optimization: Real-time inference and large-scale fine-tuning depend on hardware budgets and model compression/distillation.
Glossary
- AdamW optimizer: A variant of Adam that decouples weight decay from gradient updates to improve generalization. "using the AdamW optimizer~\citep{adam_optimizer, loshchilov2017decoupled}"
- Action density: The proportion of timesteps with non-zero actions, used to filter out low-signal data segments. "we discard segments based on action density: we only keep chunks where at least 50\% of the timesteps have non-zero button or joystick actions"
- Action head: The output layer of a model responsible for predicting action vectors. "with the language and state encoders removed, and a single action head."
- Affine transformation: A geometric mapping (including translation, rotation, scaling, shear) used to align images based on matched keypoints. "We estimate an affine transformation from the paired keypoints"
- Behavior cloning: Supervised imitation learning that maps observations to expert actions directly from demonstrations. "a unified vision-action model trained with large-scale behavior cloning."
- Cross-attention: An attention mechanism that conditions one sequence (e.g., actions) on another (e.g., image tokens). "DiT blocks consisting of alternating self-attention and cross-attention layers."
- Cross-game generalization: The ability of an agent to transfer skills across different games without game-specific retraining. "a multi-game benchmark environment that can measure cross-game generalization"
- Denoising process: The iterative procedure used at inference in diffusion/flow models to convert noise into structured outputs. "Inference follows the corresponding denoising process with steps."
- Diffusion transformer (DiT): A transformer-based architecture tailored for diffusion-style generative modeling. "Actions are generated with a diffusion transformer (DiT) \citep{peebles2023scalable}"
- Exponential moving average (EMA): A running average of parameters that weights recent values more heavily to stabilize training. "we maintain an exponential moving average (EMA) of model weights during training with a decay of $0.9999$."
- Gymnasium API: A standardized interface for reinforcement learning environments enabling uniform control and observation. "allows any commercial game to be controlled through a Gymnasium API"
- Input overlay: On-screen visualization that displays controller inputs in real time during gameplay recordings. "called ``input overlays''."
- Inverse dynamics: Inferring the actions that caused observed state transitions, often used to label actions from videos. "VPT \citep{baker2022video} annotates 70,000 hours via inverse dynamics but is limited to Minecraft."
- Isometric roguelike: A game genre with isometric perspective and procedural content, often featuring permadeath and randomized runs. "an isometric roguelike"
- Keypoint matching: Matching distinctive feature points across images to localize or align structures. "running keypoint matching against a curated set of templates using SIFT and XFeat features."
- Multi-Layer Perceptron (MLP): A feedforward neural network consisting of multiple fully connected layers. "Noisy action chunks are first encoded by an MLP into one action token per timestep"
- Procedural generation: Algorithmic creation of content (levels, worlds) rather than manual design, producing varied instances. "procedurally generated worlds."
- R2 score: The coefficient of determination used to quantify how well predicted values approximate true values. "We measure joystick accuracy with the score"
- SegFormer: A transformer-based model for semantic segmentation noted for simplicity and efficiency. "We parse controller states using a fine-tuned SegFormer~\citep{Xie2021SegFormerSA} segmentation model"
- Segmentation mask: A pixel-wise label map indicating regions of interest, used here to localize joystick positions. "It outputs a segmentation mask to localize joystick positions"
- Self-attention: An attention mechanism enabling a model to relate elements within the same sequence to capture dependencies. "DiT blocks consisting of alternating self-attention and cross-attention layers."
- SIFT: Scale-Invariant Feature Transform; a classic algorithm for detecting and describing image keypoints. "perform feature matching with SIFT~\citep{sift_lowe2004distinctive} and XFeat"
- SigLIP 2: A multilingual vision-language encoder with improved localization and dense features, used here as a vision backbone. "encoded using a SigLIP 2 vision transformer \citep{tschannen2025siglip}"
- Template matching: Locating regions in an image that best match a given template via similarity measures and feature matches. "we apply template matching using a curated set of approximately 300 common controller templates."
- Teleoperation: Remote human control of robots to collect demonstration data for imitation learning. "In robotics, teleoperation has produced datasets such as Roboturk"
- Universal simulator: An environment wrapper that standardizes control and timing for arbitrary titles via a shared API. "we develop a universal simulator that can wrap any game title with a Gymnasium API for model development."
- Vision-Language-Action (VLA) models: End-to-end policies that take visual and language inputs and output actions for embodied tasks. "Vision-Language-Action (VLA) models \citep{bjorck2025gr00t, kim2024openvla, black2024pi0, brohan2022rt, cheang2024gr, wen2025tinyvla, team2024octo}"
- Vision transformer: A transformer architecture applied to image patches for visual representation learning. "SigLIP 2 vision transformer"
- Vision–action model: A model that maps visual observations directly to action outputs without explicit language or state inputs. "a unified vision-action model trained with large-scale behavior cloning."
- Warmup-stable-decay (WSD) schedule: A learning rate schedule with an initial warmup, a stable phase, and a subsequent decay. "We use a warmup-stable-decay (WSD) schedule \citep{wen2024understanding}"
- Weight decay: Regularization that penalizes large parameter values during optimization to reduce overfitting. "weight decay of $0.001$."
- XFeat features: Lightweight, accelerated feature descriptors for efficient image matching. "perform feature matching with SIFT~\citep{sift_lowe2004distinctive} and XFeat~\citep{potje2024xfeat}"
- Zero-shot gameplay: Executing competent play in a game without any fine-tuning or additional training on that title. "enabling zero-shot gameplay across multiple titles"
- Zero-shot generalization: Succeeding on tasks not seen during training without extra adaptation. "tasks that require zero-shot generalization."
Collections
Sign up for free to add this paper to one or more collections.