AI-exposed jobs deteriorated before ChatGPT
Abstract: Public debate links worsening job prospects for AI-exposed occupations to the release of ChatGPT in late 2022. Using monthly U.S. unemployment insurance records, we measure occupation- and location-specific unemployment risk and find that risk rose in AI-exposed occupations beginning in early 2022, months before ChatGPT. Analyzing millions of LinkedIn profiles, we show that graduate cohorts from 2021 onward entered AI-exposed jobs at lower rates than earlier cohorts, with gaps opening before late 2022. Finally, from millions of university syllabi, we find that graduates taking more AI-exposed curricula had higher first-job pay and shorter job searches after ChatGPT. Together, these results point to forces pre-dating generative AI and to the ongoing value of LLM-relevant education.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how jobs that are strongly affected by AI tools (like ChatGPT) were changing in the U.S. job market. Many people think that problems for these jobs started because ChatGPT came out in late 2022. The authors test that idea and show that the job market for AI-exposed jobs was already getting worse months before ChatGPT. They also find that learning AI-related skills in college still helps students get better jobs after ChatGPT.
What questions did the researchers ask?
They focused on three simple questions:
- Did unemployment (losing jobs or needing unemployment benefits) rise for AI-exposed occupations only after ChatGPT, or earlier?
- Did recent college graduates start AI-exposed jobs less often, and did that change happen before or after ChatGPT?
- Do students who learned more AI-related skills in college do better (get paid more, find jobs faster) after ChatGPT?
How did they study it?
The researchers combined three large sources of data and kept the ideas simple:
- Unemployment records: They used monthly U.S. unemployment insurance data to see, for each occupation and state, the chance that workers in that occupation were on unemployment. Think of “unemployment risk” as a scoreboard showing how likely people in a specific job are to be receiving unemployment benefits at any given time.
- LinkedIn profiles: They analyzed millions of online resumes to track what jobs recent graduates got, how long it took them to find their first job, and estimated salaries. They looked at graduation “cohorts” (like the Class of 2021, 2022, 2023) to see patterns over time.
- University syllabi: They read millions of course syllabi to estimate how much different college programs taught skills related to AI-affected tasks (like writing, coding, and information gathering). They matched this to graduates’ first jobs to see if learning these skills helped after ChatGPT.
They also used a simple idea of “AI exposure”: If a job involves many tasks that LLMs could help with—such as drafting text, analyzing information, or writing code—then that job is considered highly exposed to AI. They grouped jobs by how exposed they are to AI to compare trends across time.
What did they find?
Here are the main results and why they matter:
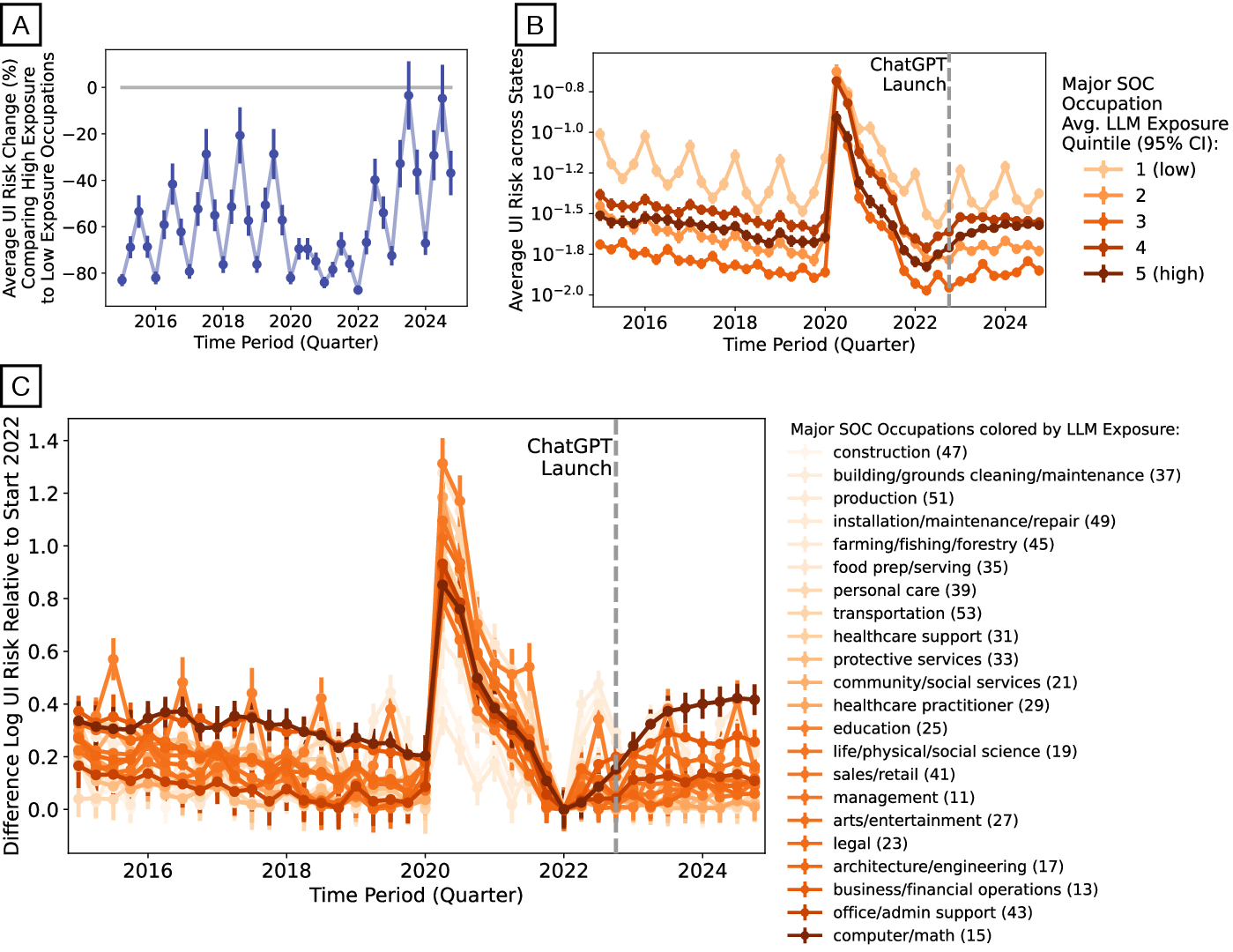
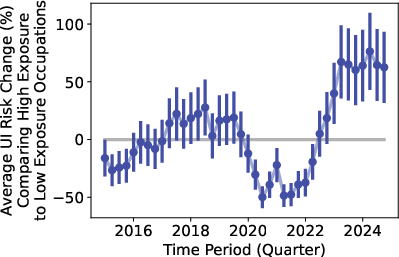
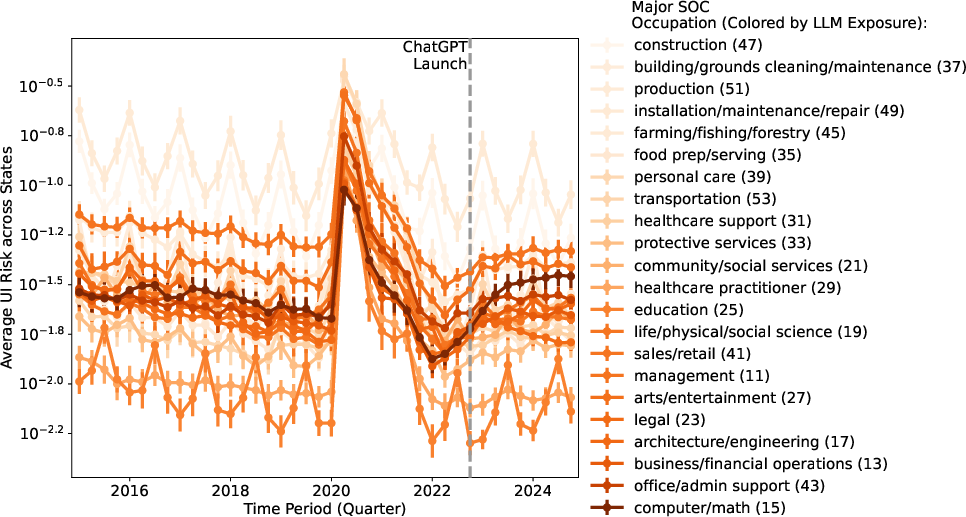
- Unemployment risk rose before ChatGPT: For jobs highly exposed to AI (like computer and math roles), the chance of being on unemployment began to increase in early 2022—months before ChatGPT launched. After ChatGPT, the rise generally flattened rather than getting much worse. This suggests other forces (like changes in the economy or a cooldown after a tech hiring boom) were already affecting these jobs.
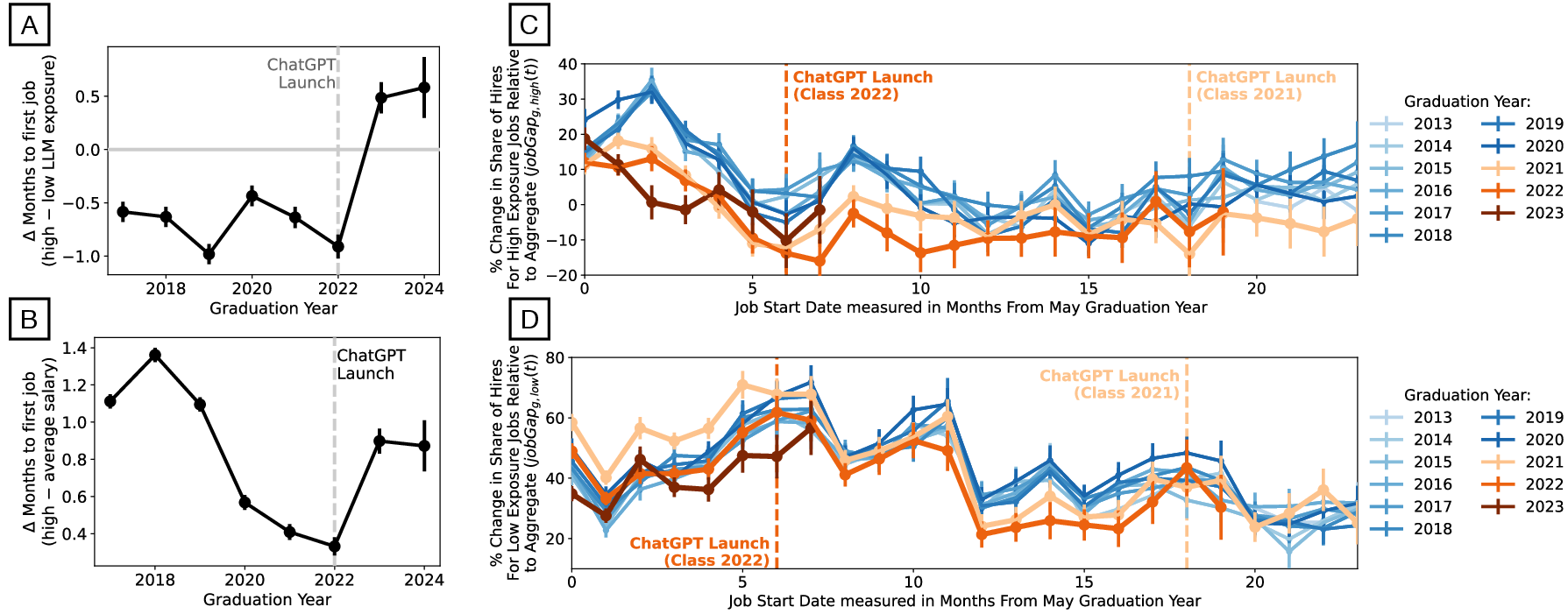
- Recent graduates faced tougher markets early: Graduates from 2021 and 2022 entered AI-exposed jobs at lower rates than earlier classes, and the drop started before late 2022. Graduates in 2023 also had longer delays to their first job. This means the job market became harder for early-career workers, not just because of ChatGPT.
- Learning AI-related skills helped after ChatGPT: Students whose college programs taught more AI-related tasks tended to get higher starting salaries and find jobs faster in the period after ChatGPT. This was especially true in jobs that are more AI-exposed. So, teaching skills like writing, coding, and information synthesis still pays off—even in an AI-heavy world.
- Not just AI: While some places (like California and Washington) did see increases after ChatGPT in certain occupations, the national patterns point to broader economic changes already underway in 2022, not a sudden shift caused only by ChatGPT.
Why does this matter?
- Don’t blame everything on ChatGPT: If we assume the job problems started only because of AI, we might miss other important causes, like interest rate changes, sector slowdowns (for example, fewer software job postings), or post-pandemic adjustments.
- Keep teaching AI-exposed skills: Instead of avoiding skills that AI can also do, colleges and training programs should teach them in smarter ways—like focusing on checking AI outputs, critical thinking, problem framing, and collaborating effectively with AI tools. These skills seem to help graduates succeed.
- Better research and policy: Policymakers and researchers should be careful using the November 2022 launch of ChatGPT as a “before vs. after” line. The job market was already shifting earlier. Future studies should combine direct measures of AI use with worker–firm data to see who benefits, who struggles, and why.
Bottom line
Jobs deeply connected to AI tasks started facing more risk before ChatGPT arrived, likely due to broader economic changes. Even so, learning AI-related skills still helps young workers in the post-ChatGPT world. Instead of dropping these skills, schools and training programs should teach them alongside how to use AI wisely.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Causal identification is absent: the paper does not quantify the relative contributions of LLM diffusion vs. concurrent macroeconomic forces (e.g., monetary tightening, sectoral demand shifts, post-pandemic corrections) to observed labor-market deterioration in 2022–2024.
- Adoption timing is proxied by ChatGPT’s launch: there is no occupation-, firm-, or region-specific timeline of LLM adoption (e.g., Copilot, internal LLMs), risking misattribution of effects; a granular diffusion map is needed.
- Unemployment risk measure scope: ETA 203 focuses on continuing UI claimants and last major occupation group, potentially excluding new entrants and early-career graduates; outcomes for those ineligible for UI or without prior occupations remain unmeasured.
- Occupational granularity mismatch: unemployment analyses use major SOC groups for risk but LLM exposure is defined at six-digit SOC; the impact of aggregation/misclassification on risk estimates is not quantified.
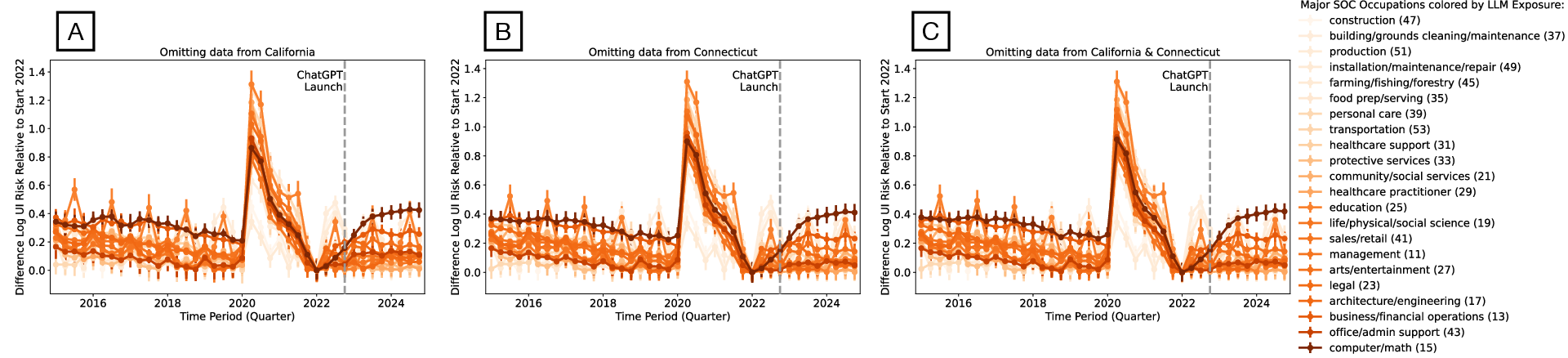
- State-level data quality and anomalies: the Connecticut-driven spike for administrative support indicates sensitivity to state reporting; systematic data quality audits and robustness across states are needed.
- LinkedIn sample representativeness: reliance on platform users introduces selection biases (e.g., differential platform use by major, school rank, visa status, gender, race); representativeness vs. the full graduate population is not fully validated.
- Salary measurement uncertainty: first-job salaries are model-based and unverified; administrative wage data (e.g., W-2/LEHD) are needed to validate magnitudes and distributional impacts.
- Job search duration measurement bias: months-to-first-job depends on user profile update behavior and excludes those whose first observed job starts >3 years post-graduation; right-censoring and nonresponse biases are not corrected.
- Educational exposure proxy limitations: syllabi-derived exposure uses pre-2020 course documents and averages at the program level; it cannot capture post-ChatGPT curricular changes, student-level course-taking heterogeneity, or actual skill acquisition and LLM literacy.
- Mechanisms behind educational exposure benefits: the paper does not disentangle whether gains reflect skill complementarity, signaling, institutional quality, networks, or selection; within-program variation and causal tests are needed.
- Task-based exposure validity: LLM exposure relies on O*NET task mappings (Eloundou et al.) with “simple interfaces and general training”; actual enterprise LLM capabilities, fine-tuning, and evolving task automation costs are not measured.
- Enterprise adoption heterogeneity: differences by firm size, sector, organizational practices, and AI maturity (pilot vs. scaled use) are not analyzed; firm-level adoption telemetry and HR data could resolve impacts.
- Seniority bias and career ladder effects: whether LLMs disproportionately reduce entry-level hiring or reconfigure junior tasks (vs. senior roles) is not directly tested, despite suggestive evidence; junior-senior task reallocation should be measured.
- Persistence of effects: outcomes are tracked only to first jobs within three years; long-run trajectories (wage growth, promotions, occupation switches, unemployment spells) and persistence vs. transience of post-2022 impacts are unknown.
- Regional heterogeneity drivers: states like CA, WA, AK show post-launch increases in risk for computer/math occupations; the local drivers (industry mix, firm adoption, policy, cost of capital) remain unexplored.
- Cross-country generalizability: findings are U.S.-specific; whether similar timing patterns and education complementarities hold internationally is untested.
- Dose–response thresholds: exposure quintiles show deterioration beginning early 2022, but non-linear thresholds (i.e., exposure levels where risk sharply increases) are not estimated.
- Posted vs. realized labor demand: declines in job postings (e.g., software developers) are noted but not linked causally to realized hiring outcomes and unemployment risk at the occupation–region level.
- Alternative confounders: return-to-office policies, remote-work retrenchment, and sectoral rebalancing in tech are plausible mechanisms; their distinct contributions are not decomposed.
- Occupation–task dynamics: changes in task bundles within occupations post-LLM (e.g., redesign toward verification, evaluation, orchestration) are not measured; dynamic task-shares would clarify displacement vs. augmentation.
- Demographic and equity impacts: distributional effects by gender, race/ethnicity, visa status, socioeconomic background, and institution selectivity are not analyzed; potential widening of inequalities is an open question.
- Mobility and transitions: flows between LLM-exposed and less-exposed occupations, barriers to switching, and the role of transferable skills are not examined with transition data.
- Entrepreneurship and non-traditional work: impacts on self-employment, freelancing, and gig work among graduates in exposed fields are not assessed.
- Alternative identification strategies: no natural experiments, instruments, or firm-level event studies are used (e.g., staggered adoption, vendor rollouts, policy shocks) to isolate LLM impacts.
- Validation with additional data sources: results are not triangulated with CPS microdata, NSCG/NACE first-destination surveys, firm HRIS/ATS data, or UI micro-records to corroborate timing and magnitudes.
- Curriculum design specifics: which LLM-complementary skills (e.g., verification, prompt engineering, critical evaluation, data provenance) drive the observed post-ChatGPT benefits are not identified; course-level interventions and RCTs are needed.
- Exposure measure evolution: the static exposure index may lag rapid capability changes; continuous updating of exposure scores and inclusion of non-LLM AI (e.g., computer vision, automation platforms) are needed.
- Robustness to seasonality and normalization choices: core unemployment results depend on trough normalization (2022Q1) and seasonal patterns; alternative seasonal adjustments and baselines could affect inference.
- Occupation coding accuracy: mapping LinkedIn titles to six-digit SOC is error-prone; misclassification rates and their effect on exposure and outcome estimates are not quantified.
Practical Applications
Below we translate the paper’s main findings and methods into concrete, real-world applications. We group them by deployment horizon and, for each, note sectors, potential tools/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
The following can be piloted or deployed now using existing data, capabilities, and organizational processes:
- AI-Exposed Occupation Risk Index and Dashboard
- Sector: software, HR tech, finance, public sector
- What: Build an occupation-location “unemployment risk” tracker using ETA-203 + OEWS and LLM-exposure scores to provide early warnings for staffing, workforce planning, and portfolio risk (e.g., for HR, insurers, investors).
- Tools/Workflows: Automated data ingestion (ETA-203, OEWS), SOC/O*NET mapping, exposure quintile views, alerts on rising risk in SOC 15 and SOC 43, state-level drilldowns (e.g., CA, WA, AK).
- Assumptions/Dependencies: Reliable state UI reporting (ETA-203), stable SOC crosswalks, Eloundou et al. LLM-exposure taxonomy; interpretational caution due to non-causal design and state idiosyncrasies (e.g., CT).
- Recruiting and Early-Career Hiring Adjustments in LLM-Exposed Roles
- Sector: software, professional services, tech-enabled industries
- What: Extend recruiting timelines, create bridge programs (apprenticeships, residencies), and reduce screening frictions for 2021–2024 cohorts entering exposed roles facing longer search times.
- Tools/Workflows: Cohort-specific hiring funnels, structured work-samples emphasizing human–LLM collaboration, mentorship allocations targeting first 12 months.
- Assumptions/Dependencies: Access to cohort-level applicant data; willingness to shift hiring calendars and criteria.
- Upskilling Programs that Emphasize AI-Complementary Skills (do not abandon writing/coding)
- Sector: corporate L&D, bootcamps, professional education
- What: Offer short courses that pair core “AI-exposed” skills (writing, coding, information synthesis) with verification, evaluation, prompt design, and human–LLM collaboration protocols.
- Tools/Workflows: Micro-credentials (e.g., “LLM Collaboration Foundations”), scenario-based labs (fact-checking, code review with LLMs), capstones that measure complementarity rather than automation.
- Assumptions/Dependencies: Training efficacy depends on task mix; outcomes vary by role seniority; results in the paper are associative, not causal.
- Curriculum Exposure Analyzer for Universities
- Sector: higher education, edtech
- What: Audit programs’ syllabi against LLM-exposed tasks to quantify “education exposure” and identify gaps or opportunities to add AI-complementary pedagogy.
- Tools/Workflows: Syllabus parsing (Course-Skill Atlas methods), mapping to O*NET tasks and LLM-exposure indices, program-level dashboards, curriculum committees’ action plans.
- Assumptions/Dependencies: Access to syllabi; robust CIP–course–task linkages; the paper’s syllabi are pre-2020 (baseline emphasis) and may not capture post-ChatGPT updates.
- Career Services Playbook for Exposed Occupations
- Sector: higher education, workforce boards
- What: Prepare students for longer job searches in LLM-exposed paths with earlier outreach, targeted employer pipelines, and showcasing LLM-collaboration projects in portfolios.
- Tools/Workflows: “Job-gap” monitoring by cohort and exposure decile, employer days focused on AI-collaborative workflows, alumni mentorship for the first 6–12 months post-graduation.
- Assumptions/Dependencies: Institutional access to student outcomes data; LinkedIn/NSCG weighting shows representativeness matters.
- State and Local Labor Market Monitoring and Rapid Response
- Sector: policy, workforce development
- What: Incorporate occupation-location unemployment risk into rapid response and retraining allocations; watch for pre-inflection changes (as in early 2022) rather than anchoring to product launch dates.
- Tools/Workflows: Quarterly risk briefs for governors and WIBs, targeted training vouchers for rising-risk SOCs, coordination with UI trust fund management.
- Assumptions/Dependencies: Timeliness of administrative data; governance for resource targeting.
- Compensation Benchmarks and Offer Design in Exposed Jobs
- Sector: industry HR/compensation analytics
- What: Recalibrate salary expectations considering post-ChatGPT softening in exposed roles while recognizing higher salaries for candidates with strong education exposure.
- Tools/Workflows: Comp models that include LLM exposure and education exposure interactions; retention bonuses tied to AI-complementary upskilling milestones.
- Assumptions/Dependencies: Revelio salary estimates are model-based; firm- and location-specific variation is large.
- Vendor Products for Talent Analytics
- Sector: HR tech, data vendors
- What: Commercialize a “Cohort Job-Gap Tracker” and an “Education Exposure Score” for candidate ranking and workforce risk assessment.
- Tools/Workflows: API endpoints with SOC exposure deciles, cohort job-gap curves, and syllabus-based exposure features; integrations with ATS/HRIS.
- Assumptions/Dependencies: Data licensing (LinkedIn/Revelio), privacy compliance (FERPA/GDPR/CCPA), continuous model calibration.
- Evidence Standards for Researchers and Analysts
- Sector: academia, think tanks, policy analysis
- What: Avoid treating ChatGPT’s launch as a clean natural experiment; include pre-2022 trends and macro controls when attributing labor-market changes to AI.
- Tools/Workflows: Pre-trend checks, state-by-industry fixed effects, inclusion of monetary tightening proxies; robustness to sectoral demand shifts.
- Assumptions/Dependencies: Availability of macro/sectoral covariates; transparency in exposure measures.
- Individual Career Planning
- Sector: daily life, lifelong learning
- What: Students and early-career workers prioritize coursework and projects that blend writing/coding with AI collaboration, verification, and synthesis rather than withdrawing from these domains.
- Tools/Workflows: Personal “AI-complementary skills” portfolios; budgeting extra time for job search in exposed fields; targeting firms/regions with better near-term absorption.
- Assumptions/Dependencies: Individual access to AI tools and mentors; local labor conditions.
Long-Term Applications
These require further research, scaling, data infrastructure, or institutional change:
- National AI Labor Observatory
- Sector: policy, academia, public–private partnerships
- What: Integrate UI administrative records, job postings, firm-level AI adoption logs, and linked worker–firm data to distinguish AI effects from macro shocks and to map exposure dynamically.
- Tools/Workflows: Secure data enclaves, standardized AI adoption reporting, longitudinal worker–firm panels, exposure recalibration pipelines.
- Assumptions/Dependencies: Data-sharing agreements, privacy-preserving linkage, federal/state funding, standardized AI adoption metrics.
- Policy Simulation and Early-Career Safety Nets
- Sector: policy
- What: Build models that stress-test monetary policy shocks vs. AI adoption shocks on occupation-specific unemployment risk; design responsive instruments (e.g., wage insurance, accelerated apprenticeships) for exposed graduates.
- Tools/Workflows: Structural and semi-structural models calibrated on the paper’s timing evidence; policy triggers tied to risk thresholds.
- Assumptions/Dependencies: Causal identification remains challenging; political feasibility and fiscal resources.
- Standards for Measuring AI Adoption and Exposure
- Sector: policy, industry consortia, standards bodies
- What: Establish reporting standards for firm-level AI usage and task exposure, complementing O*NET with dynamic, task-level cost-effectiveness measures.
- Tools/Workflows: Sector-specific templates for AI-in-use reporting; third-party audits; open taxonomies linking tasks to tools.
- Assumptions/Dependencies: Industry participation; confidentiality protections; evolving technology landscape.
- Credentialing and Assessment of Human–LLM Collaboration
- Sector: education, professional certification
- What: Create validated credentials assessing verification, evaluation, oversight, and handoff in AI-assisted work, recognized by employers across exposed occupations.
- Tools/Workflows: Performance-based exams, standardized simulated LLM tasks with adversarial errors, longitudinal validation with labor-market outcomes.
- Assumptions/Dependencies: Psychometric rigor; employer buy-in; updating content as models evolve.
- LMS-Integrated Syllabus-to-Task Alignment
- Sector: edtech
- What: Embed automated syllabus analytics into learning management systems to continuously align course content with evolving LLM-exposed tasks and AI-complementary competencies.
- Tools/Workflows: NLP pipelines for syllabi, O*NET/task mapping, instructor dashboards suggesting module updates, A/B tests on student outcomes.
- Assumptions/Dependencies: Access to course materials; faculty adoption; governance for curricular changes.
- Regional Economic Development Strategies Based on Exposure Maps
- Sector: policy, economic development
- What: Use exposure-by-occupation-by-region to guide cluster strategies, target reskilling, and anticipate fiscal impacts on UI funds and tax bases.
- Tools/Workflows: Exposure heatmaps layered with firm AI adoption; incentives for AI-complementary training providers; regional apprenticeship consortia.
- Assumptions/Dependencies: Accurate regional labor flows; coordination among employers, colleges, and WIBs.
- UI Program Modernization for Richer Labor Intelligence
- Sector: policy, public administration
- What: Enhance UI intake to capture finer-grained occupation, skill, and technology-use information; harmonize across states to improve timeliness and comparability.
- Tools/Workflows: Updated reporting standards, digital forms with SOC-6 and skill tags, automated validation against O*NET.
- Assumptions/Dependencies: Legislative updates; IT modernization budgets; burden on claimants.
- Causal Research Infrastructure Linking AI Tool Adoption to Worker Outcomes
- Sector: academia, industry research partnerships
- What: Combine firm telemetry (AI tool logs) with HRIS and earnings to identify displacement vs. productivity channels, seniority effects, and heterogeneity across tasks.
- Tools/Workflows: Differential rollout designs, event studies with granular adoption timestamps, secure multiparty computation for privacy.
- Assumptions/Dependencies: Willingness of firms to share logs; IRB and privacy protections; interoperable data schemas.
- International Comparatives and Crosswalks
- Sector: academia, policy
- What: Extend exposure, risk, and education-exposure measures to other countries’ occupation and education taxonomies to inform global policy.
- Tools/Workflows: SOC–ISCO and CIP–ISCED crosswalks; harmonized UI and postings data; multilingual syllabus parsing.
- Assumptions/Dependencies: Data availability; differences in UI systems and adoption timelines.
- Trigger-Based Training Tax Credits and Wage Subsidies
- Sector: policy
- What: Implement automatic stabilizers that activate tax credits or subsidies when an occupation-location risk index crosses thresholds, prioritizing AI-complementary training.
- Tools/Workflows: Statutory triggers tied to published indices; accredited provider lists; outcome-based funding.
- Assumptions/Dependencies: Legal frameworks; safeguarding against gaming; index robustness and transparency.
Notes on overarching assumptions:
- Exposure measures (e.g., Eloundou et al.) capture task susceptibility but not adoption pace or cost-effectiveness; they should be updated regularly.
- LinkedIn/Revelio data introduce selection and measurement error; weighting and validation against official statistics mitigate but do not eliminate bias.
- The paper’s results are observational and emphasize timing; applications that assume causality should incorporate additional identification strategies.
- Macro shocks (e.g., monetary tightening) interact with AI diffusion; monitoring must model both to avoid misattribution.
Glossary
- AI-exposed occupations: Jobs whose tasks are particularly susceptible to automation or augmentation by AI systems. "Public debate links worsening job prospects for AI-exposed occupations to the release of ChatGPT in late 2022."
- Bureau of Labor Statistics (BLS): The U.S. federal agency that collects and disseminates labor market data. "share of its workplace tasks in the Bureau of Labor Statistics (BLS) O*NET database"
- Classification of Instructional Programs (CIP): A standardized taxonomy for classifying academic programs and fields of study. "two-digit codes from the Classification of Instructional Programs (CIP)"
- Continuing claimant: An individual who remains on unemployment insurance and continues to certify eligibility. "the most recent major occupation group of each continuing claimant."
- Decile: One of ten equal groups into which data are divided for analysis or ranking. "decile "
- Employment and Training Administration (ETA) 203 report: A monthly federal report detailing characteristics of insured unemployed individuals, including occupation. "ETA 203 report from the Employment and Training Administration (ETA)"
- Fixed effects: Regression controls that account for unobserved, time-invariant differences across entities (e.g., states, sectors, schools). "fixed effects for the job's state and sector, and fixed effects for the individuals' education characteristics"
- LLMs: AI models trained on vast text corpora that can generate and understand human-like language. "were driven primarily by LLMs"
- LLM diffusion: The spread and adoption of LLM technologies across users, firms, and sectors. "LLM diffusion occurred in a labor market already shaped by macroeconomic and sectoral forces"
- LLM exposure: The extent to which an occupation’s tasks are affected by LLMs. "consider a job's LLM exposure according to its six-digit SOC occupation code."
- Long-run equilibrium: A stable state of the economy or market after short-term fluctuations have settled. "post-launch unemployment risk remains comparable to pre-pandemic levels, suggesting limited movement in the longer-run equilibrium."
- Monetary tightening: Policy actions (e.g., raising interest rates) that reduce money supply to curb inflation, potentially slowing employment. "monetary tightening accelerated through 2022â2023"
- NAICS code: The North American classification system for categorizing industries. "two-digit NAICS code of the job"
- Natural experiment: An observational situation where external events approximate random assignment, used to infer causal effects. "warn against using ChatGPT's 2022 launch as a clean natural experiment"
- Occupational Employment and Wage Statistics (OEWS): A BLS program providing employment and wage estimates by occupation. "BLS Occupational Employment and Wage Statistics (OEWS) program"
- O*NET: A comprehensive database of occupational tasks, skills, and requirements used to analyze job content. "Bureau of Labor Statistics (BLS) O*NET database"
- Quintile: One of five equal groups into which data are divided for analysis or ranking. "We group occupations into quintiles of LLM exposure"
- Real dollars: Monetary values adjusted for inflation to a base year to reflect purchasing power. "Log Salary (Real 2015 $)"</li> <li><strong>Seasonality</strong>: Regular, periodic fluctuations in data tied to calendar patterns (e.g., quarters, months). "lower-exposure quintiles exhibit higher levels and stronger seasonality"</li> <li><strong>Seasonally adjusted</strong>: Data modified to remove predictable seasonal effects, clarifying underlying trends. "see SI Fig. S2 for seasonally-adjusted plot"</li> <li><strong>Standard Occupation Classification (SOC)</strong>: A hierarchical coding system for U.S. occupations (e.g., two-digit major groups, six-digit detailed codes). "two-digit Standard Occupation Classification (SOC) codes"</li> <li><strong>Task-based exposure measures</strong>: Metrics that assess how specific job tasks are affected by technologies like LLMs. "task-based exposure measures"</li> <li><strong>Terminal degree</strong>: The highest academic degree typically required or offered in a field (e.g., PhD, MFA). "within three years after completing their terminal degree."</li> <li><strong>Three-way interaction</strong>: A regression term capturing how the joint effect of two variables depends on a third. "three-way interactions ($edu\times LLM\times gpt$) indicates that educational exposure partially offsets these post-ChatGPT penalties"
- Unemployment Insurance (UI): A government program providing temporary income to eligible unemployed workers. "Using monthly U.S. unemployment insurance records"
- Unemployment risk: The probability that workers in a given occupation will claim unemployment insurance in a given period. "we calculate an occupation's unemployment risk"
- Z-scores: Standardized values indicating how many standard deviations an observation lies from the mean. "Continuous predictors and dependent variables are centered and standardized (i.e., z-scores)."
Collections
Sign up for free to add this paper to one or more collections.