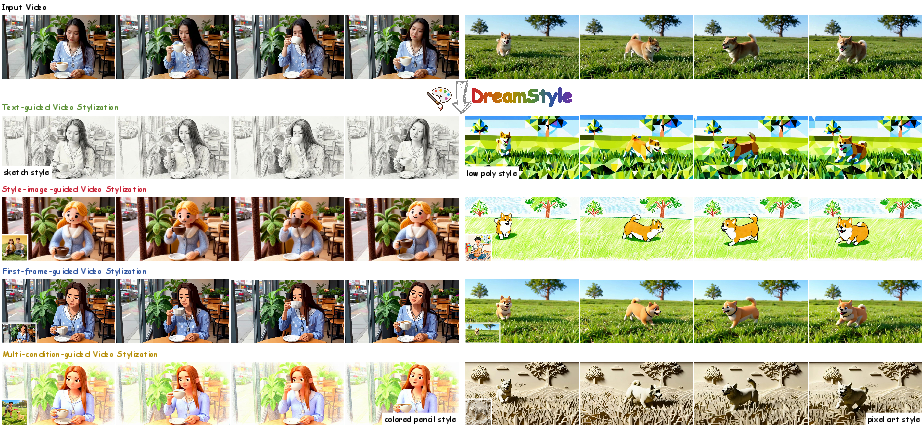
DreamStyle: A Unified Framework for Video Stylization
Abstract: Video stylization, an important downstream task of video generation models, has not yet been thoroughly explored. Its input style conditions typically include text, style image, and stylized first frame. Each condition has a characteristic advantage: text is more flexible, style image provides a more accurate visual anchor, and stylized first frame makes long-video stylization feasible. However, existing methods are largely confined to a single type of style condition, which limits their scope of application. Additionally, their lack of high-quality datasets leads to style inconsistency and temporal flicker. To address these limitations, we introduce DreamStyle, a unified framework for video stylization, supporting (1) text-guided, (2) style-image-guided, and (3) first-frame-guided video stylization, accompanied by a well-designed data curation pipeline to acquire high-quality paired video data. DreamStyle is built on a vanilla Image-to-Video (I2V) model and trained using a Low-Rank Adaptation (LoRA) with token-specific up matrices that reduces the confusion among different condition tokens. Both qualitative and quantitative evaluations demonstrate that DreamStyle is competent in all three video stylization tasks, and outperforms the competitors in style consistency and video quality.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DreamStyle, a tool that can change the “look” or “style” of a video while keeping the original action and story. Think of it like applying a high-quality filter to a video: you can make a normal clip look like a watercolor painting, a retro anime, or a futuristic neon world, without changing what happens in the video. DreamStyle is special because it works with three kinds of style instructions:
- Text (for example: “in the style of watercolor with soft pastel colors”)
- A style image (a picture that shows the exact look you want)
- A stylized first frame (one frame of the video already transformed to the target style)
What questions does the paper try to answer?
The authors aim to solve three main problems:
- How can we build one system that handles all three types of style guidance (text, style image, first frame) instead of training separate models?
- How can we train this system when there aren’t enough high-quality, matched examples of “before-and-after” stylized videos?
- How can we keep videos consistent over time (no flickering), stick closely to the chosen style, and still preserve the original motion and structure?
How does DreamStyle work?
DreamStyle has two big ideas: a data pipeline to create good training examples and a unified model that can accept different kinds of style inputs.
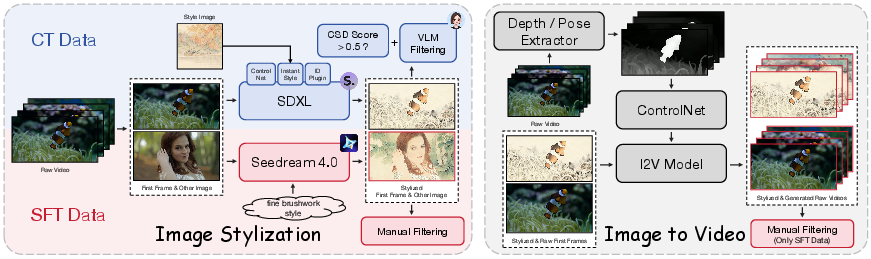
1) A smart way to make training data
Training a video stylization model is hard because you need pairs: the original video and a perfectly stylized version with matching motion. The authors build these pairs in two steps:
- Step A: Stylize the first frame of a real video using strong image tools. This gives a very clear “style anchor.”
- Step B: Use an image-to-video model to animate that stylized first frame into a full stylized video that matches the motion of the original.
To keep motion aligned, they use “ControlNets,” which are like helpful guides:
- Depth guide: a rough 3D map that keeps the structure of the scene stable.
- Pose guide: a skeleton-like map that keeps human movement consistent.
They also filter the data automatically and manually, keeping only high-quality pairs. They build two datasets:
- A large, diverse dataset (around 40,000 pairs) for “continual training” (CT) to teach broad stylization skills.
- A smaller, cleaner dataset (around 5,000 pairs) for “supervised fine-tuning” (SFT) to polish visual quality and style consistency.
2) One model that accepts different style inputs
DreamStyle is built on a strong, existing image-to-video model. The authors add a careful “condition injection” design so the model can use:
- Text prompts through the model’s normal text attention system.
- A stylized first frame by feeding it as a special starting frame.
- A style image by adding it as an extra frame and also extracting high-level features with CLIP (a tool that understands images and text).
To train without breaking the base model, they use LoRA, which you can think of as a small “plugin” that lightly tweaks the big model. Their version is “token-specific LoRA”: different types of input tokens (video tokens, first-frame tokens, style-image tokens) get their own customized path inside the plugin. This avoids confusion, like mixing up style details with motion signals.
They train the model in two stages:
- Stage 1: Train on the big CT dataset to learn general stylization skills across all three guidance types.
- Stage 2: Fine-tune on the small SFT dataset to improve style fidelity and video quality.
What did they find?
In tests, DreamStyle performs well across all three tasks:
- Text-guided stylization: It follows the style prompt closely and preserves the original video’s structure better than several commercial systems.
- Style-image-guided stylization: It matches the reference style strongly and produces more consistent videos than other open-source methods.
- First-frame-guided stylization: It keeps the style of the first frame stable throughout the video and maintains good motion and content coherence.
The model also supports:
- Multi-style fusion: You can combine a style image and a text description to create a blended, creative look.
- Long-video stylization: By chaining segments and using the last frame of one as the first frame of the next, DreamStyle can stylize longer videos more smoothly.
User studies (where people scored the results) show DreamStyle gets higher ratings in style consistency, content consistency, and overall quality.
Why is this important?
This work makes video stylization more practical and powerful:
- One unified tool: Creators don’t need separate models for different style inputs—DreamStyle handles text prompts, reference images, and stylized first frames in a single framework.
- Better training data: The pipeline provides matched, high-quality examples, reducing flicker and improving style consistency over time.
- Flexible and scalable: Multi-style fusion and long-video stylization unlock new creative workflows, useful for filmmakers, animators, and social media creators.
- Efficient training: LoRA lets the model learn new stylization abilities without retraining everything from scratch, saving time and resources.
In short, DreamStyle moves video stylization closer to “just works” by making it accurate, stable, and easy to control—no matter how you prefer to describe the style you want.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps, uncertainties, and unexplored directions left open by the paper, formulated to guide future research:
- Dataset availability and reproducibility: The paper does not state whether the 40K CT and 5K SFT paired stylized–raw video datasets will be released; without public data (and code), reproducing results and benchmarking competing methods is difficult.
- Dependence on non-public components: The approach relies on an in-house Wan14B-I2V model and proprietary stylization tools (e.g., Seedream 4.0); portability to publicly available backbones and open-source stylization models remains unexplored.
- Motion control inadequacy: Depth and human pose ControlNets fail to capture complex scene dynamics (non-rigid deformations, camera motion, occlusions); assess and integrate richer controls (optical flow/scene flow, segmentation/tracking, camera trajectory) and quantify their impact.
- Paired data alignment quality: The pipeline drives both raw and stylized videos with the same control conditions to reduce mismatch, but lacks objective measures of motion alignment; develop quantitative alignment metrics (e.g., flow consistency, warping error) and report alignment quality.
- Temporal consistency evaluation: No explicit flicker/temporal stability metrics are used; add temporal LPIPS variance, FVD, short-term/long-term warping error, and dedicated user studies focused on flicker and temporal coherence.
- Resolution and duration scaling: Training and evaluation are limited to 480p and ≤81 frames; investigate scalability to HD/4K and minute-long sequences, including memory, latency, and style persistence under longer temporal horizons.
- Multi-shot limitations: The method currently does not support multi-shot/scene videos; design shot-aware conditioning (e.g., per-shot anchors, transition handling) and datasets to tackle cross-shot style and content consistency.
- Multi-style fusion control: Fusion is demonstrated qualitatively but lacks a principled mechanism to weight or blend multiple style sources; introduce controllable fusion parameters, style embedding arithmetic, and quantitative fusion evaluations.
- Localized stylization: The framework does not support region-specific style application (e.g., subject-only or background-only); incorporate segmentation/masks and evaluate localized style transfer quality and content preservation.
- Style strength control: There is no explicit control over style intensity or a schedule across time; add a continuous “style strength” knob and per-frame style schedules, and measure trade-offs with structure preservation.
- Token-specific LoRA scope: Token-specific LoRA is applied to full attention and FFN layers with rank 64, but alternatives (conditional adapters, MoE routing, hypernetworks) and layer/rank ablations are not studied; compare conditioning-specific parameterizations across backbones.
- Conditioning injection design: Style-image and first-frame cues are injected via frame concatenation with fixed mask values; evaluate alternative conditioning (feature-level modulation, FiLM, style ControlNets) and justify mask/value choices through ablations.
- Training regime for multi-condition inference: Training uses only one condition type per batch while inference may mix multiple conditions; study joint multi-condition training, curriculum schedules, and sensitivity to the 1:2:1 sampling ratio.
- Metric coverage and validity: Reliance on CLIP-T (style-text similarity), DINO (structure), CSD (style consistency), and a subset of VBench may miss aspects of stylization quality; broaden metrics (FVD, tLPIPS, perceptual style diversity) and report statistical significance.
- Baseline coverage and fairness: Comparisons are limited (commercial text baselines, one open style baseline in T2V mode); include more open baselines, unify resolution/length, standardize inputs, and conduct significance testing on larger test sets.
- Style diversity quantification: The paper does not quantify style coverage in CT/SFT datasets or define a style taxonomy; measure style diversity, coverage of genres, color palettes, and patterns, and test generalization to unseen/out-of-distribution styles.
- Robustness to mismatched/contradictory inputs: Behavior under conflicting style prompts and style images, or low-quality style references, is not analyzed; develop conflict resolution (e.g., learned weighting/gating) and robustness tests to noisy/misaligned conditions.
- Failure case analysis: Limited discussion of challenging scenarios (fast motion, occlusions, camera shake, complex geometry changes); provide systematic failure-case diagnostics and targeted remedies (e.g., motion-aware losses, alignment modules).
- Identity preservation across time: While an ID plugin is used for first-frame stylization, identity preservation across the entire video is not quantified; add identity metrics (face recognition consistency) and evaluate trade-offs with style strength.
- Efficiency and latency: No runtime, memory footprint, or throughput measurements are reported; benchmark training/inference speed and quantify overhead from token-specific LoRA and multi-condition processing.
- Style persistence in long videos: Segment concatenation may lead to style drift; explore memory mechanisms (style caches, recurrent conditioning, temporal anchors) to maintain consistent style over long sequences.
- Architectural portability: The solution assumes specific image condition channels and mask conventions; document adaptation guidelines for models without such channels and verify portability across DiT-based and U-Net-based I2V/T2V backbones.
- Mask channel design: The use of fixed mask values (e.g., 1.0/0.0/−1.0 in ablations) is ad hoc; formalize token identification via learned tags/gates and ablate mask value schemes to establish principled conditioning.
- Style–structure trade-off controls: First-frame stylization can conflict with input structure (lower DINO scores); introduce explicit knobs to trade style fidelity vs structure preservation and evaluate user preference across tasks.
- Captioning and filtering reliability: VLM-based captioning and automatic filtering (CSD, VLM rules) may introduce biases/errors; measure filtering accuracy, inter-annotator agreement for manual filters, and their effect on training outcomes.
- Unified V2V/T2V training: DreamStyle inherits T2V capability without explicit training; study a unified training that jointly optimizes V2V and T2V and analyze cross-task interference/synergy.
- Non-human motion controls: Beyond human pose, controls for animals, objects, and rigid/non-rigid motion are not addressed; add object keypoints, skeletons, or category-specific motion priors and evaluate their benefits.
- Domain generalization: Performance on diverse domains (animation, line-art, comics, medical, scientific visualization) is untested; conduct domain-specific evaluations and adaptations.
- Stronger temporal losses: Training uses standard flow matching without explicit temporal/style persistence losses; explore auxiliary losses (temporal consistency, style coherence across frames, content anchors) and their training stability.
Practical Applications
Practical Applications Derived from the Paper
Below are concrete, real-world use cases that follow directly from DreamStyle’s unified video stylization framework, its token-specific LoRA, and its scalable data curation pipeline. Each item specifies sector(s), potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
- Stylized ad asset production at scale — marketing/advertising, media/entertainment
- Use DreamStyle to convert raw product or lifestyle videos into consistent brand-aligned styles using text prompts or brand style images while preserving content and motion.
- Tools/products/workflows: “Brand Style Locker” (style-image-guided presets), batch pipeline integrated with DAM (Digital Asset Management) systems; API endpoints for creative ops A/B testing using CLIP/ViCLIP scoring.
- Assumptions/dependencies: Access to brand-approved style references; GPU capacity; rights to input footage/style assets; adherence to brand governance.
- Creator tools for short-form video platforms — consumer apps, social media
- Offer text-guided or style-image-guided filters superior to LUTs, with first-frame guidance for longer clips; multi-style fusion sliders for creative control.
- Tools/products/workflows: Mobile/desktop “DreamStyle Studio” app or plugin (Premiere Pro/CapCut/Resolve); preset marketplace; inference served via cloud.
- Assumptions/dependencies: Distilled/optimized inference for near-real-time UX; content safety and IP filters for uploaded style images.
- Pre-visualization and art direction in post-production — film/TV, animation, VFX
- Rapidly explore art styles on live-action plates or previz sequences; preserve blocking and motion while varying texture/palette/geometric patterns.
- Tools/products/workflows: DCC plugins (Nuke/After Effects/Blender), shot-by-shot stylization with per-shot style-image guides; automated reporting of structure preservation (DINO) and style consistency (CSD).
- Assumptions/dependencies: Per-shot (single-shot) constraints; multi-shot consistency needs manual supervision; high-end GPUs in studio render farms.
- Uniform brand look for corporate/training videos — enterprise enablement
- Standardize style across distributed content teams (region-specific adaptations, brand refreshes) using shared style-image references and templated prompts.
- Tools/products/workflows: Workflow bot in MAM/LMS; batch job that extracts pose/depth, stylizes first frame, and runs V2V; governance dashboard with human-in-the-loop filtering.
- Assumptions/dependencies: Corporate IT integration; template governance; privacy and consent for any identifiable subjects.
- Rapid prototyping of game cutscenes and trailers — gaming, interactive media
- Stylize captured or cinematic sequences to quickly evaluate alternative art directions (anime, comic, painterly) while preserving camera and motion beats.
- Tools/products/workflows: Unreal/Unity pipeline node; offline batch stylization of recorded takes; multi-style fusion to converge on new art styles.
- Assumptions/dependencies: Offline (not real-time) inference; legal clearance on third-party style references.
- Educational content re-skinning for engagement — education/edtech
- Convert lecture or explainer videos into styles aligned with learner age/interest (comic, chalkboard, blueprint) while preserving diagrams/gestures.
- Tools/products/workflows: LMS-integrated batch stylizer; templates per course persona; automatic captioning alignment preserved via V2V content retention.
- Assumptions/dependencies: Safeguards to avoid misrepresenting scientific visuals; accessibility (contrast/legibility) QA.
- Music and fashion campaign visuals — media/entertainment, retail
- Stylize performance or runway footage to match album or collection aesthetics; maintain subject identity and choreography.
- Tools/products/workflows: Campaign presets; sequence-level first-frame chaining for 10–20s clips; side-by-side dashboards with aesthetic/dynamic metrics.
- Assumptions/dependencies: Identity and likeness rights; curated prompts to avoid over-stylization that harms recognizability.
- Automated dataset generation for video editing research — academia, R&D labs
- Reuse the paper’s pipeline (stylize first frame with SOTA image models + I2V with ControlNets + filtering) to create paired stylized-real datasets for new tasks (e.g., illumination/weather editing).
- Tools/products/workflows: Open benchmarking kit with VLM captions, CSD/DINO scoring, and human QA templates; LoRA-based adapters for multi-condition training.
- Assumptions/dependencies: Availability/licensing of base I2V and ControlNets; reproducible filtering heuristics; compute availability.
- Unified multi-condition model training template — academia, applied ML
- Apply token-specific LoRA (shared down, token-specific up) to reduce interference for models that handle text, image, and frame tokens jointly.
- Tools/products/workflows: Training recipes and reference implementations; ablation-ready checkpoints; token routing utilities.
- Assumptions/dependencies: Access to base DiT or U-Net architectures; support for condition-channel injection; stable training configs.
- Privacy-enhancing stylization for public sharing — consumer, enterprise compliance
- Stylize backgrounds while preserving main subject to reduce scene identifiability in workplace demos or consumer videos.
- Tools/products/workflows: Background-only stylization prompts; pose/depth ControlNets to keep subject coherent; automated content safety checks.
- Assumptions/dependencies: Stylization may not guarantee anonymity; legal review required; test for leakage of sensitive details.
Long-Term Applications
- Long-form, multi-shot consistent stylization — film/TV, streaming
- Extend first-frame chaining with cross-shot linkage (scene graphs, shot detection, global style tokens) for episode-length stylization with stable identity, palette, and motifs.
- Tools/products/workflows: Edit-decision-list (EDL) aware stylization; global style memory and per-shot refinement; color pipeline interop.
- Assumptions/dependencies: Research in multi-shot coherence and identity preservation across cuts; stronger temporal modeling beyond current base model limits.
- Real-time stylization for live streaming and AR — consumer, broadcasting
- Deliver low-latency, text/style-image-guided stylization for livestreams, telepresence, or AR filters.
- Tools/products/workflows: Model distillation, quantization, and sparse attention; edge serving on GPUs/NPUs; dynamic prompt/style mixing.
- Assumptions/dependencies: Significant efficiency gains over current I2V backbones; robust safety and failure handling.
- Domain adaptation and robustness via video style augmentation — robotics, autonomous driving, vision ML
- Use controllable stylization to produce domain-shifted videos (textures/lighting) for training perception models more robust to appearance changes.
- Tools/products/workflows: Data augmentation factory; style curricula; automated validation against downstream metrics.
- Assumptions/dependencies: Demonstrated positive transfer without harming geometry/motion cues; licensing of source data.
- Personalized learning and accessibility-at-scale — education, public sector
- Dynamically stylize learning videos to match learner profiles (readability, contrast, motion sensitivity), and to localize cultural aesthetics for global audiences.
- Tools/products/workflows: Accessibility presets (high-contrast, dyslexia-friendly overlays); teacher dashboards to configure per cohort; policy-aligned content metadata.
- Assumptions/dependencies: Empirical studies validating learning outcomes; accessibility standards compliance.
- IP-safe style ecosystems and provenance — policy, creative industry infrastructure
- Create frameworks for consented style references, watermarking/steganography of stylized outputs, and metadata signaling of transformations.
- Tools/products/workflows: Style licensing registries; content provenance (C2PA) integration; filters detecting protected artist styles.
- Assumptions/dependencies: Cross-industry standards; detection robustness; regulatory buy-in.
- Hybrid creative direction (human + AI) tools — media/entertainment, design
- Interactive UIs to mix text and multiple style images with fine-grained weights, mask-controlled regions, and timeline curves for style strength.
- Tools/products/workflows: Style graph editors; per-layer token weighting; timeline keyframing of styles; collaborative review with metric overlays.
- Assumptions/dependencies: Improved controllability and interpretability; UX research for professional adoption.
- Synthetic video data factories for broader editing tasks — software, ML platforms
- Generalize the paper’s data curation pipeline to generate paired datasets for de-aging, relighting, weather/time-of-day changes, or material edits.
- Tools/products/workflows: Modular pipeline with plug-in condition extractors (normals, optical flow); multi-task LoRA adapters; evaluation suites beyond CSD/DINO.
- Assumptions/dependencies: High-quality image-to-image controllers for target edits; reliable multi-condition extraction.
- Brand-native “style tokens” and creative governance — advertising, retail
- Train brand-specific LoRA adapters or style tokens that lock content to brand guides across agencies and regions, with compliance dashboards.
- Tools/products/workflows: Token lifecycle management; automatic drift detection; audit logs of prompts and references.
- Assumptions/dependencies: Legal frameworks for style tokenization; secure model hosting and usage controls.
- Identity-preserving yet content-transforming pipelines — sports, live events
- Maintain athlete/performer identity and motion while transforming venue aesthetics for alternative broadcasts (retro, comic, team-themed).
- Tools/products/workflows: Real-time or near-real-time stylization with identity locks; sponsor-integrated styles; audience-selectable feeds.
- Assumptions/dependencies: Efficient inference; rights and sponsorship approvals; broadcast-grade QA.
- Standards, benchmarks, and policy guidance for stylized video — academia, standards bodies, regulators
- Formalize metrics that correlate with human perception across style, content preservation, temporal coherence; develop disclosure standards for stylized content.
- Tools/products/workflows: Public benchmark suites with subjective/objective protocols; dataset cards for curated stylized data; disclosure templates.
- Assumptions/dependencies: Community consensus on metrics; collaboration across industry/academia; funding for shared infrastructure.
Notes on cross-cutting assumptions/dependencies:
- Model access/licensing: Availability of Wan14B-I2V (or equivalent) and ControlNets, plus rights to use InstantStyle/Seedream or substitutes.
- Compute and cost: GPU resources for training/inference; potential need for distillation/optimization for edge and real-time cases.
- Data rights and ethics: Permission for source videos and style images; safeguards against unauthorized style appropriation; privacy and safety reviews.
- Limitations to plan around: Current model is strongest on single-shot clips; multi-shot/global consistency and live latency require further R&D.
Glossary
- AdamW: An optimizer that decouples weight decay from gradient updates to improve training stability. "We train DreamStyle for $6,000$ and $3,000$ iterations in the CT and SFT stages, respectively, using a LoRA with a rank of $64$ and AdamW~\cite{loshchilov2018decoupled} optimizer with a learning rate of ."
- AdaIN: Adaptive Instance Normalization; a technique that aligns feature statistics to transfer style. "UniVST~\cite{song2024univst} further DDIM inverses the style image and leverage AdaIN~\cite{huang2017arbitrary} to guide the denoising progress of noisy video by the inverted features of style."
- Aesthetic Quality: A metric assessing the visual appeal of generated videos. "We further assess the overall quality of stylized video with five metrics from VBench~\cite{huang2024vbench}: dynamic degree, image quality, aesthetic quality, subject consistency, and background consistency."
- Background Consistency: A metric measuring how consistently the background remains across frames. "We further assess the overall quality of stylized video with five metrics from VBench~\cite{huang2024vbench}: dynamic degree, image quality, aesthetic quality, subject consistency, and background consistency."
- Channel-wise concatenation: Concatenation operation along the channel dimension of a tensor to combine inputs. "we construct the final I2V model's input tensor for the style image via channel-wise concatenation:"
- CLIP: A vision-LLM that encodes images/text into a shared embedding space for semantic alignment. "StyleCrafter~\cite{liu2024stylecrafter} utilizes CLIP~\cite{radford2021learning} to extract style features and inject these features into the denoising U-Net via dual cross-attention."
- CLS token: The special classification token used in Transformer models to aggregate sequence information. "Moreover, structure preservation is evaluated using the cosine similarity of the patch features (excluding the CLS token) extracted from DINOv2~\cite{oquab2024dinov}."
- ControlNet: A network that conditions diffusion models on external signals (e.g., depth, pose) to control generation. "For image to video, we utilize ControlNets to enhance the motion consistency between the generated stylized and raw videos."
- cross-attention: An attention mechanism that conditions one sequence (e.g., video tokens) on another (e.g., text or image features). "StyleCrafter~\cite{liu2024stylecrafter} utilizes CLIP~\cite{radford2021learning} to extract style features and inject these features into the denoising U-Net via dual cross-attention."
- CSD score: A quantitative metric for style consistency based on style distance. "For the CT dataset, we further filter out those with low style consistency detected by VLM and CSD~\cite{somepalli2024measuring} score"
- DDIM inversion: Reversing the DDIM sampling process to obtain latent trajectories aligned with a given image or video. "However, these approaches can not perform video stylization independently, and rely on a time-consuming DDIM~\cite{song2021denoising} inversion."
- Depth ControlNet: A ControlNet variant that uses depth maps to constrain structure and motion. "InstantStyle is a SDXL~\cite{podell2024sdxl} plugin, which we further equip with a depth ControlNet~\cite{zhang2023adding} and ID plugin~\cite{guo2024pulid} to constrain the consistency of structure and face identity."
- DINOv2: A self-supervised vision transformer providing robust patch-level features for similarity and consistency evaluation. "Moreover, structure preservation is evaluated using the cosine similarity of the patch features (excluding the CLS token) extracted from DINOv2~\cite{oquab2024dinov}."
- DiT (Diffusion Transformer): A transformer-based diffusion architecture modeling spatial-temporal tokens for generation. "With the release of Sora~\cite{brooks2024video} and its epoch-making generation quality, researchers notice the potential of Diffusion Transformer~\cite{peebles2023scalable} (DiT) for video generation."
- Dynamic Degree: A metric quantifying the amount of motion dynamics in generated videos. "We further assess the overall quality of stylized video with five metrics from VBench~\cite{huang2024vbench}: dynamic degree, image quality, aesthetic quality, subject consistency, and background consistency."
- Feedforward (FFN) layers: The position-wise multilayer perceptron blocks in transformer architectures. "we propose adopting a modified LoRA with token-specific up matrices in full attention and feedforward (FFN) layers."
- Flow Matching: A training objective that matches probability flows between data and noise distributions for generative models. "We follow the same optimization objective as flow matching to train our DreamStyle."
- Flow matching loss: The specific regression loss used to train models under the flow matching objective. "We train it using a standard flow matching loss and a token-specific LoRA that contributes to distinguishing different condition tokens."
- frame-wise concatenation: Concatenation along the temporal frame dimension to insert reference frames into sequences. "For the style-image-guided mode, is treated as an additional frame and concatenated to the end of via frame-wise concatenation "
- gradient accumulation: A training technique that accumulates gradients over multiple steps to simulate larger batch sizes. "To stabilize training, we further adopt a 2-step gradient accumulation strategy, resulting in a larger effective batch size of $16$."
- HydraLoRA: A LoRA variant that uses shared-down and multiple up-projections to specialize adapters for different inputs. "Inspired by HydraLoRA~\cite{tian2024hydralora}, we propose adopting a modified LoRA with token-specific up matrices in full attention and feedforward (FFN) layers."
- ID plugin: An identity-preservation module to keep face or subject identity consistent during generation. "InstantStyle is a SDXL~\cite{podell2024sdxl} plugin, which we further equip with a depth ControlNet~\cite{zhang2023adding} and ID plugin~\cite{guo2024pulid} to constrain the consistency of structure and face identity."
- Image Quality: A metric measuring frame-level visual fidelity and clarity. "We further assess the overall quality of stylized video with five metrics from VBench~\cite{huang2024vbench}: dynamic degree, image quality, aesthetic quality, subject consistency, and background consistency."
- Image-to-Video (I2V): Generating video sequences conditioned on a single image (e.g., the first frame) and auxiliary signals. "DreamStyle is built on a vanilla Image-to-Video (I2V) model"
- In-context frames injection: Providing reference frames directly to the model’s context rather than via dedicated channels. "This design allows for the injection of raw video condition via these channels, rather than the in-context frames injection adopted in UNIC~\cite{ye2025unic}."
- Latent Diffusion Models (LDMs): Diffusion models trained in the latent space of a VAE to reduce computational cost. "Latent Diffusion Models~\cite{rombach2022high, podell2024sdxl} (LDMs) further optimize this paradigm by training a diffusion network in the latent space of pretrained Variational Autoencoder~\cite{Kingma2014} (VAE)"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank adapters into layers. "DreamStyle is built on a vanilla Image-to-Video (I2V) model and trained using a Low-Rank Adaptation (LoRA) with token-specific up matrices that reduces the confusion among different condition tokens."
- LoRA MoE: A mixture-of-experts adaptation where multiple LoRA heads are routed to different token types. "which is analogous to a LoRA MoE~\cite{dou2024loramoe} with manual routing."
- mask channels: Special channels indicating which parts of the input are fixed or conditioned (e.g., first frame). "The number of mask channels is $4$ in Wan14B-I2V, thus represents a mask tensor filled with a constant value $1.0$."
- Patchify layer: A preprocessing layer that splits images/videos into patches before transformer tokenization. "that incorporates additional image condition channels before the patchify layer."
- Pose ControlNet: A ControlNet variant that uses human pose estimates for precise motion control. "the human pose ControlNet offers a more precise control of human motion and especially allows for a larger deformation of driven objects without losing motion coherence."
- SDXL: A large-scale latent diffusion backbone for high-quality image generation. "InstantStyle is a SDXL~\cite{podell2024sdxl} plugin"
- Seedream 4.0: A text-guided image stylization model used to build high-quality datasets. "InstantStyle~\cite{wang2024instantstyle} and Seedream 4.0~\cite{seedream2025seedream} are selected as their stylization models, respectively."
- SFT (Supervised Fine-Tuning): A fine-tuning stage on high-quality curated data to improve performance bounds. "a small-scale higher-quality stylized dataset for Supervised Fine-Tuning (SFT) generated with Seedream 4.0 to elevate the upper bound of DreamStyle."
- Style-image-guided stylization: Stylizing videos using a reference image that anchors the target style. "supporting (1) text-guided, (2) style-image-guided, and (3) first-frame-guided video stylization"
- Subject Consistency: A metric evaluating how consistently the main subject is preserved across frames. "We further assess the overall quality of stylized video with five metrics from VBench~\cite{huang2024vbench}: dynamic degree, image quality, aesthetic quality, subject consistency, and background consistency."
- Temporal attention: Attention mechanisms modeling dependencies across time for video generation/editing. "resorting to StillMoving~\cite{chefer2024still} to train a LoRA~\cite{hu2022lora} for temporal attention to bridge the gap between image and video."
- Text-to-Video (T2V): Generating videos directly from text prompts without an input video. "UNIC~\cite{ye2025unic} synthesizes stylized videos via a Text-to-Video (T2V) model"
- Token-specific LoRA: A LoRA design that uses different up-projection matrices per token type to avoid interference. "We train it using a standard flow matching loss and a token-specific LoRA that contributes to distinguishing different condition tokens."
- U-Net: A convolutional encoder-decoder architecture commonly used as the denoising backbone in diffusion. "StyleCrafter~\cite{liu2024stylecrafter} utilizes CLIP to extract style features and inject these features into the denoising U-Net via dual cross-attention."
- V2V (Video-to-Video): Editing or stylizing a video conditioned on another video (or its features). "we introduce a unified Video-to-Video (V2V) stylization framework, which is built upon a vanilla I2V model."
- VAE (Variational Autoencoder): A generative model that encodes data into a latent distribution for efficient reconstruction/generation. "Latent Diffusion Models~\cite{rombach2022high, podell2024sdxl} (LDMs) further optimize this paradigm by training a diffusion network in the latent space of pretrained Variational Autoencoder~\cite{Kingma2014} (VAE)"
- VBench: A benchmark suite providing multi-dimensional video quality and consistency metrics. "We further assess the overall quality of stylized video with five metrics from VBench~\cite{huang2024vbench}: dynamic degree, image quality, aesthetic quality, subject consistency, and background consistency."
- ViCLIP: A video-LLM measuring text-video semantic alignment. "For text-guided stylization, we employ ViCLIP~\cite{wanginternvid} to measure the similarity between user prompt and stylized video."
- Visual-LLM (VLM): Models that jointly reason over visual and textual inputs to produce captions or descriptions. "We utilize a Visual-LLM~\cite{zhang2024vision} (VLM) to parse the stylized video and then generate the corresponding video caption."
- Wan14B-I2V: A large Image-to-Video base model used as the backbone for DreamStyle. "our DreamStyle framework is built upon the Wan14B-I2V~\cite{wan2025wan} base model"
Collections
Sign up for free to add this paper to one or more collections.