- The paper introduces a unified framework, JPU, that mines adversarial samples, identifies dynamic jailbreak paths, and applies constraint-based rectification.
- It employs a first-order Taylor approximation for inter-layer gradient integration to effectively isolate and reprogram adversarial circuits while maintaining model performance.
- Experimental evaluations on Llama-2 and Llama-3 models show JPU reduces attack success rates by up to 2× and halves refusal errors compared to leading baselines.
Jailbreak Path Unlearning: Mechanism, Effectiveness, and Implications
Motivation and Problem Analysis
Despite advanced safety alignment methods, LLMs remain susceptible to adaptive jailbreak attacks that bypass standard refusal behaviors. Traditional machine unlearning approaches—parameter erasure using harmful data—have shown vulnerability to sophisticated, evolving jailbreak strategies. Empirical analysis in the paper demonstrates that successful jailbreaks activate non-erased parameters, particularly in intermediate layers, allowing adversarial information to propagate toward harmful outputs. The critical insight is that static unlearning methods neglect dynamic, path-based mechanisms facilitating adaptive attacks. Dynamic jailbreak paths persist even after conventional unlearning, underscoring the necessity for defenses targeting inter-layer adversarial circuitry.
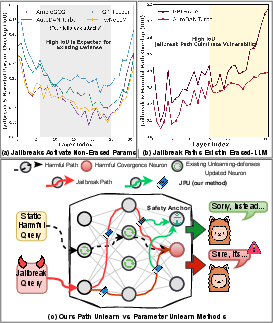
Figure 1: JPU explicitly rectifies dynamic jailbreak paths within erased LLMs, achieving superior defense while preserving utility.
Methodology: Jailbreak Path Unlearning (JPU)
JPU introduces a unified framework that actively mines adversarial samples via on-policy attack buffer mining, identifies dynamic jailbreak paths, and performs constrained path rectification. The process iteratively exposes vulnerabilities, traces critical information flows from intermediate to final layers, and applies targeted constraints to redirect harmful trajectories toward benign semantic anchors.
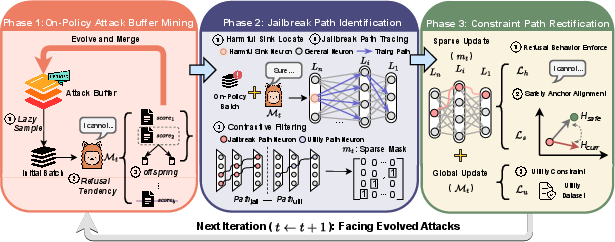
Figure 2: JPU comprises on-policy attack mining, dynamic path identification, and constraint-based path rectification within LLMs.
Attack Buffer Mining
JPU maintains a dynamic attack buffer by evolving adversarial prompts in tandem with model updates. Samples in the buffer are selected based on the model's current refusal loss; high-loss samples (where refusals fail) are mutated to explore diverse vulnerabilities, simulating an adversarial red-teaming process. This adaptive mining ensures that the defense remains responsive to evolving attack semantics rather than fixed data distributions.
Path Identification
JPU employs a first-order Taylor approximation of Inter-layer Gradient Integration (IGI) to efficiently identify dynamic jailbreak paths. By anchoring to the logits of semantically critical tokens (e.g., “Sure”), the method traces information flows backward from deep layers through FFNs to locate neurons and connections responsible for propagating harmful activations. A binary sparse mask is constructed to demarcate top-p% connections with high jailbreak flow and low utility flow, reliably pinpointing adversarial circuits.
Constraint Path Rectification
Defense is accomplished not by crude pruning but through joint optimization. Three constraints are imposed:
- refusal behavior (token-level suppression of unsafe outputs),
- safety representation alignment (minimizing hidden-state distance to safety anchors),
- utility preservation (standard likelihood on benign data).
These losses are aggregated and applied selectively on identified paths, reprogramming adversarial circuitry toward safe computation while preserving broad utility.
Experimental Evaluation
JPU is benchmarked on Llama-2-7B-Chat and Llama-3-8B-Instruct against multiple adaptive and static jailbreak attacks (AdvBench, MIX-JAIL, etc.) and compared to leading baselines (CKU, Eraser, Safe Unlearning, Circuit Breaker, RSFT).
JPU consistently achieves the lowest attack success rates (ASR), outperforming CKU and others by up to 2× reduction on critical benchmarks. Notably, defense generalizes even when trained only on randomly selected small query subsets, indicating the robustness of path-focused unlearning over isolated harmful knowledge erasure. The analysis of layer-wise intersection over union (IOU) shows substantial reduction in adversarial path overlap after JPU treatment.
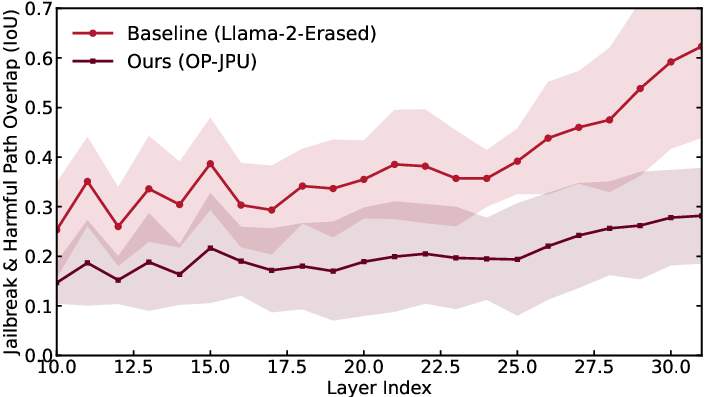
Figure 3: JPU rectifies adversarial circuitry more effectively than baselines, as measured by path overlap across attacks and layers.
Utility Preservation and Refusal Calibration
NLP performance is maintained across MT-Bench, CommonsenseQA, HellaSwag, and other general benchmarks. Importantly, JPU reduces False Refusal Rate (FRR) on XSTest by half compared to baseline models, signifying successful disentanglement of adversarial and benign inputs—crucial for practical deployment.
Component and Hyperparameter Analysis
Ablation studies indicate that each component of JPU (dynamic mining, path localization, semantic anchor alignment, utility constraint) is indispensable. Random masking or removal of key modules leads to catastrophic degradation in either robustness or general model utility.
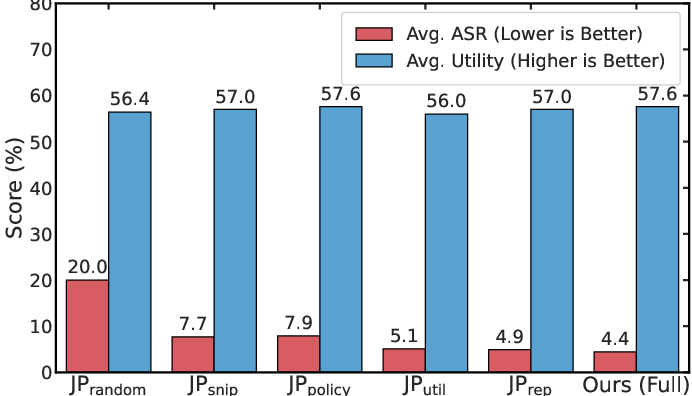
Figure 4: Ablation: All components of JPU are essential for high jailbreak resistance and generic performance.
Path sparsity is identified as a crucial trade-off: masking too few neurons yields poor defense, while excessive pruning damages utility. The authors select p=0.05 as optimal.
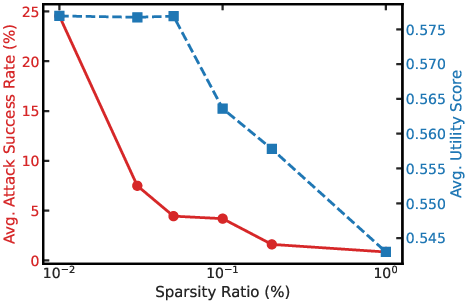
Figure 5: Tuning path sparsity achieves the best balance between jailbreak resistance and model utility.
On-Policy Mining Necessity
Static training with fixed adversarial buffers is demonstrably insufficient against dynamic attacks. Only the on-policy strategy yields robust defense under varying buffer compositions, confirming the benefit of online adversarial data mining.
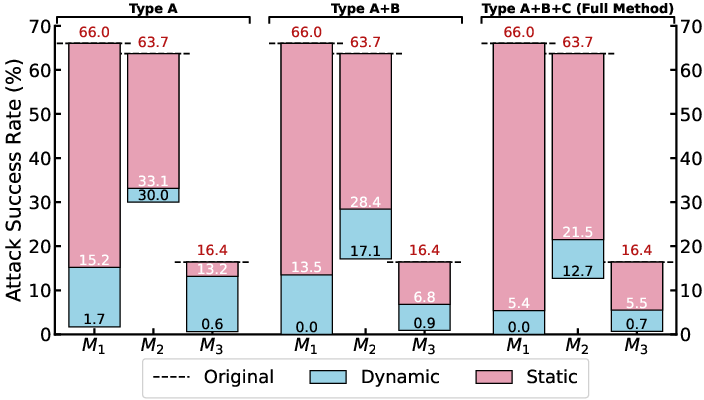
Figure 6: Dynamic (on-policy) mining yields consistently lower ASR than static baselines, regardless of buffer diversity.
Theoretical and Practical Implications
JPU demonstrates that robust jailbreak defense in LLMs must target dynamic, path-based adversarial mechanisms rather than isolated parameter sets. This paradigm reconciles the limitations of prior unlearning approaches, transforming defense from passive knowledge deletion to active structural reconfiguration. Practically, JPU provides a scalable blueprint for incorporating dynamic adversarial mining and path rectification within alignment pipelines, promising higher resilience against future adaptive attack methodologies.
Theoretically, the work suggests a broader direction for safety in neural networks: defenses should be designed to monitor, identify, and rectify distributed activation pathways that evolve with model and adversary states. This has implications for interpretability, safe representation learning, and the design of modular update strategies for large models.
Future Directions
While JPU currently focuses on prompt-based jailbreak attacks, extending coverage to decoding manipulations and parameter-level adversarial methods is likely to further enhance robustness. Mechanistically, incorporating richer adversarial mining, targeted attention intervention, and multimodal path tracing represents key venue for future research in scalable LLM safety. The framework also inspires potential automation of red-teaming protocols and more granular model editing at the circuit level.
Conclusion
JPU represents a significant advance in defending LLMs against adaptive jailbreak attacks by rectifying dynamic adversarial paths through on-policy mining and structural optimization. The framework yields superior resistance across diversified attack surfaces, maintains general model utility, and avoids over-refusal on benign tasks. This path-centric defense paradigm answers the shortcomings of static unlearning and sets a precedent for future LLM safety research focused on internal activation dynamics and circuit-level adaptability (2601.03005).