- The paper presents QZero, a model-free RL approach that masters Go without search by leveraging self-play and off-policy experience replay.
- It employs entropy regularization and an ignition mechanism to stabilize training and balance exploration with exploitation.
- Evaluations show QZero achieving a competitive 5D rank and an Elo rating between 2000 and 2100, demonstrating efficient learning with reduced resources.
Mastering the Game of Go with Self-play Experience Replay
Introduction
The game of Go has traditionally posed a formidable challenge for AI due to its intricate strategic requirements and expansive decision space. Historically, AI systems like AlphaGo have demonstrated success in this domain using model-based Reinforcement Learning (RL) with Monte-Carlo Tree Search (MCTS). However, this paper, titled "Mastering the Game of Go with Self-play Experience Replay" (2601.03306), introduces QZero, a novel approach leveraging model-free reinforcement learning. This methodology emphasizes learning a Nash equilibrium policy through self-play and off-policy experience replay without the use of search during training.
Methodology
Model-Free Reinforcement Learning
QZero distinguishes itself by adopting a model-free approach that eliminates the dependency on an environment model, characteristic of prior systems like AlphaGo. In model-free RL, the agent learns through direct interaction with the environment, guided by the framework of Markov Decision Processes (MDPs). The goal is to optimize the policy such that the expected cumulative reward is maximized, adhering to the MDP framework with states, actions, transition probabilities, reward functions, and a discount factor.
Entropy Regularization and Unification
Central to QZero's methodology is the integration of entropy regularization within reinforcement learning to stabilize training and enhance exploration-exploitation trade-offs. Under this approach, the entropy of the policy is included as an additional reward component, leading to what is termed Soft Reinforcement Learning (SRL). This allows for the unification of value-based and policy-based methods, suggesting that SRL can encompass traditional RL as a special case.
QZero Algorithm
QZero evolves from conventional soft Q-learning, applying it to the complex domain of Go through a single Q-value network for unified policy evaluation and improvement. QZero initiates with an "Ignition Mechanism" that uses episode returns as Q-value targets to mitigate the severe bias typically encountered in early training phases. It further employs Polyak averaging to stabilize training, refining neural network parameters through an exponentially weighted average.
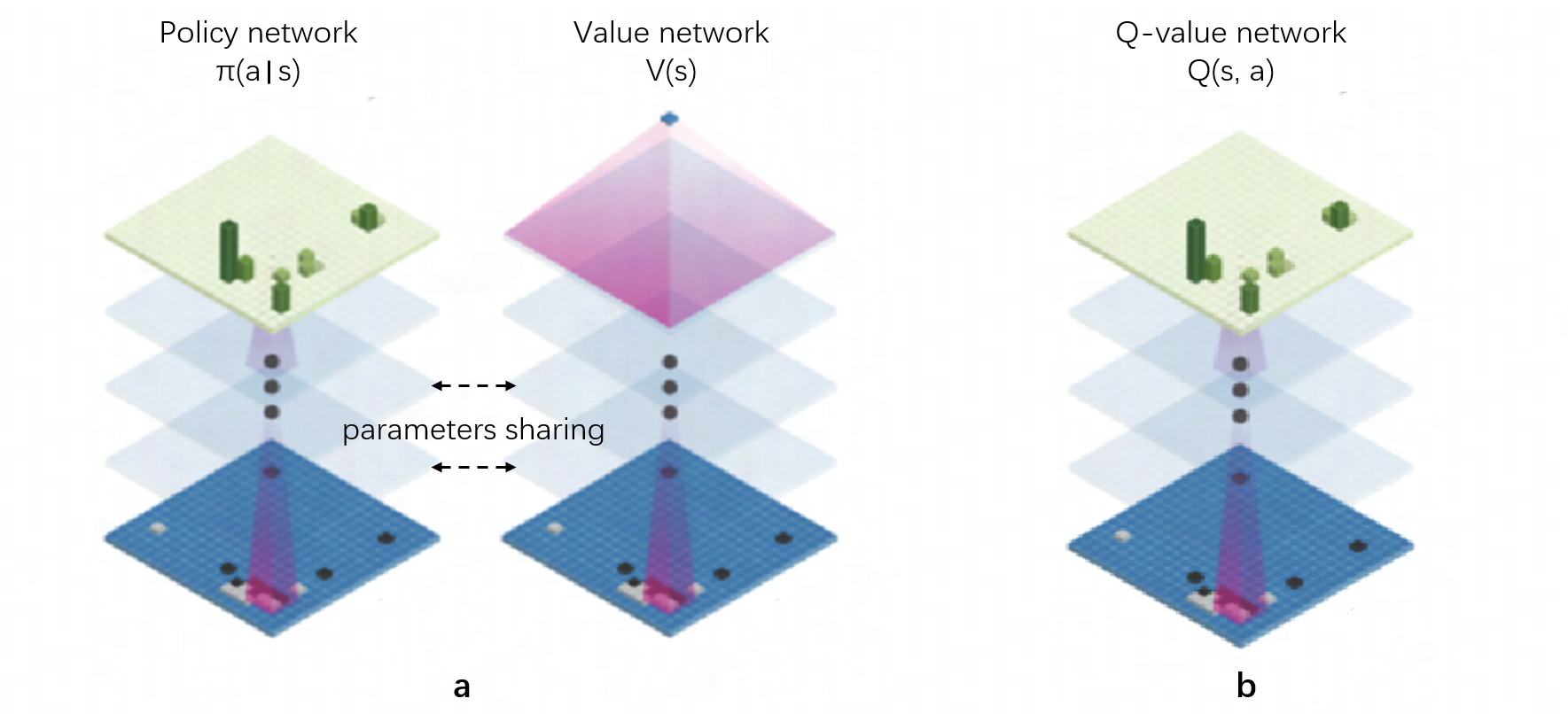
Figure 1: Neural network architectures of AlphaGo and QZero, highlighting QZero's single network used for both policy and value.
Experimental Setup
Environment and Network Architecture
For its experiments, QZero employs a modified Go environment based on GymGo. The environment outputs observations as tensors capturing board state, player turn, and move legality. The game follows standard Go rules with scoring adjusted to adhere to the Chinese scoring system with a komi of 7.5 points. The neural network architecture remains largely similar to AlphaGo Zero, featuring a residual network structure that processes the 19x19 board state.
Training Framework
The training is conducted asynchronously across a framework involving multiple GPUs, Actors performing self-play, Replay Buffers for experience storage, and Learners managing neural network training. This infrastructure mirrors industry-standard off-policy reinforcement learning setups but operates with significantly less computational power compared to its predecessors, showcasing a striking level of data and compute efficiency.
Results
QZero demonstrates performance comparative to AlphaGo with significantly reduced resources. Through self-play and the absence of human data, QZero reached a competitive rank of 5D on an online Go platform, achieving an Elo rating between 2000 and 2100. These evaluations are based directly on raw network outputs without leveraging test-time computation enhancements like MCTS.
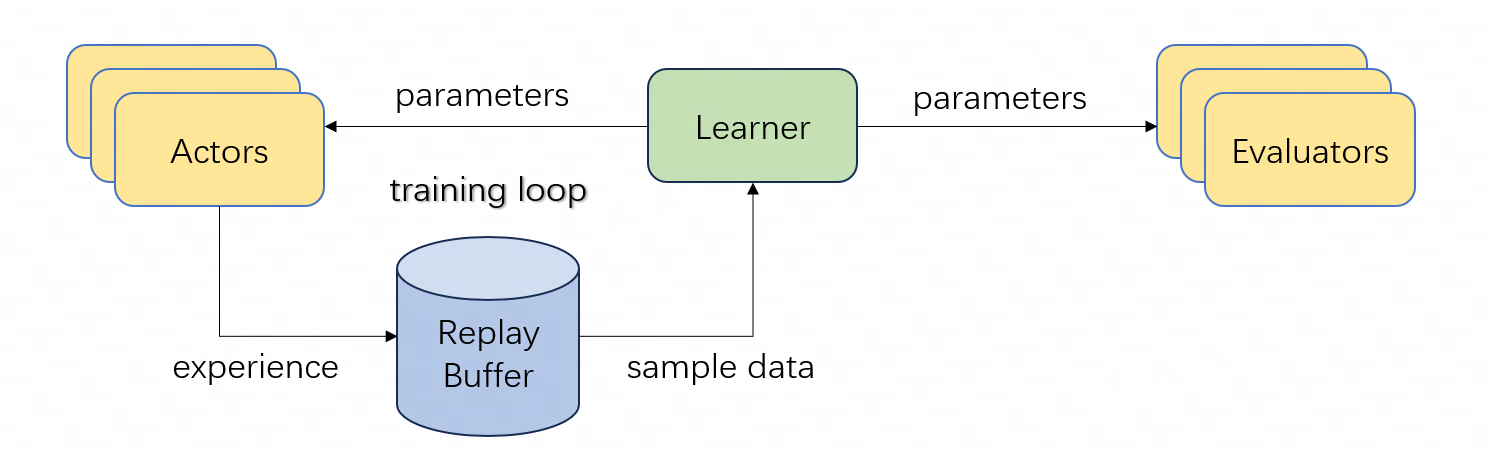
Figure 2: Evaluations depicting history score gain and Elo ratings comparison among QZero, AlphaGo, and AlphaGo Zero.
The training encompassed a five-month period, highlighting consistent improvement as evidenced by stable history score gains throughout the process. QZero's progress indicates substantial mastery of complex Go concepts, achieved from self-generated stochastic data.
Discussion
The findings challenge the preconceived notion that rigorous computation models are necessary to overcome the complexity of Go. The success of QZero underscores the potential of model-free RL methods in environments traditionally dominated by model-based approaches. The paper posits that efficient reinforcement learning algorithms can indeed align computational efficiency with high-level strategic mastery.
Conclusion
QZero successfully demonstrates the efficacy of model-free RL in mastering the game of Go, offering a compelling alternative to traditional model-based systems. By achieving comparable results to AlphaGo with significantly fewer computational resources, QZero exemplifies an innovative stride in the scalability and efficiency of reinforcement learning. These results emphasize a broader implication for AI research, suggesting promising avenues for future exploration in both large-scale off-policy reinforcement learning and the pursuit of continual learning paradigms.
