- The paper presents a novel Gaussian-to-Point alignment technique that integrates appearance and boundary cues to enhance 3D semantic segmentation.
- It employs anisotropic Gaussian splatting and Mahalanobis-based neighbor matching to extract precise boundary features and mitigate misalignment.
- Experimental results on ScanNet benchmarks demonstrate significant improvements in segmenting geometrically ambiguous regions in indoor scenes.
G2P: Gaussian-to-Point Attribute Alignment for Boundary-Aware 3D Semantic Segmentation
Introduction
The paper introduces Gaussian-to-Point (G2P), a methodology for 3D semantic segmentation that leverages attributes from 3D Gaussian Splatting (GS) to augment conventional point cloud inputs. The motivation stems from the limitations of geometric features for semantic segmentation: sparse and irregularly-distributed point clouds often make it difficult to separate objects of similar geometry but distinct visual appearance, especially at boundaries or in cases of coplanarity, such as windows, doors, and metallic appliances adjacent to walls. Existing approaches relying solely on geometric cues or 2D/3D fusion face alignment issues and fail to consistently capture critical appearance information.
By explicitly aligning GS-derived appearance and boundary indicators to the native point representation, G2P unifies both geometric and appearance cues in the 3D domain, greatly improving segmentation, especially for geometrically ambiguous regions. The framework introduces a robust alignment mechanism that accounts for spatial misalignment induced by GS optimization, opacities for appearance distillation, and scale attributes for boundary extraction. All improvements are implemented without 2D or language-based supervision, providing a purely 3D, label-efficient pipeline.
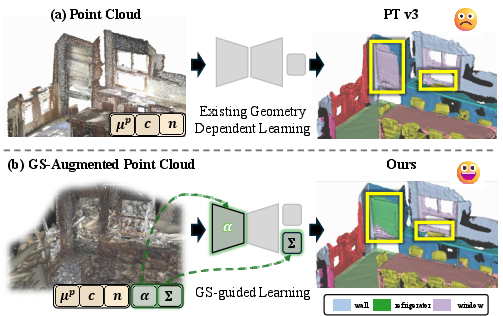
Figure 1: The G2P approach augments standard point clouds with Gaussian attributes, enabling more discriminative segmentation, particularly in scenarios with appearance ambiguity and geometric bias.
Methodology
G2P is structured as a two-stage learning framework encompassing:
- Preparation Stage:
- Feature Augmentation: For each point in the original cloud, G2P finds the best-matched anisotropic GS primitives via Mahalanobis-distance-based neighbor search, aggregating their opacity (α) and scale (S) attributes as weighted features to each point while maintaining geometric fidelity.
- Boundary Extraction: Scale attributes allow for the extraction of boundary pseudo-labels, identifying boundary points by filtering those with low aggregated scale magnitude (after excluding background classes), inherently capturing subtle surface discontinuities and thin or coplanar object edges.
- Appearance Encoder Pre-Training: The Sonata backbone is pre-trained self-supervised, but over augmented features (including opacity), making learned representations intrinsically aware of appearance cues that are consistent across views.
- Main Training Stage:
- GS Appearance Distillation: The pre-trained teacher transfers rich, opacity-guided appearance representations to the point segmentation model via cosine distance minimization, aligning the student’s feature space to one with enhanced material and texture awareness.
- Joint Supervision: Training loss comprises semantic segmentation (cross-entropy and Lovász-softmax), boundary supervision (BCE and Dice), and appearance distillation, with each signal balanced to ensure complementary improvements.
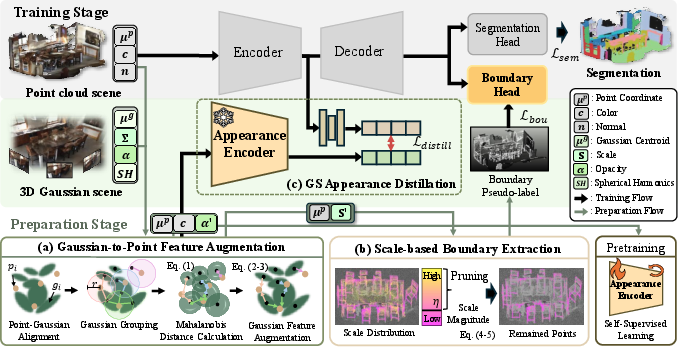
Figure 2: An overview of the G2P pipeline—alignment and augmentation (prep), scale-based boundary extraction, teacher appearance distillation, and joint supervised optimization in the segmentation backbone.
Gaussian-to-Point Alignment
To address GS-induced coordinate drift, the Mahalanobis metric is chosen over the Euclidean for point-Gaussian assignment. This respects the anisotropic spatial support of GS, providing precise, outlier-tolerant correspondence, especially important for boundary regions. G2P aggregates the k nearest neighbors’ attributes to each point with distance-normalized weighting, generating a robust set of appearance- and geometry-enriched features.
Scale-Based Pseudo-Boundaries
Object boundaries manifest as points with locally small scale accumulations, effectively separating object clusters that are geometrically indistinct. A dynamic scale threshold is employed, filtered for object, not background, regions. The resultant pseudo-boundary set is further merged with a semantic-boundary heuristic (neighbor-label disagreement) for reliability.
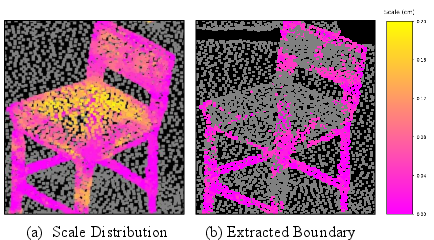
Figure 3: GS scale distribution highlights that small-scale Gaussians concentrate at object boundaries—enabling robust boundary pseudo-label extraction.
Distillation & Training
The network architecture is backbone-agnostic (demonstrated on Point Transformer v3 with BFANet’s B-S block). Appearance distillation aligns features from the augmented (opacity-aware) teacher with the student’s standard (coordinate, color, normal) input using a lightweight MLP, effectively transferring material and reflectance cues absent from raw geometry. Combined with explicit boundary supervision, the segmentation model achieves high fidelity delineation in coplanar and visually-confused regions.
Experimental Results
On ScanNet v2, G2P achieves a mean IoU of 78.4, mAcc of 85.2, and OA of 92.5, exceeding strong geometric and cross-modal fusion baselines, including BFANet and Point Transformer v3 (both at least +1.1 mIoU lower). On the more challenging ScanNet200 (200 categories), G2P attains 36.6 mIoU and 46.0 mAcc, outperforming geometric and self-supervised competitors not using large-scale external pre-training.
Critically, G2P’s largest gains manifest in classes with geometric ambiguity—refrigerators (+6.0 IoU over PT v3), shower curtains (+7.2), and windows, where geometric-only models systematically fail. On ScanNet++ and Matterport3D, G2P demonstrates strong cross-dataset generalization.
Qualitative Analysis
Visually, G2P mitigates both category confusion (mislabeling coplanar or reflective objects) and incomplete segmentation of thin structures, compared to geometric and 2D/3D-fusion baselines. The boundary-aware masks are sharper and more complete, especially on ambiguous object margins.

Figure 4: Qualitative comparison on challenging classes; G2P eliminates geometric bias, resolving both boundary leakage and category confusion prevalent in baselines.
Ablation and Efficiency
Ablations reveal that both appearance distillation and boundary pseudo-labels yield additive improvements; their absence drops IoU by up to 1.4 points. The Mahalanobis metric and moderate neighbor pool (k=20) yield optimal alignment. Training overhead is moderate (67% higher latency, +30% GPU RAM), with inference cost increases negligible, making G2P practical for deployment.
Discussion and Implications
G2P establishes that enriching native 3D point representations with GS-derived opacity and scale attributes is a highly effective strategy for boundary-aware segmentation, outperforming not only geometric pipelines but also those incorporating explicit 2D (image-level) or vision-language modalities. The approach’s explicit spatial correspondence and scale/opacity selection mitigate traditional GS-to-point misalignment, while operating without the need for external cues such as RGB views or large-scale pre-training.
The separation of boundary cues from appearance cues—using scale for edge detection and opacity for material discrimination—represents a more physically plausible and data-efficient division than cross-modal fusion, especially in indoor scene contexts. By retaining geometric fidelity while introducing appearance awareness, the method sidesteps both projection-induced misalignment and label leakage.
Practically, G2P directly improves robot perception, AR/VR scene understanding, and 3D object localization in environments where color or reflectance is a primary differentiator (e.g., appliances, glass surfaces, thin structures). Theoretically, it motivates further work on 3D-native, non-rasterized segmentation pipelines, suggesting that continuous, physically-motivated attributes (e.g., from GS or related radiance field constructs) can be aligned to discrete inputs with high utility.
Conclusion
G2P delivers a compelling advance in 3D semantic segmentation by integrating appearance and geometric information from GS directly into point cloud models. This yields robust, boundary-aware segmentation, especially for cases of geometric ambiguity. Extensive experiments confirm effectiveness across benchmarks and object types. The approach is not only modular and inference-efficient but also highlights the potential of attribute alignment—beyond classic geometric descriptors—in the design of future 3D deep learning architectures.