ETR: Outcome-Guided Elastic Trust Regions for Policy Optimization
Abstract: Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an important paradigm for unlocking reasoning capabilities in LLMs, exemplified by the success of OpenAI o1 and DeepSeek-R1. Currently, Group Relative Policy Optimization (GRPO) stands as the dominant algorithm in this domain due to its stable training and critic-free efficiency. However, we argue that GRPO suffers from a structural limitation: it imposes a uniform, static trust region constraint across all samples. This design implicitly assumes signal homogeneity, a premise misaligned with the heterogeneous nature of outcome-driven learning, where advantage magnitudes and variances fluctuate significantly. Consequently, static constraints fail to fully exploit high-quality signals while insufficiently suppressing noise, often precipitating rapid entropy collapse. To address this, we propose \textbf{E}lastic \textbf{T}rust \textbf{R}egions (\textbf{ETR}), a dynamic mechanism that aligns optimization constraints with signal quality. ETR constructs a signal-aware landscape through dual-level elasticity: at the micro level, it scales clipping boundaries based on advantage magnitude to accelerate learning from high-confidence paths; at the macro level, it leverages group variance to implicitly allocate larger update budgets to tasks in the optimal learning zone. Extensive experiments on AIME and MATH benchmarks demonstrate that ETR consistently outperforms GRPO, achieving superior accuracy while effectively mitigating policy entropy degradation to ensure sustained exploration.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a new way to train reasoning-focused AI models (like math- or code-solving chatbots) using rewards that can be checked automatically (right or wrong). The authors show that a popular training method (called GRPO) uses the same “safety limit” for every learning step, even though some steps have very strong, trustworthy signals and others are noisy or weak. They propose Elastic Trust Regions (ETR), which adjusts that safety limit on the fly based on how good the learning signal is. This helps the model learn faster from good signals while staying stable and exploratory.
Key Objectives
The researchers set out to:
- Explain why using one fixed update limit (a “trust region”) for every example is a bad match for tasks where some signals are strong and others are weak.
- Design a method that gives bigger updates to high-quality signals and smaller updates to noisy ones.
- Prove their idea makes sense mathematically and test it on hard math benchmarks to see if it really works better.
Methods in Simple Terms
Before the method, here are a few key ideas in everyday language:
- Policy: Think of the model’s “policy” as its set of habits for choosing the next word. Training changes these habits.
- Trust region (clipping): A safety rule that says “don’t change your habits too much at once.” GRPO uses the same limit for everyone, like a single speed limit on all roads.
- Advantage: A score that says how helpful a choice was. Big positive advantage means “that was a great move,” big negative means “not good.”
- Group variance and pass rate: For each question, the model tries multiple answers. If about half are correct (pass rate ~50%), the results vary a lot (high variance), meaning there’s a lot to learn.
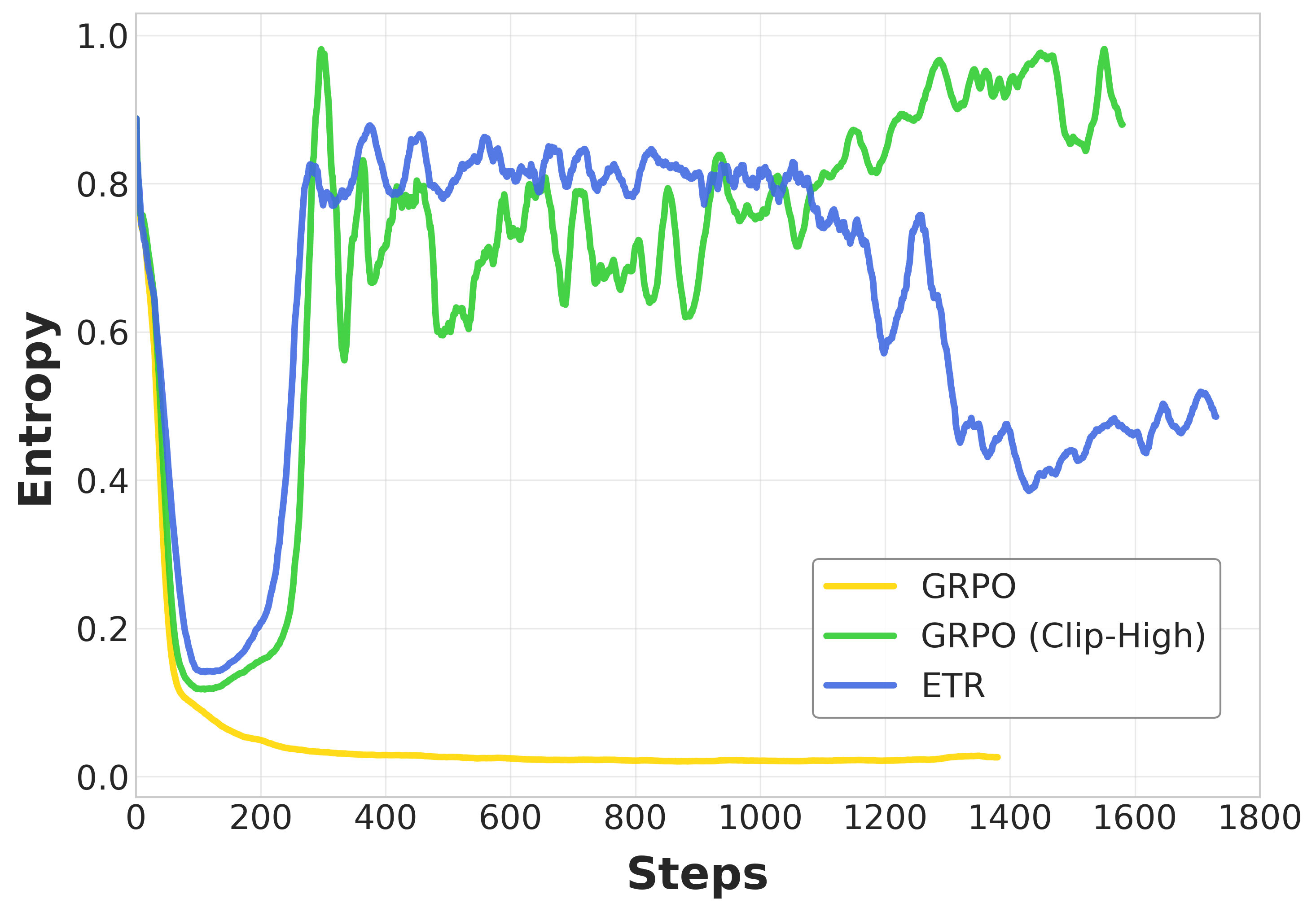
- Entropy: How diverse the model’s answers are. High entropy means lots of exploration; very low entropy means the model is too sure and stops exploring.
What’s wrong today:
- GRPO’s fixed “speed limit” treats all steps the same. But signals are different: some are crystal clear and very valuable; others are confusing or noisy.
- The result: important updates get chopped down too much, and weak or noisy updates aren’t controlled enough. Training can become unstable, and the model can collapse into repeating the same answers (low entropy), hurting exploration.
What ETR does:
- ETR sets a dynamic “speed limit” that stretches or shrinks based on signal quality.
- Micro level (per step/token): If the advantage is strongly positive (a clear success), ETR allows a bigger update. If it’s negative (a mistake), ETR tightens the update to avoid spreading noise. They use a smooth, bounded function (tanh) to keep this safe and stable.
- Macro level (per question/group): If a question’s pass rate is around 50% (most informative), ETR gives a larger update budget. If it’s too easy or too hard (near 0% or 100%), ETR keeps the updates smaller.
- Theory: They show that, in principle, the “right” safe limit should grow with the strength of the signal. ETR follows this principle.
How it plugs in:
- ETR is a simple change to GRPO’s clipping rule. It needs no new networks, adds almost no extra compute, and fits right into existing training code.
Main Findings and Why They Matter
On tough math benchmarks (like AIME and AMC), ETR:
- Improves accuracy over standard GRPO and a stronger baseline that just increases the fixed limit (“Clip-High”).
- Prevents “entropy collapse,” keeping the model exploring instead of getting stuck with narrow, repetitive answers.
- Generalizes better to new kinds of questions (out-of-distribution tests), suggesting it learns deeper reasoning rather than memorizing patterns.
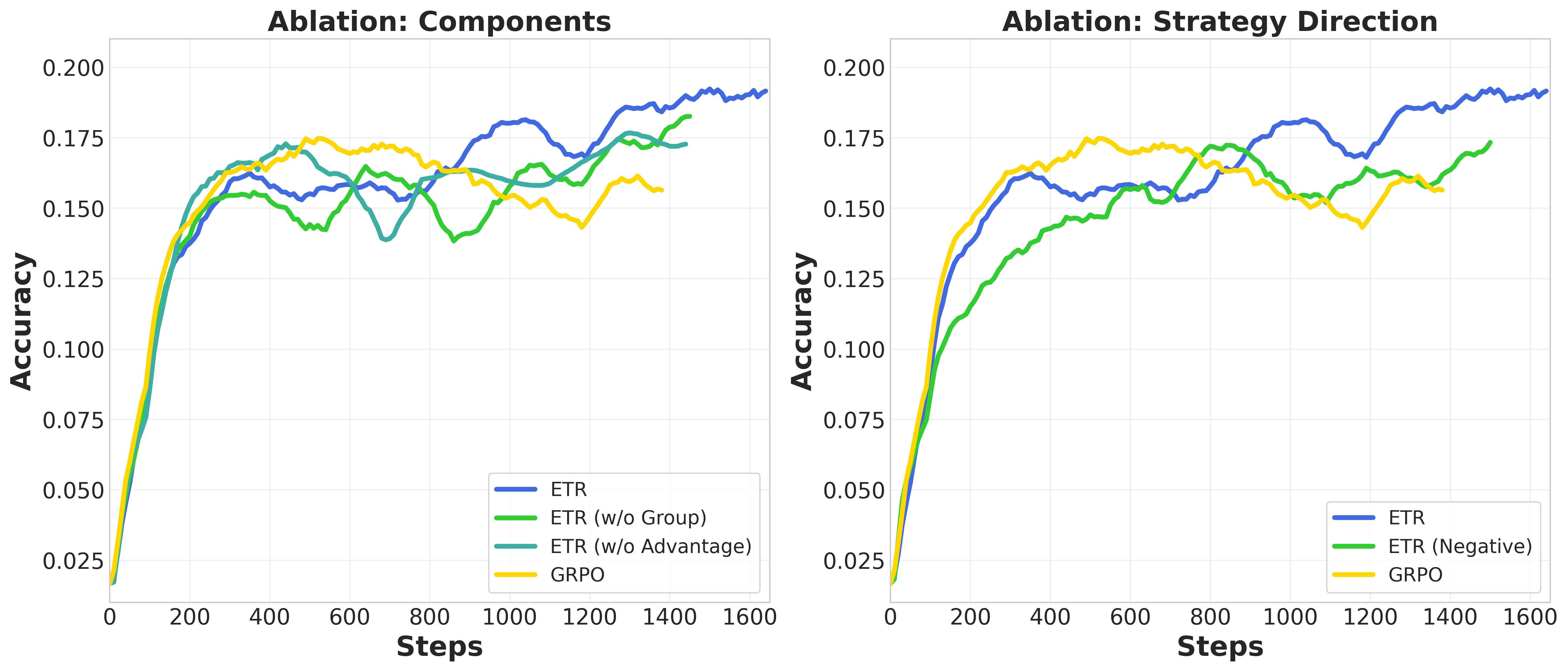
- Ablation tests show both parts matter:
- Micro-level adjustment (per-step advantage) gives the biggest boost.
- Macro-level adjustment (group variance) adds steady gains by focusing on the most informative difficulty zone.
- Reversing the design (loosening for negative signals) hurts performance, confirming the need to be strict with noisy updates.
Why it matters:
- Better scores on hard reasoning tasks mean more reliable math/coding assistants.
- Keeping exploration healthy helps models discover correct solutions that are rare or hidden.
- The method is simple, fast, and easy to adopt.
Implications and Impact
ETR offers a practical, “plug-and-play” upgrade for training reasoning models:
- It adapts learning speed to signal quality, like a smart speed limit that changes with road conditions.
- It helps models learn more from good signals, stay stable on noisy ones, and keep exploring.
- Because it’s lightweight, it can be widely used in future systems that rely on verifiable rewards (e.g., math solvers, code assistants, scientific reasoning tools).
In short, ETR makes training smarter by matching the update size to how trustworthy the learning signal is—leading to stronger, more stable, and more exploratory reasoning models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow-up research:
- Theory–implementation mismatch: Theorem 3.1 prescribes multiplicative scaling of the trust region radius with sqrt-signal (), but the algorithm instantiates an additive rule . The paper does not justify when the additive surrogate preserves the theoretical properties or how to map to the chosen additive form.
- Missing proof details and assumptions: The theorem relies on a second-order local approximation and KL-constrained trust-region analysis, but the paper omits the full derivation, conditions for validity (e.g., smoothness, small-step regime), and how these assumptions relate to the clipped objective actually optimized.
- Clipping–KL objective gap: The theory is framed around a KL-constrained optimization, whereas the method optimizes a clipped surrogate with a separate KL penalty. The paper does not analyze the induced bias from replacing the KL constraint with clipping nor how dynamic clipping interacts with the KL penalty in practice.
- Ambiguity in token-level versus sequence-level advantages: Micro-level elasticity uses in equations, but the final objective uses a sequence-level advantage for all tokens. It remains unclear whether token-level advantages are computed and used, or whether a single is broadcast to all tokens; the impact of this choice on credit assignment is unstudied.
- Unspecified advantage normalization and scale: GRPO “normalizes intra-group rewards,” but the exact normalization (e.g., z-score, min–max, rank) and resulting advantage scale are not specified. Since is sensitive to scale, reproducibility and stability depend on this missing detail.
- No analysis of distribution over training: The paper does not report the empirical distribution of dynamic thresholds (per-token or per-step), making it hard to diagnose whether ETR meaningfully expands/contracts updates or to tune safety bounds.
- Limited hyperparameter robustness evidence: Although λ1 and λ2 are claimed to be robust at 0.1, there is no systematic sweep (e.g., across orders of magnitude) or cross-task sensitivity analysis to demonstrate stability beyond the chosen defaults.
- No ablation of additive vs multiplicative elasticity: The theoretically suggested multiplicative scaling is not compared against the implemented additive rule, leaving performance and stability trade-offs unexplored.
- Small-sample bias in pass-rate estimates: Macro elasticity uses group pass rate with G=8, but the paper does not address estimation noise, confidence intervals, or Bayesian smoothing; robustness to small G and noisy remains unknown.
- Group size sensitivity: ETR’s macro term depends on G; there is no sweep over group sizes to quantify how estimation quality affects performance or stability.
- Potential neglect of very easy/hard items: The macro term vanishes near , which may under-resource extremely hard (or easy) items; there is no curriculum schedule (e.g., annealing λ2) or evidence that very hard tasks eventually get sufficient update budget.
- Interactions with adaptive-KL schemes: The paper fixes β and does not study how ETR behaves with commonly used adaptive β targeting a KL budget, nor whether dynamic clipping plus adaptive KL yields better stability.
- Sampling temperature effects: Experiments fix temperature=1.0; the interaction between dynamic clipping and sampling temperature (training and inference) is not investigated.
- Inference budget sensitivity: Results report Mean@32/Best@32, while training uses G=8; the paper does not analyze how ETR scales with different inference sample budgets (e.g., k ∈ {1,4,8,16,64}).
- Missing runtime and throughput measurements: The “zero overhead” claim lacks wall-clock, FLOPs, and throughput comparisons; potential memory or compute overhead from per-token dynamic thresholds is not quantified.
- Statistical significance and reproducibility: Results appear single-seed with no confidence intervals; multi-seed variance, run-to-run stability, and significance tests are absent.
- Baseline coverage: Comparisons omit strong adaptive-baseline variants (e.g., PPO with adaptive KL penalty, TRPO/TRPO-penalty, Trust Region Adaptive Policy Optimization, advantage clipping/normalization alternatives), leaving it unclear whether ETR surpasses state-of-the-art dynamic-trust-region methods.
- Domain generality: Evaluation is math-centric; applicability to other RLVR domains (e.g., program synthesis with partial-credit test suites, formal proofs, reasoning on noisy verifiers) is untested.
- Non-binary/graded rewards: ETR is evaluated with +1/−1 rewards; behavior under graded or continuous verifiable rewards (e.g., pass@k fractions, partial unit tests) is unstudied.
- Robustness to verifier noise and reward hacking: Although RLVR rewards are verifiable, real-world verifiers can be imperfect or exploitable; the safety of expanding trust regions on “high-confidence” but spurious positives is not assessed.
- Token criticality and sparse credit: ETR adjusts bounds per token without distinguishing critical reasoning steps from boilerplate tokens; methods that weight elasticity by token salience (e.g., entropy/gradient norms/attribution) are unexplored.
- KL-to-reference design choices: The impact of the reference model choice and alternative divergence metrics (e.g., reverse KL, symmetrized KL, χ² divergence) on ETR’s stability and exploration is not analyzed.
- Failure mode analysis: The paper lacks granular error analyses (where ETR underperforms or destabilizes), especially on negative samples and high-frequency tokens that might amplify diffusion noise.
- Scaling to larger models and longer horizons: Experiments are limited to ~7–8B models; whether ETR’s benefits persist (or amplify) at 34B/70B scales and on longer reasoning chains remains open.
- Code-level reproducibility details: Precise pseudocode, advantage normalization formulae, KL computation granularity (per-token vs sequence), entropy computation protocol, and evaluation scripts are not provided, hindering exact replication.
- Editorial/consistency issues: Several formula typos and a figure placeholder (“{paper_content}”) suggest documentation gaps; ensuring mathematical and implementation consistency would aid adoption.
Practical Applications
Immediate Applications
Below are deployable use cases that leverage ETR’s outcome-guided, dynamic trust regions to improve RL with verifiable rewards (RLVR) for reasoning LLMs and related systems.
- Higher-reliability math tutors and graders
- Sector: Education
- What: Fine-tune math tutors/graders on datasets with auto-checkable answers (e.g., AIME/MATH) using ETR to capture sparse high-value signals while preserving exploration.
- Tools/workflows: RLFT pipeline with GRPO+ETR; entropy monitors; multi-sample inference (Best@k) for solution diversity.
- Assumptions/dependencies: Verifiable ground truth; sufficient group sampling (G≥8); stable KL regularization; GPU budget for RLFT.
- Test-driven code assistant training
- Sector: Software
- What: Train coding models with unit/integration tests as rewards; ETR relaxes updates on high-confidence passes and constrains noisy failures.
- Tools/workflows: CI-integrated RLFT harness (vLLM/trlx/verl), dynamic clipping logs, pass-rate tracing for p_g.
- Assumptions/dependencies: High-quality, deterministic tests; sandboxing; reliable coverage; reproducible environments.
- Program repair and auto-patching
- Sector: Software/DevOps
- What: RLVR on failing tests as negative rewards and fixed tests as positives; ETR prevents entropy collapse during exploration of candidate patches.
- Tools/workflows: Patch generation loop with regression suites; ETR-based clipping; best-of-n candidate evaluation.
- Assumptions/dependencies: Rich regression suites; controlled side effects; reproducible builds.
- Formal theorem proving with proof checkers
- Sector: Software verification/Research
- What: Train LLM provers with verifiable rewards from proof assistants (Lean/Isabelle/Coq); ETR helps learn from rare valid proof paths.
- Tools/workflows: RL rollouts validated by proof checker; micro-level adjustment via advantage magnitude.
- Assumptions/dependencies: Proof-checker integration; curated problem sets; sufficient sampling.
- Schema- and rule-verified information extraction
- Sector: Finance, Healthcare, Legal
- What: Fine-tune extractors to emit structured outputs validated by schema/rules (reward=pass/fail); ETR curbs spurious updates on invalid samples.
- Tools/workflows: Validator-as-reward; GRPO+ETR; OOD checks to monitor generalization.
- Assumptions/dependencies: High-precision validators; de-identification/privacy guardrails; robust normalization.
- Safer, more stable reasoning agents for enterprise Q&A
- Sector: Enterprise AI
- What: Use ETR to maintain healthy policy entropy during RLVR, improving OOD robustness (e.g., GPQA-like tasks).
- Tools/workflows: Entropy dashboards; curriculum-like sampling based on pass-rate variance.
- Assumptions/dependencies: Tasks with objectively checkable responses; reliable reference model and KL settings.
- Cost- and time-efficient model post-training
- Sector: AI infrastructure/Platform
- What: Reduce late-stage instability and restarts by swapping static clipping with ETR; same compute graph, negligible overhead.
- Tools/workflows: Drop-in ETR module for PPO/GRPO objectives; default λ1=λ2≈0.1; automated early-stopping on entropy collapse.
- Assumptions/dependencies: Existing GRPO-style setup; monitoring and logging; modest hyperparameter tuning.
- Implicit curriculum without extra supervision
- Sector: Academia/Industry labs
- What: Use group pass-rate variance p_g(1−p_g) for dynamic update budgets—data batches near 50% pass receive larger steps.
- Tools/workflows: Batch-level variance tracking; sampling orchestrators prioritizing “learning zone” prompts.
- Assumptions/dependencies: Grouped sampling per prompt; stable variance estimates per batch.
- Benchmarked improvement in small/medium models
- Sector: Model distillation/pruning
- What: Train compact reasoning models (7B–8B class) to higher accuracy using ETR to exploit rare high-advantage signals.
- Tools/workflows: RLVR fine-tuning on curated datasets (e.g., DAPO-Math), model selection by Best@k.
- Assumptions/dependencies: Curated verifiable tasks; consistent advantage normalization within groups.
- Research baselines and ablations
- Sector: Academia
- What: Adopt ETR as a standard baseline for RLVR algorithm studies (entropy dynamics, curriculum effects).
- Tools/workflows: Open-source ETR loss variants; micro/macro ablations; negative-control “inverse” strategies for robustness checks.
- Assumptions/dependencies: Access to training code; compute for systematic studies; reproducible seeds.
Long-Term Applications
The following applications require further research, integration, or scaling of ETR beyond current RLVR reasoning settings.
- Uncertainty-aware RLHF/RLAIF
- Sectors: Alignment, General LLM training
- What: Extend ETR by setting the scaling factor via reward model uncertainty or ensemble variance (ρ_t from epistemic uncertainty).
- Tools/workflows: Calibrated reward-model uncertainty; dynamic trust regions coupled with KL penalties.
- Assumptions/dependencies: Reliable uncertainty estimates; mitigation of reward hacking; additional modeling overhead.
- Robotics and continuous control
- Sectors: Robotics, Industrial automation
- What: Translate ETR’s dynamic trust region to PPO/TRPO in continuous control; micro-level via advantage magnitude (GAE), macro-level via success variance across tasks/scenarios.
- Tools/workflows: Simulators (Isaac Gym/Mujoco) with success/failure metrics; safety-aware clipping schedules.
- Assumptions/dependencies: Stable variance estimation; safe exploration policies; sim-to-real transfer.
- Simulation-verified decision-making for grid/traffic/logistics
- Sectors: Energy, Mobility, Operations
- What: Use simulation verifiers (power flow, traffic simulators, digital twins) to drive RLVR; ETR improves sample efficiency and prevents premature mode collapse.
- Tools/workflows: Batch evaluation harnesses; variance-based curriculum across scenarios.
- Assumptions/dependencies: High-fidelity simulators; differentiable or stable-black-box evaluation; compute for large rollouts.
- Financial strategy generation with robust backtesting gates
- Sector: Finance
- What: Train agents using backtest/verifier pipelines as reward; ETR helps maintain exploration while avoiding over-optimization to specific regimes.
- Tools/workflows: Rolling-window backtests; leakage-guard workflows; dynamic clipping tied to out-of-sample variance.
- Assumptions/dependencies: Realistic transaction costs/slippage; strict data splitting; governance and compliance.
- Verified clinical calculators and order-set reasoning
- Sector: Healthcare
- What: RLVR on rule-based, guideline-verified subtasks (e.g., dose calculators, contraindication checks) to build reliable micro-reasoners; ETR stabilizes training.
- Tools/workflows: Medical knowledge bases and validators; EHR sandbox evaluation; stepwise reasoning scaffolds.
- Assumptions/dependencies: Regulatory approval; rigorous clinical validation; robust guardrails and oversight.
- Compiler and system optimization agents
- Sector: Systems/Platform engineering
- What: Agents proposing compiler flags, schedule choices, or caching strategies with performance regression tests as verifiers; ETR scales updates on informative benchmarks.
- Tools/workflows: Benchmark harness pipelines; performance variance–aware macro scaling.
- Assumptions/dependencies: Reproducible performance measurement; hardware heterogeneity handling; long-run stability.
- Auto-curriculum orchestrators for RL training
- Sector: MLOps/Training platforms
- What: Generalize ETR’s macro variance principle to schedule data, sampling temperature, and compute budgets across tasks whose pass-rates indicate “learning zone.”
- Tools/workflows: Training orchestrators that track pass-rate distributions; adaptive batch constructors.
- Assumptions/dependencies: Accurate pass-rate telemetry at scale; prevention of catastrophic forgetting.
- Safety-focused entropy regularization
- Sector: AI safety
- What: Leverage ETR’s entropy stabilization to mitigate mode collapse and brittle behaviors; tie deployment gates to entropy and verification metrics.
- Tools/workflows: Safety dashboards correlating entropy trends with failure modes; alarms on collapse or chaotic exploration.
- Assumptions/dependencies: Proven linkage between entropy and safety outcomes; domain-specific red-teaming.
- Cross-domain generalist reasoning agents with verifiers
- Sectors: Multimodal assistants, Enterprise automation
- What: Build agents that solve heterogeneous tasks with task-specific verifiers (math, code, data cleaning, scheduling); ETR harmonizes updates across variable-signal domains.
- Tools/workflows: Modular “verifier registry”; per-domain variance profiles for macro scaling.
- Assumptions/dependencies: Coverage of verifiers; unified logging and reward schema; interference management across domains.
- Methodological standardization and policy guidance
- Sector: Policy/Standards
- What: Codify best practices for outcome-adaptive trust regions in RL post-training to reduce overfitting, improve robustness, and enable reproducibility.
- Tools/workflows: Benchmark suites with required verification harnesses; reporting of entropy dynamics and clipping budgets.
- Assumptions/dependencies: Community consensus; alignment with risk and audit requirements.
Notes on feasibility and transfer
- ETR is most impactful when rewards are objectively verifiable (tests, checkers, validators, simulators). Domains lacking such signals require additional work (e.g., calibrated uncertainty).
- Integration is simplest in GRPO-like pipelines; applying to value-based or off-policy RL needs adaptation and validation.
- Macro-level benefits rely on accurate pass-rate estimation per group; extremely small groups or highly imbalanced tasks may reduce the effectiveness of variance-based scaling.
- Safe deployment in high-stakes sectors (finance, healthcare, robotics) requires rigorous governance, bias and safety audits, and robust out-of-distribution evaluation.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update, improving training stability. "All models are trained using the AdamW optimizer."
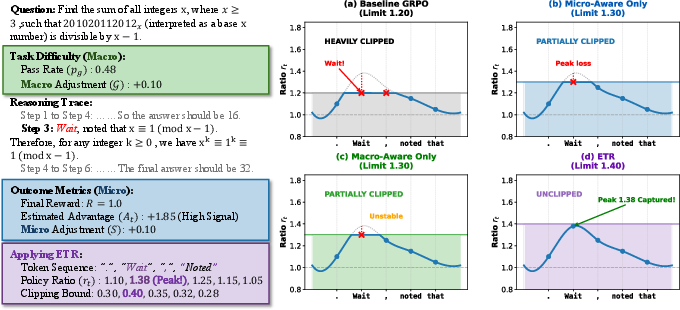
- Advantage: In reinforcement learning, a measure of how much better an action is compared to a baseline, guiding the magnitude and direction of policy updates. "advantage magnitudes and variances fluctuate significantly."
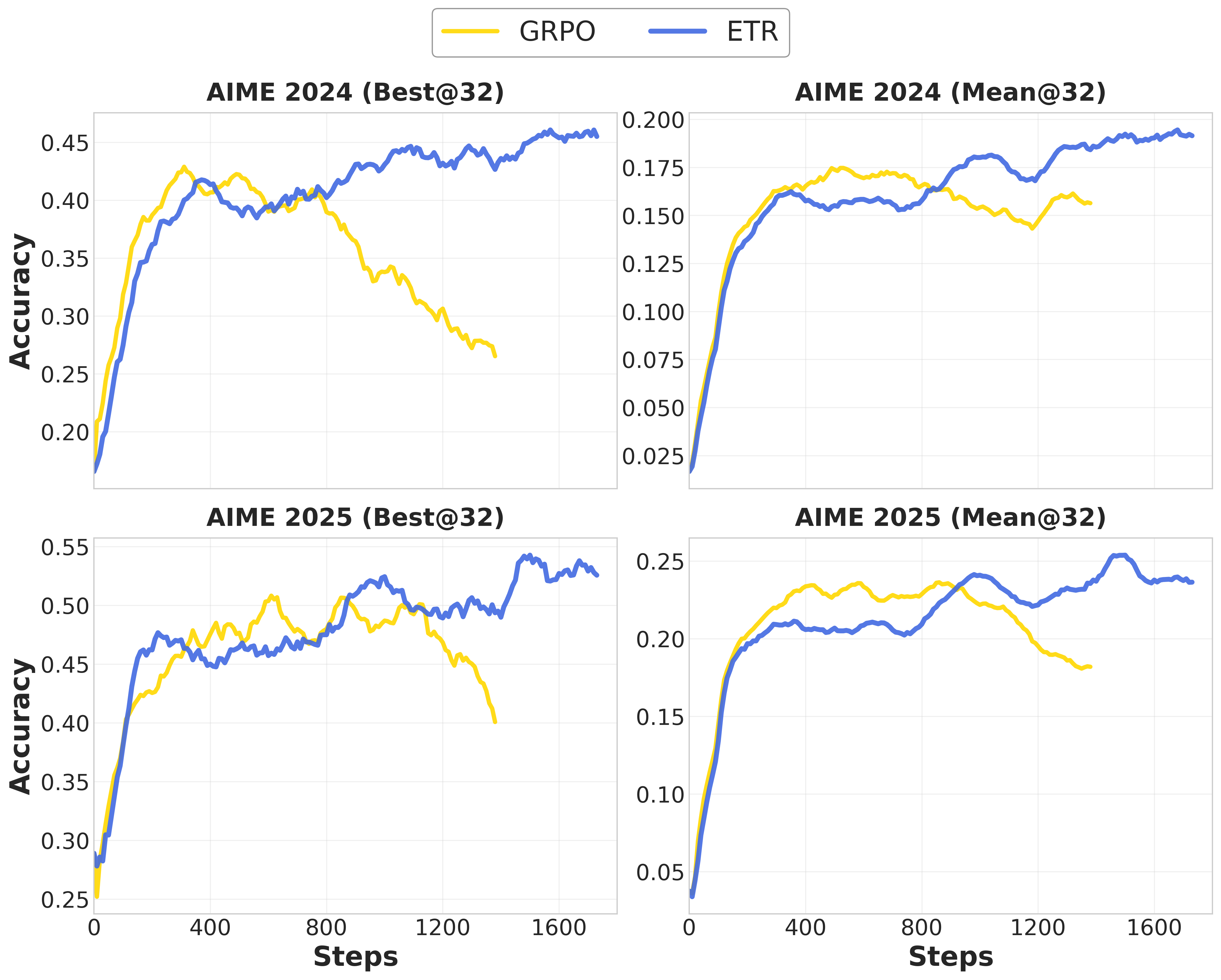
- Best@32: A metric that records the best accuracy achieved among 32 sampled responses per query. "we report both Mean@32 and Best@32 accuracy to measure average performance and exploration ceilings, respectively."
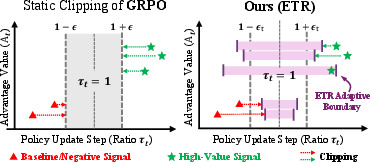
- Clipped surrogate objective: The PPO-style objective that limits the probability ratio to a fixed range to stabilize training. "It employs a clipped surrogate objective to prevent destructive large updates."
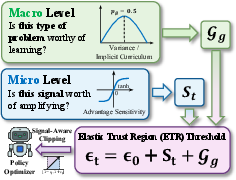
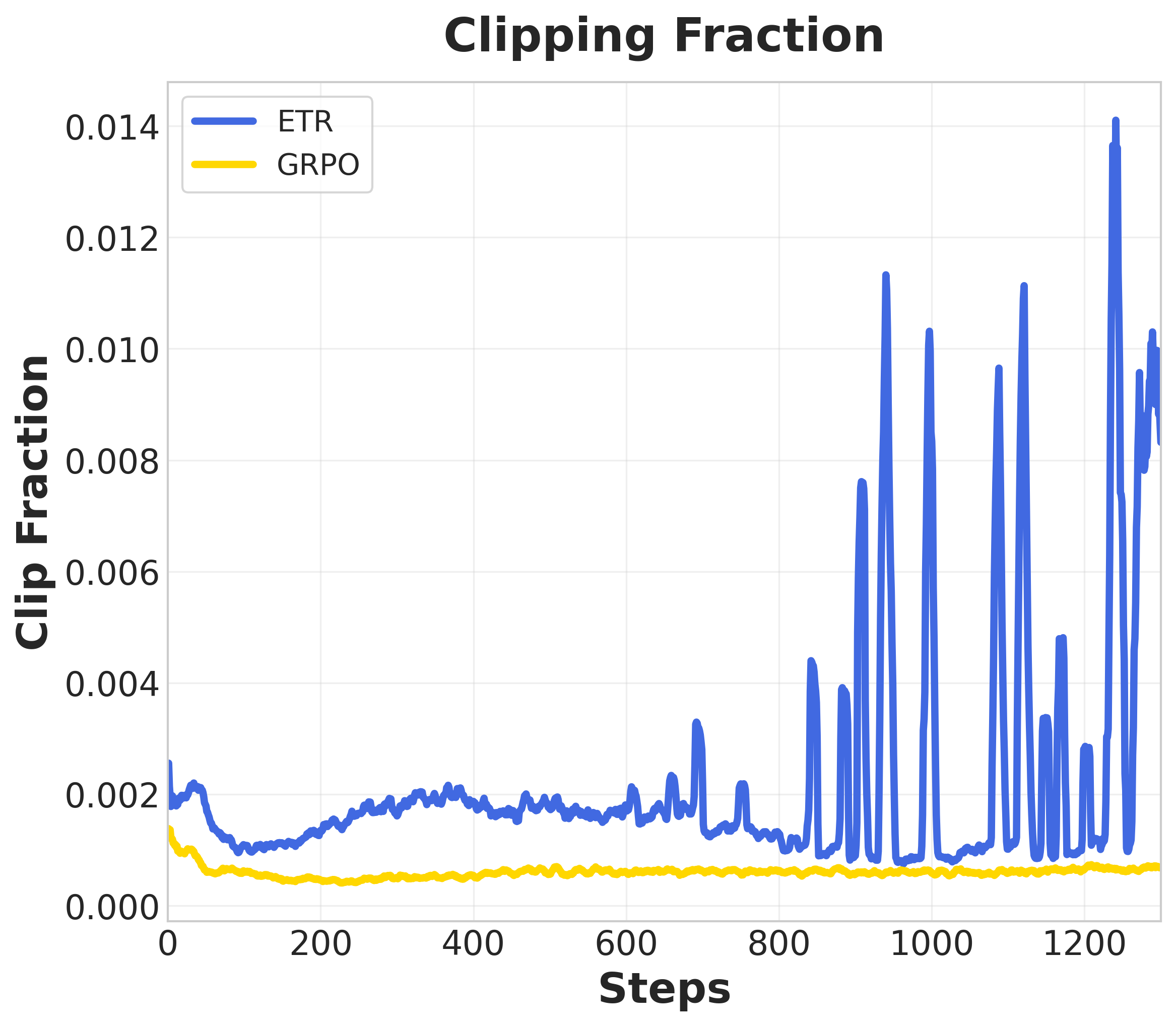
- Clipping boundaries: Upper and lower limits applied to the probability ratio to enforce a trust region in PPO/GRPO. "it scales clipping boundaries based on advantage magnitude to accelerate learning from high-confidence paths"
- Clipping threshold: The epsilon parameter that defines the width of the trust region for clipping the probability ratio. "Instead of enforcing a fixed clipping threshold, ETR adjusts the effective trust region based on both sample-level advantages and group-level variance."
- Critic-free: Policy optimization without an explicit value function network (critic), reducing computation. "due to its stable training and critic-free efficiency."
- Elastic Trust Regions (ETR): A dynamic trust-region mechanism that adapts clipping bounds to signal quality at both sample and group levels. "we propose Elastic Trust Regions (ETR), a dynamic mechanism that aligns optimization constraints with signal quality."
- Entropy collapse: A rapid decline of policy entropy toward zero, causing overly deterministic behavior and reduced exploration. "rapid entropy collapse."
- FSDP: Fully Sharded Data Parallel, a distributed training technique that shards model parameters across devices. "utilizing FSDP for training and vLLM for inference on 8H20 GPUs."
- Generalized Advantage Estimation (GAE): A method to compute advantages with a bias-variance trade-off using exponentially weighted returns. "utilizes Generalized Advantage Estimation (GAE)~\cite{schulman2015high} to balance bias and variance."
- Group Relative Policy Optimization (GRPO): A policy optimization method that normalizes rewards within sampled groups and uses clipping without a value network. "Group Relative Policy Optimization (GRPO) stands as the dominant algorithm in this domain due to its stable training and critic-free efficiency."
- Group variance: Variance of outcomes within a group, often proportional to p(1−p), indicating information density for learning. "it leverages group variance to implicitly allocate larger update budgets to tasks in the optimal learning zone."
- Implicit Curriculum Learning: Automatic prioritization of moderately difficult data (high variance) by allocating larger update budgets to such groups. "This introduces an Implicit Curriculum Learning mechanism: the algorithm automatically allocates a larger update budget to tasks within the ``optimal learning zone'' (high variance)"
- KL divergence: A measure of difference between probability distributions used to constrain policy updates for stability. "with a KL divergence penalty "
- KL regularization term: A penalty encouraging the current policy to remain close to a reference model. "and ii) a KL penalty term (to keep the policy close to the reference model )"
- Lagrangian dual: The dual formulation of a constrained optimization problem used to derive optimal conditions. "By solving the Lagrangian dual of this constrained optimization problem, we derive the optimal form of the clipping boundary."
- Macro-Level Adjustment: ETR’s group-level scaling based on pass-rate variance to allocate update budgets to informative groups. "Macro-Level Adjustment ()."
- Mean@32: Average accuracy measured over 32 sampled responses per query. "we report both Mean@32 and Best@32 accuracy"
- Micro-Level Adjustment: ETR’s sample-level scaling based on advantage magnitude and sign to adjust bounds for positive/negative signals. "Micro-Level Adjustment ()."
- Out-of-Distribution (OOD): Data that differs from the training distribution, used to evaluate generalization. "To evaluate generalization capabilities, we employ out-of-distribution (OOD) benchmarks including GPQA-Main, GPQA-Diamond~\cite{rein2024gpqa}, and ACPBench~\cite{kokel2024acp}, reporting Pass@1 accuracy."
- Pass@1: Accuracy metric measuring whether a single sampled response per query is correct. "reporting Pass@1 accuracy."
- Policy diversity: The variety in a policy’s generated responses, linked to exploration and generalization. "analyze their impact on policy diversity and learning efficiency."
- Policy entropy: Entropy of the policy’s token distribution, indicating the level of exploration vs. determinism. "effectively mitigating policy entropy degradation to ensure sustained exploration."
- Policy ratio: The trajectory or value of the ratio between current and old policy probabilities across training steps. "We visualize the policy ratio trajectory for a critical step that requires a large update ()."
- Probability ratio: The ratio of current to old policy probabilities for an action/state, central to PPO/GRPO objectives. "where $r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}(a_t|s_t)}$ is the probability ratio."
- Proximal Policy Optimization (PPO): A policy optimization algorithm that stabilizes updates via clipping within a trust region. "Proximal Policy Optimization (PPO)."
- Reference model: A fixed model toward which the current policy is regularized using KL divergence. "towards the reference model "
- Reinforcement Learning from Human Feedback (RLHF): RL paradigm where a learned reward model approximates human preferences to guide training. "Reinforcement Learning from Human Feedback (RLHF)~\cite{schulman2017proximal}, where a learned reward model approximates human preferences and guides policy optimization."
- Reinforcement Learning with Verifiable Rewards (RLVR): RL paradigm using rewards derived directly from ground-truth outcomes, enabling precise signals. "Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an important paradigm for unlocking reasoning capabilities in LLMs"
- Signal-Aware Weighted Constraint: A constraint framework that scales KL penalties by a per-token signal quality factor. "we propose to replace the uniform trust region assumption with a Signal-Aware Weighted Constraint."
- Static Mismatch: Misalignment between fixed clipping bounds and heterogeneous training signals that reduces learning efficiency. "We formalize this structural inefficiency as the Static Mismatch:"
- Taylor expansion: Series approximation technique used to derive local objectives and optimal update steps. "is approximated via a second-order Taylor expansion as ."
- Trust Region Policy Optimization (TRPO): A trust-region method that enforces explicit KL constraints for stable policy updates. "TRPO~\cite{schulman2017trustregionpolicyoptimization} enforces an explicit constraint on policy updates via KL divergence"
- Trust region: A bounded region restricting policy updates to maintain stability during optimization. "PPO~\cite{schulman2017proximal} stabilizes training by constraining policy updates within a trust region."
- vLLM: An optimized inference framework for serving LLMs efficiently. "utilizing FSDP for training and vLLM for inference on 8H20 GPUs."
- Value function: The critic estimating expected returns, used to compute advantages in actor-critic methods. "a learned value function "
Collections
Sign up for free to add this paper to one or more collections.