- The paper introduces a training-free RAG framework that leverages uncertainty-guided retrieval triggering and dual-path retrieval to significantly boost QA accuracy.
- It combines query-based and pseudo-context retrieval with adaptive information selection to overcome semantic drift and improve recall, EM, and F1 scores.
- Empirical results across benchmarks like SQuAD and HotpotQA confirm the framework's effectiveness, offering reduced latency and lower retrieval engine load.
Decide Then Retrieve: A Training-Free Framework with Uncertainty-Guided Triggering and Dual-Path Retrieval
Motivation and Problem Analysis
Recent advancements in RAG architectures have demonstrated measurable gains over parametric-only LLM generation when accessing external corpora. However, contemporary RAG systems suffer from crude retrieval heuristics, indiscriminately retrieving for all queries and inducing performance regression on questions readily answerable from model weights. Furthermore, query-based retrieval is brittle under sparse queries, with high mismatch rates between user queries and ground truth (GT) contexts and semantic drift in retrievals. To address these issues, "Decide Then Retrieve" (DTR) (2601.03908) rethinks retrieval as an adaptive, conditional module, and proposes a two-pronged architecture: uncertainty-guided retrieval triggering and dual-path retrieval with adaptive information selection (AIS).
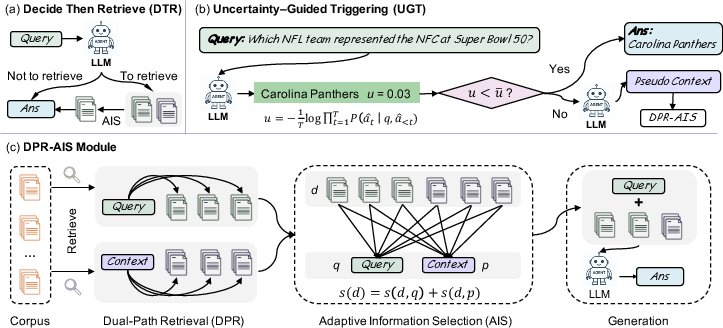
Figure 1: Overview of the DTR framework comprising (a) adaptive retrieval and selection, (b) retrieval triggering based on uncertainty score, and (c) dual-path retrieval with adaptive fusion for generation.
The paper first decomposes RAG performance as a function of parametric, retrieval, and conditional generation probabilities for a given query q, denoting the likelihood of parametric success as Pparam, retrieval success as Pret, and generation robustness as Pgen. Retrieval is only beneficial when Pret⋅Pgen>Pparam, which motivates the need for dynamic retrieval triggering mechanisms to avoid degradation in easy cases, and improved retrieval paths in cases where semantic signal is weak or ambiguous.
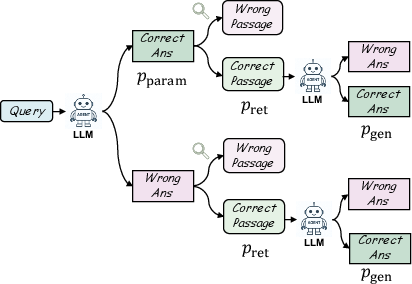
Figure 2: The accuracy analysis framework for RAG, illustrating when retrieval aids or degrades response accuracy.
Uncertainty-Guided Triggering (UGT)
UGT leverages the internal uncertainty of LLM outputs to drive the retrieval decision process. The token-wise negative log-likelihood is normalized as an uncertainty metric. Empirical analysis demonstrates strong monotonicity between model uncertainty and answer accuracy: low-uncertainty generations are accurate, while higher uncertainty corresponds to parametric failure. By selecting a threshold u, only queries with uncertainty above u trigger external retrieval, allowing the architecture to avoid submitting solvable cases to noisy corpus retrieval.
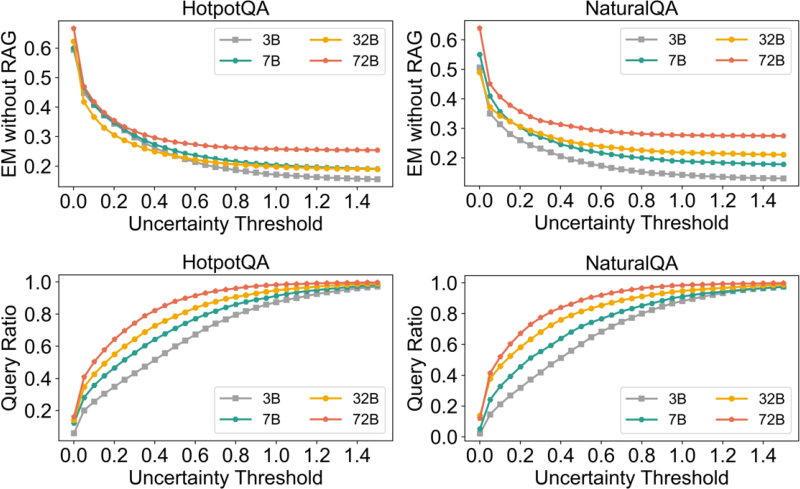
Figure 3: Relationship between generation uncertainty, parametric accuracy, and query coverage for Qwen2.5 models.
To resolve the limitations of single-path query-based retrieval, DTR introduces dual-path retrieval, which supplements traditional query-based retrieval with an LLM-generated pseudo-context path. The two retrieval sets are merged and reranked using AIS, which jointly scores each candidate by its embedding similarity to both the original query and the pseudo-context. Importantly, AIS utilizes not only additive similarity but also the cosine of the combinatorial angle to penalize drift, enforcing that top documents must be semantically compatible with both sources.
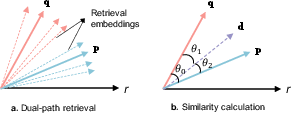
Figure 4: (a) Dual-path retrieval mechanism and (b) joint similarity computation between retrieved chunks, queries, and generated pseudo-contexts.
Empirical analysis shows that query-based retrieval often misses relevant GT documents due to embedding misalignment (Figure 5 and 8), while pseudo-context-based retrieval bridges this gap, especially for multi-hop or factoid QA, reflecting improved recall@3 and EM/F1 metrics.
Experimental Results and Ablations
DTR is evaluated on five QA benchmarks, including NaturalQA, HotpotQA, SQuAD, TriviaQA, and WebQuestions, using Qwen2.5-7B and Qwen2.5-72B models as generators. Across all tasks and both scales, DTR yields best-or-second-best results in both EM and F1, outperforming all static and heuristic retrieval baselines. Typical gains over standard RAG exceed 2 EM / 2 F1 points even on large models.
The ablation study reveals both UGT and dual-path AIS are indispensable: turning off UGT induces accuracy regression due to noisy retrieval on easy questions, while reverting to single-path retrieval severely degrades performance. Fixed retrieval ratios (e.g., static mixture of query and pseudo-context) also underperform, confirming the need for adaptive selection.
Notably, uncertainty scaling analysis (Figure 6) establishes that retrieval negatively impacts accuracy for low-uncertainty queries, but increasingly benefits higher uncertainty cases, demonstrating that dynamic triggering is required for optimality.
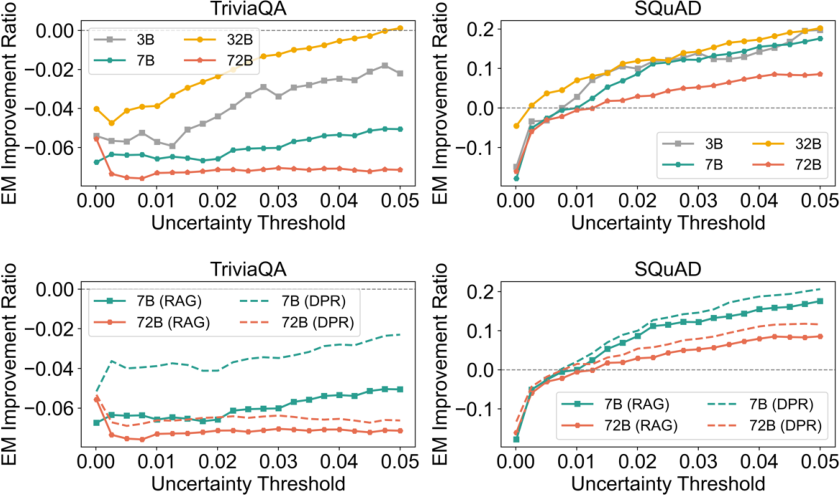
Figure 6: EM improvement as a function of uncertainty, model size, and retrieval mechanism.
Case Analysis and Additional Findings
Empirical case studies (Figure 7) reinforce the core claim: triggering retrieval in cases with clear parametric support injects noise and degrades accuracy, whereas DTR’s selective mechanism avoids this pitfall. Spatial analysis of embedding projections demonstrates that pseudo-context-path retrievals fill the semantic gaps of sparse queries (Figures 9 and 10), supporting the dual-path hypothesis from both retrieval recall and alignment perspectives.

Figure 7: Comparison between uncertainty-guided triggering and standard RAG for a representative query.
Implications and Future Directions
DTR imposes minimal assumptions: it is training-free, model-agnostic, and deployable with any retriever/corpus. It makes a contradictory claim to much of RAG’s status quo: that retrieval is frequently harmful unless invoked adaptively, and that naive query expansion can amplify, rather than suppress, noise. Practically, this yields lower system latency for many cases (via retrieval bypass), reduced retrieval engine load, and higher accuracy on both sparse and ambiguous queries.
There remain open questions on the reliability of uncertainty estimates under non-greedy decoding strategies, applicability to multi-step reasoning pipelines, and corpus-specific challenges. Future work may investigate more sophisticated pseudo-context generation, adaptive reranking algorithms, or regret-minimizing retrieval triggering policies with user feedback.
Conclusion
DTR redefines retrieval as a conditional, uncertainty-driven module and establishes dual-path retrieval with adaptive selection as critical for robust RAG performance. The architecture yields consistently higher EM/F1 metrics across diverse regimes, and reframes when and how retrieval should be integrated into advanced LLM systems. This work provides a modular, theoretically justified, and empirically validated framework for adaptive retrieval-augmented generation that can be productively extended in future RAG research.