Klear: Unified Multi-Task Audio-Video Joint Generation
Abstract: Audio-video joint generation has progressed rapidly, yet substantial challenges still remain. Non-commercial approaches still suffer audio-visual asynchrony, poor lip-speech alignment, and unimodal degradation, which can be stemmed from weak audio-visual correspondence modeling, limited generalization, and scarce high-quality dense-caption data. To address these issues, we introduce Klear and delve into three axes--model architecture, training strategy, and data curation. Architecturally, we adopt a single-tower design with unified DiT blocks and an Omni-Full Attention mechanism, achieving tight audio-visual alignment and strong scalability. Training-wise, we adopt a progressive multitask regime--random modality masking to joint optimization across tasks, and a multistage curriculum, yielding robust representations, strengthening A-V aligned world knowledge, and preventing unimodal collapse. For datasets, we present the first large-scale audio-video dataset with dense captions, and introduce a novel automated data-construction pipeline which annotates and filters millions of diverse, high-quality, strictly aligned audio-video-caption triplets. Building on this, Klear scales to large datasets, delivering high-fidelity, semantically and temporally aligned, instruction-following generation in both joint and unimodal settings while generalizing robustly to out-of-distribution scenarios. Across tasks, it substantially outperforms prior methods by a large margin and achieves performance comparable to Veo 3, offering a unified, scalable path toward next-generation audio-video synthesis.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “Unified Multi-Task Audio-Video Joint Generation” (Klear)
1) What is this paper about?
This paper introduces Klear, an AI system that can create video and audio together so they match perfectly. Think of it like a smart movie-maker: you can give it text, an image, or both, and it can produce a video with sound where the music, sound effects, and speech line up exactly with what you see on screen (like lips moving in sync with words).
2) What questions were they trying to answer?
The team wanted to fix common problems in AI video+audio creation:
- How can we make the sound and the picture stay in sync, especially for lip movements and speech?
- How can one model handle many tasks (text-to-video, text-to-audio, text-to-audio+video, image-to-video, image-to-audio+video) without getting worse at any of them?
- How do we train such a model so it understands the world well and works on new kinds of inputs it hasn’t seen before?
3) How did they do it?
They improved three things at the same time: the model’s design, how it is trained, and the data it learns from.
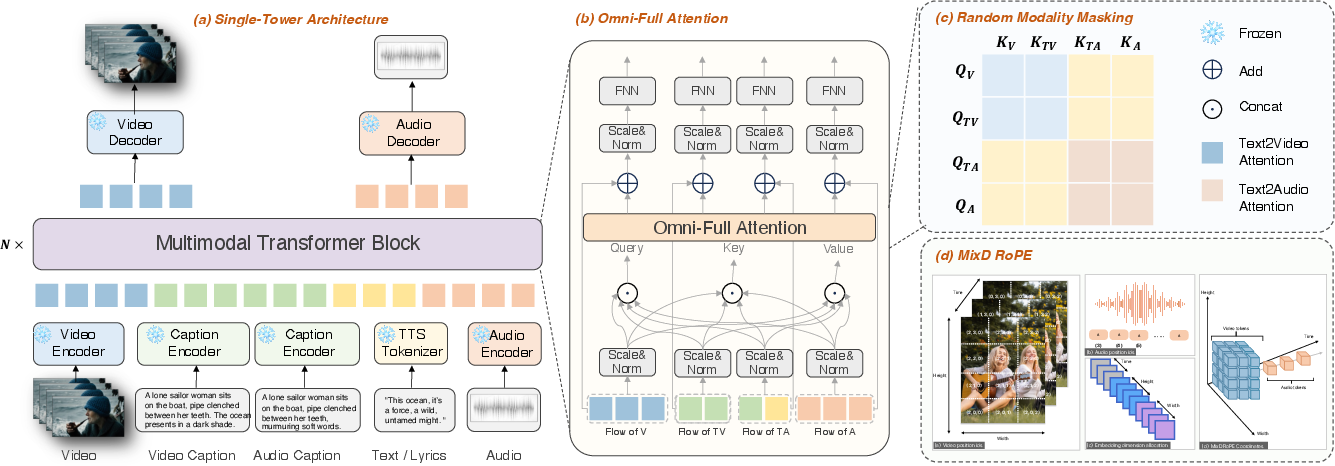
- One “brain” for everything (Single-Tower with “Omni-Full Attention”)
- Many past systems use two separate “brains” (one for audio, one for video) and try to stitch them together later. That often causes misalignment.
- Klear uses one shared “brain” where audio, video, and their texts all sit at the same table and talk to each other at every step. The authors call this Omni-Full Attention: every part can “listen” to every other part, so timing and meaning stay aligned.
- Better “where and when” sense (Mixed-Dimension Position Tags)
- Videos have width, height, and time; audio has time. Klear gives both audio and video strong “position tags” (like timestamps and map coordinates), and they share the same timeline. This helps the model know exactly what should happen when, which improves sync.
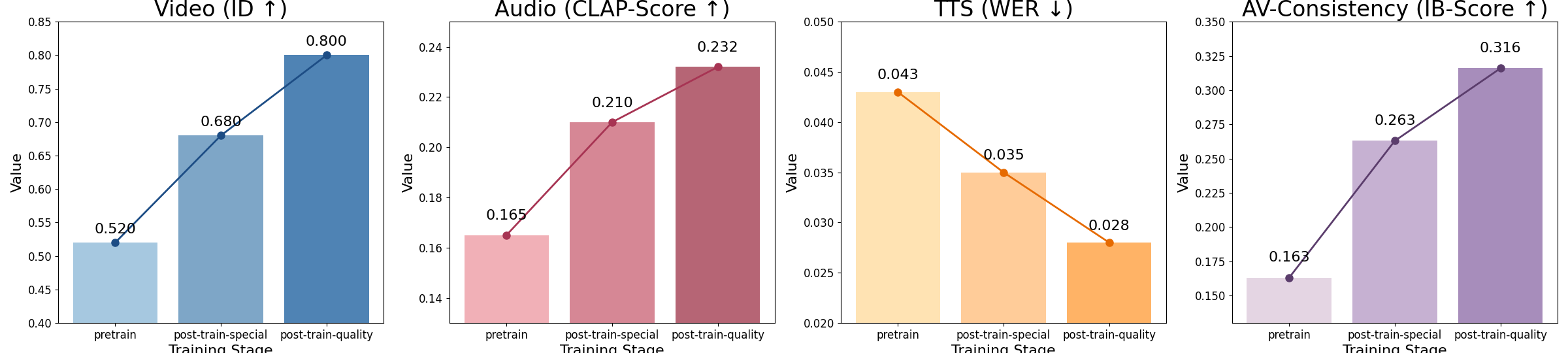
- A smart training plan (Progressive multi-task learning)
- Stage 1: Learn the basics on lots of data so it can make decent videos, audio, and both together.
- Stage 2: Focus extra practice on weak spots (for example, lip-sync) by adjusting the training mix.
- Stage 3: Polish on high-quality, hand-checked data to boost realism.
- Random modality masking: sometimes the model “covers one ear” (audio) or “one eye” (video) during practice so it also gets really good at single tasks like only video or only audio. This keeps it strong in both joint and single-modality jobs.
- A huge, carefully built dataset
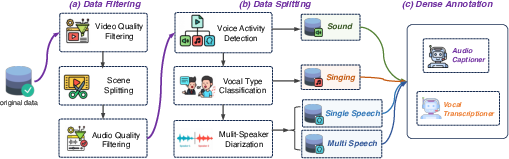
- They created the first very large audio–video dataset (about 81 million examples) with “dense captions,” which are detailed descriptions of what’s in the video, what’s in the audio, and what is being said or sung.
- They automatically filtered out bad-quality clips, checked that audio and video really match in time and meaning, and split the data by type (speech, singing, natural sounds). This gives the model high-quality examples to learn from.
- How the “make from noise” part works (simple analogy for flow matching)
- The model starts from random noise and learns which direction to move the noise to turn it into clear audio and video. Imagine sculpting: you start with a big block and learn the exact motions to carve out the final shape. This “flow matching” teaches the model those motions step by step.
4) What did they find, and why is it important?
- Much better sync and lip-reading match
- Mouth shapes match the spoken sounds at the level of phonemes (the tiny units of speech), which makes talking characters look real.
- Strong quality in both video and audio
- The visuals look sharp and natural; the audio sounds clear and fits the scene.
- Works across many tasks without getting worse at any
- It can do text-to-video, text-to-audio, text-to-audio+video, image-to-video, and image-to-audio+video. Training on all these together actually makes it better, not worse.
- Handles singing, rap, emotions, and overlapping sounds
- Breathing, rhythm, and expressions match the audio; music and sound effects line up with the action.
- Generalizes well to new situations
- It keeps working even on types of inputs it didn’t see much during training.
- Competitive with top systems
- Among open models, Klear performs at a level close to leading commercial systems like Veo 3, and it beats previous research models by a sizable margin.
Why this matters: When audio and video truly match, the result feels real. This is crucial for dubbing, animation, education, accessibility (like clear speech with matching lips), and content creation.
5) What’s the impact?
Klear points to a simple, scalable path for future AI that creates both what you see and what you hear—together, in sync, and under clear instructions. Because it:
- Uses one shared “brain” so all parts align naturally.
- Trains across many tasks without sacrificing any one of them.
- Learns from a large, carefully filtered dataset with detailed labels.
This approach could help:
- Filmmakers and animators quickly prototype scenes with accurate sound and speech.
- Game and app designers add believable voices, music, and sound effects that fit the action.
- Educators and creators produce compelling, synchronized learning materials.
- Accessibility tools generate clearer, better-matched audio–visual content.
In short, Klear shows that a unified design plus smart training and great data can make AI create videos and sounds that truly belong together.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points summarize what remains missing, uncertain, or left unexplored in the paper and can guide future research.
- Dataset openness and licensing: Is the 81M audio–video dataset, its dense captions, and the automated annotation pipeline publicly available with clear licensing and consent? If not, how can reproducible training/evaluation be ensured?
- Annotation reliability: What are the empirical error rates of the automated dense annotations (transcripts, audio/video captions, speaker attributes), and how do annotation errors propagate to downstream alignment and fidelity during training?
- OOD generalization design: The paper claims robust OOD generalization but does not define OOD categories or report results on explicit OOD splits; which domains (e.g., extreme motion, crowded scenes, noisy audio) constitute OOD and how does performance vary across them?
- Human evaluation: Audio/video quality and alignment assessments rely on proxy metrics; where are controlled human studies (e.g., double-blind MOS for audio, expert lip-sync rating, overall AV realism) and do they correlate with the reported automatic metrics?
- Lip-sync quantification: Beyond SyncNet/Synchformer, can phoneme/viseme-level alignment scores (e.g., forced alignment, viseme confusion matrices) be reported to substantiate the “phoneme-level” claim, and across diverse languages and speaking rates?
- Language coverage: How well does Klear handle multilingual speech, code-switching, and singing in non-English languages given the reliance on Whisper/SenseVoice/Qwen/Gemini annotations; are performance drops measured across languages and scripts?
- Multi-speaker and conversational scenes: The dataset includes multi-speaker speech, but does the model generate temporally coherent conversational turns, overlapping speech, and accurate speaker lip-sync for multiple faces; what is the current failure rate?
- Long-form generation limits: What are the maximum durations for tightly synchronized AV generation before drift occurs, and how do memory, quality, and alignment scale with sequence length (e.g., minutes-long videos)?
- Computational scalability: Omni-Full Attention concatenates all modalities, implying quadratic cost in sequence length; what are memory/latency footprints at higher resolutions, frame rates, or longer audio, and which sparse/chunked strategies are needed?
- MixD-RoPE robustness: How does shared temporal position ID between audio (43 Hz embeddings) and video (3 Hz embeddings) behave when modalities have mismatched durations, variable frame rates, or audio-only/video-only segments; are failure modes characterized?
- Resolution and frame-rate constraints: With Video-VAE output embeddings at 3 Hz and 16× spatial compression, what is the impact on fast lip/face articulation, high-motion scenes, and fine visual details; can higher FPS latents improve sync?
- Audio bandwidth and transients: The Audio-VAE’s 1024× downsampling to 43 Hz embeddings risks losing high-frequency content and transients; how does this affect percussive sounds, sibilants, and crispness, and can hierarchical audio latents mitigate it?
- Multi-track audio synthesis: The paper shows overlapping sounds (music + effects), but lacks quantitative analysis of source separation, balance, spatialization, panning, and dynamic range; how can controlled multi-stem generation and mixing be evaluated?
- Instruction following: Claims of reliable instruction following are not tied to a benchmark; which instruction taxonomies (temporal constraints, beat-synchronization, camera motion scripting, style transfers) are supported and where do they fail?
- Fine-grained control: Can users lock audio or video while editing the other, control lip–speech time offsets, align to music beats, or specify speaker timbre/emotion; what interfaces and conditioning signals enable precise timeline control?
- Curriculum specifics: The “performance-adaptive pretrain–post-train curriculum” is underspecified; what algorithm selects data mixtures, what metrics and thresholds drive rebalancing, and how sensitive are results to these choices?
- Negative transfer and task interference: Multi-task masking improves performance, but where does task interference or catastrophic forgetting occur (e.g., T2A vs TI2AV), and what schedules or parameter isolation techniques best mitigate it?
- Benchmark coverage: Verse-Bench is used for T2AV, but coverage of TI2AV/TI2V/T2V/T2A is limited; can broader, standardized, and publicly accessible benchmarks be established for joint AV generation, including multi-person dialogue and singing?
- Comparative baselines: Claims of “comparable to Veo-3” lack direct evaluation; can a fair cross-system benchmark (including closed and open models) be constructed with common prompts, seeds, and evaluation protocols?
- Robustness to noise and occlusions: How does performance degrade under real-world conditions (background noise, reverberation, visual occlusions, lighting changes), and can data augmentation or robustness training improve reliability?
- Safety, ethics, and misuse: What safeguards exist against harmful deepfakes (voice/face cloning), consent violations, and deceptive content; are watermarking, provenance tracking, and detection tools integrated and evaluated?
- Bias and fairness: Are demographic distributions (gender, age, accent, language) balanced in training data, and do outputs exhibit bias in voice timbre, emotion portrayal, or visual identity preservation; which fairness metrics are reported?
- Reproducibility and release: Are model weights, training recipes, data stats, and evaluation scripts released; without them, how can other researchers replicate, audit, or extend the system?
- Efficiency and deployment: With a 26B parameter model, what are inference costs, throughput, and latency for practical deployment; is distillation, quantization, or modularization viable without degrading AV alignment?
- Error taxonomy: The paper provides qualitative examples but no systematic failure taxonomy; what recurring failure modes (e.g., lip lag, emotion mismatch, identity drift, audio artifacts) occur, at what rates, and under which conditions?
- Editing and post-hoc alignment: Can generated audio or video be post-aligned (e.g., via time-stretching or dynamic time warping) while preserving fidelity; what toolchain supports iterative refinement?
- Generalization across content types: How does Klear perform on edge cases (rapid sports, crowded scenes, instruments with complex articulation, ASMR, whispering), and can domain-specific adapters improve these niches?
Practical Applications
Immediate Applications
The following applications leverage Klear’s demonstrated capabilities now: high-fidelity joint audio–video generation, phoneme-level lip–speech alignment, robust instruction-following, unimodal strength (T2V/T2A), and the automated dense-caption data pipeline.
- Bold auto-dubbing and localization with accurate lip-sync — Replace human re-timing in multi-language dubbing while preserving identity, emotion, and mouth movements. Sectors: media/entertainment, gaming, education. Tools/products/workflows: “Lip-locked Dubbing API” for studio NLEs; workflow: script/transcript → T2A speech → TI2AV/T2AV with emotion/style control → QC via SyncNet/Synchformer. Assumptions/dependencies: high-quality transcripts; multilingual TTS voices; brand/inclusivity policies; GPU inference capacity; content provenance and disclosure.
- Synthetic presenters and training avatars — Generate instructional, corporate, and compliance videos from scripts, with controlled tone and visuals (identity preserved via TI2V/TI2AV). Sectors: enterprise L&D, finance communications, public sector training. Tools/products/workflows: “Script-to-AV Studio” (slides + reference image → TI2AV); integrations with LMS/SCORM. Assumptions/dependencies: policy-compliant disclosure; voice/face/style libraries; editorial review pipelines; compute budgeting.
- Automatic Foley and background music aligned to picture — Create synchronized SFX and mood-consistent music that matches scene timing and dynamics. Sectors: film/TV post, advertising, social creators. Tools/products/workflows: “Foley & Score Co-pilot” plugin; workflow: locked cut → T2A for SFX/music → mix & mastering pass. Assumptions/dependencies: licensing terms for generated music; style controls; audio QA for loudness and spectral balance.
- Image-to-AV product promos and social content — Turn a product or brand image into motion video with voice-over and SFX, maintaining identity fidelity. Sectors: e-commerce, marketing. Tools/products/workflows: “TI2AV Burst” for product pages, A/B testing creatives. Assumptions/dependencies: product IP rights; template and style palettes; moderation (claims/disclosures).
- Accessibility and audio description tracks — Generate narration aligned to visual scenes for existing videos; produce lip-synced “talking head” summaries of complex documents. Sectors: education, public services, media accessibility. Tools/products/workflows: caption→T2A description; optional TI2AV for visual summaries; alignment verification via Verse-Bench metrics. Assumptions/dependencies: accurate scene understanding (dense captions); editorial validation; compliance with accessibility standards (WCAG).
- AV alignment auditing and QA for production pipelines — Use SyncNet Confidence, Synchformer AV-A, and ImageBind scores to flag mismatches before release. Sectors: studios, platforms, content moderation. Tools/products/workflows: “AV Alignment Auditor” integrated into CI/CD for media; score thresholds and dashboards. Assumptions/dependencies: compatible metrics with domain content; threshold tuning; human-in-the-loop resolution.
- Synthetic AV data augmentation for research and ML — Generate tightly aligned AV pairs for training ASR, lip-reading, AVSR, avatar synthesis, and multimodal retrieval. Sectors: academia, speech/vision ML, software tooling. Tools/products/workflows: controlled TI2AV/T2AV corpora; labels from the annotation pipeline (Whisper, Qwen Omni, Gemini); release under research licenses. Assumptions/dependencies: domain gap management; clear data governance; documented annotation quality.
- Automated dense-caption dataset construction at scale — Adopt the paper’s filtering, scene-splitting, and multi-model annotation pipeline to build internal AV datasets. Sectors: platforms, research labs. Tools/products/workflows: “AV Data Foundry” (SNR/MOS filters, Synchformer/ImageBind checks, split by audio type). Assumptions/dependencies: source data licensing; annotator model availability; continuous quality audits; safety filters.
Long-Term Applications
These applications build on Klear’s methods but require advances in latency, scaling, controllability, multi-speaker modeling, domain adaptation, governance, or hardware.
- Real-time telepresence and live translation avatars — Low-latency TI2AV agents that translate speech and render matched mouth movements/emotions on the fly. Sectors: conferencing, customer support, education. Tools/products/workflows: streaming diffusion/flow-matching; GPU/ASIC acceleration; voice conversion + real-time AV synthesis. Assumptions/dependencies: sub-150 ms end-to-end latency; robust streaming alignment; privacy/security policies.
- Multi-person conversational video generation — Generate turn-taking scenes with overlapping sounds, gaze, and gestures. Sectors: entertainment, training simulations, social platforms. Tools/products/workflows: multi-speaker datasets; conversation management; scene and camera planning modules. Assumptions/dependencies: dialog corpora with dense AV labels; speaker separation and diarization; ethical safeguards against synthetic impersonation.
- Immersive AR/VR tutors and companions — Instruction-following agents that teach with synchronized visuals, audio, and spatial cues. Sectors: education, healthcare coaching, industrial training. Tools/products/workflows: spatial audio integration; gesture and object demonstration modules; curriculum engines. Assumptions/dependencies: spatial alignment (SLAM); user comfort and safety; pedagogical effectiveness studies.
- Robotics perception training in photo-real AV simulation — Simulate environments with realistic audio cues (e.g., machinery hum, footsteps) aligned to visual dynamics for multimodal sensor training. Sectors: robotics, manufacturing, logistics. Tools/products/workflows: “AV Sim Gym” with physical dynamics and spatial audio; synthetic task scenarios. Assumptions/dependencies: physics engines, room acoustics modeling; sim2real transfer validation.
- Generative film co-pilots (“Storyboard-to-Final”) — A unified pipeline that maps scripts to sequences: blocking, shots, camera motion, dialog, Foley, score—iteratively refined by editors. Sectors: film/TV, advertising. Tools/products/workflows: shot planner + TI2AV/T2AV + emotion controls; editorial feedback loops. Assumptions/dependencies: advanced controllability (shot lists, lens choices); union and IP frameworks; provenance/watermarking.
- Pronunciation and speech therapy coaches using visual articulation — Phoneme-level mouth movement generation to teach articulation and aid rehabilitation. Sectors: healthcare, speech therapy. Tools/products/workflows: phoneme-to-viseme mappings; progress tracking; clinician dashboards. Assumptions/dependencies: clinical trials; personalization to patient anatomy; regulatory clearance.
- Multimodal assistants that answer with video+audio — Enterprise and consumer agents that demonstrate procedures visually while narrating. Sectors: software support, retail, finance onboarding. Tools/products/workflows: task planners → TI2AV responses; integration with knowledge bases. Assumptions/dependencies: reliability and safety guarantees; hallucination control; access governance.
- Safety training simulators with realistic incidents — Generate hazardous scenarios (alarms, equipment failures) with synchronized audio–video for drills. Sectors: energy, construction, aviation, chemical plants. Tools/products/workflows: scenario libraries; compliance-aligned assessments. Assumptions/dependencies: domain-specific conditioning; regulator acceptance; stress-testing for realism.
- Content provenance, watermarking, and policy frameworks for synthetic AV — Standardized markers (e.g., C2PA) and auditable logs embedded in generated outputs. Sectors: platforms, regulators, media. Tools/products/workflows: watermarking at decode; provenance manifests; risk scoring using AV consistency metrics. Assumptions/dependencies: ecosystem adoption; robustness to transformations; legal harmonization.
- Personalized language learning with viseme-based feedback — Learners practice with an avatar demonstrating targets; system scores timing, prosody, and mouth shapes. Sectors: edtech. Tools/products/workflows: phoneme/viseme analytics; adaptive curricula; TI2AV exercises. Assumptions/dependencies: cross-language lip-shape models; fairness across accents/speech rates.
- Domain-adapted broadcast automation — News, weather, and market updates rendered from structured data (tickers, forecasts) into ready-to-air segments. Sectors: media, finance. Tools/products/workflows: data-to-script → TI2AV generation → editorial QA → playout. Assumptions/dependencies: data reliability; fact-checking; compliance policies for synthetic anchors.
- Cross-modal research platforms for alignment and curriculum learning — Extend Omni-Full Attention, MixD-RoPE, and progressive multi-task regimes to new modalities (e.g., haptics). Sectors: academia, ML tooling. Tools/products/workflows: open benchmarks; curriculum schedulers; ablation suites. Assumptions/dependencies: reproducible releases; compute and dataset access; community governance.
Notes on feasibility dependencies across applications:
- Compute and latency: The current 26B single-tower model is likely offline or batch-oriented; real-time scenarios need optimization, distillation, and hardware acceleration.
- Data rights and safety: Source content licensing, privacy, and safety filtering are critical in dataset construction and deployment; disclosure and watermarking should be standard.
- Controls and reliability: Fine-grained controls (emotion, shot, voice timbre), guardrails against impersonation, and robust AV metrics in QA gates improve trustworthiness.
- Multilingual and multi-speaker support: Extending dense captions and training splits to more languages, accents, and conversational settings is necessary for global coverage.
- Integration: Practical adoption depends on plugins/APIs for NLEs, LMSs, MLOps, and moderation tools, plus human-in-the-loop workflows for editorial and compliance.
Glossary
- 3D RoPE: Three-dimensional rotary position embedding that encodes temporal and spatial positions for video tokens. "we apply 3D RoPE encoding across three dimensions"
- 3D VAE: A variational autoencoder that compresses videos into spatiotemporal latent representations. "a 3D VAE compresses videos into spatiotemporal latents"
- A2V: Audio-to-video generation, where audio conditions drive video synthesis. "these methods typically employ sequential T2V+V2A or T2A+A2V."
- Adam optimizer: A stochastic gradient-based optimizer combining momentum and adaptive learning rates. "We train the model using the Adam optimizer with an initial learning rate of 1e-4."
- Aesthetic Score (AS): A composite metric assessing visual quality using multiple aesthetic predictors. "the Aesthetic Score (AS), a composite metric from MANIQA, aesthetic-predictor-v2-5, and Musiq for visual fidelity."
- Audio-VAE: A variational autoencoder that encodes and decodes audio waveforms into latent embeddings. "The Audio-VAE processes input waveforms at 44.1 kHz and generates embeddings at 43 Hz"
- AV-A (Audio-Video Alignment): A metric measuring temporal synchronization between audio and video streams. "we report AV-A (Audio-Video Alignment) distance from Synchformer"
- CLAP score: A measure of semantic alignment between audio and text using CLAP embeddings. "Semantic alignment is evaluated using the CLAP score"
- CLIP-based feature injection: Conditioning technique that injects CLIP-derived features to guide generation. "conditioning on a single frame via latent concatenation or CLIP-based feature injection"
- Conditional Flow-Matching: Training objective that learns a velocity field to transport noise to data under conditions. "Conditional Flow-Matching."
- Cross-attention module: Attention mechanism where queries attend to keys/values from another modality for fusion. "employ a single-tower architecture with a cross-attention module"
- DeSync: A metric indicating audio–video desynchronization magnitude. "DeSync ↓"
- Diffusion Transformer (DiT): A transformer architecture for diffusion-based generative modeling. "Diffusion Transformer (DiT) architecture"
- DINOV3: A vision foundation model used for identity similarity and preservation metrics. "calculated via DINOV3 feature similarity."
- Dual-tower architectures: Designs with separate transformer towers for each modality, fused via interaction layers. "most existing models adopt dual-tower architectures with modality-specific initialization"
- Fréchet Distance (FD): A statistical distance between distributions, used to assess audio quality. "we use Fréchet Distance (FD)"
- I2AV: Image-to-audio-video generation, where a source image conditions both audio and video outputs. "we also incorporate several tasks of T2AV, I2V and I2AV."
- I2V: Image-to-video generation, synthesizing motion and frames conditioned on an input image. "we also incorporate several tasks of T2AV, I2V and I2AV."
- ID Consistency (ID): Metric for identity preservation across generated frames or modalities. "Identity preservation is measured by ID Consistency (ID)"
- ImageBind (IB): A multimodal embedding model used to measure cross-modal alignment. "Global cross-modal alignment is measured by ImageBind (IB)."
- MANIQA: A no-reference image quality assessment model used within the aesthetic score. "MANIQA"
- Mel-spectrograms: Time–frequency audio representation used for evaluating audio distributions. "KL Divergence on mel-spectrograms from PANNs"
- Mixed Dimension Rotary Position Embedding (MixD-RoPE): Joint temporal and spatial positional encoding shared across audio and video. "Mixed Dimension Rotary Position Embedding (MixD-RoPE)."
- MMDiT (Multimodal Diffusion): A diffusion transformer that ingests multiple modalities jointly with full attention. "we employ Multimodal Diffusion (MMDiT) to take the sequences of all modalities as input and perform full attention."
- Motion Score (MS): A metric derived from optical flow to assess dynamic realism of video. "we report the Motion Score (MS) based on RAFT optical flow for dynamic realism"
- MOS: Mean Opinion Score; subjective quality rating metric for audio. "We filter audio data by removing samples with low SNR, MOS, abnormal clipping"
- Musiq: A learned aesthetic quality model used in the composite Aesthetic Score. "Musiq"
- Omni-Full Attention: Joint full-attention mechanism across audio, video, and text streams for tight fusion. "an Omni-Full Attention mechanism"
- Out-of-distribution (OOD): Data or scenarios that differ from the training distribution, used to assess generalization. "with robust OOD generalization."
- PANNs: Pretrained Audio Neural Networks used for feature extraction in evaluation. "from PANNs"
- Progressive Training Strategy: Multi-stage curriculum combining pretraining and post-training phases to refine capabilities. "Progressive Training Strategy."
- RAFT: Recurrent All-Pairs Field Transforms; optical flow method used for motion assessment. "RAFT"
- Random Modality Masking: Training trick that masks modality queries/keys to induce single- or joint-task behavior. "Random Modality Masking."
- Rectified Flow Matching: Flow-based training variant used to improve alignment in joint generation. "SyncFlow (dual-DiT with Rectified Flow Matching)"
- Scene splitting: Preprocessing step to segment videos into single-scene samples for cleaner training data. "We then apply scene splitting to ensure each sample contains only one scene."
- Single-tower architecture: A unified backbone where all modalities are processed jointly in one transformer tower. "employ a single-tower architecture with a cross-attention module"
- Synchformer: A model used to measure and enforce temporal audio–video alignment. "using Synchformer for temporal alignment"
- SyncNet Confidence (SNC): Confidence score for lip synchronization quality. "SyncNet Confidence (SNC) score for lip sync."
- T2A: Text-to-audio generation task. "Across tasks (T2AV/TI2AV/TI2V/T2V/T2A)"
- T2AV: Text-to-audio-video generation task. "Across tasks (T2AV/TI2AV/TI2V/T2V/T2A)"
- T2V: Text-to-video generation task. "Across tasks (T2AV/TI2AV/TI2V/T2V/T2A)"
- TI2AV: Text-and-image-to-audio-video generation task. "Across tasks (T2AV/TI2AV/TI2V/T2V/T2A)"
- TI2V: Text-and-image-to-video generation task. "Across tasks (T2AV/TI2AV/TI2V/T2V/T2A)"
- U-Net backbones: Convolutional encoder–decoder architectures historically used in diffusion models. "Early models used U-Net backbones"
- Velocity field: The learned vector field that transports noise to data in flow matching. "The model needs to learn the velocity field that transforms pure noise p0=… to the underlying data distribution p_data."
- Verse-Bench: A benchmark suite for evaluating audio–video joint generation. "On the Verse-Bench, it surpasses prior methods by a large margin"
- Video-VAE: A variational autoencoder that encodes/decodes video frames into compressed latent embeddings. "The Video-VAE handles input videos with varying resolutions and frame rates"
- V2A: Video-to-audio generation, where visual content conditions audio synthesis. "these methods typically employ sequential T2V+V2A or T2A+A2V."
- WER: Word Error Rate; metric for transcription accuracy in TTS evaluation. "WER ↓"
- Zero-shot style transfer: Applying stylistic changes without task-specific fine-tuning. "enable zero-shot style transfer."
Collections
Sign up for free to add this paper to one or more collections.