ImLoc: Revisiting Visual Localization with Image-based Representation
Abstract: Existing visual localization methods are typically either 2D image-based, which are easy to build and maintain but limited in effective geometric reasoning, or 3D structure-based, which achieve high accuracy but require a centralized reconstruction and are difficult to update. In this work, we revisit visual localization with a 2D image-based representation and propose to augment each image with estimated depth maps to capture the geometric structure. Supported by the effective use of dense matchers, this representation is not only easy to build and maintain, but achieves highest accuracy in challenging conditions. With compact compression and a GPU-accelerated LO-RANSAC implementation, the whole pipeline is efficient in both storage and computation and allows for a flexible trade-off between accuracy and highest memory efficiency. Our method achieves a new state-of-the-art accuracy on various standard benchmarks and outperforms existing memory-efficient methods at comparable map sizes. Code will be available at https://github.com/cvg/Hierarchical-Localization.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces ImLoc, a new way to figure out where a camera is and where it’s pointing just from photos. This task is called visual localization. ImLoc keeps things simple: instead of building a big 3D model of a place, it stores regular images plus a “depth map” for each image (a depth map says how far away things are in the picture). Using these, ImLoc can find the camera’s position very accurately, even in tough conditions like nighttime, while being easy to build, update, and store.
What the researchers wanted to achieve
The authors asked three main questions, in easy terms:
- Can we get the best of both worlds by using a simple map made of images, but still do strong geometry like 3D methods do?
- If we add a depth map to every image, can that give us enough “3D clues” to place the camera accurately?
- Can we make the system fast and compact (small memory), yet still state-of-the-art in accuracy?
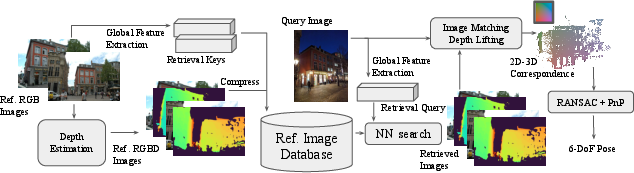
How ImLoc works (with simple explanations)
Think of ImLoc as a two-step process: building the map and using the map.
Building the map (mapping)
- Store the basic stuff for each image:
- The image itself (RGB).
- The camera’s known position and direction (its “pose”) and lens info (“intrinsics”).
- A compact “global feature” that helps quickly find similar images, like a thumbnail fingerprint.
- A depth map: a picture where each pixel stores how far away that point is, like a heat map of distance.
How do they get the depth map? They use “dense matching,” which means finding for many pixels in one image the matching pixel in other images. If two images see the same place from different angles, they can “triangulate,” like measuring with two eyes to estimate distance. This creates a depth value for each pixel. They store these depth maps in a compressed form so they take up very little memory.
Using the map (localization)
- Image retrieval: given a new photo (the query), the system quickly finds the top K most similar stored images (so it only works with the most relevant ones).
- Dense matching: the system matches many pixels from the query image to pixels in each of those K images.
- Lifting to 2D–3D: for each matched pixel in a stored image, it looks up the depth from the depth map. That turns a 2D pixel into a 3D point in space (because with the camera pose and depth, you can compute the 3D position). Now, each query pixel is matched to a 3D point—these are called 2D–3D correspondences.
- Pose estimation: with lots of 2D–3D pairs, the system computes the camera’s position and direction. It uses a classic solver called PnP (Perspective-n-Point) together with RANSAC (a robust method that tests many guesses and throws away bad matches or “outliers”). They speed this up on a GPU and refine the result for extra accuracy.
Key ideas in plain language
- Depth map: like a special grayscale picture where lighter/darker values show how far things are from the camera.
- Dense matching: instead of choosing a few “keypoints,” it tries to match many pixels. This avoids missing important details and works better under changes in lighting or viewpoint.
- PnP + RANSAC: PnP figures out where the camera is using 2D–3D pairs; RANSAC makes it robust by ignoring bad matches. LO-RANSAC adds a local refinement step to improve the best guess.
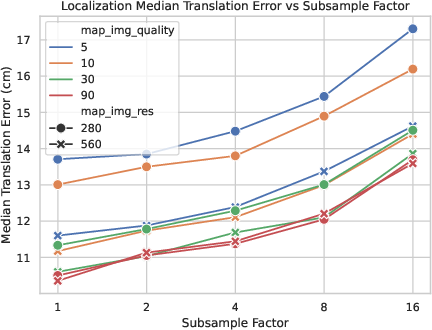
Efficiency and storage
To keep the map small:
- Images are downsampled (shrunk) to a reasonable resolution (around 560x560) and compressed with modern image codecs.
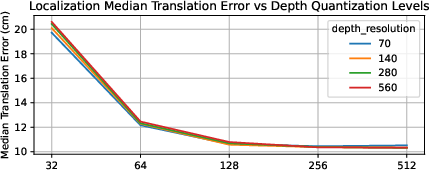
- Depth maps are quantized (stored with fewer levels) and also compressed.
- Because most of the important structure is kept, this small map can still give excellent accuracy.
Main results and why they matter
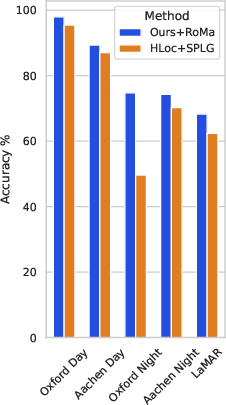
The authors tested ImLoc on several standard, tough benchmarks and found it consistently achieved top accuracy:
- Oxford Day and Night: large outdoor area with tough day/night differences. ImLoc had the best accuracy for day and night across all scenes.
- LaMAR: huge AR datasets with changing furniture, people, weather, and lighting. ImLoc again was best across scenes and thresholds.
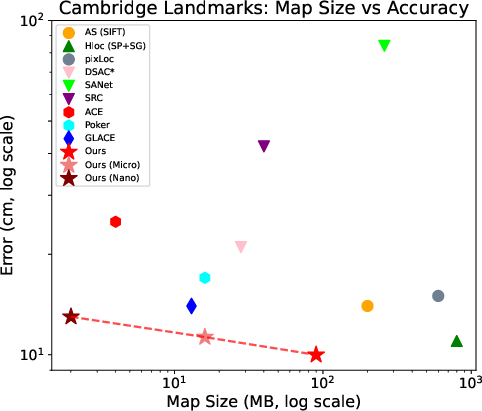
- Cambridge Landmarks: classic outdoor dataset. ImLoc matched or beat state-of-the-art methods and showed it could be compressed heavily (down to “micro” and even “nano” versions) while staying competitive.
- Aachen Day-Night: city-scale with strong day/night shifts. ImLoc outperformed both structure-based and structureless baselines.
Why this is important:
- Accuracy in challenging conditions means it’s reliable for real-world use.
- Memory efficiency means it can run on devices with limited storage (like phones or drones).
- Flexibility means you can add or remove images as places change, without re-building a big 3D model.
What this could mean going forward
ImLoc shows that a simple image-based map augmented with depth maps can compete with or beat complex 3D systems:
- Easier to maintain: if a street changes or furniture moves, you can just add or replace images. No need to rebuild a huge, globally consistent 3D model.
- Scalable: using retrieval first then dense matching keeps computation manageable even for city-scale scenes.
- Future-proof: as depth estimation and matching models improve, you can upgrade parts of the pipeline without changing the map representation.
- Practical impact: better localization for AR/VR, robots, and self-driving vehicles with lower storage and faster updates. Developers can choose a trade-off—smaller maps for speed and storage, or larger maps for maximum accuracy.
In short, ImLoc follows “Occam’s Razor” (prefer simpler solutions) and still achieves state-of-the-art results. It proves that storing images plus depth maps is a powerful and practical way to do visual localization accurately, efficiently, and flexibly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following concise, actionable gaps highlight what remains uncertain or unexplored in the paper and can guide future research:
- Dependence on known, accurate mapping poses and intrinsics: the method assumes posed images for mapping, but the impact of pose/intrinsic errors on triangulated depths and downstream localization accuracy is not quantified.
- Covisibility estimation without SfM: the paper sometimes uses a “reference SfM reconstruction” to pick covisible images, undermining the claim of decoupling from global 3D; strategies that avoid SfM and their performance trade-offs are not evaluated.
- Cross-view depth consistency: storing per-view depths avoids a global model but introduces cross-view inconsistencies; the effects of inconsistent depths on PnP accuracy and outlier rates are not analyzed, nor are mechanisms to reconcile or fuse per-view geometry.
- Sparse coverage and single-view cases: the pipeline requires covisible images to triangulate depth; fallback strategies (e.g., monocular depth priors, sensor fusion) for areas with limited overlap are not explored or evaluated.
- Depth estimation design choices: thresholds for match confidence (≥0.05), angular error (2°), and inlier counts (>3) are set heuristically; their sensitivity and optimality across datasets and baselines remain unstudied.
- Comparison to alternative depth sources: robustness/accuracy trade-offs between dense-matching triangulation, classical MVS, and learned monocular/stereo depth across lighting/baseline regimes are not systematically compared.
- Dynamic/transient content in stored depths: the potential contamination of per-image depth by people/vehicles and its impact on 2D–3D correspondences is not addressed; no dynamic region detection or filtering is proposed or evaluated.
- Camera model assumptions: the approach assumes pinhole cameras with stable intrinsics; the effects of lens distortion, rolling shutter, zoom/focus changes, and calibration drift on triangulation and PnP are not investigated.
- Resolution choice and information loss: the fixed 560×560 resolution is justified empirically, but no broad study quantifies accuracy/time trade-offs vs. resolution across different scenes, FOVs, and object scales.
- Retrieval dependency and failure modes: performance hinges on image retrieval (with different retrievers per dataset), yet sensitivity to retrieval errors, choice of top‑K, and missed-neighbor cases are not analyzed.
- End-to-end runtime and scalability: comprehensive mapping and query-time runtime/memory profiles (including matching and RANSAC), especially at LaMAR scale (~100k images) and larger (city/million-image scale), are not reported.
- Hardware constraints: the feasibility on embedded/mobile platforms (GPU availability, memory footprint, energy consumption) is not evaluated; CPU-only fallbacks and their performance are unspecified.
- RANSAC configuration and sampling: subsampling to 10k correspondences and fixed iteration limits are used without ablation; guided sampling, early stopping criteria, and spatial correlation-aware strategies remain unexplored.
- Uncertainty modeling: per-pixel depth and match confidences are only used as weights; explicit uncertainty propagation and probabilistic PnP formulations (e.g., heteroscedastic noise models) are not considered.
- Map updates and lifecycle: although claimed flexible, there are no experiments on incremental adding/removing images, time-aware map versions, or policies for detecting and purging stale imagery/depths after scene changes.
- Privacy and storage policies: storing compressed RGB raises privacy concerns; alternatives such as privacy-preserving representations or learned, decryptable feature maps are not discussed or benchmarked.
- Extremely large-scale deployment: storage/indexing overheads (including retrieval indices) and accuracy-memory-speed trade-offs are not quantified for very large maps (e.g., millions of images).
- Sensor fusion opportunities: integration of IMU/GNSS/gravity priors to reduce pose ambiguity (e.g., vertical mislocalizations in LaMAR) is not attempted or evaluated.
- Generalization to other camera setups: applicability to fisheye, panoramic, multi-camera rigs, and RGB‑D sensors is not studied; required adaptations and benefits are open.
- Beyond day/night: robustness to severe weather (rain, fog, snow), seasonal changes, specular surfaces, and heavy occlusions is not assessed.
- Depth range and quantization: the chosen depth range (0.25–128 m) and 8‑bit log quantization are not validated across diverse scenes (very close/very far ranges) or analyzed for induced bias/quantization error on pose.
- Compression generality: aggressive “micro/nano” compression is evaluated primarily on Cambridge; the accuracy–memory trade-off across other datasets and conditions remains untested.
- Failure analysis: detailed attribution of errors to retrieval vs. matching vs. depth vs. RANSAC is missing; no qualitative/quantitative analysis of common failure cases (e.g., repetitive facades, floor confusion) is provided.
- Comparisons to recent NVS-based localizers: head-to-head evaluations (accuracy, runtime, memory) against recent NeRF/3DGS/mesh localizers on the same datasets are limited or absent.
- Training and adaptation of dense matcher: RoMa is used off-the-shelf; the benefits/risks of fine-tuning for specific domains or of using alternative dense matchers are not examined.
- Robust fallback strategies: the system lacks defined fallbacks when all retrieved images yield inconsistent/noisy depths or when dense matches are unreliable; hybrid strategies (e.g., local on-the-fly triangulation, sparse features) are not explored.
Practical Applications
Immediate Applications
The following use cases can be deployed now by leveraging the paper’s image+depth map representation, dense matching, and GPU-accelerated LO-RANSAC. They assume you can obtain posed mapping images (e.g., via VIO/SLAM or survey), run retrieval and dense matching (e.g., RoMa), and host maps with JPEG XL-compressed RGB/depth.
- Robotics (warehouses, logistics, retail)
- Use case: Drop-in visual relocalization for AMRs/AGVs in dynamic indoor spaces without maintaining a global 3D model.
- Tools/products/workflows: ImLoc micro/nano maps stored on-robot; edge GPU for dense matching; periodic map refresh by adding/removing posed images from patrol runs; integration with existing planners as a relocalization module.
- Assumptions/dependencies: Posed mapping images and camera intrinsics available; GPU or sufficient edge compute; retrieval features precomputed; lighting varies but scene has sufficient texture.
- AR/XR (malls, airports, museums, stadiums)
- Use case: Persistent AR anchoring and indoor/outdoor AR navigation that remains robust across day/night and crowd variations.
- Tools/products/workflows: Venue-level ImLoc map server; SDK for on-device retrieval+matching; content management to attach anchors to mapped images; compression tuner to select micro/nano maps for on-device storage.
- Assumptions/dependencies: Initial mapping with posed images; privacy management for stored RGB; device camera intrinsics; acceptable latency on mobile/edge GPU or reduced K/resolution settings.
- Autonomous driving and micro-mobility
- Use case: Visual localization as a redundancy to GNSS/HD maps for urban canyons and GNSS-denied zones.
- Tools/products/workflows: Roadside or fleet-collected posed imagery; per-corridor ImLoc maps compressed and deployed to vehicles; online retrieval and dense matching fused with wheel odometry/IMU.
- Assumptions/dependencies: Camera calibration; map refresh for construction changes; top-K retrieval coverage; compute budget on vehicle.
- Drone and infrastructure inspection
- Use case: Robust pose estimation around known structures (bridges, towers, plants) under illumination changes.
- Tools/products/workflows: Pre-flight mapping (posed images from survey flight) → depth triangulation on GPU → compressed map; on-mission query matching for accurate pose to overlay CAD/BIM or detect defects.
- Assumptions/dependencies: Overlap between query and mapped views; safe operational envelopes; retrieval tuned for aerial viewpoints.
- Construction and facility management
- Use case: Progress tracking and BIM alignment by relocalizing handheld/phone photos without building a global 3D model each time.
- Tools/products/workflows: Weekly image sweeps with VIO poses; automated depth triangulation; small per-floor ImLoc maps; “pose-and-overlay” viewer for BIM comparison.
- Assumptions/dependencies: Floor-by-floor mapping cadence; handling of repetitive structures via retrieval; privacy workflows for occupied spaces.
- Retail and smart stores
- Use case: Store navigation and shelf-scanning localization for robots or staff devices despite frequent planogram changes.
- Tools/products/workflows: On-shift mapping updates from staff wearable/robot cameras; add/remove images to reflect planogram changes; on-device micro maps for low-latency localization.
- Assumptions/dependencies: Regular updates; reliable retrieval under occlusions; sufficient lighting and texture.
- Security and safety (industrial sites, campuses)
- Use case: Camera pose estimation for incident localization and AR-assisted procedures in GNSS-denied indoor zones.
- Tools/products/workflows: Site-level image+depth map with access control; operator devices run retrieval+dense matching; pose fused with floor plans for rapid guidance.
- Assumptions/dependencies: Secure storage of RGB imagery; calibration compliance; GPU access or reduced settings.
- Smart-city wayfinding and accessibility
- Use case: Visual localization for pedestrian apps in transit hubs and campuses; robust day/night performance for visually impaired assistance.
- Tools/products/workflows: Authority-maintained ImLoc map per facility; SDK integration into navigation apps; micro/nano map packs downloadable per facility.
- Assumptions/dependencies: Maintenance processes for scene changes; device capability for on-device matching or edge inference; policy for image retention.
- Media/creative tech
- Use case: Accurate “from-where-was-this-shot” estimation to align 3D content for VFX/previs in known locations.
- Tools/products/workflows: Productions build an ImLoc map during location scouting; editors query with new frames for immediate camera pose; export to DCC tools.
- Assumptions/dependencies: Location permits and privacy; coverage of required viewpoints; integration plugin.
- Photo organization and search
- Use case: Localizing personal photos to known venues to cluster by place and viewpoint.
- Tools/products/workflows: Venue apps distribute micro maps; photo apps run lightweight retrieval+matching to estimate pose per photo.
- Assumptions/dependencies: User opt-in; device compute or cloud inference; sufficient overlap between photo and map imagery.
- Academic research toolkit
- Use case: Benchmarking dense vs. sparse localization, map-size/accuracy trade-offs, and compression effects.
- Tools/products/workflows: Use provided code, GPU LO-RANSAC, RoMa depth triangulation; reproduce LaMAR/Aachen/Oxford/Cambridge results; ablate resolution, K, and compression.
- Assumptions/dependencies: Access to datasets, GPUs, and retrieval backbones (Megaloc/NetVLAD/EigenPlaces).
- Software integrations
- Use case: Extend existing pipelines (e.g., HLoc/COLMAP) with image+depth map storage and dense matching pose heads.
- Tools/products/workflows: “ImLoc SDK” with CUDA LO-RANSAC op, JPEG XL I/O, and retrieval adapters; map server with API for add/remove images and compression tuning.
- Assumptions/dependencies: CUDA-capable hardware; license compatibility for matchers/retrieval models; JPEG XL support or alternative codecs.
Long-Term Applications
These rely on further research, scaling, or productization, such as fully on-device operation without a GPU, standardized map formats, or automated dynamic-scene handling.
- City-scale crowd-sourced localization
- Use case: Continually refreshed, image+depth maps from user devices for city navigation and AR layers.
- Tools/products/workflows: Federated mapping from VIO-equipped phones; automated covisibility selection and triangulation at scale; time-aware map versions.
- Assumptions/dependencies: Privacy-preserving data collection; incentives; scalable retrieval indexing; governance for updates.
- On-device, real-time mobile localization
- Use case: Full ImLoc pipeline on smartphones/AR glasses without offloading.
- Tools/products/workflows: NPU-optimized dense matchers; low-power CUDA/Vulkan kernels for LO-RANSAC; aggressive micro/nano maps with adaptive K and resolution.
- Assumptions/dependencies: Hardware acceleration for dense correlation and RANSAC; model distillation/quantization; OS-level camera calibration access.
- Standardization of image+depth map formats
- Use case: Interoperable “ImLoc Map” packages across vendors and apps.
- Tools/products/workflows: Open spec for compressed RGB, log-quantized depth, intrinsics/poses, and retrieval features; validation tools; security and privacy extensions.
- Assumptions/dependencies: Community/industry buy-in; long-term codec support (JPEG XL or successors).
- Dynamic-scene reasoning and map hygiene
- Use case: Automatic detection and pruning of stale images, time-of-day layers, and change-aware retrieval.
- Tools/products/workflows: Change-point detectors; temporal indexing; policies for conflicting content (construction, seasonal decor).
- Assumptions/dependencies: Sufficient re-observation; labeled feedback loops; compute for periodic re-triangulation.
- Multimodal fusion (IMU/LiDAR/thermal)
- Use case: Robust localization in low texture, adverse weather, or low light by fusing other sensors.
- Tools/products/workflows: Joint retrieval across visual and LiDAR descriptors; depth substitution from LiDAR; thermal-aware matchers for night operations.
- Assumptions/dependencies: Sensor calibration; cross-modal training data; extended map schema.
- Fleet-level autonomy and operations
- Use case: Map-as-a-service for robots/vehicles with automated updates, versioning, and A/B testing of compression/accuracy.
- Tools/products/workflows: CI/CD for maps; telemetry-driven re-mapping; SLA-backed service for retrieval/matching at the edge/core.
- Assumptions/dependencies: Reliable connectivity or caching; observability; safety cases for localization fallback.
- Privacy-preserving visual localization
- Use case: Deployable localization with minimal exposure of identifiable imagery.
- Tools/products/workflows: Depth-only maps where viable; face/license-plate redaction; on-device encryption; secure enclaves for retrieval.
- Assumptions/dependencies: Trade-offs in accuracy without RGB; regulatory acceptance; performance overheads.
- Digital twins and CAD alignment at enterprise scale
- Use case: Continuous alignment between as-built environments and digital twins using lightweight localization.
- Tools/products/workflows: Bidirectional pipelines from CAD to viewpoint planning and from images to pose-to-CAD alignment; semantic change logs.
- Assumptions/dependencies: Accurate CAD; viewpoint coverage; semantic correspondences for low-texture surfaces.
- Extreme-condition localization (fog, rain, snow, subterranean)
- Use case: Reliable pose in visually degraded or GPS-denied environments (mines, tunnels).
- Tools/products/workflows: Specialized dense matchers trained for adverse conditions; multispectral cameras; adaptive retrieval.
- Assumptions/dependencies: New training data; ruggedized sensors; controlled illumination strategies.
- Hardware acceleration and embedded RANSAC cores
- Use case: Dedicated accelerators for dense correlation and robust pose estimation in wearables/robots.
- Tools/products/workflows: ASIC/IP blocks for LO-RANSAC; memory tiling for dense matching; co-design with camera ISPs.
- Assumptions/dependencies: Vendor adoption; long lead times; software toolchains.
Notes on Dependencies and Feasibility
- Mapping prerequisites: Posed images with accurate intrinsics; covisible pairs for depth triangulation; or availability of RGB-D sensors.
- Compute: The reference implementation relies on GPU acceleration (dense matching and LO-RANSAC). For constrained devices, reduce image resolution, K, and correspondence density, or offload to edge servers.
- Storage and codecs: Reported gains assume JPEG XL for RGB/depth. Substitute with broadly supported codecs if needed (e.g., HEIF/AVIF for RGB, PNG for quantized depth) with potential size trade-offs.
- Models: Retrieval (e.g., Megaloc/NetVLAD/EigenPlaces) and dense matcher (RoMa) are pluggable; performance depends on training data and licensing constraints.
- Environment limitations: Performance may degrade in extremely textureless/reflective scenes, severe occlusions, or if retrieval fails. Regular map refresh mitigates drift due to scene changes.
- Privacy/compliance: Storing RGB imagery requires governance (consent, retention, PII redaction). Where risk is high, favor heavier depth quantization or depth-only maps with expected accuracy trade-offs.
Glossary
- Absolute-PR: A pose regression approach that directly predicts the absolute camera pose from an input image. "Absolute-PR~\cite{kendall2015posenet,Kendall2017GeometricLF,naseer2017deep,Walch2017lstm} typically struggles with generalization and does not scale well with limited network capacity~\cite{taira2018inloc}."
- Bilinear interpolation: A method to estimate values at non-integer pixel locations by linearly interpolating in two dimensions. "we bilinearly interpolate the depth at subpixel coordinates;"
- Bidirectional dense matching: Performing dense matching in both directions between two images to improve correspondence reliability. "we perform bidirectional dense matching with RoMa between the query image and each retrieved database image"
- Cauchy loss: A robust loss function that reduces the influence of outliers during optimization. "using a robust Cauchy loss, weighted by the RoMa~\cite{edstedt2023roma} confidences."
- Coarse-to-fine pipeline: A hierarchical approach that first retrieves candidate images (coarse) and then refines pose using detailed geometric matching (fine). "a common strategy is to use a coarse-to-fine pipeline~\cite{sarlin2019coarse}."
- Covisibility: The property that two images observe overlapping parts of the scene. "The covisibility is estimated with the reference SfM reconstruction~\cite{schoenberger2016sfm}, or by retrieving images with similar global retrieval features~\cite{berton2025megaloc}."
- Dense correspondences: A large set of per-pixel matches between images used for robust geometric estimation. "An efficient GPU accelerated LO-RANSAC allows to effectively utilize the dense correspondences for estimating the pose."
- Dense image matching: Finding correspondences for many or all pixels across images rather than just sparse keypoints. "dense image matching methods aim to find the matched position in another image for each pixel in the reference image."
- Depth map: An image that encodes the distance from the camera to the scene for each pixel. "we predict and store (dense) depth maps together with poses and camera intrinsics."
- Descriptor compression: Techniques to reduce the storage size of feature descriptors while preserving matching performance. "descriptor compression \cite{dong2023learning,ke2004pca,yang2022scenesqueezer,lynen2015get,Laskar2024dpqed}."
- Extrinsics: The camera parameters (position and orientation) that define its pose in the world coordinate system. "we predict and store 2D depth maps along with RGB images, intrinsics, and extrinsics."
- Feed-forward: A computation paradigm where the model outputs results directly without iterative refinement. "feed-forward, and refinement models."
- Gaussian Splatting (3DGS): A scene representation that uses 3D Gaussian kernels to render views efficiently. "3D Gaussian Splatting (3DGS)~\cite{kerbl20233d}"
- Globally consistent 3D model: A unified reconstruction that aligns all views coherently across the entire scene. "require building and maintaining a globally consistent 3D model, which is challenging in dynamic or sparsely observed scenes."
- Image retrieval: Selecting the most relevant database images for a query using global features. "after a set of relevant images is selected from the database by image retrieval~\cite{arandjelovic16netvlad}"
- Inliers: Correspondences that fit a geometric model within a specified error threshold. "Finally, we keep the depth estimates with more than 3 inliers."
- Intrinsics: The internal camera parameters such as focal length and principal point. "we predict and store 2D depth maps along with RGB images, intrinsics, and extrinsics."
- JPEG XL: A modern image compression format offering high efficiency and quality. "compress them with JPEG XL~\cite{alakuijala2019jpeg} at quality 90."
- Keyframe subsampling: Reducing the number of stored frames to decrease storage or computation. "it is more sensitive to keyframe subsampling or downsampling resolution"
- Keypoint detection repeatability: The consistency of detecting the same keypoints across different images or conditions. "It avoids the challenges imposed by keypoint detection repeatability, and allows to leverage all the image information for matching."
- LANCZOS filter: A resampling filter used for high-quality image downsampling. "with the LANCZOS filter~\cite{duchon1979lanczos}"
- Log-space quantization: Discretizing values after a logarithmic transform to better represent wide dynamic ranges. "quantize the depth to log space with 256 levels,"
- Map compression: Reducing the storage footprint of a scene representation while maintaining localization performance. "map compression \cite{brachmann2023ace,compression2019cvpr}"
- Minimal sets: The smallest number of correspondences required to estimate a model in RANSAC. "the CPU samples a batch of 1K minimal sets and generates hypotheses"
- NeRF: Neural Radiance Fields, a volumetric neural rendering method for view synthesis. "NeRF~\cite{mildenhall2020nerf}"
- Novel View Synthesis (NVS): Techniques that render new viewpoints from learned scene representations. "novel view synthesis (NVS)~\cite{mildenhall2020nerf,kerbl20233d}"
- P3P solver: A pose estimation algorithm that computes camera pose from three 2D–3D point correspondences. "poselib P3P solver~\cite{poselib}"
- Perspective-n-Point (PnP): Estimating camera pose from n correspondences between 3D points and their 2D projections. "Perspective-n-Point (PnP) solver~\cite{haralick1994review,bujnak2008general}"
- Point cloud sparsification: Reducing the number of points in a point cloud to save memory while maintaining structure. "point cloud sparsification~\cite{li2010location,camposeco2019hybrid,yang2022scenesqueezer}"
- RANSAC: Random Sample Consensus, a robust estimation method that fits models to data with outliers. "RANSAC to facilitate robust pose estimation."
- Render-and-compare framework: Localization by aligning a rendered view of the scene with the query image. "render-and-compare framework~\cite{labbe2022megapose,li2018deepim}"
- Reprojection error: The difference between observed image points and projected model points under a pose hypothesis. "robustified distribution of the reprojection error."
- Scene Coordinate Regression (SCR): Predicting 3D scene coordinates for image pixels to form 2D–3D correspondences. "Scene Coordinate Regression (SCR) methods~\cite{brachmann2016,Cavallari2019cascade,brachmann2017dsac,brachmann2023ace,wang2024hscnet++,glace2024cvpr,jiang2025r} instead first establish 2D-3D correspondences"
- Structure-from-Motion (SfM): Recovering camera poses and 3D structure from multiple images via matching and triangulation. "Following the classical SfM pipeline~\cite{schoenberger2016sfm}"
- Triangulation: Computing 3D points from multiple 2D observations given known camera poses. "and triangulate them to obtain the corresponding 3D points."
- Truncated squared reprojection error: A robust scoring function that caps large errors to reduce outlier impact. "using a truncated squared reprojection error weighted by RoMa confidence."
Collections
Sign up for free to add this paper to one or more collections.