- The paper introduces a unified framework using meta-learning to automatically discover shared generative structure across multiple datasets.
- It decomposes parameters into global neural network components and local dataset-specific variables, enabling efficient bi-level variational inference.
- Empirical results reveal competitive performance in object-centric image and sequential text modeling, with high ARI scores and reduced test-log-perplexity.
Introduction
Probabilistic graphical models (PGMs) have long been a foundation for learning latent structure in complex datasets, but their efficacy fundamentally depends on the correct specification of model structure and distributional assumptions. The manual design and adaptation of these models for heterogeneous or large-scale data remains laborious and brittle. "Meta-probabilistic Modeling" (2601.04462) advances this line of research by introducing a methodology that leverages meta-learning to automatically discover suitable generative model structure from multiple related datasets. This framework, termed meta-probabilistic modeling (MPM), marries the interpretability of classical PGMs with the expressivity of neural parameterizations, supporting efficient and scalable learning across varied data sources.
Model Architecture and Learning Framework
MPM assumes access to several related datasets and constructs a hierarchical generative model that decomposes parameters into global (shared) and local (dataset-specific) components. Global parameters, modeled via neural networks, encode cross-dataset generative structure, while local parameters capture individual dataset variation. The approach generalizes existing PGM formulations by introducing explicit meta-level structure that can capture statistical regularities across collections rather than isolated datasets.
A key challenge in this context is tractable inference, particularly with deep neural parameterizations. MPM resolves this by designing a surrogate variational objective inspired by VAE recognition networks, enabling efficient coordinate-ascent updates for dataset-specific variables and gradient-based learning for global parameters. The framework operates via bi-level optimization—inner local optimizations are performed analytically where possible, while outer updates for global parameters leverage stochastic optimization.
The structure and motivation of MPM are well-captured in schematic overviews such as the one below, emphasizing the distinction and interaction between global and local model components:

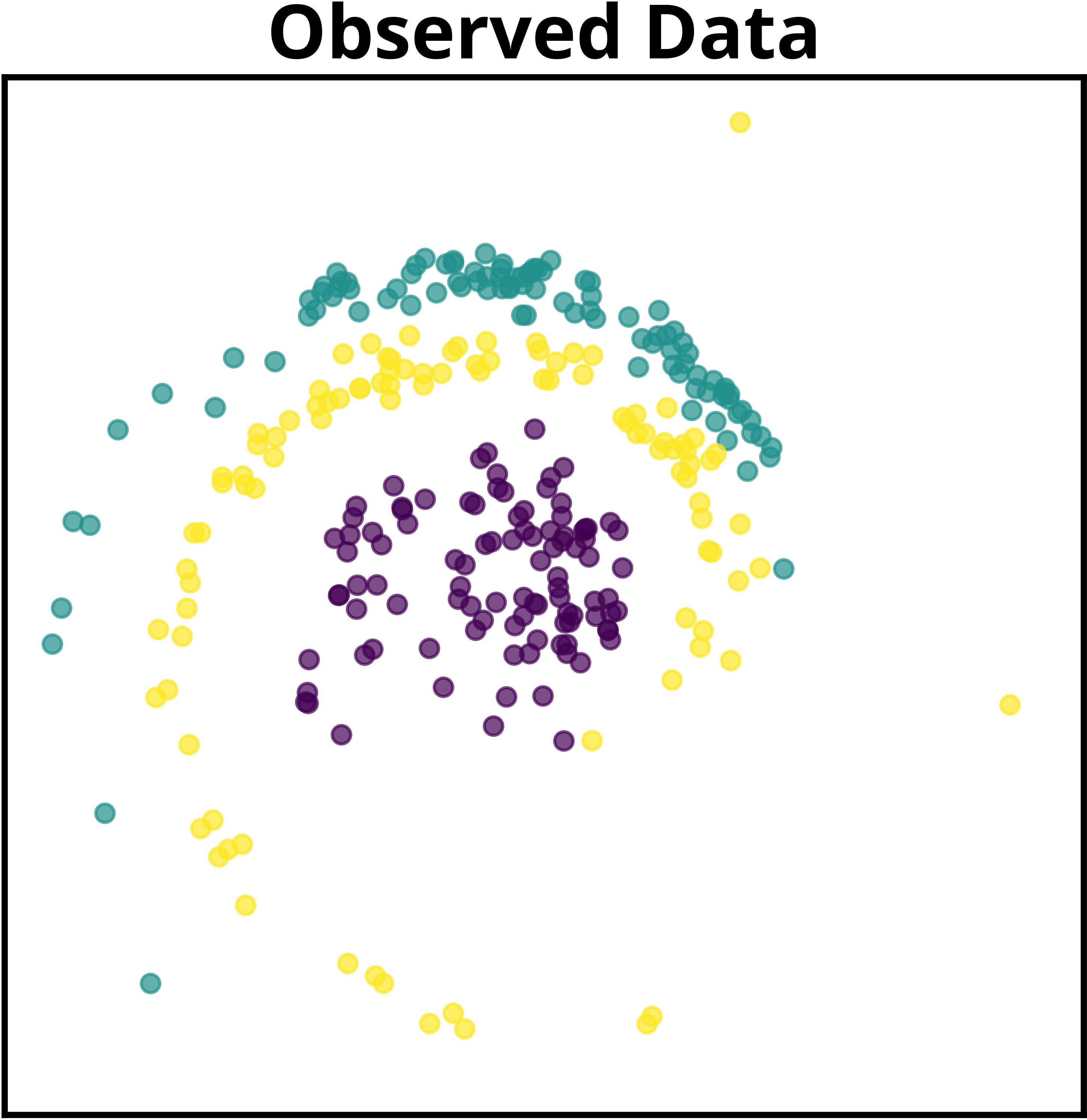
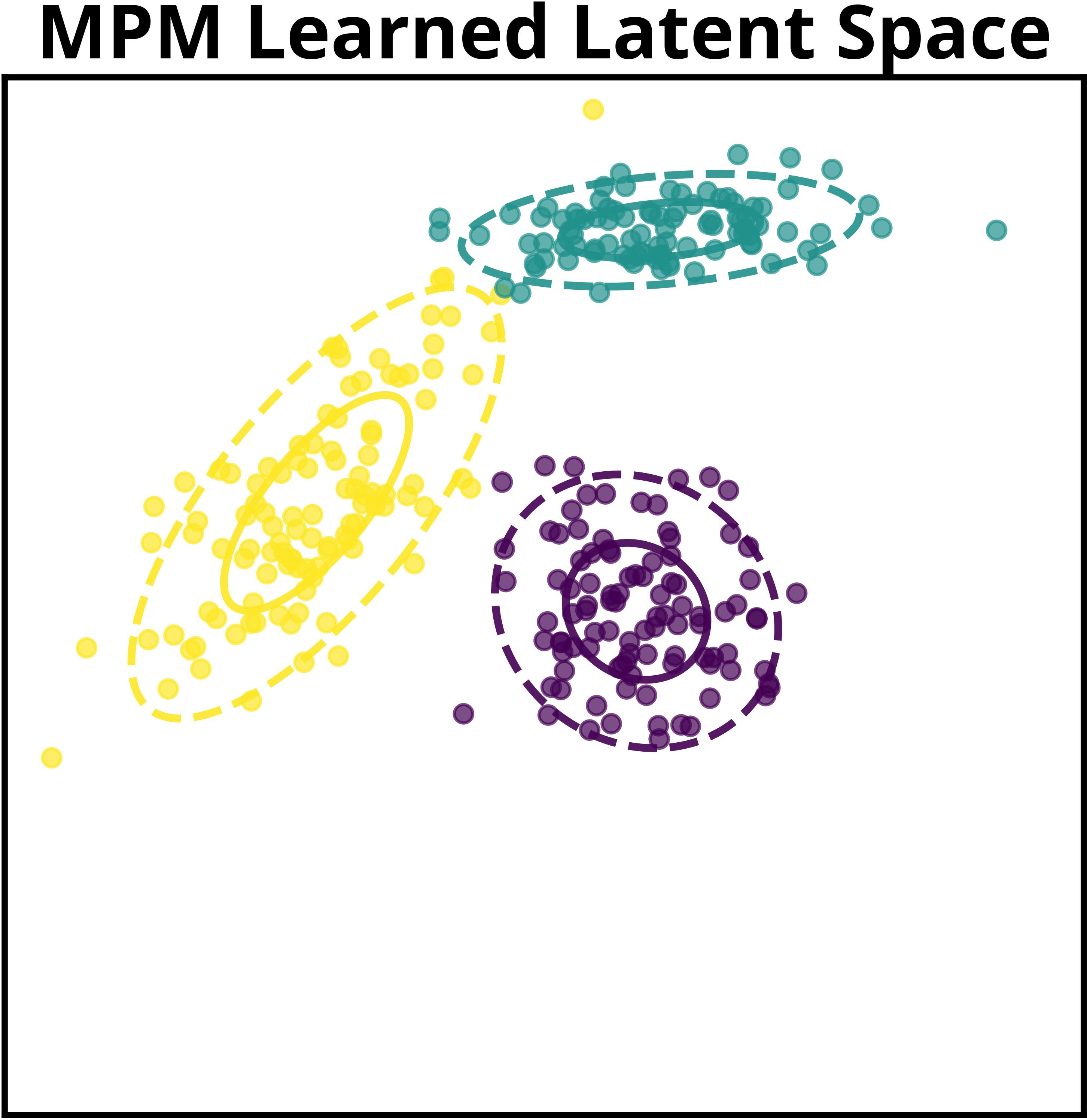
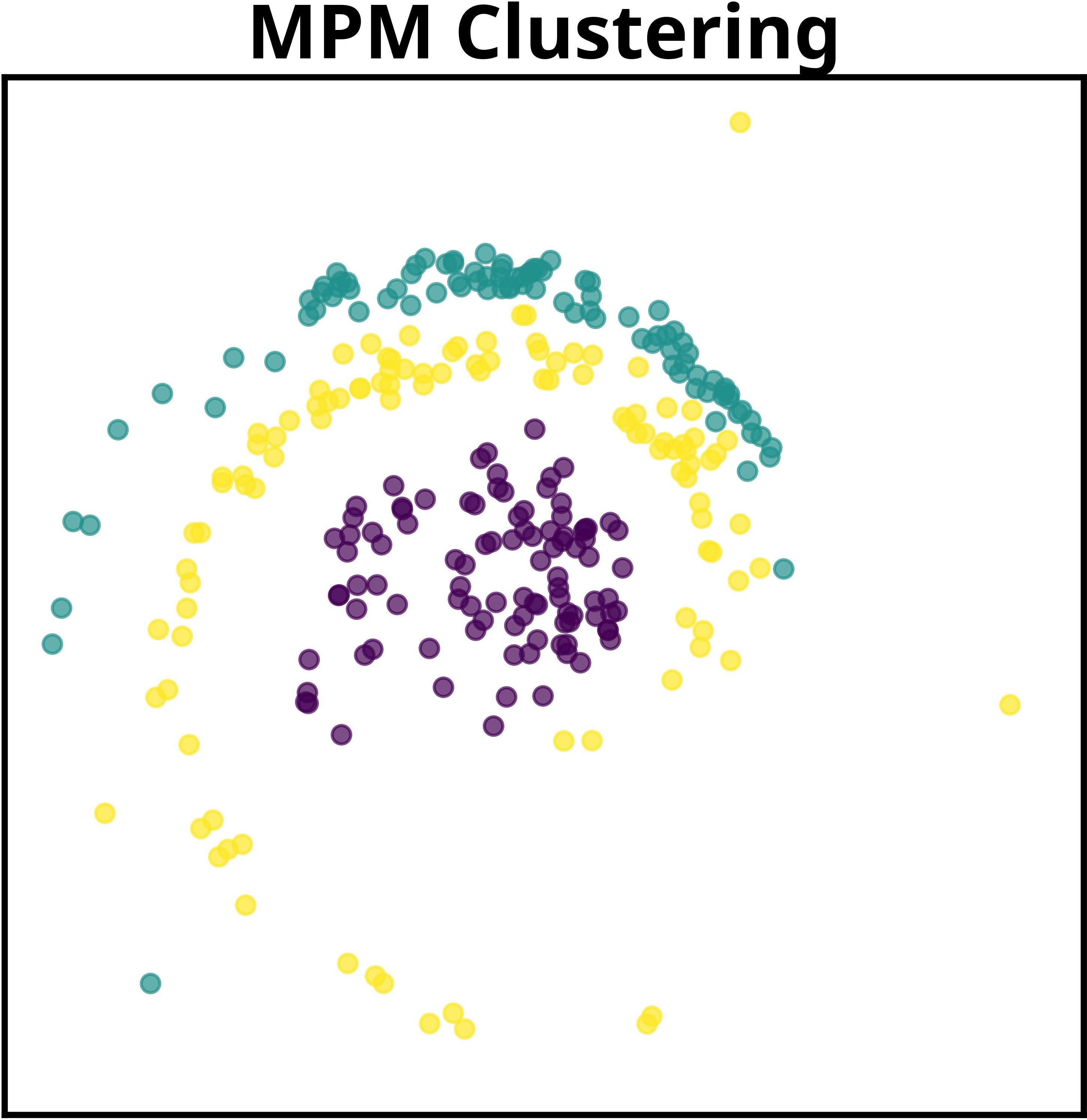
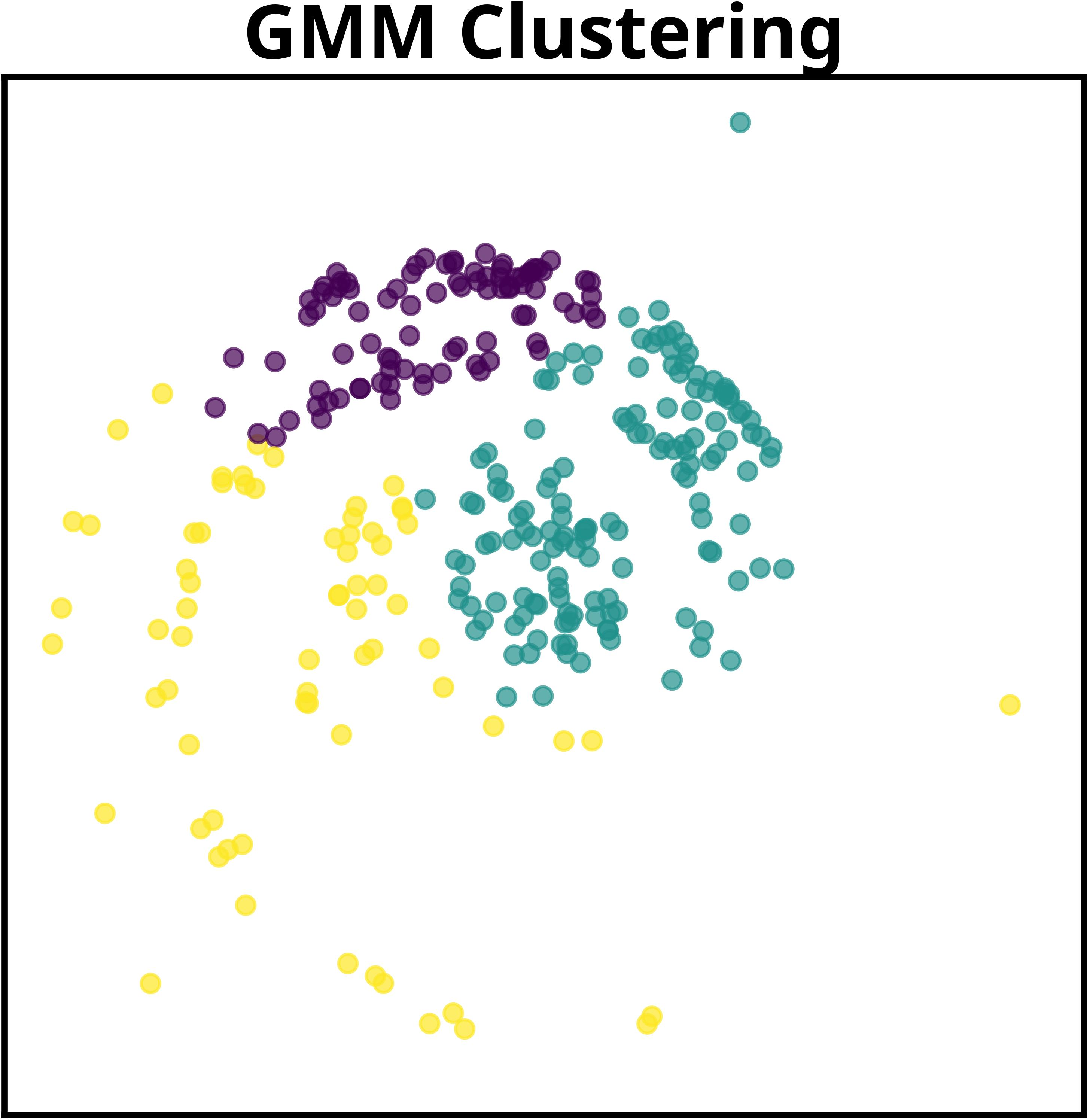
Figure 2: MPM jointly learns global model structure shared across datasets while adapting dataset-specific components, contrasting with prior approaches focusing exclusively on dataset-level structure.
Illustrative Examples and Analytical Properties
The paper details a motivating example in which multiple datasets, generated via GMMs and subject to a shared nonlinear transformation, cannot be reliably disentangled by traditional methods. MPM exploits the shared mapping to recover correct latent representations. The authors show that even without explicit knowledge of the transformation, sufficiently expressive neural parameterizations allow the method to identify informative latent structure using their surrogate objective.
A primary theoretical contribution is the demonstration that, with suitable choices of surrogate potential functions, analytic and efficient coordinate ascent updates are available for both the variational (posterior approximation) and model parameter steps. This yields closed-form solutions akin to those in classical EM for tractable subclasses, while supporting deep, nonlinear extensions.
A formal connection is also drawn between the MPM methodology and the slot attention mechanism for object-centric learning. The authors rigorously show that slot attention can be interpreted as a special case of MPM with particular parameterizations and update rules. This unification provides probabilistic underpinnings for slot attention's effectiveness and opens avenues for principled extensions, such as global object clustering across images.
Empirical Evaluation
The authors conduct empirical studies in two domains: object-centric image modeling (using Tetrominoes) and sequential text modeling (AP News corpus). In both settings, the MPM framework is instantiated to model dataset-level and global latent structure, demonstrating adaptability and interpretability.
For object-centric learning, each image serves as a dataset, with MPM grouping pixels based on shared visual roles and discovering global object prototypes. The model supports both mixture-based and additive decoders. Notably, in the additive decoder configuration, MPM achieves mean ARI of 97.76 ± 0.53, outperforming slot attention and direct GMM baselines. Even in the mixture-based setting, MPM produces more realistic object reconstructions compared to the GMM, particularly in color composition and segmentation masks.
In sequential text modeling, MPM models articles as datasets and words as data points, uncovering hierarchical topic embeddings. By incorporating contextualized token embeddings (via BERT) and positional encodings, MPM attains lower test-log-perplexity (14.15 ± 1.17) relative to LDA baselines.
Visualization of learned global clusters demonstrates MPM's capability to extract semantically meaningful attributes—object shape, color, and position in images; thematic coherence in text—across datasets, a task infeasible for methods lacking hierarchical global modeling.
Theoretical and Practical Implications
MPM's decomposition of global and local latent structure offers both theoretical and pragmatic benefits:
- Generalization Across Datasets: By learning global structure, MPM can transfer learned generative processes to previously unseen datasets, facilitating few-shot or zero-shot adaptation in both image and language domains.
- Latent Interpretability: The ability to visualize and analyze both dataset-specific and cross-dataset latent representations enhances model transparency, a critical feature for scientific domains where interpretability is essential.
- Unified Treatment of Existing Mechanisms: Slot attention and related object-centric learning frameworks are shown to be subsumed by MPM, with clarifications on their specific update strategies and limitations.
- Scalability and Tractability: The bi-level variational inference scheme, leveraging closed-form updates where possible, balances computational efficiency with representational power.
Prospects for Future Development
Potential directions stemming from this work include:
- Automated discovery of network architectures for the global generative process, tailored to specific domains via meta-learning.
- Extensions to other structured latent variable models (e.g., dynamical systems, hierarchical topic models) and richer forms of transfer across domains (cross-modal data, temporal adaptation).
- Integration of causal discovery mechanisms at the meta-level, allowing for interpretable, data-driven design of probabilistic programs.
- More sophisticated amortization and regularization schemes to further stabilize training in deep hierarchical settings and suppress posterior collapse.
Conclusion
Meta-probabilistic modeling provides a systematic framework for learning generative structure at both local and global levels, reconciling the interpretability of probabilistic graphical models with the flexibility of deep networks. The framework's efficient variational learning procedures, competitive quantitative results, and theoretical unification of related approaches establish a foundation for further advances in data-driven model discovery and transfer across multiple domains.