- The paper introduces a bi-actor, model-based framework that predicts unsafe states and plans actions to preemptively avoid safety violations.
- It leverages a Recurrent State-Space Model to simulate latent dynamics, enabling efficient policy improvement through separate reward-maximizing and safety-focused actors.
- The evaluation on Safety Gymnasium benchmarks shows near-zero safety violations and significant improvements in sample efficiency compared to traditional model-free approaches.
Nightmare Dreamer: Model-Based Safe RL via Predictive Planning and Bi-Actor Architecture
Introduction and Motivation
The proliferation of RL in robotics and other safety-critical domains has been hampered by inadequate safety assurances, particularly under high-dimensional input regimes such as vision. The paper "Nightmare Dreamer: Dreaming About Unsafe States And Planning Ahead" (2601.04686) addresses this fundamental bottleneck in SafeRL by proposing a novel model-based framework that leverages a learned world model for predictive safety planning. Unlike prior model-free SafeRL approaches (e.g., CPO, PPO-Lagrangian), which suffer from poor sample efficiency and struggle to maintain safety guarantees during learning, Nightmare Dreamer does not solely rely on reacting to violations; instead, it anticipates potential future unsafe states and proactively adjusts agent behavior.
Architecture and Algorithmic Contributions
Nightmare Dreamer's architecture is centered on a bi-actor critic schema, integrating two separate actors for reward maximization and constraint satisfaction, respectively, within a learned latent dynamics model framework. This division is critical for effective CMDP optimization.
Safe World Model Learning
The approach employs a Recurrent State-Space Model (RSSM) akin to the DreamerV2 architecture for high-fidelity latent dynamics modeling. The world model learns to encode observed images and actions into a latent space, enabling accurate rollout simulations that predict not only next observations and rewards but also per-action costs.
Bi-Actor Policy Structure
The formal division into a control actor (optimized for cumulative reward) and a safe actor (optimized for cost minimization) allows explicit modeling and separation of the contradictory RL objectives in CMDPs. Both actors are MLPs employing ELU activations and are trained independently using imagination rollouts in latent space. This design further facilitates efficient policy improvement without dangerous direct environment exploration.
Online Safety-Aware Planning
During deployment, the system performs multi-step rollouts for the currently observed embedding under the control policy. If at any step the predicted sum of future costs exceeds the safety budget, the agent switches action selection to the safe policy; otherwise, it continues with the control policy (Figure 1).
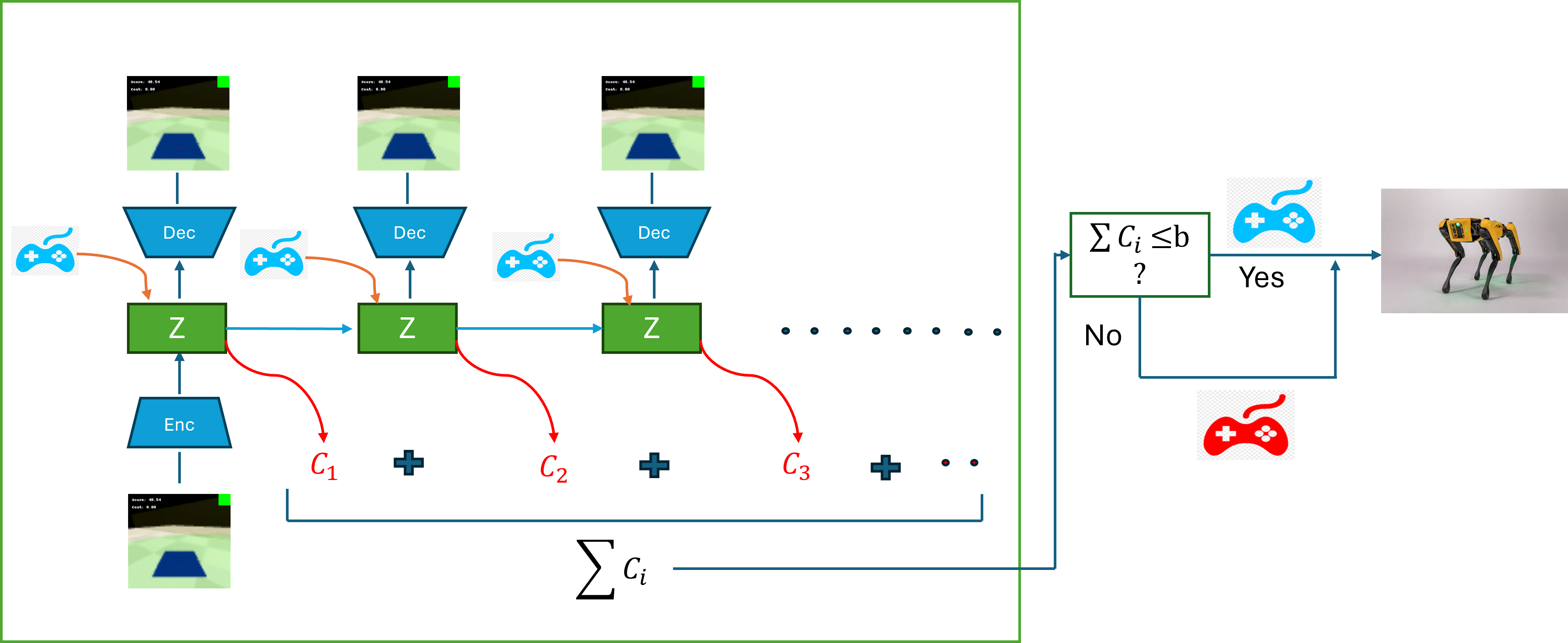
Figure 1: Action selection during environment interaction: The blue game pad signifies the control (reward-optimizing) actor’s action, while the red game pad represents the safe (constraint-satisfying) actor’s action.
This mechanism operationalizes a direct and responsive interface between safety prediction and action execution, contrasting with dual-aspect Lagrangian approaches that operate via scalar penalty coefficients.
Discriminator-Based Policy Regularization
A discriminator is trained to distinguish actions from the control and safe policies, and its signal regularizes the safe actor towards control-like behavior when no unsafe states are anticipated. This design moves beyond classical KL-based behavioral cloning, significantly improving training stability and transferability across tasks.
Empirical Evaluation and Results
The system is evaluated on the Safety Gymnasium benchmark, with focus on vision-based SafePointCircle and SafeCarCircle tasks featuring progressively tighter state constraints.
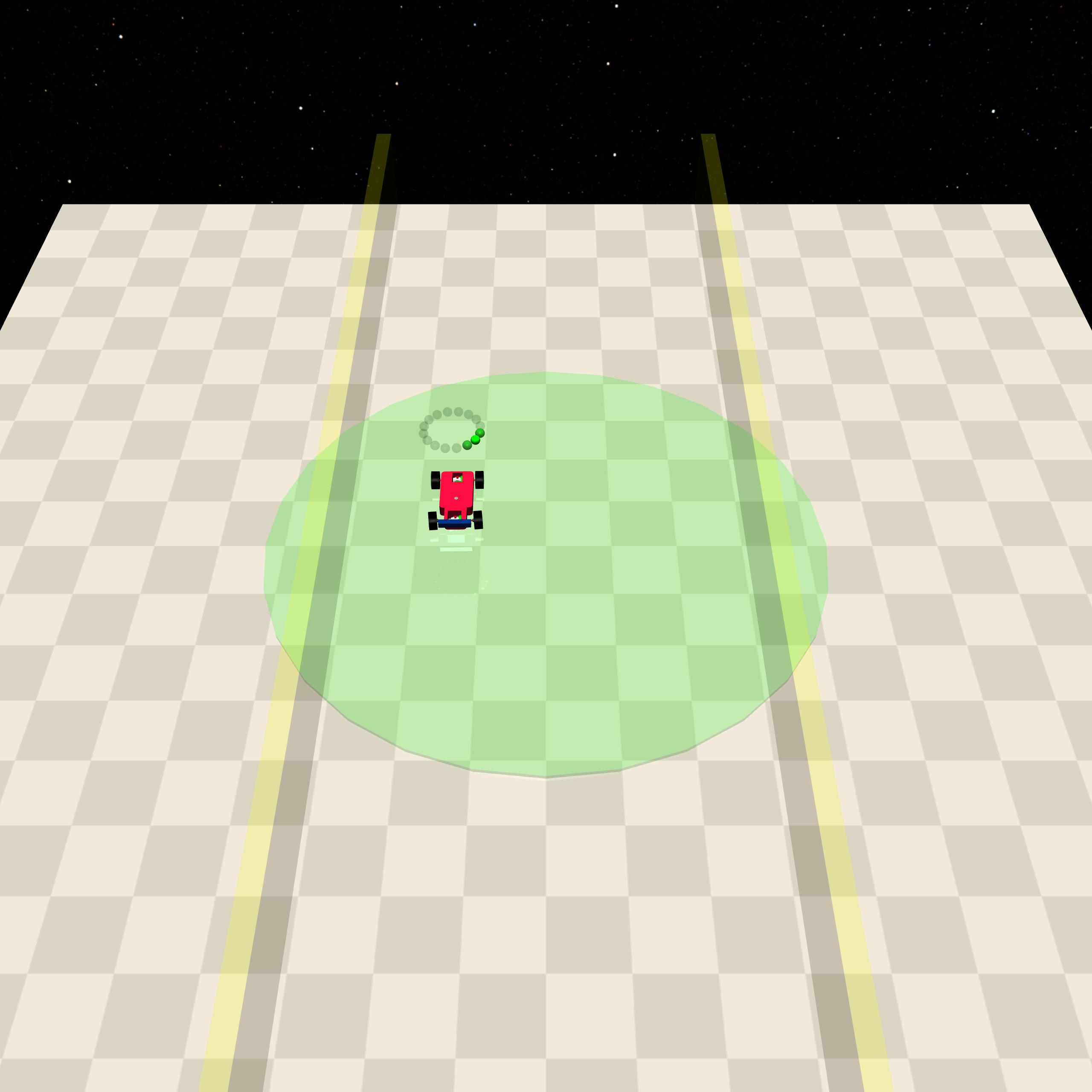


Figure 2: Visualization of “Circle 1,” a Safety Gymnasium environment requiring continual in-bound navigation under cost constraints.
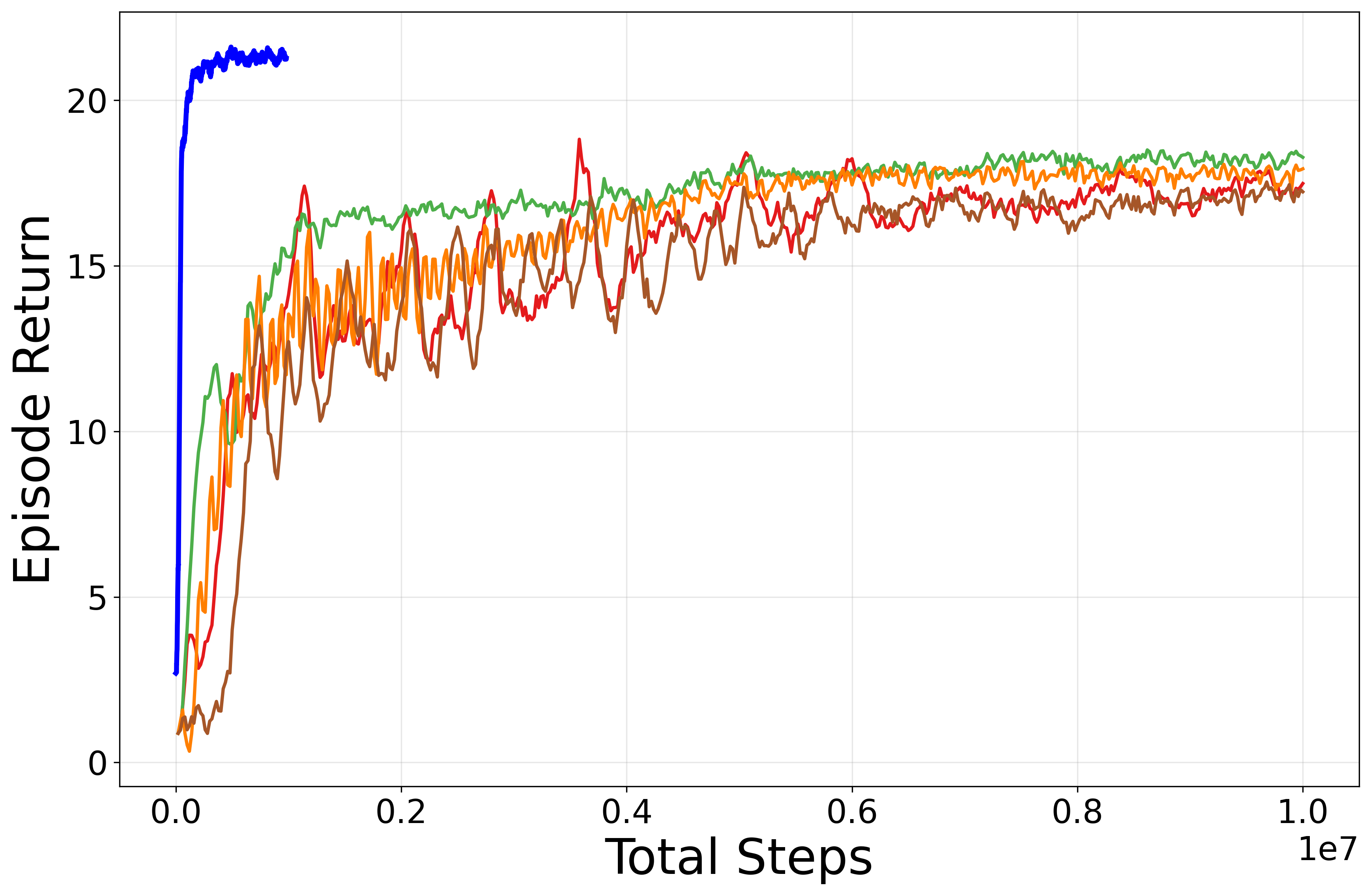
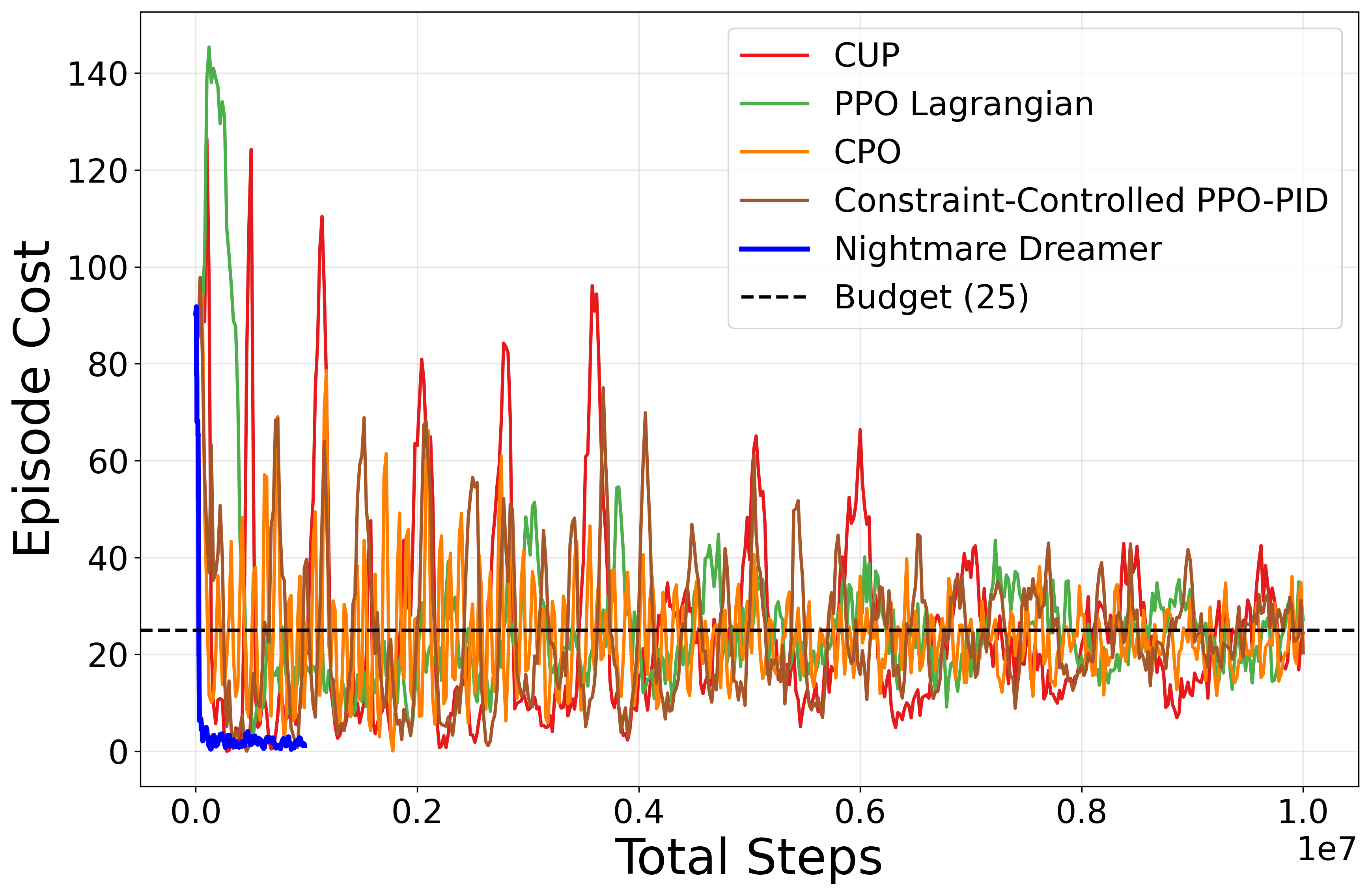
Figure 3: Task illustration for the Point agent in Circle1 with reward feedback.
Key reported quantitative results include:
- Near-zero safety violations throughout training and evaluation: Nightmare Dreamer maintains cost below the designated budget at all times.
- Substantial improvement in sample efficiency: Reaching parity with, or outperforming, baseline model-free SafeRL benchmarks within 1/20th of the environment interactions.
- Competitive standard task performance: The architecture does not trade off reward maximization to achieve lower costs, as is often observed in dual-objective approaches.
Such outcomes underline the effectiveness of the predictive planning mechanism in shielding the agent from unsafe regions even in highly exploratory, vision-based settings.
Implications and Future Directions
Practically, the proposed bi-actor, model-based approach represents a significant progression towards reliable deployment of RL in domains with stringent safety demands, such as autonomous robotics, industrial automation, and human-centric interaction. It demonstrates that model-based imaginary rollouts, when tightly coupled with explicit policy switching and discriminator-based regularization, can simultaneously enforce safety and enable efficient learning from visual input.
On a theoretical level, Nightmare Dreamer paves the way for more fine-grained, modular policy structures within CMDPs, where safety-constraint satisfaction is decoupled but not divorced from reward seeking. The complementary use of discriminators as regularizers for safety-aligned yet goal-consistent behaviors is also a promising line for subsequent research in hierarchical or meta-controller architectures.
Extensions to more complex or dynamic constraints, integration with uncertainty estimation techniques, and deployment in real-world robotic platforms are indicated as immediate future directions. The framework offers a blueprint for formulating SafeRL algorithms that are robust, data-efficient, and generalizable across sensory modalities and task genres.
Conclusion
Nightmare Dreamer (2601.04686) advances SafeRL by fusing bi-actor policy learning with world-model-based predictive safety planning and discriminator-guided policy alignment. Results exhibit substantial gains in sample efficiency and robust constraint satisfaction on visually rich safety-critical benchmarks. The study underscores the increasing viability of model-based SafeRL approaches for deployment in practical, high-stakes autonomous systems, with multiple avenues for scaling and extension to broader classes of safety-constrained problems.