- The paper introduces EDL as a novel metric measuring the excess information captured during fine-tuning by comparing prequential MDL with test loss.
- EDL offers a framework to distinguish between elicited latent capabilities and genuine acquisition of new, task-specific information.
- Empirical evaluations using toy models demonstrate that EDL effectively differentiates between memorization and true generalizable learning.
Excess Description Length of Learning Generalizable Predictors
The paper "Excess Description Length of Learning Generalizable Predictors" (2601.04728) presents a comprehensive mathematical framework aimed at understanding the nature of capabilities acquired or elicited during the fine-tuning of LLMs. This exploration is centered around an information-theoretic metric: Excess Description Length (EDL), developed as an empirical tool to measure the amount of information a model absorbs when transitioning from a baseline to a fine-tuned state.
Definition and Importance of EDL
EDL is introduced through the concept of prequential minimum description length (MDL). In this framework, MDL represents the cumulative bits required to sequentially encode training labels using the evolving predictions of a model being trained online. The MDL reflects the total information content supplied to the model during training. Coupled with the finalized test loss of the trained model, EDL quantifies the difference between this minimum description length and the number of bits the model would use to encode new samples given its final form. Essentially, EDL captures the generalizable predictive information that the model's parameters have internalized from the training dataset.
Properties and Theoretical Underpinnings
The authors establish EDL as a non-negative quantity in expectation with convergence to surplus description length in the infinite data limit. Critically, EDL provides formal bounds on potential generalization improvements, situating it as a powerful diagnostic tool for understanding model learning dynamics. Through an exploration of toy models, the paper underscores scenarios where EDL effectively distinguishes between elicitation (surfacing latent capabilities) and genuine teaching (acquisition of novel capabilities).
EDL is formally defined as:
$\mathrm{EDL}(D; \theta_0, A) = \mathrm{MDL}(D; \theta_0, A) - n \cdot L_{\mathrm{test}(\theta^*).$
Here, MDL(D;θ0,A) is the cumulative codelength of training dataset D encoded using initial model parameters θ0 and training algorithm A. The test loss $L_{\mathrm{test}(\theta^*)$ of the final model provides a lower bound on the residual data entropy. The convergence characteristics to minimum description length principles further assure that EDL properly encapsulates the model's learning efficacy.
Practical Implications
Empirical Utility of EDL
The introduction of EDL offers researchers a formal method to dissect the informational exchange during model fine-tuning, thus facilitating deeper insights into how models transform their initial latent capabilities into task-specific performance improvements. EDL serves as an evaluative measure that allows for the differentiation between mere memorization of training data and genuine absorption of task-relevant structure, characterized by improved prediction on unseen data.
Impacts on AI Development and Safety
EDL provides a diagnostic for evaluating whether a capability is latent or must be instilled through new data. A significant reduction in EDL signals efficient elicitation with minimal examples, whereas high EDL may be indicative of extensive teaching requirements. In safety contexts, this distinction is pertinent—latent capabilities can be surfaced with fewer resources, thus presenting lower barriers for potentially harmful applications.
Toy Models
The paper elucidates EDL's applicability through several toy models, which serve to illuminate typical learning dynamics:
- Random Labels: Demonstrates near-zero EDL, affirming that EDL measures learnable structure rather than arbitrary data exposure.
- Hypothesis Collapse: Illustrates how a single example can resolve uncertainty across many hypotheses, optimizing EDL absorption within limited examples.
- Coupon Collector: Highlights the importance of concept coverage in learning, stressing the efficiency of additional examples as they become less informative after certain thresholds.
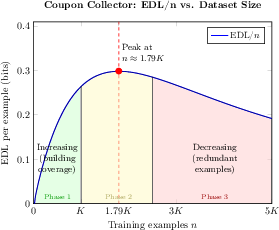
Figure 1: In the low-coverage regime (Phase 1, green), additional examples provide opportunities to learn generalizable patterns from relatively few known concepts. The rate of information absorption peaks as full coverage of concepts is approached (Phase 2, yellow). Beyond the coverage threshold (peak), learning enters the full-coverage regime (Phase 3, red), as additional examples yield diminishing predictive information that can be absorbed.
Conclusion
By providing a precise mathematical basis for evaluating learning efficiency, "Excess Description Length of Learning Generalizable Predictors" advances our understanding of model evolution from generalized to task-specific predictors. Crucially, EDL quantifies the absorbed informational content, furnishing clarity on the nature of capability acquisition during fine-tuning. This analytical tool opens further inquiry into AI safety and optimization by allowing for empirical scrutiny of the informational demands and constraints intrinsic to modern machine learning paradigms.

