- The paper introduces projective conditioning as a robust alternative to Plücker ray conditioning, improving feed-forward view synthesis by encoding inputs as projection images.
- It leverages a masked auto-encoding pretraining strategy combined with DINOv3 features to boost data efficiency and perceptual quality.
- Experiments show significant PSNR gains and enhanced geometric consistency under camera perturbations compared to traditional methods like LVSM.
Projective Conditioning for Robust Feed-Forward View Synthesis
Introduction
"From Rays to Projections: Better Inputs for Feed-Forward View Synthesis" (2601.05116) presents a significant reevaluation of input conditioning for feed-forward novel view synthesis models. The paper identifies critical instability issues with absolute Plücker ray conditioning—a representation underpinning recent scalable view synthesis transformers such as LVSM. The authors propose projective conditioning, wherein models are supplied with point cloud projection images derived from context views and depths, shifting the paradigm from brittle geometric regression in high-dimensional ray space to a stable, visually coherent 2D image-to-image translation. A dedicated masked auto-encoding pretraining strategy leverages this 2D structure, enabling scalable self-supervised training on uncalibrated data.
Analysis of Ray Conditioning Instabilities
Conventional large view synthesis models encode pixel-wise camera rays using Plücker coordinates, treating the synthesis task as absolute regression in 6D ray space. This framework is theoretically problematic: Plücker coordinates vary non-smoothly under global SE(3) or Sim(3) transformations, and even small camera movements result in distributed, non-local perturbations of input tokens. The neural backbone thus overfits to arbitrary world coordinate gauges, manifesting in severe degradation when subjected to basic camera operations:
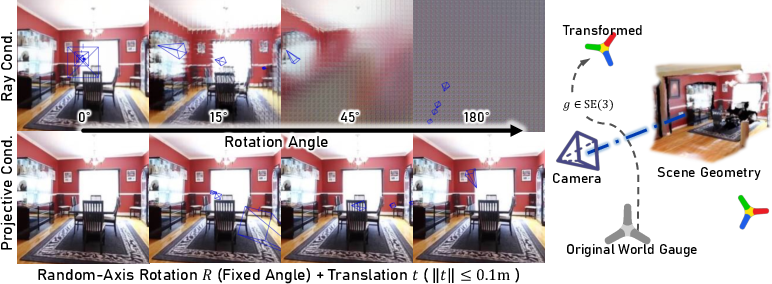
Figure 1: Under a random global SE(3) transformation, ray-conditioned models fail while projective conditioning remains robust.
Empirical results demonstrate pronounced artifacts and collapse in LVSM and related ray-conditioned approaches under coordinate changes, as well as common field-of-view, aspect-ratio, or roll modifications. These findings reveal Plücker rays as an over-parameterized, gauge-dependent representation ill-suited for consistent 3D rendering.
Projective Conditioning: Methodology
Projective conditioning eschews explicit camera parameter embeddings. Instead, depth maps are extracted from context views using off-the-shelf perception models, then unprojected and rasterized into a unified point cloud as observed from the target frustum. The resulting point cloud projection image encodes geometric relationships as a stable, camera-invariant 2D buffer. The model thus receives both context RGB images and the projection cue, facilitating robust completion of target views via image-to-image mapping.
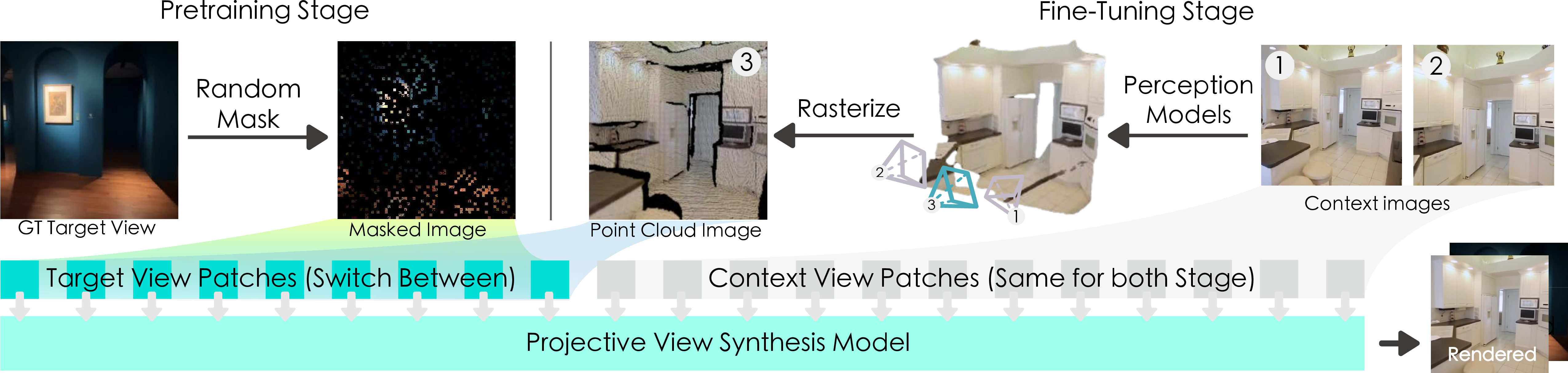
Figure 2: An overview of the two-stage training pipeline. Pretraining is self-supervised and fine-tuning uses projected point clouds providing geometric cues.
A decoder-only ViT backbone processes patch-wise tokens from context images, DINOv3 features, and the point cloud projection. To ensure token uniqueness, positional rotary embeddings (RoPE) are applied, addressing ambiguities arising from patchification of empty regions in the projection image.
The authors provide a formal quotient-space interpretation: projective conditioning maps the configuration space of context images, depths, and camera poses into the quotient space modulo global SE(3) transformation. Thus, the input is invariant by construction, eliminating the need for network-learned coordinate invariance.
Masked Auto-Encoding Pretraining
Masked auto-encoding (MAE) is adopted for pretraining, exploiting the structural similarity between sparsified, randomly masked target images and point cloud projection images. The network—conditioned on context views and corrupted targets—learns powerful cross-view completion priors in a fully self-supervised regime. Fine-tuning then proceeds with projective cues, drastically reducing dependence on labeled RGB-D data and improving efficiency.

Figure 3: Pretraining reconstructs the target view from a masked version; fine-tuning uses warped projections into the target frustum.
Experimental Results
The proposed framework is evaluated on a new consistency benchmark simulating out-of-distribution camera transformations, as well as sparse-view synthesis benchmarks derived from RealEstate10K and DL3DV. Projective conditioning shows marked improvements over both ray-conditioned ViT models and feed-forward 3D Gaussian approaches.
- On consistency (robustness to camera perturbations), the model achieves up to 25.43 PSNR under World Scale transformations versus LVSM's 14.56, with significant gains across all tested axes (aspect, FOV, roll).
- On RealEstate10K sparse-view synthesis:
- 24-layer projective model: 28.60 PSNR on large overlap; 26.88 PSNR on medium; 24.98 PSNR on small.
- Outperforming comparable LVSM variants, especially under challenging overlaps and disocclusion scenarios.
Qualitative results further indicate improved geometric consistency and reduction of artifacts compared to AnySplat, WorldMirror, LVSM, and RayZer baselines.

Figure 4: Consistency benchmark demonstrating superior geometric coherency. LVSM, RayZer, and AnySplat exhibit inconsistencies and errors under camera alteration.

Figure 5: Qualitative comparisons on RealEstate10K. Orange and blue boxes highlight failure modes in other models, with projective conditioning maintaining structural fidelity.
Efficiency analyses show reduced processing time over 3D Gaussian approaches and competitive rendering throughput.
Ablation Studies
Ablations confirm the merit of each architectural innovation:
Implications and Prospects
The reframing of feed-forward view synthesis as a quotient-space structured image-to-image problem demonstrates that removing over-parametrization from the input is critical for generalization, consistency, and controllability. Projective conditioning sidesteps notorious "train–test gap" issues in coordinate gauges and enables camera-robust, high-fidelity synthesis with practical runtime.
Practically, the approach greatly enhances the scalability and deployment of view synthesis models in unconstrained, dynamic environments, with direct utility for robotics, AR/VR, and content creation where on-the-fly camera motion and scene interaction are prevalent.
Theoretically, this quotient-based input design opens new research avenues into generalized scene representations, dynamic scene adaptation, and further extension to temporal and deformable entities. The masked auto-encoding pretraining regime signals a promising direction for harnessing vast, unlabeled 2D/3D data in visual LLMs and universal scene synthesis.
Conclusion
This work demonstrates that projective conditioning fundamentally improves feed-forward view synthesis, addressing the brittleness of coordinate-dependent ray embeddings and enabling robust, consistent, and scalable novel view synthesis. Strong empirical results substantiate the approach's effectiveness, with pretraining and architectural choices further boosting data efficiency and quality. Future work may extend projective conditioning to dynamic and temporal scenarios, enriching the compositional and interactive capabilities of 3D scene synthesis.
