VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
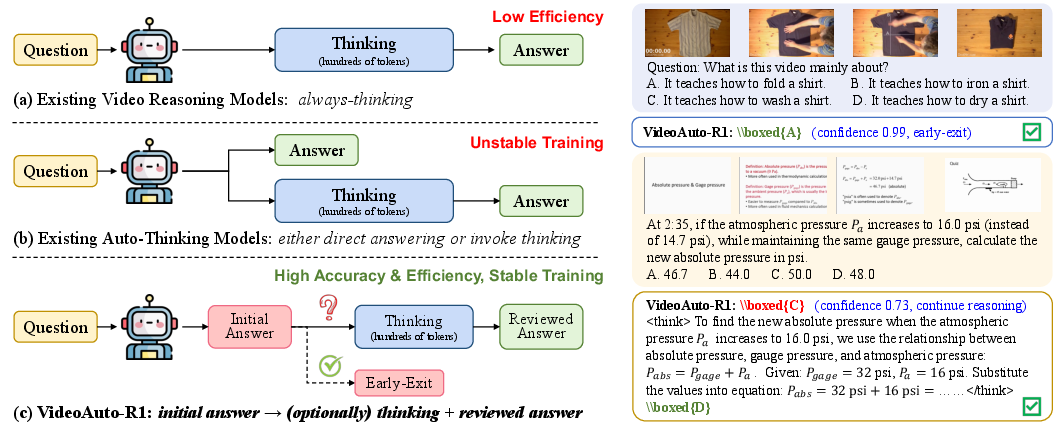
Abstract: Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal LLMs on video understanding tasks. However, its necessity and advantages over direct answering remain underexplored. In this paper, we first demonstrate that for RL-trained video models, direct answering often matches or even surpasses CoT performance, despite CoT producing step-by-step analyses at a higher computational cost. Motivated by this, we propose VideoAuto-R1, a video understanding framework that adopts a reason-when-necessary strategy. During training, our approach follows a Thinking Once, Answering Twice paradigm: the model first generates an initial answer, then performs reasoning, and finally outputs a reviewed answer. Both answers are supervised via verifiable rewards. During inference, the model uses the confidence score of the initial answer to determine whether to proceed with reasoning. Across video QA and grounding benchmarks, VideoAuto-R1 achieves state-of-the-art accuracy with significantly improved efficiency, reducing the average response length by ~3.3x, e.g., from 149 to just 44 tokens. Moreover, we observe a low rate of thinking-mode activation on perception-oriented tasks, but a higher rate on reasoning-intensive tasks. This suggests that explicit language-based reasoning is generally beneficial but not always necessary.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI to understand videos more efficiently. Many AI models use “chain-of-thought” (CoT) reasoning, which means they write out step-by-step explanations before giving an answer. That can help on hard problems, but it also takes longer. The authors ask: do video models always need to “think out loud,” or can they often just answer directly? They then introduce a new system, called VideoAuto-R1, that decides when to think and when to answer straight away, so it stays accurate while being much faster.
Key Questions
The paper explores three simple questions:
- Do video models really need step-by-step reasoning every time?
- Can an AI learn to give a quick answer first, then think more only if needed?
- Will this “think-when-necessary” approach be both accurate and faster than always thinking?
How the Research Was Done
To make this understandable, think of how you solve school problems:
- If a question is easy, you answer it right away.
- If it’s tricky (like a multi-step math problem), you write out your reasoning to make sure you’re correct.
The AI in this paper does something similar using a training and testing strategy called “Thinking Once, Answering Twice.”
The Training Approach (like practice rounds)
- The AI is trained to always produce three parts in order: 1) First, a short initial answer (in a box). 2) Then, a hidden reasoning section (like notes to itself). 3) Finally, a reviewed final answer (in another box), which can confirm or correct the first one.
- If the question is too hard to answer directly, the AI is allowed to put a placeholder first, like “Let’s analyze the problem step by step,” and then do the reasoning and give a final answer.
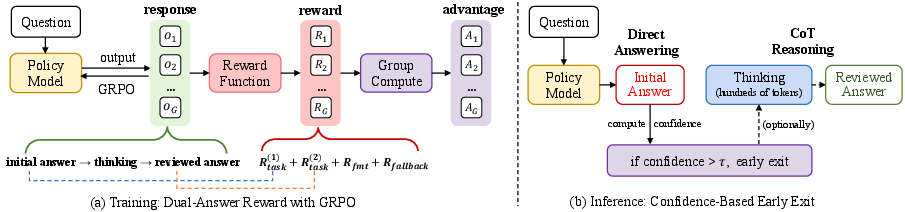
- The AI gets “points” (rewards) for correct answers and for following the format. The final answer earns more points than the initial answer, encouraging the AI to check itself and improve.
- The training method is called reinforcement learning (RL). An analogy: the AI tries different answers, gets scored, and learns what works best—like practicing with feedback.
- A specific RL method called GRPO is used. Think of GRPO as a fair scoring system in a group contest: the model generates several answers, each gets a score, and the scores are adjusted within the group so the model can learn which answers are better than average.
The Testing Approach (like the real exam)
- When the AI is used for real, it gives the first answer and also measures how confident it is in that answer (like asking itself, “How sure am I?”).
- Confidence is estimated from its own token predictions (you can think of this as “how sure it was about each word in its short answer”).
- If the AI is confident enough, it stops early and doesn’t do the long reasoning. If it’s not confident, it continues and writes out its thinking and final answer.
- This “early exit” saves time and computing power because it avoids long explanations when they’re not needed.
What kinds of tasks were tested?
- Video QA: Answer questions about what’s happening in a video (like “What is the person doing?”).
- Temporal grounding: Find the exact time segment in a video that matches a description (like “When does the ball go into the goal?”).
- Reasoning-heavy video benchmarks: Harder questions that need multi-step thinking (like physics or math problems shown in videos).
- They also checked some image-based reasoning tasks to see if the idea generalizes beyond video.
Main Findings and Why They Matter
- Direct answers can be as good as, or even better than, always using chain-of-thought on many video tasks. In other words, long explanations aren’t always useful for videos.
- VideoAuto-R1 learns to answer quickly first, and only think more when needed. This keeps accuracy high while making the AI much faster.
- Big efficiency win: the average response length shrank by about 3.3 times (from 149 tokens to just 44). Shorter answers mean faster replies and lower cost.
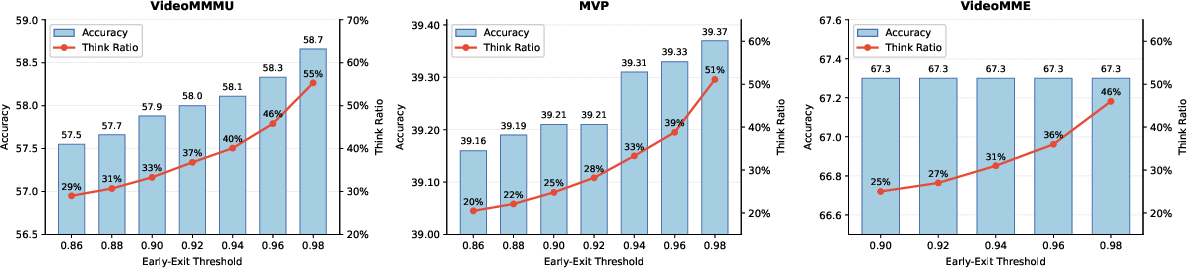
- Smart thinking activation:
- On simple, perception-focused tasks (like recognizing objects or actions), the AI rarely needs to think out loud (about 25% of the time).
- On complex, reasoning-heavy tasks, it thinks more often (about 51% of the time).
- This shows the model can “budget” its thinking: spend time where it matters most.
- Strong performance: VideoAuto-R1 reached state-of-the-art accuracy on several video question-answering and grounding benchmarks, and also showed improvements on challenging image benchmarks.
- No extra labels needed: The model didn’t need special “think” vs “no-think” labels during training. It simply learned the “answer → think → answer” format and used confidence to decide at test time.
Implications and Impact
- Faster, cheaper AI: By avoiding unnecessary explanations, the model responds sooner and uses less compute. This is great for real-world uses like mobile apps, online assistants, or any system that needs quick, low-cost video understanding.
- Smarter reasoning usage: The model “thinks” when it helps and skips it when it doesn’t—like a student who shows work for hard problems but answers easy ones directly.
- Better design for video AI: In videos, a lot of the challenge is seeing and recognizing correctly. Long step-by-step reasoning isn’t always helpful there. This paper encourages AI builders to use adaptive reasoning instead of always-on reasoning.
- Generalization: The same idea can help with images and other tasks, not just videos. It’s a practical blueprint for making reasoning both efficient and effective.
In short, VideoAuto-R1 shows that AI can be both smart and practical by thinking only when necessary—keeping accuracy high while saving time and resources.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper that future work could address:
- Confidence routing calibration and generality: The early-exit threshold τ is fixed (0.97) and tuned on held-out data; its robustness across datasets, tasks (MCQ vs open-ended), model sizes (7B vs 8B+), and decoding settings (temperature/beam) is untested. A systematic sensitivity and per-task calibration study is missing.
- Alternative routing signals: The method uses mean log-probability of the first answer as confidence. It remains unknown whether entropy, variance across stochastic decodes (self-consistency), verifier models, or uncertainty quantification (e.g., ensembles, dropout) yield better accuracy–efficiency trade-offs.
- Routing precision/false positives: The paper reports recall on “think-needed” cases (a1 wrong → a2 correct) but does not quantify precision (cases where thinking is triggered yet yields no gain). Understanding and reducing unnecessary CoT activations is an open problem.
- Overconfidence and miscalibration: RL can sharpen token probabilities, potentially inflating confidence for wrong a1 answers. The extent of miscalibration under distribution shift (e.g., new domains, longer videos) is not measured; calibration techniques (temperature scaling, ECE/MCE reporting) are unexplored.
- Fallback mechanism brittleness: Reliance on a fixed English fallback string ("Let's analyze the problem step by step") raises questions about multilingual robustness, susceptibility to prompt injection (user-provided identical phrase), and potential gaming of the fallback reward.
- Reward design sensitivity: The dual-answer reward uses specific weights (w2 > w1, α for fallback, λ for format). There is no reported sensitivity analysis of these hyperparameters, nor mitigation strategies for cases where a correct a1 is wrongly “revised” to an incorrect a2.
- Reasoning quality is unverified: The rationale r is not rewarded for factuality or logical soundness. The model may produce persuasive but incorrect CoT. Methods to verify or train for truthful/causal rationales (e.g., rationale verifiers, critique-and-repair) are not explored.
- Scope beyond verifiable tasks: The framework assumes verifiable rewards (accuracy, IoU). Extending to open-ended video tasks lacking automatic verifiers (narrative QA, causal explanation, commonsense justification) remains open.
- Scaling to longer/streaming videos: Experiments cap frames/tokens (e.g., up to 2048 frames, 128K tokens). Performance and routing behavior on hour-long streaming videos, memory-constrained setups, or sliding-window inference are not studied.
- Frame selection and tool use: The auto-think controller does not integrate progressive perception (“thinking with frames”), retrieval, or external tools. Can routing jointly decide when to think and when to fetch higher-resolution frames or call tools?
- Visual encoder rigidity: The visual encoder is frozen. How much could encoder fine-tuning (or adapters) improve perception and reduce unnecessary thinking? The perception–reasoning trade-off is not dissected.
- Base-model dependence: Results are shown on Qwen2.5-VL and Qwen3-VL. Generality to other MLLM backbones (e.g., InternVL, LLaVA-Next, Idefics) and to larger models is untested.
- Data coverage and rarity of must-think cases: Training uses 83K curated samples with mixed video/image/text sources. Coverage of rare temporal reasoning patterns, compositional multi-event queries, occlusions, and hard negatives is unclear; active mining of “must-think” video cases is an open direction.
- Robustness to real-world noise: Effects of compression artifacts, motion blur, camera shake, abrupt cuts, and domain-shifted content (egocentric, surveillance, medical) are not evaluated.
- Audio/subtitles integration: Many video reasoning tasks depend on audio or ASR. The approach is evaluated “without subtitles” on some sets and does not incorporate audio; extending auto-thinking to tri-modal video–audio–text remains unexplored.
- Efficiency beyond token counts: While response tokens are reduced ~3.3×, there is no end-to-end latency, throughput, or energy/cost analysis across hardware, batch sizes, and long-context settings; overhead of computing log-probs for routing is not quantified.
- Fairness and reproducibility of comparisons: Although re-evaluations standardize some constraints, potential residual confounds remain (prompt differences, decoding, context packing). Variance across seeds and multiple training runs is not reported.
- Understanding CoT underperformance: The paper observes cases where CoT hurts accuracy but does not analyze why (e.g., distractor reasoning, anchoring, length-induced drift). Methods to detect and prevent “overthinking” remain open.
- Early-exit granularity: Routing is decided only after the first answer. Exploring multi-stage exit (e.g., after brief reasoning segments), budgeted decoding, or adaptive reasoning-length control is left for future work.
- User preference and explainability: Some applications require justifications. How to balance auto-think efficiency with user demands for explanations, and how user-configurable policies affect performance and trust, is unaddressed.
- Safety and content risks: The model prints internal monologue in > tags; implications for privacy, leakage of sensitive content, or unsafe reasoning are not discussed. Hidden-CoT vs visible-CoT trade-offs are open.
Temporal grounding CoT utility: The conclusion that CoT adds little to localization is drawn on selected datasets; whether structured reasoning helps on harder grounding scenarios (e.g., long-range dependencies, counterfactual pairs) remains unclear.
- Threshold selection methodology: A single τ works “in practice,” but there is no principled selection method (e.g., cost-aware utility, ROC-based choice) or adaptive online calibration under non-stationary inputs.
- Interaction with non-greedy decoding: All evaluations use greedy decoding. How sampling (temperature, nucleus) affects both confidence estimates and routing accuracy is unknown.
- Contamination checks: Given mixed-source training data, rigorous checks for benchmark leakage and their impact on the claimed gains are not reported.
- Memory and video token load: Early-exit reduces text tokens, but video tokens dominate compute for long inputs. Methods to jointly route perception cost (e.g., adaptive tokenization, frame dropping) are not addressed.
- Multi-lingual and cross-cultural generalization: Benchmarks are primarily English; performance and routing behavior in other languages and cultural contexts are untested.
- Ambiguity handling and abstention: For ambiguous or multi-valid-answer questions, confident a1 might still be unacceptable. Mechanisms to abstain, request clarification, or defer are not incorporated.
- Training stability of GRPO: While hyperparameters are listed, stability across seeds, rollout size G choices, KL penalties, and reward sparsity is not analyzed; convergence and failure modes (e.g., mode collapse to fallback) require deeper study.
- Human evaluation of rationales: No human studies assess rationale helpfulness, correctness, or user trust impacts of auto-thinking vs always-thinking strategies.
Practical Applications
Immediate Applications
Below is a concise set of practical, deployable use cases that leverage the paper’s “thinking once, answering twice” training paradigm and confidence-based early-exit inference to improve accuracy and efficiency in video understanding.
- Video analytics and search in media platforms (Software, Media/Entertainment)
- Application: Integrate VideoAuto-R1 into video QA/search to answer user queries about scenes, objects, and actions with minimal latency and cost.
- Workflow/Product: An API wrapper that returns the initial boxed answer plus a confidence score; only triggers chain-of-thought (CoT) when confidence is below a threshold.
- Benefits: ~3.3x reduction in tokens per response; lower cloud inference cost; faster user experiences.
- Assumptions/Dependencies: Access to VL model weights or API; reliable verifiable rewards for QA correctness; tuned confidence threshold per domain.
- Video editing “find-clip” features using temporal grounding (Creative software, Media Production)
- Application: Automatically localize segments in long videos based on natural language queries (e.g., “find when the presenter demonstrates the device”).
- Workflow/Product: Use the initial boxed answer for start/end timestamps; early-exit by default since CoT rarely improves localization.
- Benefits: Improved mIoU on Charades-STA/ActivityNet; responsive UI for editors.
- Assumptions/Dependencies: Sufficient video token budget; domain-specific prompts; format-adherence in outputs.
- Surveillance and safety event localization (Public safety, Retail operations)
- Application: Rapidly detect and localize events (falls, theft, intrusion) within multi-camera feeds.
- Workflow/Product: Real-time inference with early-exit for perception-heavy cases; CoT only for ambiguous sequences.
- Benefits: Lower latency and compute; scalable deployment across cameras.
- Assumptions/Dependencies: Robustness to visual noise and frame-rate variations; privacy/security compliance; calibrated thresholds per site.
- Sports analytics and highlight generation (Sports media)
- Application: Auto-segmentation of plays and key moments; quick QA about player actions.
- Workflow/Product: Temporal grounding for highlight detection; QA for commentary assistants.
- Benefits: Faster turnaround for content teams; reduced manual review.
- Assumptions/Dependencies: Domain prompts and reward designs tailored to sports events; video resolution and codec variability.
- E-commerce product video Q&A (Retail)
- Application: Answer questions about product features demonstrated in videos (color, size, usage).
- Workflow/Product: Chat widget that returns initial answer with a confidence score; invokes reasoning for tricky comparisons or multi-step explanations.
- Benefits: Improved customer self-service; reduced support load.
- Assumptions/Dependencies: Product-specific fine-tuning; verifiable QA reward functions; consistent lighting and angles.
- On-robot perception with selective reasoning (Robotics)
- Application: Use direct answers for routine perception (object/action recognition); trigger CoT for spatial/temporal ambiguities.
- Workflow/Product: Confidence-gated perception module on robot; budget-aware reasoning to meet real-time constraints.
- Benefits: Reduced compute on edge hardware; more reliable decisions for complex tasks.
- Assumptions/Dependencies: Edge-optimized VL models; calibrated thresholds for on-device sensors; real-time token logprob access.
- Interactive learning from instructional videos (Education)
- Application: Tutor systems that answer questions on math/physics videos; CoT activated on symbol-heavy or multi-step reasoning tasks.
- Workflow/Product: Video classroom assistant with dual-answer template; fallback string (“Let’s analyze…”) to defer reasoning safely.
- Benefits: Accurate answers when needed; efficient responses otherwise.
- Assumptions/Dependencies: Benchmarks and data resembling VideoMMMU; domain-specific evaluation rubrics.
- Contact center triage for video attachments (Enterprise software)
- Application: First-pass analysis of customer-submitted videos to identify the issue; escalate with CoT for nontrivial cases.
- Workflow/Product: Ticketing integrations that embed the initial answer, confidence score, and optional reviewed answer.
- Benefits: Reduced handling time; clearer handoffs to human agents.
- Assumptions/Dependencies: Privacy and data governance; verifiable rewards aligned with support taxonomies.
- Content moderation and policy enforcement in video platforms (Policy, Trust & Safety)
- Application: Detect policy violations (e.g., prohibited actions) with minimal compute; CoT only for borderline content.
- Workflow/Product: Moderation pipeline with early-exit gating; reports include rationale when invoked.
- Benefits: Lower energy use; improved throughput; explainability for escalations.
- Assumptions/Dependencies: Domain-specific reward design for policy categories; human-in-the-loop review.
- Energy and cost optimization for multimodal inference (Energy/Cloud operations)
- Application: Deploy confidence-based early exit to reduce token generation and energy consumption across inference fleets.
- Workflow/Product: A “Think Router” microservice in serving stacks (vLLM/DeepSpeed) that enforces early exit policy and logs think ratio.
- Benefits: Immediate savings in compute and carbon footprint.
- Assumptions/Dependencies: Access to per-token logprobs; ops monitoring for thresholds; workload profiling.
- Academic evaluation and benchmarking efficiency (Academia)
- Application: Introduce “think ratio” and confidence metrics in benchmark reporting; compare direct vs CoT modes systematically.
- Workflow/Product: Evaluation harness that logs initial answer confidence, think activation, and pairwise accuracy.
- Benefits: Better scientific rigor on overthinking; reproducible efficiency claims.
- Assumptions/Dependencies: Public datasets; standardized prompts; harmonized decoding settings.
Long-Term Applications
The following opportunities are promising but require additional research, scaling, or engineering to reach production quality.
- Edge deployment on AR/VR wearables and mobile devices (Hardware, AR/VR)
- Application: Adaptive video assistants that minimize battery draw via early-exit; CoT only for complex spatial reasoning (e.g., guided tutorials).
- Tools/Products: On-device inference engines with token-level logprob access; lightweight video encoders; adaptive SLAs.
- Dependencies: Further model compression/distillation; efficient video tokenizers; thermal constraints; robust privacy features.
- Standardized governance for “adaptive reasoning” policies (Policy, AI governance)
- Application: Industry-wide guidelines that discourage unconditional CoT to reduce energy usage and overthinking risks.
- Tools/Products: Compliance checklists; auditing tools that report think ratio, energy per answer, and rationale necessity.
- Dependencies: Agreement on metrics; alignment with regulatory frameworks; transparency requirements for rationale generation.
- Multimodal clinical assistants for procedural video understanding (Healthcare)
- Application: Assist clinicians by localizing steps in surgical/procedural videos; engage CoT for complex decision points.
- Tools/Products: Workflow-integrated assistants with verifiable task rewards (e.g., step recognition); rationale logging for audit trails.
- Dependencies: Medical-grade datasets; rigorous validation and certification; bias and safety assessments; integration with hospital IT.
- Autonomous driving and fleet video reasoning (Automotive)
- Application: Localize events and explain edge-case scenarios (near-miss, unusual pedestrian behavior) with adaptive reasoning.
- Tools/Products: Fleet-scale video analytics; post-hoc incident analysis with reviewed answers.
- Dependencies: Safety-critical performance guarantees; domain-specific training; regulatory approval; sensor fusion.
- Compute-aware orchestration and dynamic pricing (Cloud/Platform)
- Application: Service-level policies that adjust the confidence threshold based on budget, latency targets, and user tier.
- Tools/Products: Budget-aware routing layers; dashboards showing cost/accuracy trade-offs; per-tenant “thinking budgets.”
- Dependencies: Robust calibration across workloads; customer transparency; billing integration.
- Open-source SDKs for dual-answer GRPO and verifiable rewards (Software tooling)
- Application: Reusable training/evaluation libraries that implement the paper’s dual-answer reward, fallback handling, and early-exit gating.
- Tools/Products: Modular reward functions for QA/grounding; evaluation harnesses; prompt templates.
- Dependencies: Licensing compatibility; community datasets; reference implementations for multiple VL backbones.
- Hardware-level support for confidence-gated early exit (Semiconductors)
- Application: Accelerator features to expose token logprobs and fast gating primitives to cut off generation early.
- Tools/Products: Firmware/driver APIs; compiler/runtime optimizations for confidence checks; energy-saving modes.
- Dependencies: Vendor adoption; standardized interfaces; benchmarks demonstrating energy/latency gains.
- Integrated agents with tool-calling only when necessary (General-purpose AI agents)
- Application: Agents that first attempt direct answers and selectively invoke tools (retrievers, calculators, frame selectors) only when confidence is low.
- Tools/Products: Tool orchestration policies conditioned on confidence; “thinking with frames” pipelines for progressive perception.
- Dependencies: Robust tool quality; reliable uncertainty estimation; domain-tailored thresholds; end-to-end logging.
- Domain-adaptive thresholds and calibration (Cross-industry)
- Application: Automated procedures to set and maintain confidence thresholds per domain/task to maximize gains without harming accuracy.
- Tools/Products: Calibration suites; drift detection; active learning to refine thresholds over time.
- Dependencies: Ongoing data collection; monitoring infrastructure; human oversight.
- New benchmarks and taxonomies for “must-think” detection (Academia/Standards)
- Application: Curate datasets and metrics that separate perception-oriented from reasoning-intensive video tasks to study overthinking.
- Tools/Products: Public corpora with labels for think necessity; protocols for reporting think ratio and energy.
- Dependencies: Community collaboration; shared evaluation tooling; reproducibility practices.
Cross-cutting assumptions and dependencies to consider
- Confidence–correctness correlation: Early-exit depends on the initial answer’s length-normalized logprob being predictive; miscalibration can hurt accuracy on rare, hard cases.
- Reward design: Verifiable, task-specific rewards must exist (QA accuracy, temporal IoU, format correctness) for training and evaluation to be reliable.
- Generalization: Thresholds tuned on one domain may not transfer; per-domain calibration is recommended.
- Privacy and compliance: Video data often contains sensitive information; deployments must meet governance, auditability, and explainability requirements.
- Operational readiness: Access to token logprobs, inference runtime hooks, and monitoring (think ratio, latency, energy) is needed to realize efficiency gains.
- Data quality: The approach benefits from curated multimodal datasets (text/image/video) that cover both perception and reasoning cases.
Glossary
- adaptive reasoning: A strategy where a model dynamically decides whether to perform explicit reasoning or answer directly based on input difficulty. "Auto-thinking, or adaptive reasoning, allows a model to decide whether to answer directly or to invoke CoT reasoning based on input complexity~\citep{yang2025qwen3,cheng2025incentivizing,lou2025adacot}."
- auto-thinking: An approach that adaptively invokes chain-of-thought only when needed to balance accuracy and efficiency. "Auto-thinking, or adaptive reasoning, allows a model to decide whether to answer directly or to invoke CoT reasoning based on input complexity~\citep{yang2025qwen3,cheng2025incentivizing,lou2025adacot}."
- autoregressive: A generation process where tokens are produced sequentially, making longer outputs slower and more expensive. "Given the autoregressive nature of LLMs, these longer traces substantially increase latency and inference cost."
- bi-mode policy optimization: An RL/SFT strategy that trains and selects between two modes (e.g., think vs. no-think) for reasoning. "R-4B~\citep{yang2025r} adopts bi-mode policy optimization, using SFT for initialization and then refining the model via RL to enhance the decision accuracy of whether to activate CoT."
- Chain-of-thought (CoT) reasoning: Generating explicit, step-by-step rationales to improve problem solving. "Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal LLMs on video understanding tasks."
- cold-start SFT: An initial supervised fine-tuning phase used to bootstrap a model before RL; avoided in this work. "Notably, we conduct RL directly on the curated data without relying on a cold-start SFT stage."
- confidence-based early-exit: An inference strategy that stops generation after the first answer if its confidence exceeds a threshold. "We propose VideoAuto-R1, which couples a thinking once, answering twice training paradigm with a confidence-based early-exit inference strategy."
- dual-answer reward: An RL reward design that simultaneously supervises the initial and the reviewed (final) answers. "we introduce a new dual-answer reward that supervises both the initial and reviewed answers."
- early-exit mechanism: A procedure to terminate decoding early when sufficient certainty is achieved, saving computation. "During inference, an early-exit mechanism is adopted to dynamically determine whether to proceed with CoT reasoning."
- fallback reward: A bonus encouraging the model to defer an uncertain first answer and then provide a correct final answer after reasoning. "Specifically, a fallback reward is introduced to avoid a spurious initial guess."
- format correctness: A verifiable constraint ensuring outputs adhere to a specified structure or template. "Standard GRPO employs verifiable, rule-based rewards consisting of a task-accuracy term $R_{\text{task}$ and a format correctness term $R_{\text{fmt}$."
- Group Relative Policy Optimization (GRPO): An RL algorithm that uses group-normalized, rule-based rewards instead of a learned critic. "Group Relative Policy Optimization (GRPO) replaces a learned critic with group-normalized, rule-based verifiable rewards, offering a simplified and scalable RL training pipeline with strong empirical performance~\citep{guo2025deepseek}."
- grounding QA: A question answering task that requires predicting both an answer and the corresponding grounded (spatiotemporal) evidence. "In this paper, we consider three video task types: QA, temporal grounding, and grounding QA."
- importance ratio: The likelihood ratio between current and old policies used to weight updates in policy optimization. "Then with the importance ratio $\rho_i = \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}(o_i \mid q)}$, the training objective becomes:"
- interleaved video-text reasoning: A method that reasons by alternating between video frames and text, e.g., “thinking with frames.” "Recent works further explore interleaved video-text reasoning, also known as ``thinking with frames''."
- KL penalty: A regularization term based on Kullback–Leibler divergence to keep the learned policy close to a reference policy. "where $D_{\text{KL}$ regularizes the policy against a reference policy $\pi_{\text{ref}$ via a KL penalty, and controls the strength of this regularization."
- length-normalized mean log probability: An average log-probability per token used as a confidence score for an answer. "we compute the length-normalized mean log probability of those answer tokens as the confidence score."
- model collapse: A failure mode where training converges to degenerate behavior (e.g., always think or never think). "rigidly enforcing think/no-think decisions during training often led to model collapse (always think or no-think) and poor generalization at test time."
- multimodal LLMs: LLMs that process multiple modalities such as text, images, and videos. "Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal LLMs on video understanding tasks."
- on-policy training: RL training using data sampled from the current policy, affecting stability and mode balance. "AdaptThink~\citep{zhang2025adaptthink} emphasizes the importance of balanced data sampling between think and no-think samples during on-policy training and achieves competitive performance on math tasks."
- overthinking: Producing unnecessarily long or complex reasoning that can reduce accuracy and efficiency. "may even cause overthinking that degrades performance."
- reference policy: A fixed or slowly changing policy used to regularize the current policy during RL. "regularizes the policy against a reference policy $\pi_{\text{ref}$ via a KL penalty"
- rollout: A generated sample (output) from the model used during RL for reward computation and optimization. "For GRPO rollout generation, we set the rollout size to 16 and use a temperature of $1.0$ to encourage exploration."
- rule-based rewards: Deterministic, verifiable reward functions (e.g., accuracy, IoU, formatting) instead of learned critics. "Standard GRPO employs verifiable, rule-based rewards"
- supervised fine-tuning (SFT): Training a model on labeled input–output pairs before or instead of RL. "typically learning a switching policy via supervised fine-tuning (SFT) or reinforcement learning (RL) to dynamically select the thinking mode"
- temporal grounding: Identifying the time segment in a video that corresponds to a textual query. "Beyond QA, some approaches extend reasoning to temporal grounding tasks"
- temporal IoU: Intersection-over-Union measured over time intervals, used to evaluate temporal localization quality. "such as answer accuracy, temporal IoU, or format correctness"
- temporal localization: The task of pinpointing when in a video an event or answer-relevant content occurs. "Time-R1~\citep{wang2025time} shows that explicit reasoning can benefit temporal localization."
- think/no-think labels: Supervision indicating whether a sample should trigger reasoning or direct answering. "It eliminates the need for per-sample think/no-think labels, yielding a simple yet effective adaptive reasoning model."
- thinking-mode: An inference mode where the model emits explicit step-by-step reasoning traces. "These models often operate in a thinking-mode, which generates an explicit, step-by-step CoT to analyze the problem"
- Thinking Once, Answering Twice: A training/inference paradigm where the model gives an initial answer, reasons, and then gives a reviewed answer. "our approach follows a Thinking Once, Answering Twice paradigm"
- token-level confidence: Confidence derived from per-token probabilities, used to assess answer reliability. "token-level confidence correlates strongly with answer correctness in modern LLMs."
- verifiable rewards: Automatically checkable rewards (e.g., exact match accuracy, IoU, or format) used in RL training. "Both answers are supervised via verifiable rewards."
Collections
Sign up for free to add this paper to one or more collections.