MoE3D: A Mixture-of-Experts Module for 3D Reconstruction
Abstract: MoE3D is a mixture-of-experts module designed to sharpen depth boundaries and mitigate flying-point artifacts (highlighted in red) of existing feed-forward 3D reconstruction models (left side). MoE3D predicts multiple candidate depth maps and fuses them via dynamic weighting (visualized by MoE weights on the right side). When integrated with a pre-trained 3D reconstruction backbone such as VGGT, it substantially enhances reconstruction quality with minimal additional computational overhead. Best viewed digitally.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces MoE3D, a small add-on that makes 3D reconstruction models draw sharper edges and cleaner shapes. It focuses on fixing a common problem: when a model guesses the distance of things in a picture (a “depth map”), it often blurs the edge where a nearby object meets a faraway background. That blur creates messy “flying points” in the 3D scene. MoE3D helps the model keep edges crisp while staying fast.
What questions does the paper try to answer?
- Why do fast, one-pass 3D models blur edges and produce floating points around object boundaries?
- Can we fix those blurry boundaries without switching to slow, heavy methods (like diffusion or GANs)?
- If we add a smart, lightweight module to an existing model, will it sharpen edges, reduce artifacts, and improve overall 3D accuracy?
How did they do it? Methods and key ideas
Think of the model like a camera that also measures how far each pixel is from you. That “depth map” tells you the 3D shape of the scene. The hard part is edges—like where a person stands in front of a wall. At those edges, the depth changes suddenly. Regular training tends to “average” across that jump, so edges get blurry.
MoE3D handles this with a “Mixture of Experts” approach:
- Mixture of Experts (MoE): Imagine a team of mini-specialists. Each specialist is good at a certain pattern—smooth surfaces, thin edges, foreground vs. background, etc. Instead of one big expert making all decisions, multiple experts each give a depth guess.
- Gating network: This is a tiny “referee” that looks at each pixel and chooses which expert to trust most. It turns the experts’ scores into percentages that add up to 100% (this is called “softmax”). The final depth for a pixel is a smart blend, weighted by these percentages. In practice, the referee learns to be decisive—usually picking one expert per pixel—so edges stay sharp.
- Entropy regularization: This is a simple rule that tells the referee not to be indecisive. In everyday terms, it says, “Pick one expert strongly instead of mixing many.” That encourages clear separation between regions and sharper boundaries.
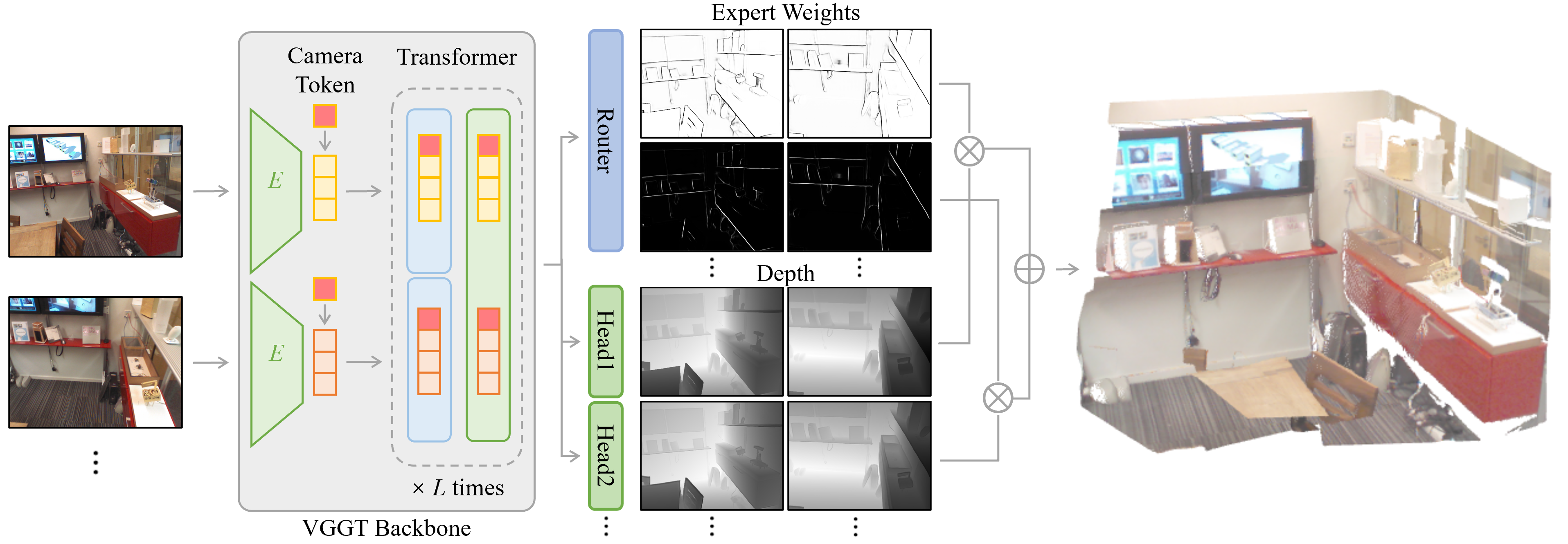
Where is MoE3D added?
- It plugs into the depth-prediction head of a strong 3D backbone called VGGT. The rest of VGGT stays the same.
- The module introduces several small expert branches that predict multiple candidate depth maps, then blends them per pixel using the gating network.
Training details in simple terms:
- They fine-tune the pre-trained VGGT with MoE3D on synthetic datasets (Hypersim and Virtual KITTI) because those have clean, accurate depth labels.
- They keep training simple (mostly an “L2 loss,” which just means “make your prediction close to the correct depth”) and avoid complicated extra tricks.
- The backbone is trained end-to-end so the experts and the shared features learn to cooperate.
Why not use slow generative methods?
- Diffusion or GAN-based depth can handle uncertainty but is heavy and slow. MoE3D gives similar benefits (better edge handling) with much less compute.
Main findings and why they’re important
MoE3D helps in three big ways:
- Sharper boundaries: It significantly improves the crispness of edges in depth maps, so objects don’t “bleed” into the background.
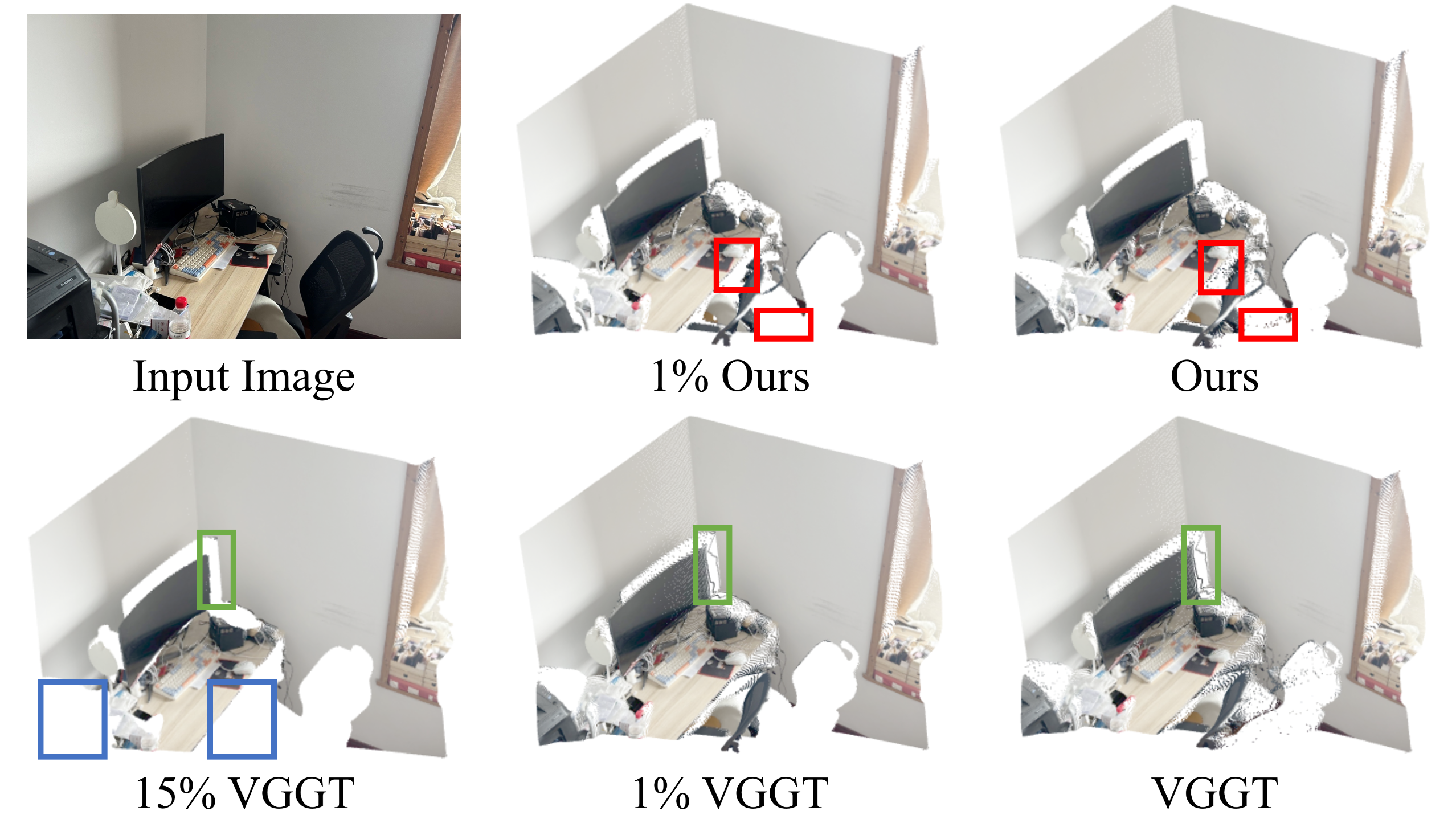
- Fewer flying-point artifacts: Those weird floating points around edges are greatly reduced, making 3D scenes look cleaner and more realistic.
- Better 3D accuracy: On standard tests, MoE3D improves accuracy and completeness of reconstructed 3D scenes and keeps or boosts performance on common depth benchmarks.
What about speed and size?
- The module adds only a tiny amount of extra computation at inference (around 5% more GFLOPs and roughly 7% runtime overhead reported in the paper).
- It increases model parameters by less than 1%.
- Despite being small and light, it gives strong, consistent improvements.
Evidence they show:
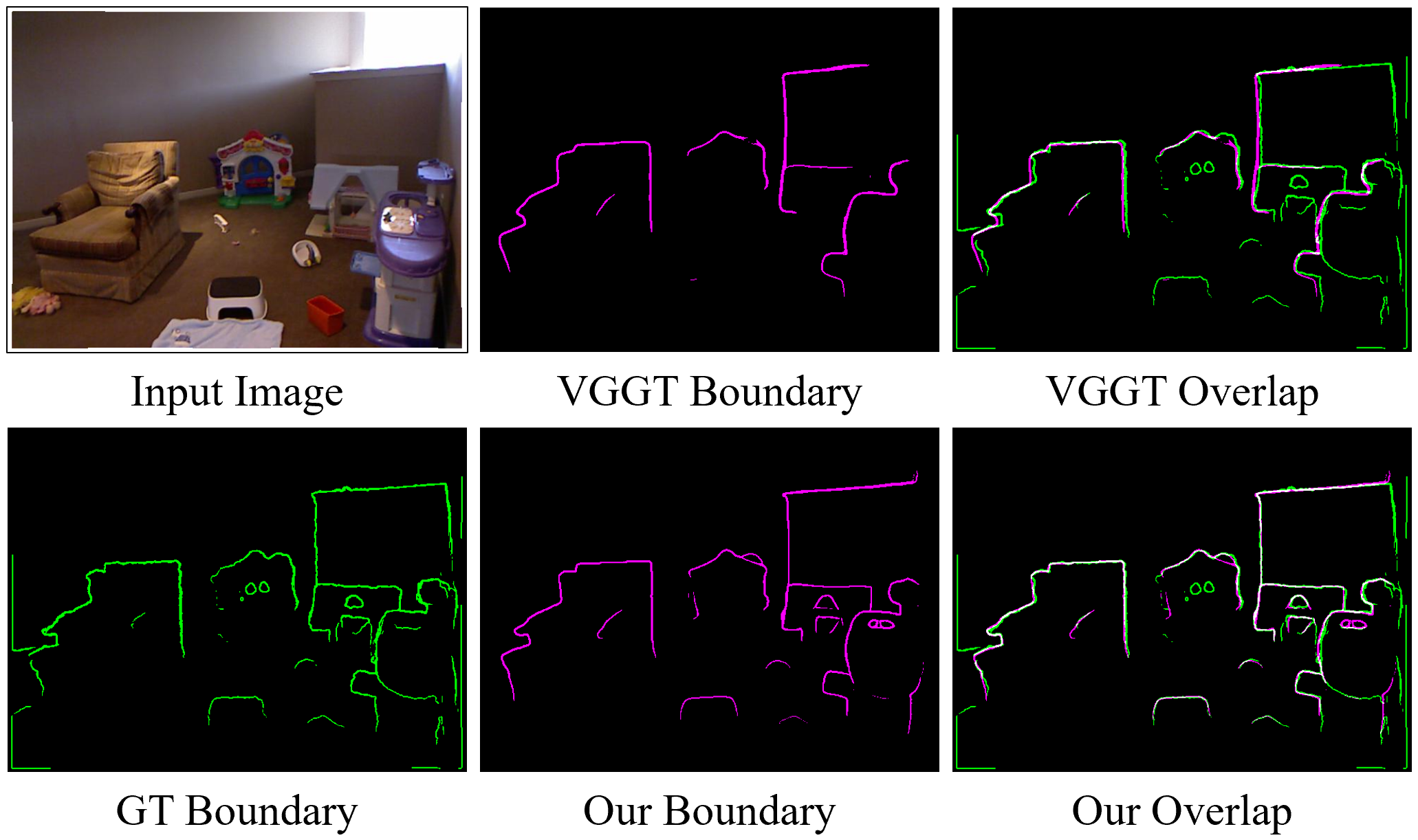
- Boundary metrics go up: precision, recall, and F1 scores for depth edges improve across datasets.
- Multi-view 3D metrics improve: accuracy and normal consistency (how well surfaces point the right way) get better than the base VGGT.
- Monocular depth stays strong: accuracy remains competitive or better on several datasets.
Implications and potential impact
MoE3D shows that you don’t need heavy, slow models to fix edge blur in 3D reconstruction. A small, smart “team of experts” added to a fast backbone can:
- Make AR/VR scenes look more believable with cleaner edges.
- Help robots and drones understand the shape of the world more accurately.
- Improve 3D mapping, scanning, and editing tools without sacrificing speed.
Limitations to keep in mind:
- The paper trains mostly with one or two views, so multi-view consistency can still be improved.
- A few artifacts may remain in very tricky areas.
Overall, MoE3D is a simple, practical idea: let mini-experts specialize, and let a smart referee pick the right one per pixel. That specialization sharpens boundaries, cleans up 3D shapes, and boosts accuracy with minimal extra cost.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research.
- Clarify and ablate the training objective: the Methods section derives a mixture negative log-likelihood, but Training Details state depth supervision is solely an L2 loss; quantify the impact of NLL vs L2 on accuracy, boundary sharpness, stability, and uncertainty calibration.
- Per-expert variance modeling is omitted (global constant σ); test learned per-expert variance (aleatoric uncertainty) and evaluate calibration (e.g., ECE, NLL) and whether it improves boundary selection and robustness in textureless regions.
- Hard vs soft routing: evaluate top-1 (argmax) gating at inference vs weighted blends, and study the trade-off between sharp boundaries, artifact suppression, and stability; include latency/quality comparisons for different temperatures τ or Gumbel-softmax.
- Number of experts K and gate temperature τ are not systematically explored; provide scaling curves (quality vs compute) across K and τ schedules, including diminishing returns and specialization patterns.
- Entropy regularization is tuned in a narrow range; study schedules and alternative gating regularizers (e.g., load-balancing, sparsity, spatial smoothness priors) to prevent collapse while maintaining specialization.
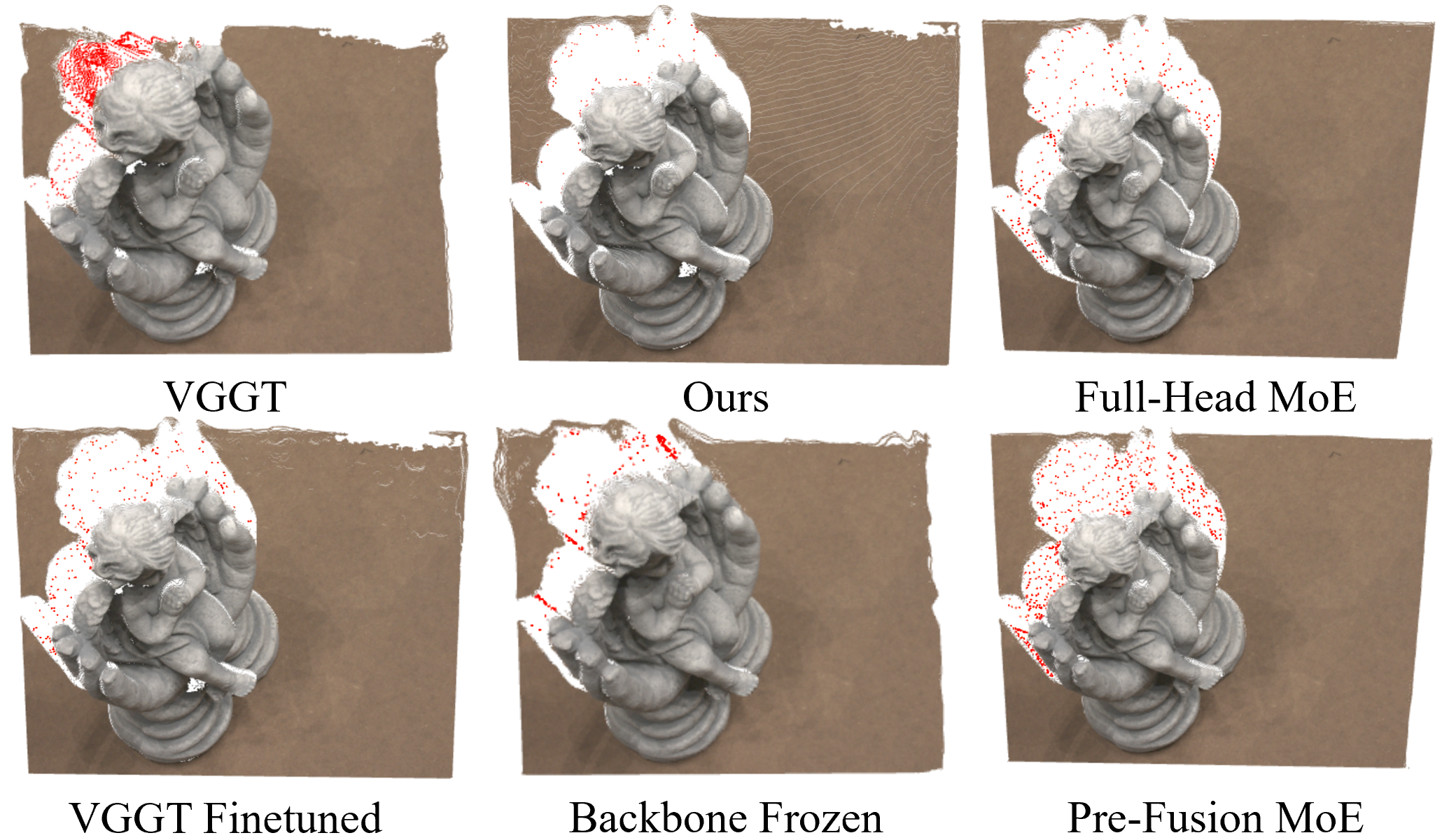
- MoE placement is limited to the final DPT stage; evaluate MoE in earlier fusion stages, in transformer blocks, or multi-scale head variants, and quantify their impact on multi-view consistency and compute.
- Extend MoE beyond depth: test MoE in point-map and camera heads (currently point head disabled, camera head frozen) to assess if multi-view geometry and pose can benefit from expert specialization.
- Multi-view consistency remains limited (trained on 1–2 views); introduce cross-view consistency losses, longer sequences, and multi-view gating consistency constraints, and measure improvements on scenes with more views.
- Multi-view evaluation is primarily indoors (NRGBD, 7Scenes); assess outdoor multi-view scenes (e.g., KITTI, Tanks and Temples), dynamic scenes, and challenging materials (specular, transparent) to determine generalization of boundary improvements.
- Domain gap and augmentation: training uses only synthetic data without augmentation; quantify gains from real datasets, diverse augmentations (blur, noise, compression, lighting), and mixed real-synthetic training on boundary sharpness and flying-point artifacts.
- Quantify flying-point artifacts explicitly: introduce a standardized metric (e.g., outlier rate beyond local surface thresholds or 3D scatter density) instead of relying solely on boundary edge metrics, and report reductions across datasets.
- Gating interpretability and semantics: analyze whether experts consistently specialize in foreground/background, edges, thin structures, or frequency bands, and explore supervised or weakly supervised routing (e.g., using semantic or edge priors).
- Uncertainty utility: evaluate whether gating weights/entropy can serve as usable uncertainty signals for downstream tasks (e.g., view selection, fusion, confidence-based filtering), including calibration and reliability diagrams.
- Computational analysis is limited to parameters and GFLOPs; measure end-to-end latency, memory footprint, throughput, and energy across hardware (GPU/CPU/edge), batch sizes, and number-of-views scaling.
- Robustness studies are missing: test performance under sensor noise, motion blur, rolling shutter, low light, extreme aspect ratios, and resolution changes to assess MoE resilience.
- Compare against mixture-density and layered-depth baselines under identical backbones and training to isolate the net contribution of MoE gating versus parametric mixtures or multi-layer depth representations.
- Investigate combining MoE with boundary-aware losses (e.g., edge or gradient losses) to test additive or redundant benefits compared to architectural specialization alone.
- Inference outputs remain single-depth via weighted sum; explore multi-hypothesis outputs (per-pixel mixture modes or layered depth) and evaluate gains for occlusion reasoning and view synthesis tasks.
- Failure modes are only qualitatively shown; provide systematic error categorization (e.g., thin structures, reflective surfaces, repetitive textures) and per-category metrics to identify where MoE helps or hurts.
- Backbone unfreezing improves performance but its contribution is under-quantified; provide controlled ablations (frozen vs partially frozen vs fully unfrozen backbones) with statistical significance across datasets.
- Training stability and seed variance: report training variance across seeds, convergence behavior, and sensitivity to λentropy and τ, including cases of expert collapse or oscillatory routing.
- Details of the gating network (architecture, depth, receptive field, normalization) are sparse; ablate gating design (attention-based gating, spatial smoothing, CRF-like post-processing) for better spatial coherence and reduced patchiness.
- Real-time scalability to dozens of views (VGGT’s regime) is not measured; benchmark MoE3D latency and memory when inferring on long sequences and assess whether benefits persist at scale.
- Interaction with camera estimation: camera head is frozen; study joint optimization (unfrozen camera head) and its effect on pose accuracy and multi-view reconstruction consistency with MoE depth.
- Edge evaluation relies on Sobel with a fixed threshold; test robustness to different edge detectors/thresholds and report sensitivity to ensure boundary gains are not metric-specific.
- Cross-dataset generalization is shown for monocular tasks but not thoroughly quantified for multi-view; include leave-one-dataset-out and cross-domain generalization tests with statistical confidence.
- Explore integration with dynamic-scene feed-forward models (e.g., MonST3R) to assess whether MoE specialization benefits 4D reconstruction and motion boundaries.
- Provide guidance for selecting K, λentropy, and τ for different resource budgets; deliver practical recipes that balance compute overhead and accuracy for deployment.
Practical Applications
Practical Applications of MoE3D: Actionable Use Cases and Deployment Pathways
Below, we group practical, real-world applications of the paper’s findings and innovations under Immediate Applications and Long-Term Applications. Each bullet specifies sector(s), concrete tools/products/workflows that could emerge, and assumptions/dependencies that affect feasibility.
Immediate Applications
These can be deployed now with modest engineering effort, leveraging the paper’s “drop-in” MoE head for VGGT and similar feed-forward 3D models, with minimal compute overhead.
- Edge-aware AR occlusion and effects for mobile apps — sectors: software, consumer, XR
- Tools/Products/Workflows: “MoE-Depth SDK” (a boundary-sharpening VGGT head), mobile AR occlusion masks with fewer halos, improved portrait-mode bokeh edges, better foreground/background separation for live filters.
- Assumptions/Dependencies: Access to a VGGT-like backbone; acceptable ~5–7% compute overhead on device; domain-appropriate fine-tuning beyond synthetic datasets.
- Cleaner real-time point clouds for robotics and drones — sectors: robotics, logistics
- Tools/Products/Workflows: ROS package for MoE3D depth, boundary-aware TSDF fusion to suppress flying points at object edges, improved obstacle delineation for navigation in clutter.
- Assumptions/Dependencies: RGB camera or RGB-D setup; careful domain adaptation (indoor/outdoor, lighting); safety validation before mission-critical use.
- Photogrammetry pre-processing and post-cleaning — sectors: software, mapping/AEC
- Tools/Products/Workflows: Use MoE3D depth as a seed or prior for MVS pipelines (e.g., COLMAP), point-cloud cleaner that reduces floaters along edges, improved wall-floor junctions in building scans.
- Assumptions/Dependencies: Integration into existing pipelines; scale-aware normalization; minor tuning for multi-view consistency if many frames are used.
- Faster content creation and compositing in VFX — sectors: media/entertainment
- Tools/Products/Workflows: Nuke/After Effects plugin for edge-accurate depth mattes, sharper depth for depth-of-field, relighting, and roto workflows, fewer artifacts in green-screen spill correction when using depth.
- Assumptions/Dependencies: Studio pipelines with GPU acceleration; per-project fine-tuning for stylized domains (anime, CGI) if needed.
- E-commerce product capture and virtual try-on — sectors: retail/e-commerce
- Tools/Products/Workflows: Smartphone product scanning that yields crisp object boundaries; improved occlusion in virtual try-on and AR furniture placement.
- Assumptions/Dependencies: Lighting variability and glossy/transparent materials may need specialized augmentation; ensure metric scale when required.
- Boundary-sharp monocular depth for SLAM and 3D mapping — sectors: software, robotics, AEC
- Tools/Products/Workflows: Swap in MoE3D depth head in visual SLAM front-ends to reduce surface bleeding; better mesh extraction at edges; improved pose-graph loop closure through cleaner geometric cues.
- Assumptions/Dependencies: Multi-view consistency limited by current training (1–2 views); align scale handling (e.g., median scaling vs. metric scale) to SLAM system requirements.
- Active capture guidance via gating entropy as uncertainty — sectors: software, XR, robotics
- Tools/Products/Workflows: Use per-pixel MoE weights/entropy as a live uncertainty map to drive “move closer” or “viewpoint change” prompts; adapt capture routes in handheld scanning to reduce ambiguous edges.
- Assumptions/Dependencies: Expose gating weights; simple UI for users; calibrate thresholds to domain.
- Academic research and teaching modules — sectors: academia/education
- Tools/Products/Workflows: Course labs demonstrating MoE routing on depth, benchmarks on boundary accuracy, reproducible ablations on entropy regularization strength.
- Assumptions/Dependencies: Open-source access to VGGT/MoE3D implementation; small GPU budget is sufficient for fine-tuning.
Long-Term Applications
These will benefit from further research and scaling (e.g., multi-view training, domain adaptation, safety validation), but are well-motivated by the paper’s results.
- Autonomous driving and ADAS depth perception — sectors: automotive
- Tools/Products/Workflows: Boundary-sharp feed-forward depth fused with stereo/LiDAR for crisp free-space estimation and object edges; pre-filtering to reduce flying points in occupancy networks.
- Assumptions/Dependencies: Extensive real-world training/validation (weather, night, motion blur); multi-sensor fusion; safety certification; higher frame-rate constraints.
- Medical 3D reconstruction (endoscopy, surgical vision) — sectors: healthcare
- Tools/Products/Workflows: Sharper organ/tissue boundaries in monocular endoscopic depth aids pose estimation and tool tracking; depth priors for 3D endoscopy reconstruction with fewer artifacts near tissue folds.
- Assumptions/Dependencies: Specialized data and regulatory compliance; domain-specific fine-tuning (specularities, fluids); metric scale requirement; clinical validation.
- Industrial inspection and manufacturing — sectors: industrial/robotics
- Tools/Products/Workflows: High-precision edge-aware depth for defect detection on parts with fine edges; robotic manipulation with reduced boundary artifacts in grasp planning.
- Assumptions/Dependencies: Calibration to shiny/transparent materials; integration with 3D metrology standards; throughput constraints in production lines.
- Large-scale mapping and digital twins — sectors: GIS, smart cities, energy/AEC
- Tools/Products/Workflows: Boundary-accurate reconstruction for city-scale meshes, cleaner edges for utility lines and building features; improved multi-view consistency through scaled training (dozens of views).
- Assumptions/Dependencies: Longer sequence training and data augmentation; robust multi-view consistency losses; scalable inference.
- Edge-aware NeRF/implicit modeling initialization — sectors: software, XR
- Tools/Products/Workflows: Use MoE3D depth to seed NeRFs or other implicit models, accelerating convergence and improving sharpness at occlusion boundaries.
- Assumptions/Dependencies: Workflow integration and joint optimization; probabilistic treatment of MoE uncertainty for space carving.
- Safety-critical standards and policy guidance for 3D quality — sectors: policy/standards
- Tools/Products/Workflows: Boundary accuracy metrics (mIoU/F1 for depth edges) incorporated into procurement and certification; best-practice guidelines for minimizing flying points in public-facing AR navigation and mapping.
- Assumptions/Dependencies: Consensus building in standards bodies; reproducible benchmarks; domain-specific thresholds.
- Hybrid discriminative–generative depth systems — sectors: software/AI research
- Tools/Products/Workflows: Combine MoE heads (epistemic uncertainty handling) with diffusion-based depth priors (aleatoric uncertainty) to achieve both sharp edges and robust fill-in; per-expert variance heads for uncertainty calibration.
- Assumptions/Dependencies: Additional compute for generative components; careful loss balancing; broader datasets.
- Consumer-grade 3D scanning appliances and apps — sectors: consumer hardware/software
- Tools/Products/Workflows: “Edge-Aware 3D Scanner” smartphone app that fuses MoE depth across video for clean meshes; one-tap room scanning with crisp corners for home remodeling.
- Assumptions/Dependencies: Real-time performance on mobile SoCs; large-scale training for generalization; UX for capture guidance.
- Energy-efficient 3D perception stacks — sectors: energy, sustainability (cross-cutting)
- Tools/Products/Workflows: Use MoE3D’s lightweight improvements to reduce need for heavier post-processing or repeated captures; lower GPU hours in pipelines for similar or better quality.
- Assumptions/Dependencies: Holistic pipeline analysis to measure net energy savings; monitoring to avoid regressions in other stages.
Notes on global assumptions and dependencies across applications:
- Model integration: The MoE head is designed for feed-forward backbones like VGGT; porting to other architectures is straightforward but requires engineering and validation.
- Training data: The paper’s experiments used synthetic data (Hypersim, VKITTI) with 1–2 views and no augmentation; improved multi-view consistency and robustness will benefit from larger, more diverse, real datasets.
- Scale and metric depth: Some use cases require metric scale; ensure proper scaling (e.g., learned scale heads or external sensors).
- Licenses and IP: Check licenses for VGGT and derived implementations before commercial use.
- Compute and latency: The reported overhead (~0.79% parameters, ~5% GFLOPs, ~7% inference) is modest but should be profiled in target environments (mobile, embedded, cloud).
- Safety and compliance: For regulated domains (automotive, healthcare), extensive validation and certification are necessary prior to deployment.
Glossary
- Absolute Relative Error (AbsRel): A depth-estimation metric measuring the absolute error relative to ground-truth depth. "using the standard depth metrics: absolute relative error (AbsRel) and accuracy thresholds ."
- Accuracy (Acc): A geometric measure of how close reconstructed 3D points are to ground truth. "report {Accuracy (Acc)}, {Completeness (Comp)}, and {Normal Consistency (NC)} as standard geometric measures."
- Aleatoric Uncertainty: Uncertainty arising from inherent noise or ambiguity in observations. "This formulation captures both aleatoric and epistemic uncertainty: the former reflects inherent input ambiguity (e.g., textureless regions), while the latter arises from multiple plausible depth hypotheses (e.g., around discontinuities)."
- Argmax: The index of the maximum value, used here to visualize expert selection. "Visualization of gating assignments (argmax) for four experts (red, blue, green, yellow)."
- Camera Intrinsics: Internal camera parameters (e.g., focal length, principal point) defining projection geometry. " represents the estimated camera parameters (rotation, translation, and intrinsics)."
- Camera Pose: The position and orientation of a camera in 3D space. "VGGT, which achieves state-of-the-art performance in depth, point, and camera pose prediction."
- Completeness (Comp): A geometric measure capturing how completely the reconstruction covers the ground-truth surface. "report {Accuracy (Acc)}, {Completeness (Comp)}, and {Normal Consistency (NC)} as standard geometric measures."
- Depth Discontinuities: Abrupt changes in depth values at object boundaries. "depth boundaries often exhibit abrupt discontinuities that introduce substantial uncertainty in depth estimation."
- DINO-based Encoder: A self-supervised transformer encoder (DINO) used to extract image tokens. "Each input image is first processed by a shared DINO-based encoder , which patchifies the image into a sequence of tokens"
- DPT Head: The Dense Prediction Transformer head used to decode pixel-wise outputs. "In the original DPT head, the decoder reconstructs spatial detail through a series of lateral connections and fusion blocks"
- Epistemic Uncertainty: Uncertainty due to limited model knowledge or multiple plausible explanations. "This formulation captures both aleatoric and epistemic uncertainty: the former reflects inherent input ambiguity (e.g., textureless regions), while the latter arises from multiple plausible depth hypotheses (e.g., around discontinuities)."
- Flying-Point Artifacts: Spurious points floating in space caused by erroneous depth predictions. "mitigate flying-point artifacts (highlighted in red) of existing feed-forward 3D reconstruction models"
- Fusion Blocks: Decoder modules that combine multi-scale features to reconstruct spatial detail. "the decoder reconstructs spatial detail through a series of lateral connections and fusion blocks"
- Gating Network: A network that produces routing logits/weights to select among experts. "A lightweight gating network takes as input and predicts gate logits "
- GFLOPs: Billions of floating point operations, a measure of computational cost. "introducing MoE adds more parameters and results in a increase in GFLOPs."
- Hard-Assignment Limit: The regime where routing selects a single expert per pixel (near one-hot). "In the hard-assignment limit, the mixture likelihood
collapses to a single component"
- Inverse-Entropy Regularization: A loss term that encourages confident (low-entropy) expert selection. "We apply an inverse-entropy regularization on the gating distribution to encourage confident expert selection."
- Layered Depth Images (LDI): A representation storing multiple depth layers per pixel to capture occlusions. "Layered Depth Images (LDI) represents scenes using multiple depth layers per pixel to explicitly capture occlusions and visibility"
- Lateral Connections: Skip connections that pass features between decoder stages at matching scales. "the decoder reconstructs spatial detail through a series of lateral connections and fusion blocks"
- Mean Intersection-over-Union (mIoU): A segmentation metric measuring overlap between predicted and true edge maps. "We quantify geometric boundary sharpness using mean Intersection-over-Union (mIoU), Precision (P), Recall (R), and F1 score over the extracted edge pixels."
- Median-Scaling: A normalization scheme aligning predicted depths’ median to ground truth. "All results are reported under the {median-scaling} scheme as in DUSt3R"
- Mixture Likelihood: The likelihood of data under a mixture model combining multiple components. "In the hard-assignment limit, the mixture likelihood
collapses to a single component"
- Mixture-of-Experts (MoE): An architecture combining multiple expert predictors via learned routing. "we introduce a mixture-of-experts formulation that handles uncertainty at depth boundaries by combining multiple smooth depth predictions."
- Monocular Depth Estimation: Predicting depth from a single image. "In monocular depth estimation, our module maintains the prediction accuracy of VGGT while markedly improving boundary sharpness and precision"
- Multi-Modal Uncertainty: Uncertainty characterized by multiple plausible modes (e.g., different depths). "pixels near depth discontinuities exhibit {multi-modal} uncertainty that cannot be captured by a single Gaussian."
- Multi-View Stereo (MVS): Depth reconstruction from multiple images by matching and triangulation. "Structure-from-Motion (SfM) and Multi-View Stereo (MVS)~\cite{colmap,mvsnet}, rely on geometric optimization over correspondences and camera parameters."
- Negative Log-Likelihood (NLL): A loss based on the negative logarithm of the model’s likelihood of the ground truth. "Training minimizes the negative log-likelihood against ground truth "
- Normal Consistency (NC): A metric measuring the alignment of surface normals between reconstruction and ground truth. "report {Accuracy (Acc)}, {Completeness (Comp)}, and {Normal Consistency (NC)} as standard geometric measures."
- Patchifies (Patchification): Converting images into fixed-size patches to form token sequences for transformers. "which patchifies the image into a sequence of tokens"
- Point Cloud: A set of 3D points representing reconstructed geometry. "reconstructed point clouds by VGGT (middle) and our MoE3D (bottom)."
- Point Map: A dense per-pixel mapping from image coordinates to 3D points. " is the corresponding point map"
- Routing (Per-Pixel Learned Routing): The learned assignment of pixels to experts based on gating weights. "our method performs per-pixel, learned routing between multiple feed-forward depth experts"
- Sobel Operator: A gradient-based edge detector used to extract depth boundaries. "Depth edges are extracted from both predicted and ground-truth depth maps using a Sobel operator with a fixed gradient threshold of~50."
- Softmax (Temperature-Scaled Softmax): A normalized exponential function for converting logits to probabilities, with a temperature controlling sharpness. "The gate logits are then are converted into mixture weights through a temperature-scaled softmax:"
- Structure-from-Motion (SfM): Recovering camera motion and 3D structure from image sequences. "Structure-from-Motion (SfM) and Multi-View Stereo (MVS)~\cite{colmap,mvsnet}, rely on geometric optimization over correspondences and camera parameters."
- Triangulation: Computing 3D points from multiple 2D views using intersecting rays. "removing the need for explicit triangulation."
- VAE Bottlenecks: Low-dimensional latent constraints in Variational Autoencoders that can limit detail. "low-dimensional latent representations (e.g., VAE bottlenecks) that compromise structural detail."
- World Coordinate Frame: A reference coordinate system in which 3D points and cameras are expressed. "As in VGGT, the first view defines the world coordinate frame."
Collections
Sign up for free to add this paper to one or more collections.