Intent at a Glance: Gaze-Guided Robotic Manipulation via Foundation Models
Abstract: Designing intuitive interfaces for robotic control remains a central challenge in enabling effective human-robot interaction, particularly in assistive care settings. Eye gaze offers a fast, non-intrusive, and intent-rich input modality, making it an attractive channel for conveying user goals. In this work, we present GAMMA (Gaze Assisted Manipulation for Modular Autonomy), a system that leverages ego-centric gaze tracking and a vision-LLM to infer user intent and autonomously execute robotic manipulation tasks. By contextualizing gaze fixations within the scene, the system maps visual attention to high-level semantic understanding, enabling skill selection and parameterization without task-specific training. We evaluate GAMMA on a range of table-top manipulation tasks and compare it against baseline gaze-based control without reasoning. Results demonstrate that GAMMA provides robust, intuitive, and generalizable control, highlighting the potential of combining foundation models and gaze for natural and scalable robot autonomy. Project website: https://gamma0.vercel.app/














Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
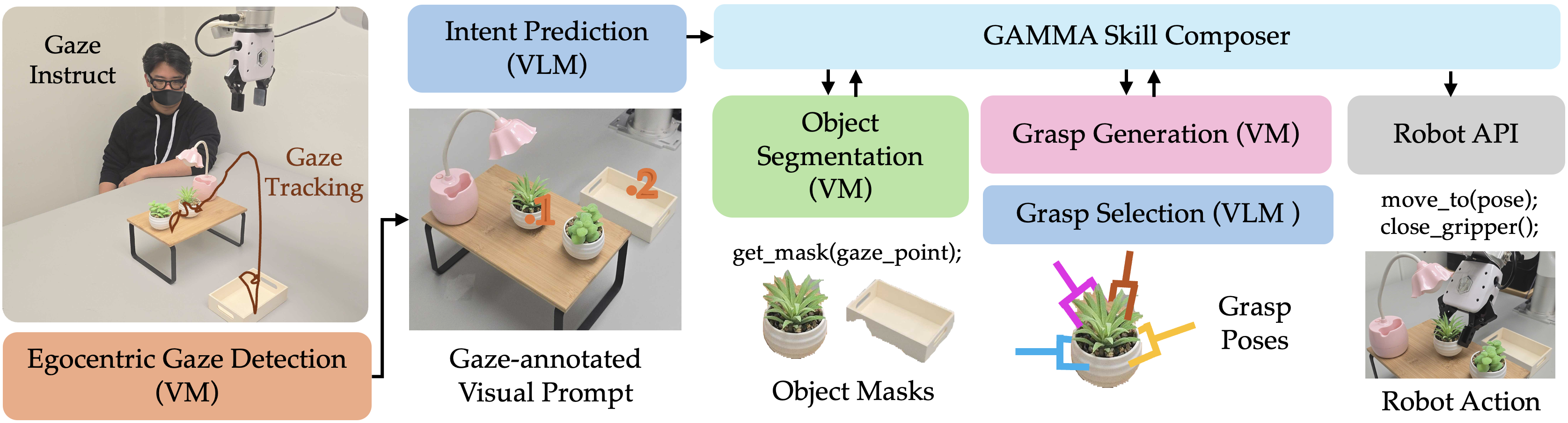
This paper presents a system called gamma (Gaze Assisted Manipulation for Modular Autonomy). It lets a robot understand what a person wants it to do just by where the person is looking. The person wears smart glasses that track their eye gaze, and the robot uses powerful AI models that understand images and language to figure out the person’s intent and then carry out tasks like picking up objects, pouring water, or placing items in containers—without needing special training for each task.
What questions did the researchers ask?
The researchers wanted to know:
- Can a robot understand a person’s goals from their eye movements alone?
- Can modern “foundation models” (very large AI models that understand pictures and words) turn those goals into correct robot actions without task-specific training?
- Is this gaze-based control faster or easier for users compared to a more traditional gaze interface where users directly move the robot by looking at on-screen buttons?
How the system works (methods and approach)
The system has several parts. Think of it like a “see, think, and act” pipeline:
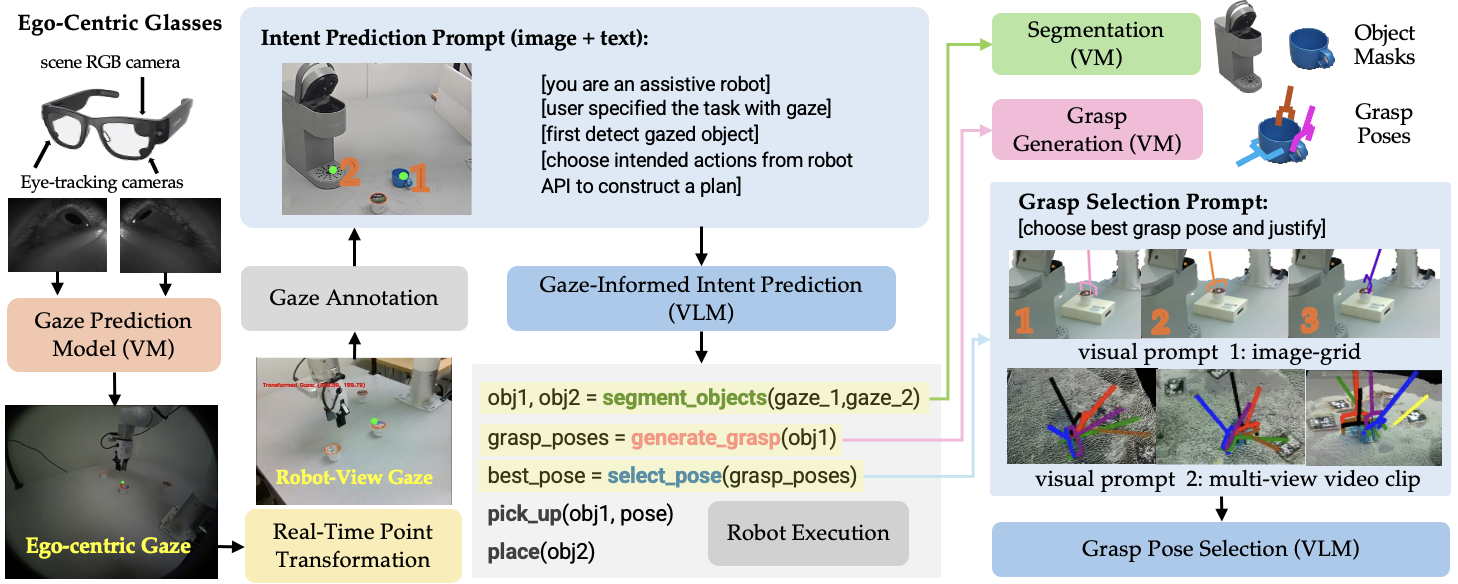
Seeing what you look at
The user wears smart glasses (Meta’s Project Aria) that track their eyes. Wherever the user focuses, the system records a “gaze point.” Because the glasses’ camera view is different from the robot’s camera view, the system uses special visual markers (like smart stickers called ArUco markers) to align the views so the robot knows what object the user is actually looking at.
- Technical term explained: “Egocentric view” means the camera is on the person, showing the scene from their perspective. The robot’s cameras provide a “third-person view.”
- The system combines multiple frames over time to get stable “gaze fixations” instead of just noisy, single points.
Understanding the scene
To figure out which object the person is looking at, the system uses a vision model called SAM2 to “segment” the image—this is like cutting the picture into pieces so each object has its own mask. It also uses depth cameras so the robot has a 3D picture of the scene made of many tiny dots called a “point cloud.” Merging the two robot cameras gives a fuller 3D view.
- Technical term explained: “Segmentation” is the process of separating an image into meaningful parts (like isolating a cup from the table).
- “Point cloud” is a 3D map made from lots of dots that show where surfaces are in space.
Choosing how to grab things
The robot needs to pick objects in ways that avoid collisions and make completing the task easier. A grasping AI model (Contact-GraspNet) suggests several possible ways to grab the object by placing the robot’s gripper in different positions and angles. Because the best grasp depends on the task and nearby obstacles, a vision-LLM (VLM)—an AI that understands both pictures and text—reviews the grasp options and selects the most appropriate one.
- Example: If the goal is to place a mug inside a microwave, grabbing it from the side might be better than from the top, so it doesn’t bump into the walls.
Planning and doing the task
The system uses a VLM (like Gemini Pro) to infer the user’s intent from their gaze sequence. For example, looking first at a plant and then at a watering can suggests “water the plant.” The model then picks the right robot “skills” to build a plan (like “go to object,” “grasp,” “move to destination,” “release”). Importantly, the order you look at objects isn’t always the order the robot must act in; the AI reasons about the correct sequence.
- Technical term explained: “Zero-shot” means the robot can handle new tasks it hasn’t specifically been trained on by using general knowledge from large AI models.
- “6 DoF” (degrees of freedom) means the robot arm can move in six ways: forward/back, left/right, up/down, plus rotate around three axes.
What did they find, and why is it important?
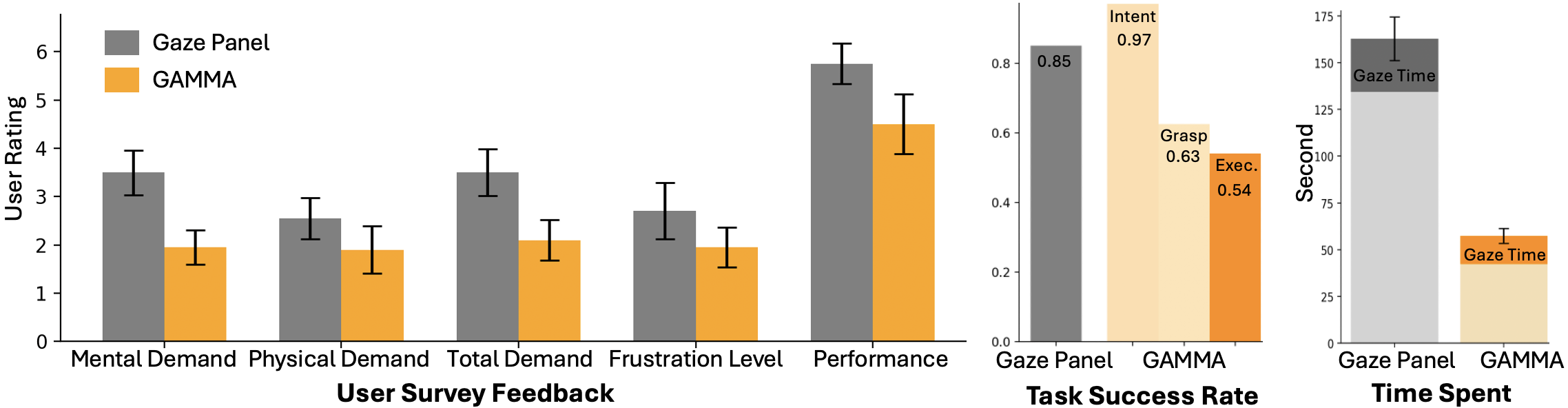
The researchers tested gamma on tabletop tasks like watering plants, picking items from clutter, and making coffee. They compared gamma to a “gaze panel” baseline where users look at on-screen buttons to manually move the robot arm and gripper.
Here are the main results:
- Gamma was faster and required less effort. Users finished tasks significantly quicker with gamma because the system handled planning and execution automatically.
- Gamma understood intent well. In lab scenes, the VLMs correctly interpreted intent in about 90% of cases. In more varied “in-the-wild” scenes (from the DROID dataset), accuracy was lower (roughly 64–73%), but still decent.
- Grasp selection was harder. Picking the perfect grasp in 3D is tough, and errors can build up. While the AI could reason about collisions and task context, it didn’t always choose a grasp that led to a smooth execution.
- Users liked control. Even though gamma was faster and felt easier, most users preferred the gaze panel because they had a stronger sense of control and could manually fix mistakes.
This matters because it shows a promising way to control robots that can help people who have limited mobility. Looking at something to make the robot act is natural and often faster than steering a robot step by step.
What does this mean for the future?
Gamma shows that combining eye tracking with powerful AI models can make robot control more natural, scalable, and less tiring. This could be especially helpful in assistive care, homes, and workplaces where people need help with physical tasks.
However, there are challenges:
- The AI still struggles with fine details of 3D grasping and can be slow to think through complex scenes.
- People want both ease and agency. A good future design may be a hybrid: the robot acts automatically most of the time, but the user can easily take over or correct it when needed.
- Making the system work in mobile settings (not just fixed tabletop scenes) will require better ways to align the user’s view with the robot’s view without relying on special markers.
- More studies with users who have mobility impairments are needed to understand real-world impact.
In short, gamma is a big step toward robots that understand us at a glance. It shows that gaze plus foundation models can turn attention into action, and it points the way to assistive robots that are both smart and user-friendly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of specific gaps and open questions the paper leaves unresolved, framed to guide actionable follow-up research.
- Gaze-to-scene mapping robustness: No quantitative evaluation of gaze localization error after egocentric-to-robot-view transformation, nor analysis of how this error propagates to segmentation, grasp selection, and task success.
- Dependency on fiducials: Reliance on ArUco markers and user proximity to the robot camera limits generality; no exploration of natural-feature SLAM/VIO for markerless, long-term, and mobile settings.
- Computationally efficient 3D gaze intersection: The system avoids per-frame 3D ray–point-cloud intersection due to cost; no study of GPU raycasting, temporal filtering, or multi-hypothesis tracking to enable accurate, real-time 3D gaze grounding.
- Personalization of fixation detection: Fixed thresholds (δ=15 px, t=2 s) are not personalized; no ablation on sensitivity, per-user calibration, or adaptive models to accommodate diverse gaze behaviors (e.g., referential or monitoring gaze).
- Midas-touch mitigation and intent disambiguation: No mechanism to prevent accidental selections, solicit confirmations, or resolve ambiguous multi-object fixations beyond VLM reasoning.
- Ordering of multi-target intents: The planner reorders steps inferred from gaze, but there is no evaluation on longer-horizon tasks (≥3–5 steps) or robustness to missing/extra fixations.
- Segmentation near gaze points: No metrics on SAM2 segmentation accuracy under gaze localization error, occlusion, small objects, or clutter; no fallback when gaze falls between adjacent instances.
- Point-cloud quality and multi-camera fusion: No characterization of depth noise, calibration drift, occlusion handling, or how fusion errors influence grasp feasibility.
- Grasp generation limits: Contact-GraspNet heuristics (rotations, bounding-box filtering) are not benchmarked against task outcomes; no adaptation from grasp failures or learning-based refinement over time.
- Context-aware grasp evaluation: VLM-based grasp scoring lacks ground truth labels of “good vs. bad for the task”; no physics- or simulation-based validation of collision and stability judgments.
- 3D representation for VLMs: Open question whether richer 3D inputs (meshes, TSDFs, NeRFs, multi-plane images) improve grasp reasoning relative to 2D images or short videos.
- Inference latency and responsiveness: VLM inference times (5–32 s) are high; no end-to-end latency breakdown, effect on user performance, or strategies for streaming, caching, or distillation for real-time control.
- Uncertainty estimation and fail-safes: No confidence calibration for VLM decisions or policies for deferring to the user under uncertainty; no formal safety checks or model-checking for planned actions.
- Recovery and mixed-initiative control: When VLM or grasp selection fails, recovery is manual via re-trial; no design or evaluation of shared autonomy, incremental correction, or interactive replanning loops.
- Closed-model dependence and reproducibility: Heavy reliance on proprietary VLMs (Gemini) without a comparable open-source baseline; unclear prompt details, seeds, and full results needed for reproducible benchmarking.
- Small-scale, constrained VLM evaluations: Intent (30 lab scenes, 45 DROID samples) and grasp-selection tests are limited in size and diversity; no stress tests with adversarial clutter, distractors, and long-horizon tasks.
- Dataset and benchmark release: No public release (or specification) of the annotated gaze-intent datasets, grasp prompts, or evaluation protocols to standardize comparisons.
- Generalization claims vs. scope: “Zero-shot manipulation” is demonstrated on tabletop tasks; no evaluation on deformable objects, tool use, non-prehensile actions, moving targets, or tasks requiring tight tolerances.
- Mobile manipulation and co-localization: Future work mentions mobility, but there is no plan or baseline for dynamic re-localization, long-term mapping, or camera–robot extrinsic drift compensation.
- User study limitations: Small N=6, healthy participants, short practice; no counterbalancing details, learning-effect controls, or statistical power analysis; lacks evaluation with target users (e.g., varying motor/oculomotor impairments).
- Agency vs. automation design: Users preferred more control; no concrete design or evaluation of hybrid autonomy, fluid mode switching, and explainability to align automation with perceived agency.
- Human factors under latency: No study on how delayed or inconsistent autonomy affects trust, frustration, and strategy adaptation over repeated interactions.
- Safety assessment: No formal hazard analysis, real-time collision monitoring beyond grasp selection, or verification that planned motions respect safety envelopes near users and sensitive objects.
- Network, privacy, and cost constraints: No quantification of token/compute costs, on-device vs. cloud trade-offs, network latency/failures, or privacy implications of always-on egocentric gaze capture.
- Skill API coverage and extensibility: The parameterized skill set is not enumerated; unclear how easily new skills are added, verified, and composed reliably by the VLM planner.
- Failure mode taxonomy: End-to-end failures (gaze mapping, segmentation, intent inference, grasp generation/selection, planning, execution) are not dissected; lack of module-level attribution hinders targeted improvements.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be piloted now with available hardware (wearable gaze trackers, RGB-D cameras, 6-DoF robot arms) and commercial VLMs, following the paper’s gamma pipeline (gaze capture → visual grounding/segmentation → VLM intent inference → grasp generation/selection → execution with safety checks).
- Gaze-driven assistive tabletop manipulation for activities of daily living (ADLs)
- Sectors: healthcare, home robotics, eldercare
- What: Enable users to indicate objects and goals via gaze to perform pick-and-place, fetching, putting items into baskets, watering plants, making coffee, and clearing clutter.
- Tools/Products/Workflow: “Gamma Assist Kit” (smart glasses + dual RGB-D + ROS package with SAM2 + Contact-GraspNet + VLM prompts), preset skill APIs (pick, place, open/close, pour).
- Assumptions/Dependencies: Stationary workspace; ArUco markers for co-localization; user near robot camera viewpoint; 6-DoF arm with gripper; cloud VLM access (latency); human supervision and E-stop; tabletop tasks.
- Human-in-the-loop kitting and bin-picking in light manufacturing cells
- Sectors: manufacturing, electronics assembly
- What: Operators use gaze to select the next part or bin and the target tray/fixture; gamma composes pick-and-place; reduces joystick panels and speeds task transitions.
- Tools/Products/Workflow: “Gaze-to-Skill Composer” integrated into MES/PLC; dashboards showing gaze fixations; ROS/MoveIt pipeline for execution; preset trays/fixtures as objects.
- Assumptions/Dependencies: Consistent lighting; known bins; moderate clutter; per-cell calibration with markers; operator training for fixation dwell.
- Gaze-augmented teleoperation fallback for existing robotic arms
- Sectors: robotics integrators, field service
- What: Retrofit teleop setups with a gaze overlay to quickly indicate waypoints/targets, switching between gaze-driven autonomy and manual control to address the agency vs. automation trade-off noted in the study.
- Tools/Products/Workflow: “Hybrid Shared Autonomy UI” (gaze panel + gamma intent mode); foot pedal/voice to toggle modes; skill library with parameterized go_to(pose), grasp, place.
- Assumptions/Dependencies: Operator eyewear compatibility; safety-certified shared control; network reliability.
- Assistive robotics in inpatient/outpatient therapy labs
- Sectors: rehabilitation, occupational therapy
- What: Use gaze for goal-directed exercises (e.g., moving real objects across stations), measuring effort and time; personalize autonomy level to user ability.
- Tools/Products/Workflow: Therapist console for autonomy level, dwell time, and safety thresholds; session logging for outcomes.
- Assumptions/Dependencies: Clinical safety protocols; adjustable dwell thresholds for atypical gaze patterns; staff supervision.
- Quality inspection and rework triage via gaze pointing
- Sectors: manufacturing QA, electronics/assembly lines
- What: Inspectors look at suspect components; robot brings item to inspection station or marks/repositions it; speeds triage without handheld pointers.
- Tools/Products/Workflow: “Gaze-to-Rework” pipeline; semantic zones for OK/NG; VLM reasoning limited to target selection and safe approach.
- Assumptions/Dependencies: Clear visibility, known fixtures; short, safe motions; precise gaze-to-object mapping.
- Laboratory bench assistance for sample handling
- Sectors: biotech, chemistry labs, education labs
- What: Researchers indicate tubes, racks, pipette tips; robot rearranges or presents items to reduce hand fatigue and contamination risk.
- Tools/Products/Workflow: Bench-mounted cameras; pre-defined labware CAD/meshes; simple skill macros (present, cap/decap if supported).
- Assumptions/Dependencies: Clean tabletop scenes; limited fluid handling; safety guarding; dwell thresholds tuned to avoid incidental glances.
- Research benchmark for gaze-intent inference and grasp selection
- Sectors: academia (HRI, robotics)
- What: Use the paper’s intent datasets and ablation methodology to benchmark VLMs (Gemini Pro/Flash, GPT-4o, Llama) and CV back-ends (SAM2, Contact-GraspNet) under clutter/attacks.
- Tools/Products/Workflow: Reproducible evaluation harness; prompt libraries; multi-view prompts for grasp selection.
- Assumptions/Dependencies: Access to VLM APIs; consistent prompts; reproducible sensor streams.
- Accessibility prototyping for gaze-first human-computer interaction
- Sectors: accessibility software, UX research
- What: Translate gamma’s fixation aggregation and dwell thresholds into gaze-first UX patterns (e.g., gaze shortcuts to trigger predefined robot routines at home).
- Tools/Products/Workflow: “Gaze Macro Builder” for routine chaining (pick cup → fill → deliver); home dashboard for caregivers.
- Assumptions/Dependencies: Known home layout; stable connectivity; caregiver oversight; fallback voice or switch input.
- Training and education in HRI and shared autonomy
- Sectors: higher education, vocational training, robotics bootcamps
- What: Use gamma to teach multimodal grounding, intent inference, and safe shared autonomy; lab exercises on agency vs. autonomy trade-offs.
- Tools/Products/Workflow: Course kits with modular gamma stack; assignments on prompt design, segmentation robustness, grasp reasoning.
- Assumptions/Dependencies: Teaching lab arms; student access to VLM credits; safety protocols.
- Policy pilots on data governance and safety for gaze-controlled robots
- Sectors: policy, standards bodies, hospital safety committees
- What: Run controlled pilots to craft guidelines for gaze data retention, on-device inference, and autonomy escalation; inform procurement and certification.
- Tools/Products/Workflow: Risk assessments (ISO/TS 15066 context), audit logs for gaze/actuation, incident response playbooks.
- Assumptions/Dependencies: Institutional review and IRB-like oversight; legal counsel on biometric data; vendor security posture.
Long-Term Applications
These require advances in model robustness, mobile manipulation, on-device inference, scene-level SLAM-based co-localization (beyond ArUco), and broader validation with target user populations.
- Full-home mobile manipulation controlled by gaze and natural language
- Sectors: home robotics, eldercare
- What: Users glance at objects across rooms and describe goals (“put the mug in the dishwasher”); robot navigates, opens appliances, avoids collisions, and completes tasks.
- Tools/Products/Workflow: Markerless visual co-localization; integrated navigation + manipulation; learned affordances; preference models.
- Assumptions/Dependencies: Accurate egocentric-to-global pose via natural features; robust object/pose detection in varied lighting; low-latency on-device VLMs.
- Surgical and clinical “gaze scrub nurse” assistance
- Sectors: healthcare, operating rooms
- What: Surgeon/nurse gaze indicates instruments or trays; robot prepares/presents tools or adjusts endoscopic camera viewpoint.
- Tools/Products/Workflow: Sterile-certified robot arms; strict safety gating and intent confirmation; integration with OR workflows.
- Assumptions/Dependencies: Near-zero false positives; medically certified devices; extensive validation, simulation, and training.
- Warehouse picking and exception handling via gaze for mobile pickers
- Sectors: logistics, e-commerce fulfillment
- What: Workers wearing smart glasses indicate SKUs or exceptions; co-bot executes grasps or repositions totes; speeds last-meter decisions.
- Tools/Products/Workflow: “Gaze-to-WMS” interface; semantic digital twins of racks; mobile manipulation carts.
- Assumptions/Dependencies: Robust perception in dynamic aisles; high-availability networks; line-of-sight constraints relaxed with SLAM.
- Advanced shared autonomy with user-agency modeling
- Sectors: HRI, software, accessibility
- What: Systems that learn each user’s preferred autonomy blend, switching fluidly between autonomous gamma mode and gaze-panel/manual control to maximize perceived agency.
- Tools/Products/Workflow: User preference and trust estimators; Bayesian arbitration between modes; continual learning with human corrections.
- Assumptions/Dependencies: Safe learning under deployment; explainable decisions; reliable intervention affordances.
- On-device, private gaze-VLM stacks for hospitals and homes
- Sectors: healthcare IT, privacy tech
- What: Run intent inference and grasp reasoning locally on edge GPUs to avoid transmitting sensitive gaze streams; differential privacy for logs.
- Tools/Products/Workflow: Distilled/quantized VLMs; retrieval-augmented local knowledge; secure enclaves; policy-compliant retention.
- Assumptions/Dependencies: Sufficient edge compute; robust distillation without performance loss; compliance with HIPAA/GDPR.
- Co-adaptive rehabilitation and motor learning
- Sectors: rehab, neuroscience
- What: Use gaze-intent signals as biomarkers of cognitive/motor planning; robots adapt task difficulty and autonomy to promote recovery and reduce fatigue over time.
- Tools/Products/Workflow: Longitudinal models of gaze dynamics; therapist-configured curricula; outcome dashboards.
- Assumptions/Dependencies: Clinical trials; standardized metrics; multimodal sensing (EMG, posture) for richer intent.
- Precision agriculture and greenhouse tending with gaze planning
- Sectors: agriculture, agri-robotics
- What: Workers indicate plants or tasks (prune, water, harvest) with gaze; robot executes context-aware manipulation among dense foliage.
- Tools/Products/Workflow: Semantic plant detectors; task-conditioned grasping; mobile base; seasonal retraining.
- Assumptions/Dependencies: Robust outdoor/greenhouse perception; manipulator reach and compliance; safety near humans.
- Industrial rework and fine assembly with constraint-aware grasping
- Sectors: high-mix manufacturing, electronics
- What: Workers specify micro-operations by gaze; systems reason about forbidden grasps (e.g., avoid heatsinks, delicate leads) and select task-appropriate grasps.
- Tools/Products/Workflow: Domain adapters for VLM grasp analysis; high-precision grippers; vision-metrology feedback.
- Assumptions/Dependencies: Sub-millimeter accuracy; rich CAD/context priors; low-latency inference.
- Standardization and certification frameworks for gaze-controlled robots
- Sectors: standards bodies, insurers, regulators
- What: Define test suites for false-fixation handling, autonomy escalation, and fail-safe behaviors; develop certification marks for assistive gaze control.
- Tools/Products/Workflow: Open benchmarks (adversarial clutter, visual attacks), reference implementations, scenario libraries.
- Assumptions/Dependencies: Cross-industry consortium; incident reporting ecosystems; insurer acceptance.
- Consumer “routine composer” for smart homes with robot integration
- Sectors: consumer IoT, home automation
- What: Gaze-select a sequence (e.g., “set table,” “load dishwasher”); system compiles context-aware skill graphs and schedules execution across devices and robot.
- Tools/Products/Workflow: Low-code routine builder; multi-agent orchestration across appliances and robot; semantic mapping of the home.
- Assumptions/Dependencies: Interoperable APIs (Matter/ROS 2); robust semantic maps; household safety and child-proofing.
Notes on feasibility across applications:
- Performance bounds: The paper shows strong gains in user effort/time, but grasp reliability and inference latency remain bottlenecks; compounding errors require human-in-the-loop recovery.
- Environment constraints: Current pipeline favors fixed, tabletop scenes with markers; mobile and markerless deployment needs SLAM-grade co-localization and better 3D understanding.
- Safety and agency: Hybrid control is essential to align with user preference for control; explicit confirmation and quick overrides should be default.
- Compute and connectivity: Many scenarios assume cloud VLMs; for regulated or connectivity-limited sites, edge inference and model distillation are prerequisites.
- User variability: Dwell thresholds and fixation detection must be adapted to individual gaze patterns, especially in populations with atypical oculomotor behavior.
Glossary
- 6-DoF: Six degrees of freedom; a full 3D pose (position and orientation) specification for a robot or object. "users control the 6-DoF pose of the robotic arm and the gripper by selecting virtual buttons (visual markers) on a screen using their eye gaze."
- ArUco markers: Fiducial visual markers used for camera calibration and pose estimation. "we employ ArUco markers as reference features, providing an efficient solution for gaze mapping between the user and the robot’s shared workspace."
- Chain-of-thought reasoning: A prompting strategy that elicits step-by-step reasoning in large models. "we design both the visual gaze prompt and the text prompt to encourage chain-of-thought reasoning within the model output."
- Contact-GraspNet: A model that generates 6-DoF grasp poses from point clouds in cluttered scenes. "Contact-GraspNet's predictions depend heavily on the viewpoint used during training, typically optimized for top-down perspectives."
- Egocentric eye gaze: Eye-tracking signals captured from the user’s first-person viewpoint. "We propose gamma as a general framework for controlling a robotic arm to perform manipulation tasks using egocentric eye gaze."
- Feature-based real-time camera pose estimation: Estimating camera position and orientation by matching image features in real time. "using feature-based real-time camera pose estimation."
- Foundation models: Large pretrained models (often multimodal) that generalize across tasks without task-specific training. "Foundation models trained on large-scale multimodal data bring strong generalization capabilities and semantic grounding"
- Gaze fixations: Periods where the eyes remain relatively still, indicating focused attention. "Given the predicted gaze fixations on the image from the robot's camera view"
- Gaze ray: A 3D ray derived from eye gaze used to localize where the user is looking in space. "computing the intersection of the gaze ray with the 3D point cloud from the robot’s viewpoint"
- Grasp pose: The 6-DoF configuration of a gripper to securely grasp an object. "Selecting an appropriate grasp pose is critical for successful object manipulation."
- Human-in-the-loop: Systems where humans provide input or oversight during autonomous operation. "human-in-the-loop industrial settings."
- Instance segmentation: Computer vision task that identifies and separates individual object instances in an image. "instance segmentation maps from each of the two robot-mounted cameras."
- Intent inference: Predicting a user’s goal or desired action from observed signals (e.g., gaze). "gaze-based intent inference is inherently ambiguous and typically requires additional contextual reasoning to accurately interpret user goals."
- Iterative visual prompts: Repeatedly refined visual inputs to guide VLMs in planning or reasoning. "using iterative visual prompts for zero-shot planning of robotics tasks."
- Likert-scale survey: A questionnaire format where respondents rate items on an ordered scale. "asking them to fill out a likert-scale survey adapted from the NASA TLX questionnaire"
- LLM-as-policy: Using a LLM directly to select actions or control policies. "One-shot success in zero-shot LLM-as-policy systems remains unreliable"
- Motion primitive: A low-level, parameterized robot action used as a building block for complex tasks. "a sequence of atomic skills s(o, a), where each skill applies a parameterized motion primitive a to a target object o."
- Object segmentation: Partitioning an image into regions corresponding to objects of interest. "gamma combines off-the-shelf computer vision models for object segmentation and grasp prediction"
- Parameterized robot APIs: Robot control interfaces where skills or commands accept parameters (e.g., objects, poses). "gamma assumes access to a set of parameterized robot APIs that contain both high-level skills such as open(door), and low-level commands such as go_to(pose)."
- Point cloud: A set of 3D points representing the geometry of a scene or object. "the 3D point cloud from the robot’s viewpoint"
- Point-query-based segmentation: Segmentation method that extracts an object mask from a user-specified point. "gamma employs point-query-based segmentation using SAM2 to generate object masks"
- RGB-D: Color (RGB) plus depth sensing modality used in perception. "a dual RGB-D camera setup."
- Retrieval-augmented reasoning: Enhancing model reasoning by fetching relevant information before generating a response. "utilize more specialized reasoning models that does retrieval-augmented reasoning before generating a response."
- Semantic grounding: Aligning model predictions with meaningful, high-level concepts in the world. "bring strong generalization capabilities and semantic grounding"
- Skill composer: A module that sequences parameterized skills into an executable behavior program. "the skill composer generates a behavior program"
- Teleoperation: Remote control of a robot by a human operator. "assistive multimodal teleoperation"
- Vision-based grasp prediction: Inferring feasible gripper poses from visual data (e.g., images or point clouds). "Vision-based grasp prediction models propose gripper poses that can securely grasp and lift objects"
- Vision-LLM (VLM): A multimodal model that processes both visual and textual inputs for reasoning and control. "a vision-LLM to infer user intent"
- Visual co-localization: Estimating relative camera poses across views using natural scene features. "more advanced visual co-localization techniques beyond fixed ArUco markers"
- Visual prompting: Supplying images or videos as prompts to guide a VLM’s reasoning. "applies visual prompting to both intent recognition and low-level grasp selection."
- Zero-shot manipulation: Executing robotic tasks without task-specific training by leveraging pretrained models. "enable direct zero-shot robot manipulation using gaze alone."
- Zero-shot motion generation: Producing robot motions without prior task-specific demonstrations or training. "execution risk and failure rate associated with zero-shot motion generation"
Collections
Sign up for free to add this paper to one or more collections.