Thinking with Map: Reinforced Parallel Map-Augmented Agent for Geolocalization
Abstract: The image geolocalization task aims to predict the location where an image was taken anywhere on Earth using visual clues. Existing large vision-LLM (LVLM) approaches leverage world knowledge, chain-of-thought reasoning, and agentic capabilities, but overlook a common strategy used by humans -- using maps. In this work, we first equip the model \textit{Thinking with Map} ability and formulate it as an agent-in-the-map loop. We develop a two-stage optimization scheme for it, including agentic reinforcement learning (RL) followed by parallel test-time scaling (TTS). The RL strengthens the agentic capability of model to improve sampling efficiency, and the parallel TTS enables the model to explore multiple candidate paths before making the final prediction, which is crucial for geolocalization. To evaluate our method on up-to-date and in-the-wild images, we further present MAPBench, a comprehensive geolocalization training and evaluation benchmark composed entirely of real-world images. Experimental results show that our method outperforms existing open- and closed-source models on most metrics, specifically improving Acc@500m from 8.0\% to 22.1\% compared to \textit{Gemini-3-Pro} with Google Search/Map grounded mode.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching an AI to figure out where a photo was taken on Earth (geolocalization) by doing what people naturally do: look for clues in the picture and then use a map to check those clues. The authors build an AI “agent” that can search maps, look up places, and compare what it finds to the photo. They call this skill “Thinking with Map.”
What questions are the researchers asking?
- Can a vision-and-language AI do better at guessing a photo’s location if it actually uses map tools (like searching nearby places or checking road layouts) instead of only “thinking in its head”?
- Can training with rewards (so the AI learns which actions lead to good results) and letting the AI explore several ideas at once make it more accurate?
- How well does this approach work on new, real-world photos, not just old or easy datasets?
How did they do it?
The authors combine three ideas. Think of the AI as a detective who uses a city map while solving a mystery.
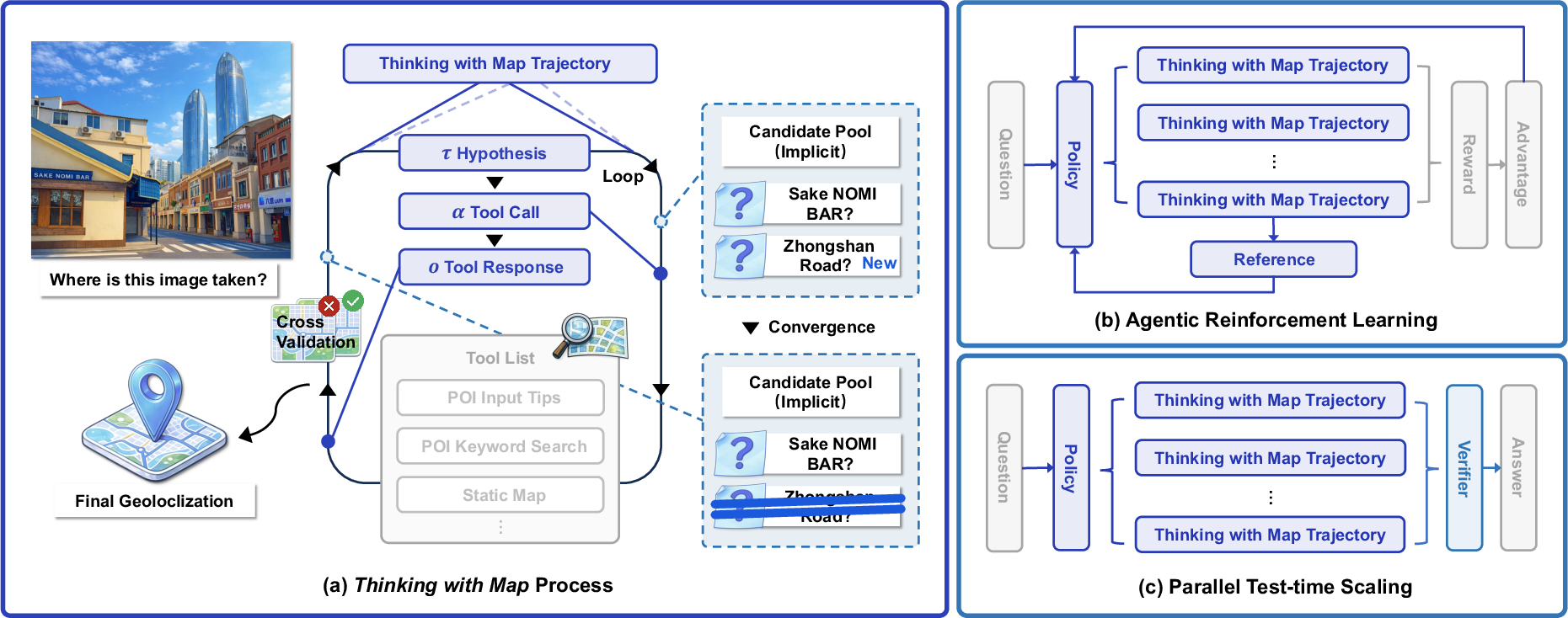
1) “Thinking with Map”: an agent-in-the-map loop
The AI repeats a simple loop, like a detective:
- Make a guess (a few possible places based on clues in the photo: language on signs, architectural style, climate, road shapes).
- Use map tools to check the guess.
- Compare the map results with the photo (Do the nearby stores match? Does the street pattern look right?).
- Keep or drop the guess, and try again if needed.
To do this, the AI can call map tools, similar to apps you’d use:
- Search for places (POIs, “Points of Interest,” like restaurants, schools, or landmarks).
- Get details about a place (address, category).
- View static or satellite maps to compare layouts.
- Zoom into parts of the photo to inspect small clues (like a street name or a logo).
This creates a chain of evidence the AI can follow and double-check.
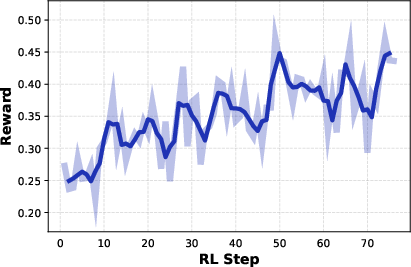
2) Reinforcement Learning (RL): practice with feedback
Reinforcement Learning is like practicing with a coach who gives rewards when you get closer to the right answer. The AI tries different actions (which tool to use next, what to search), gets a score based on how close its final guess is to the true location, and learns to choose better actions next time. The authors give higher rewards for being very close (within 500 meters) and smaller rewards for being roughly right (like city-level).
3) Parallel test-time scaling: many detectives, one judge
Instead of following just one line of thinking, the AI runs several “mini-investigations” in parallel (like multiple detectives chasing different leads). Each one uses the map tools independently. At the end, a “verifier” (another AI) reviews the separate trails and picks the best final answer. This works well because map results (like actual store names and positions) are factual, so wrong paths tend to contradict the photo or each other and are easier to weed out.
A new benchmark: MAPBench
Many older datasets are out of date or too easy (famous landmarks that models may simply memorize), and they often miss certain regions. The authors created MAPBench: 5,000 recent, real street-view images across cities in China, split into “easy” and “hard” cases. This helps test true reasoning and map-using ability, not just memory.
What did they find?
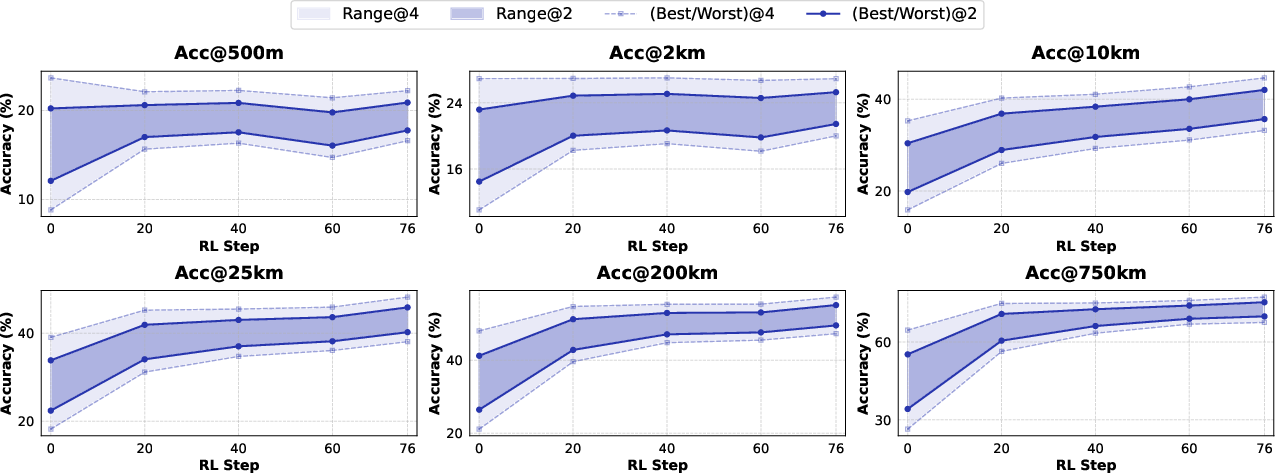
- Using maps helps a lot for fine-grained accuracy (getting very close to the exact spot).
- Training with RL makes the agent better at deciding which tools to use and when.
- Running several parallel investigations and then using a verifier improves results further.
On modern geolocalization tests, their method often beats both open-source and closed-source systems. A key highlight from the paper’s abstract: compared to a strong commercial model (Gemini-3-Pro using Google Search/Map), their system improved the “within 500 meters” accuracy from about 8.0% to 22.1%. That’s nearly tripling the success rate at pinpoint accuracy.
In short, the combination of “Think with Map” + RL + parallel-and-verify produced clear gains, especially for tough, real-world images where there aren’t obvious landmark hints.
Why does it matter?
- More trustworthy reasoning: Because the AI checks facts against real maps, its reasoning is less “guessy” and more grounded in the world.
- Better at hard, real photos: This is useful for tasks like helping travelers, organizing photo collections, journalism, disaster response, or any application that needs to know where an image came from.
- A practical recipe: The paper shows a simple and effective strategy—give the model the right tools (maps), let it practice with feedback (RL), and let it explore several ideas at once (parallel sampling with a verifier).
Looking ahead
The authors note there’s still room to grow. Humans use clever map tricks (like reasoning about directions and relative positions) that the AI doesn’t fully master yet. Training on larger, more diverse interaction data and improving long-step planning could make future agents even better at solving location mysteries in one clean shot, without needing multiple parallel tries.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- Generalization beyond a single backbone: Results and training are centered on Qwen3‑VL‑30B‑A3B; there is no systematic study of model-scale dependence, architecture effects, or portability to smaller models (e.g., 7B) and other LVLMs.
- Global tool-provider coverage and selection policy: The agent uses AMAP and Google Maps APIs, but lacks a principled strategy for which provider to call when, how to handle provider unavailability, rate limits, or region-specific coverage gaps and biases.
- Robustness to noisy/outdated map data: While noisy map outputs are noted to hurt coarse localization, the paper does not provide mechanisms to detect outdated POIs, filter erroneous search results, reconcile contradictory map information, or quantify the impact of map data quality on accuracy.
- Formalization of the candidate pool “Update” function: The implicit candidate pool maintenance is not specified—there is no concrete algorithm for hypothesis ranking, pruning, memory management, or explicit state representation to support systematic improvements.
- Verifier design and objective: The parallel verifier is an LVLM that “summarizes evidence,” but there is no formal trajectory-scoring function (e.g., causal consistency metrics, rule-based checks, or confidence calibration), nor ablations of non-LLM verifiers or hybrid verifiers combining symbolic and neural scoring.
- Handling verifier errors: The paper does not measure or mitigate verifier false negatives/positives, despite known issues in LLM verification; there is no strategy to detect misaggregation or to re-evaluate borderline trajectories.
- Diversity in parallel sampling: Parallel TTS scales pass@K, but there is no method to explicitly diversify samples (e.g., hypothesis priors, temperature control, nucleus sampling, MAP-Elites, or disagreement-based resampling) to reduce redundancy and improve coverage of plausible locations.
- Budget, latency, and cost analysis: The work does not quantify tool-call counts, context length, wall-clock latency, or monetary/API costs for different N in parallel TTS and for sequential vs. parallel reasoning.
- Upper-bound exploration: Parallel sampling is evaluated only up to N=4; there is no scaling study to larger N, nor analysis of diminishing returns, optimal N under budget constraints, or adaptive stopping criteria.
- Reward shaping beyond distance: RL uses piecewise distance rewards only; there is no reward for intermediate tool-use quality (e.g., correct POI disambiguation, map-view selection, spatial consistency checks), nor credit assignment across multi-step trajectories.
- RL algorithm ablations: GRPO is used without comparisons to alternative algorithms (e.g., DPO variants, PPO, policy-gradient with best-of-n sampling, off-policy RL), nor studies on stability, hyperparameters, or the effect of group size.
- Limited RL data scale and diversity: RL training is relatively small (MAPBench train + 2,000 IMAGEO-2), with no analysis of scaling laws, cross-domain generalization, or curriculum design for progressively harder geographies and scenes.
- Orientation and spatial reasoning: The agent reportedly fails to infer orientation and relative spatial relationships; there is no dedicated mechanism (e.g., sun/shadow analysis, street topology matching, skyline/terrain orientation cues) to build these human-like skills.
- Pixel-space tool use: Only a basic image_zoom_tool is included; there is no exploration of richer visual operations (e.g., crop, annotate, segment, detect text/signs) or how pixel-space reasoning interacts with map tools to improve fine localization.
- Integration with retrieval/classification paradigms: The agent does not combine map-augmented reasoning with geo-retrieval or geocell classification, leaving unexplored hybrid systems that could bootstrap coarse localization before fine verification.
- Failure modes in low-POI/remote areas: The approach relies heavily on POI search; there is no strategy for natural scenes, rural or wilderness settings with sparse POIs, or indoor images without map anchors.
- Multi-image and temporal contexts: The paper focuses on single-image localization; it does not address multi-view, video, or time-of-day/seasonal cues that could materially improve accuracy.
- Difficulty tiering based on model predictions: MAPBench’s easy/hard split is defined using GPT-5, GPT‑o3, and Qwen3‑VL‑235B outputs, which may bake in model biases; a more objective, human-annotated or feature-based difficulty scheme is not provided.
- Geographic coverage and external validity: MAPBench is China-focused; the paper does not offer a globally comprehensive, up-to-date benchmark nor analyze performance across continents, languages, signage scripts, and cultural/architectural variability.
- Label quality and annotation protocol: The dataset creation process (e.g., ground-truth acquisition, label noise rates, QA) is not fully detailed in the main text; there is no measurement of label uncertainty and its effect on Acc@Dis.
- Tool orchestration policies: The agent’s tool-calling strategy (ordering, backtracking, confirmation steps) is not formalized or learned; there is no planner that explicitly models tool dependencies and action-value trade-offs.
- Confidence calibration and abstention: The system outputs a single answer; it does not provide calibrated uncertainty, abstain decisions, or confidence-based fallback strategies (e.g., output city-level when fine-level is unreliable).
- Safety, ethics, and reproducibility: The paper does not discuss privacy risks (e.g., sensitive locations), API terms and rate limits, or open-sourcing of tool interfaces, making full reproducibility and deployment implications unclear.
- Interpretability evaluation: Although “self-verifying” trajectories are claimed, there is no quantitative evaluation of interpretability (e.g., human ratings of reasoning plausibility, evidence alignment scores, or explanation quality metrics).
- Adaptive provider fusion: The agent does not learn a policy to fuse outputs from multiple map providers or web sources when they disagree; criteria for trust, recency, and corroboration are not specified.
- Calibration of pass@K to pass@1: RL appears to tighten pass@K variance, but best@500m gains are limited; it remains open how to better convert ensemble/parallel gains into single-shot accuracy (e.g., via improved verifier, better trajectory scoring, or meta-learning).
- Resource-constrained deployment: There is no analysis of how the method performs under strict token budgets or limited tool-call quotas, nor techniques for budget-aware planning and compression of reasoning context.
Practical Applications
Overview
Below are practical, real-world applications that build directly on the paper’s findings and innovations: a map-augmented LVLM agent (“Thinking with Map”), an agent-in-the-map loop with callable map tools, agentic RL (GRPO) to improve pass@K, and parallel test-time scaling (TTS) with a verifier to turn pass@K gains into pass@1. Each application lists relevant sectors, potential tools/products/workflows, and assumptions or dependencies that affect feasibility.
Immediate Applications
These applications can be deployed now, leveraging the paper’s demonstrated agent framework, tool suite (poi_keyword_search, poi_detail_query, static_map_query, satellite_map_query, image_zoom_tool), RL improvements, and parallel TTS with a verifier.
- Sector: Journalism/OSINT, Policy
- Application: Rapid geolocation of user-generated content for verification
- What it does: Newsrooms and watchdogs geolocate images from social platforms during breaking events; parallel hypotheses reduce false positives and create a verifiable evidence chain.
- Tools/products/workflows: “Geolocate copilot” API that wraps the agent-in-the-map loop; standardized JSON outputs with map-query traces; parallel TTS + verifier for selection.
- Assumptions/dependencies: Map API access and rate limits; reliable POI freshness; human review for edge cases; privacy/compliance for processing UGC.
- Sector: Public Safety/Disaster Response
- Application: Damage assessment triage from crowd-sourced images
- What it does: Emergency operation centers ingest images of floods, fires, or infrastructure damage; the agent identifies plausible lat/long and nearest critical facilities.
- Tools/products/workflows: Batch pipeline with parallel sampling; static/satellite map overlays; integration into incident management systems (e.g., ICS dashboards).
- Assumptions/dependencies: Network connectivity to map providers; model guardrails for low-quality/ambiguous imagery; operational SOPs for confidence thresholds.
- Sector: Finance/Insurance
- Application: Claims verification and fraud detection via image geolocation
- What it does: Auto-check whether images of collisions, property damage, or receipts were taken where claimed; detect mismatches in city/region and storefront POIs.
- Tools/products/workflows: Claims intake plugin; poi_detail_query and static_map_query for storefronts; audit trail of map calls and verifier decisions.
- Assumptions/dependencies: Legal compliance for automated decision support; scalable parallel TTS cost control; diverse domain fine-tuning for indoor/outdoor scenes.
- Sector: E-commerce/Marketplaces
- Application: Listing trust and policy enforcement
- What it does: Verify that photos in real-estate and secondhand marketplaces correspond to stated neighborhoods or venues; flag deceptive listings.
- Tools/products/workflows: Seller-side pre-check; poi_keyword_search to match signage and nearby POIs; confidence scoring; moderation queue.
- Assumptions/dependencies: POI completeness and timeliness; policies for acceptable geolocation uncertainty; multilingual POI support.
- Sector: Mobility/Ride-hailing
- Application: Incident geolocation from driver/rider submissions
- What it does: Infer exact pickup/drop-off or dispute locations from uploaded photos (e.g., curbside, parking lot, gate) to speed case resolution.
- Tools/products/workflows: In-app agent microservice; image_zoom_tool for fine clues; parallel TTS for hypothesis exploration; nearest-road topology check via static map.
- Assumptions/dependencies: Sufficient visual context (signage, facades); rate limits; potential integration with platform trip logs for cross-checking.
- Sector: Cultural Heritage/Archives, Academia
- Application: Photo archive geotagging and curation
- What it does: Libraries and museums geotag legacy collections, enabling map-based exploration and research on urban change.
- Tools/products/workflows: Batch geotag pipeline; candidate pool maintenance to store multiple plausible locations; curator-in-the-loop verification.
- Assumptions/dependencies: Older imagery may show defunct POIs; curated human review; long-tail domain gaps in training data.
- Sector: Social Media/Trust & Safety
- Application: Location-sensitive content moderation
- What it does: Detect cases where precise locations are revealed (e.g., private residences, schools) to enforce platform policy or warn users.
- Tools/products/workflows: Real-time agent call on upload; map proximity checks to sensitive POI types; confidence-based action (warn, blur, escalate).
- Assumptions/dependencies: Clear policy definitions; privacy and consent; minimizing false alarms via verifier and human escalation.
- Sector: Consumer Software/Daily Life
- Application: Personal photo organizer for geotag recovery
- What it does: Users geotag old photos lacking GPS; cluster images by city or neighborhood; suggest itineraries based on inferred paths.
- Tools/products/workflows: Mobile integration; lightweight parallel sampling; interactive UI for selecting among candidate locations.
- Assumptions/dependencies: On-device or cloud inference costs; map API quotas; UX for uncertainty and corrections.
Long-Term Applications
These rely on scaling, research into orientation/spatial reasoning and broader tool-use proficiency, expanded training data, or tighter integrations/regulatory readiness.
- Sector: Robotics/Autonomy
- Application: GPS-light urban localization for delivery drones/robots
- What it does: Use visual clues and map topology to localize when GNSS is degraded; validate route decisions against map evidence.
- Tools/products/workflows: Real-time agent loop; stronger orientation inference; hybrid sensor fusion; safety-certified verifier.
- Assumptions/dependencies: Low-latency inference; robust orientation and relative spatial reasoning (noted limitation); extensive RL in diverse environments.
- Sector: AR/Consumer
- Application: Place-anchored AR overlays without GPS
- What it does: Anchor AR scenes to storefronts or landmarks by visually geolocating the camera view and verifying with maps.
- Tools/products/workflows: On-device map tool proxies; fast parallel sampling; fallback to cached POIs; visual SLAM integration.
- Assumptions/dependencies: Efficient mobile inference; local/offline POI databases; privacy-preserving map interactions.
- Sector: Accessibility/Healthcare
- Application: Assistive navigation for visually impaired users
- What it does: Infer location from camera feed and describe surroundings and nearest POIs; guide users along safe routes.
- Tools/products/workflows: Continuous agent loop with streaming imagery; satellite/static maps for context; speech interface.
- Assumptions/dependencies: High reliability and safety guarantees; robust reasoning in low-visual-clue scenarios; compliance with medical device standards if applicable.
- Sector: Platform Integrity/Misinformation
- Application: Platform-scale misinformation geolocation checks
- What it does: Automatically geolocate images tied to claims (e.g., event locations); produce verifiable traces for content labeling.
- Tools/products/workflows: Distributed parallel TTS; hierarchical verifiers to reduce false negatives; audit logs for policy/legal review.
- Assumptions/dependencies: Cost and throughput; cross-region map coverage; appeals process and due process.
- Sector: Mapping/Geospatial Industry
- Application: POI freshness auditing via crowd images
- What it does: Detect POIs that have changed (closed/moved/rebranded) by comparing map results against visual evidence.
- Tools/products/workflows: Batch agent processing; change detection pipeline; human-in-the-loop for edits; data governance.
- Assumptions/dependencies: Access to map provider update APIs; careful quality control; regional policy and licensing.
- Sector: Emergency Services/Public Policy
- Application: 911/112 dispatch augmentation with image geolocation
- What it does: Operators receive images and the system proposes likely locations, nearest responders, and ingress routes.
- Tools/products/workflows: Real-time agent; map overlays; legal-grade audit trail; integration with CAD systems.
- Assumptions/dependencies: Regulatory approval; service-level reliability; secure data handling.
- Sector: Legal/Compliance
- Application: Chain-of-custody evidencing for geolocation-assisted investigations
- What it does: Preserve tool-call traces and verifier decisions as structured evidence; improve transparency in proceedings.
- Tools/products/workflows: Immutable logs; standardized JSON outputs; third-party verifier (TinyV-like) to reduce false negatives.
- Assumptions/dependencies: Standards for admissibility; independent audits; bias and error documentation.
- Sector: AI/Research/Education
- Application: Benchmarking and training for agentic map reasoning
- What it does: Extend MAPBench globally and build curricula for RL-based map reasoning; study pass@K→pass@1 dynamics and verifier design.
- Tools/products/workflows: Open datasets with difficulty tiers; GRPO pipelines; synthetic and real map interaction trajectories.
- Assumptions/dependencies: Expanded, up-to-date global datasets; shared tool interfaces across map providers; reproducible evaluation.
- Sector: Privacy/Security
- Application: Location leakage detection and redaction
- What it does: Identify when images allow fine-grained geolocation and automatically blur/alter sensitive features.
- Tools/products/workflows: Detection agent; policy rules (schools/hospitals/private residences); user controls and explanations.
- Assumptions/dependencies: Clear policy norms; explainability; balance between utility and privacy.
Cross-cutting assumptions and dependencies
- Map API coverage, rate limits, costs, and licensing (AMAP/Google Maps and others) vary by region.
- POI freshness and quality can materially impact accuracy (noted by the paper’s timeliness critique and MAPBench rationale).
- Parallel TTS increases compute costs; practical systems need budgeting and adaptive sampling.
- RL generalization requires diverse, up-to-date training data; current orientation reasoning is a known limitation.
- Privacy, consent, and regulatory compliance are essential when processing user images and storing audit trails.
- Multilingual, region-specific signage and cultural cues may require additional fine-tuning or locale-specific tool adapters.
Glossary
- Acc@500m: Accuracy measured by whether a prediction falls within 500 meters of the ground truth. "specifically improving Acc@500m from 8.0\% to 22.1\% compared to Gemini-3-Pro with Google Search/Map grounded mode."
- Acc@Dis: A family of accuracy metrics evaluated at multiple distance thresholds. "Results are reported as accuracy at multiple granularities ()."
- agent-in-the-map loop: An iterative process where the agent proposes hypotheses, queries map tools, verifies evidence, and converges on a location. "we first equip the model Thinking with Map ability and formulate it as an agent-in-the-map loop."
- agentic reinforcement learning (RL): Reinforcement learning focused on improving an agent’s decision-making and tool-use abilities. "including agentic reinforcement learning (RL) followed by parallel test-time scaling (TTS)."
- chain-of-thought (CoT) reasoning: Explicit multi-step reasoning traces generated by the model to reach a conclusion. "using chain-of-thought (CoT) reasoning"
- geocells: Discrete geographic cells used to partition the Earth for location classification. "partitions the Earth into structured ``geocells''"
- geolocalization: Inferring the geographic coordinates of an image from visual clues. "Image geolocalization is a challenging task to determine the latitude and longitude of an image as accurately as possible."
- Group Relative Policy Optimization (GRPO): A group-based policy optimization algorithm for reinforcement learning that maximizes relative advantages. "Group Relative Policy Optimization (GRPO)"
- importance sampling ratio: The likelihood ratio used to reweight sampled data under a new policy relative to an old policy in RL. "where is the importance sampling ratio"
- LVLM: Large Vision-LLM; a model that processes and reasons over both images and text. "Existing large vision-LLM (LVLM) approaches"
- MAPBench: An up-to-date, real-world geolocalization benchmark introduced in the paper. "we further present MAPBench, a comprehensive geolocalization training and evaluation benchmark"
- map-API: Programmatic interfaces to map services that return POIs, details, and map images for grounding and verification. "The abundant map-API results make the trajectories easily verified based on their causal relationships."
- map-augmented agent: An agent equipped with map tools to ground its reasoning in geographic data. "In this section, we present Thinking with Map, a map-augmented agent for improved LVLM-based geolocalization."
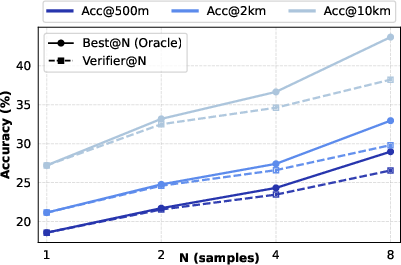
- oracle best@N: The best achievable result among N samples assuming perfect selection by an oracle. "verifier@N closely matches oracle best@N."
- parallel sampling: Generating multiple independent reasoning trajectories concurrently to explore alternative hypotheses. "we introduce a simple parallel sampling with verifier framework for test-time scaling (TTS) in Thinking with Map."
- pass@1: Probability that a single sample contains a correct answer. "This approach transfers performance gains from pass@K to pass@1."
- pass@K: Probability that at least one of K samples contains a correct answer. "To further improve the model's pass@K performance and enable more effective parallel sampling"
- piecewise discrete scheme: A reward design that assigns discrete reward tiers based on distance ranges. "we simply use a piecewise discrete scheme that assigns different rewards to different distance ranges:"
- Point of Interest (POI): A named location (e.g., store, landmark) in map data used as a localization clue. "POI represents Point of Interest."
- policy model: The agent’s decision function mapping observations to actions and hypotheses. "a policy model "
- test-time scaling (TTS): Boosting performance by increasing sampling or compute at inference time. "parallel test-time scaling (TTS)"
- tool-call actions: Explicit invocations of external tools by the agent during reasoning. "tool-call actions "
- verifiable reward function: A reward computed from structured outputs that can be automatically checked for correctness. "for the verifiable reward function."
- verifier: A model that aggregates evidence from multiple trajectories and selects the most plausible answer. "a verifier aggregates the results."
- zero-shot: Evaluation without task-specific fine-tuning or training examples. "based on the zero-shot predictions of three base models"
Collections
Sign up for free to add this paper to one or more collections.