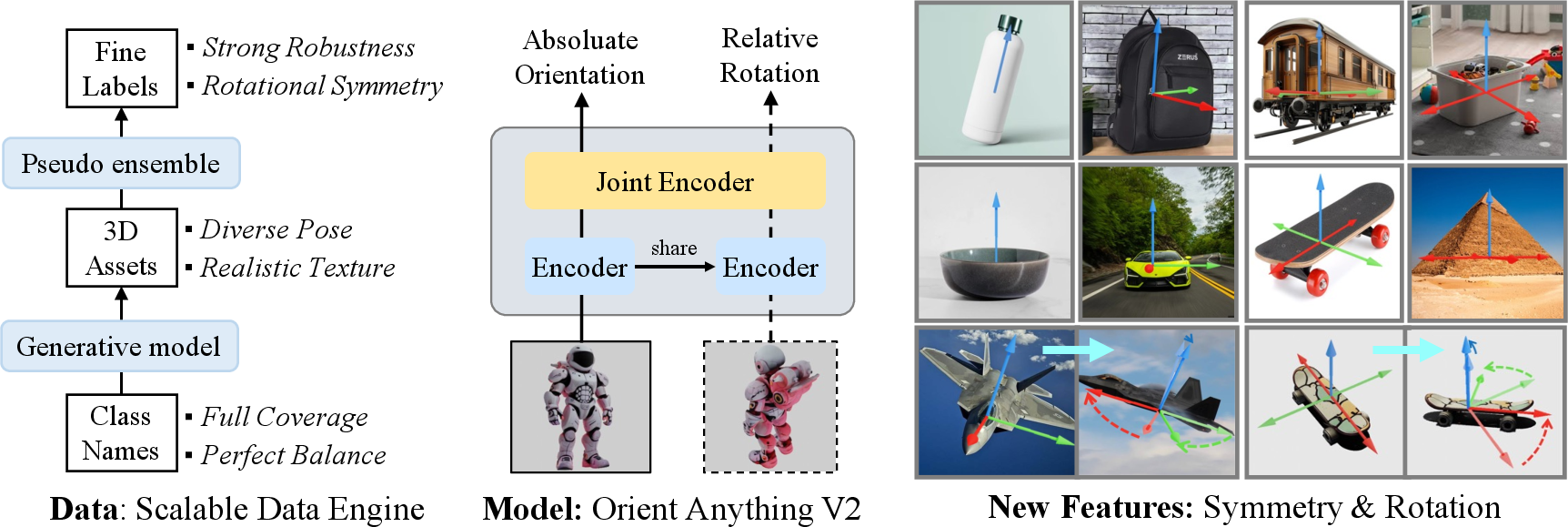
Orient Anything V2: Unifying Orientation and Rotation Understanding
Abstract: This work presents Orient Anything V2, an enhanced foundation model for unified understanding of object 3D orientation and rotation from single or paired images. Building upon Orient Anything V1, which defines orientation via a single unique front face, V2 extends this capability to handle objects with diverse rotational symmetries and directly estimate relative rotations. These improvements are enabled by four key innovations: 1) Scalable 3D assets synthesized by generative models, ensuring broad category coverage and balanced data distribution; 2) An efficient, model-in-the-loop annotation system that robustly identifies 0 to N valid front faces for each object; 3) A symmetry-aware, periodic distribution fitting objective that captures all plausible front-facing orientations, effectively modeling object rotational symmetry; 4) A multi-frame architecture that directly predicts relative object rotations. Extensive experiments show that Orient Anything V2 achieves state-of-the-art zero-shot performance on orientation estimation, 6DoF pose estimation, and object symmetry recognition across 11 widely used benchmarks. The model demonstrates strong generalization, significantly broadening the applicability of orientation estimation in diverse downstream tasks.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Orient Anything V2: Unifying Orientation and Rotation Understanding”
Overview (What is this paper about?)
This paper introduces Orient Anything V2, a smarter computer vision model that looks at pictures and works out:
- which way an object is facing (its “orientation” — think of the front of a car), and
- how much an object has turned between two pictures (its “rotation” — like comparing a “before” and “after” photo).
It also handles tricky cases where an object looks the same from several angles (like a pizza with identical slices) or from any angle (like a ball).
Key Questions (What did the researchers want to achieve?)
- Can a model tell the “front” of almost any object from a single image?
- Can it understand and predict an object’s rotation between two images?
- Can it recognize when an object has rotational symmetry (e.g., looks the same every 180° or 90°)?
- Can it do all this on new objects and scenes it hasn’t seen before (“zero-shot”)?
How They Did It (Methods in simple terms)
To make the model both smart and reliable, the team improved two big pieces: the data and the model.
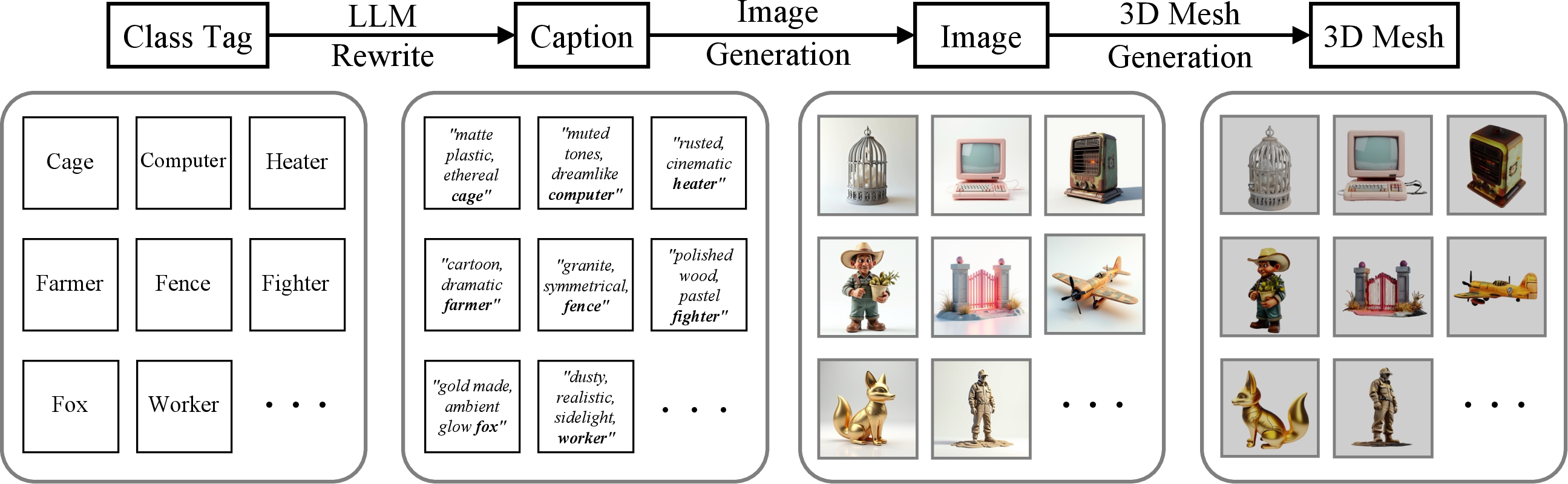
1) Building a massive, balanced 3D training set
Real 3D model collections are uneven (too many of some categories, low quality for others). So the team created a new pipeline to generate high-quality 3D objects:
- Start with a class name (like “giraffe”)
- Write a detailed description (caption) using an AI LLM
- Generate an image from that caption using an image generator
- Turn the image into a 3D model using a 3D generator
They produced about 600,000 3D assets (much larger and more balanced than before), each with detailed shapes and textures.
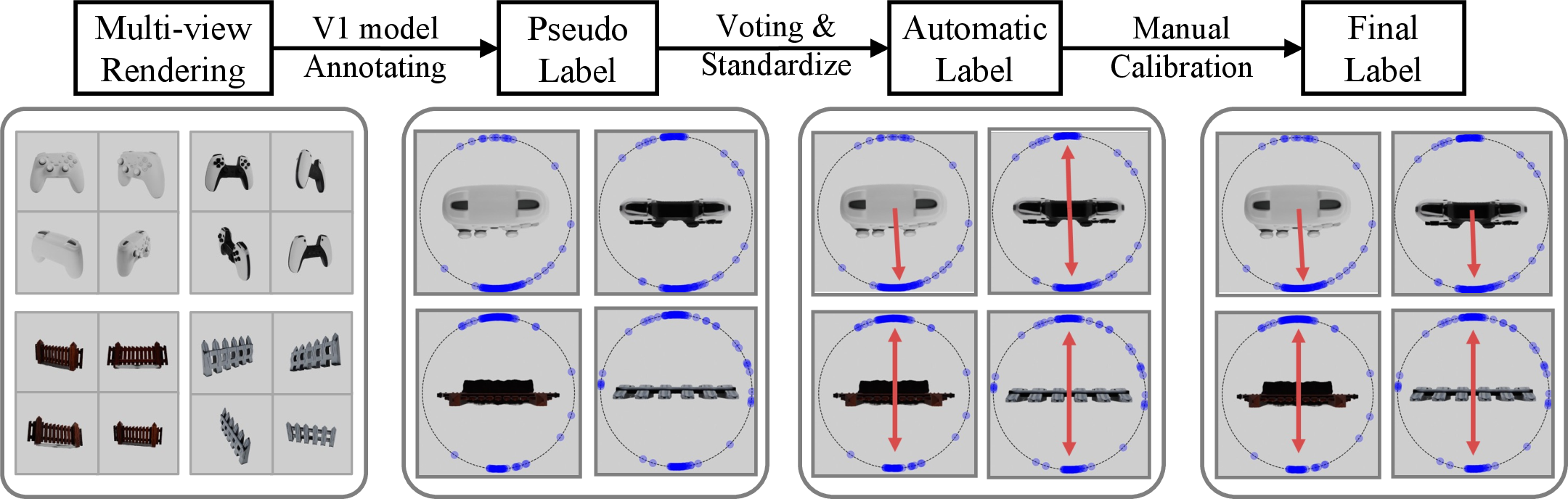
2) Smarter labels using “many views” and “model-in-the-loop”
Labeling “front” for each 3D object is hard—especially for symmetric objects. They:
- Rendered each 3D object from many angles
- Used a strong orientation model to make lots of “best guesses”
- Merged those guesses into a circle of directions (like a compass heat map) to find:
- the main facing direction(s), and
- the object’s rotational symmetry (e.g., unique front; two fronts at 180°; four fronts at 90°; or “no meaningful front” like a ball)
- Checked consistency within categories (e.g., all “mugs” should have similar symmetry) and fixed inconsistent cases with quick human reviews
This makes labels much more reliable, especially for symmetric objects with multiple valid “fronts.”
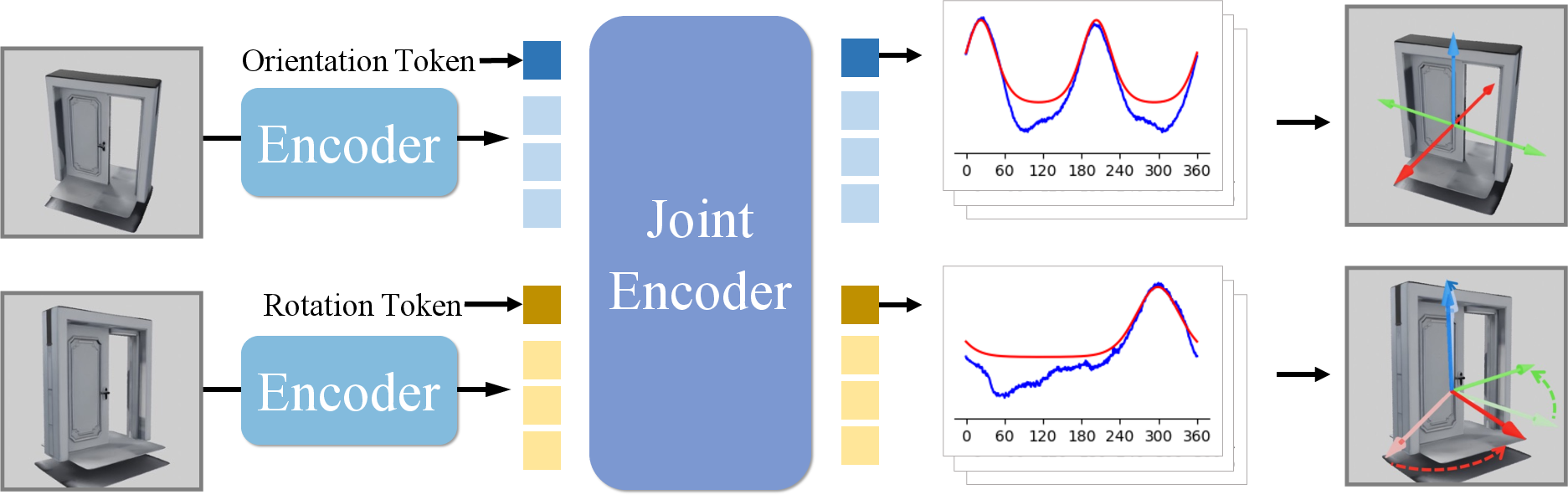
3) Teaching the model about symmetry with “circular probabilities”
Instead of predicting just one “front,” the model learns a probability ring around a circle (360°). This ring can have:
- one peak (unique front),
- several peaks (multiple valid fronts due to symmetry),
- or be flat (no front, like a sphere).
This “symmetry-aware” training helps the model naturally understand objects with 0 to N valid fronts.
4) Learning rotation between two images (multi-frame)
The model can take:
- one image to predict the absolute orientation, or
- two images to predict how much the object turned between them (relative rotation).
This avoids the usual “subtract two separate guesses” trick, which can stack errors. Instead, it learns the relative turn directly, making it more accurate—especially when the views are very different.
Main Results (What did they find?)
- Better single-image orientation: More accurate at telling which way objects are facing, across many real-world datasets.
- Strong rotation between two images: Beats previous methods at estimating how much an object turned—especially when the two views differ a lot (big rotations). Earlier methods rely on matching tiny image details, which breaks when viewpoints change a lot; this model understands the overall object instead.
- Recognizes rotational symmetry: More accurate than big vision-LLMs at telling if an object has 1, 2, 4, or infinite valid “fronts.”
- Generalizes well (“zero-shot”): Works on objects and scenes it wasn’t specifically trained on.
In short: it sets state-of-the-art results on several benchmarks for orientation, rotation (pose), and symmetry.
Why This Matters (Impact and uses)
- Robots can better grasp and move objects by understanding where the “front” is and how much the object has turned.
- AR/VR and games can place and rotate virtual objects more accurately.
- Self-driving and drones can better understand object directions in scenes.
- Image generation and editing tools can keep objects’ directions consistent.
By handling symmetrical objects and learning rotation directly from image pairs, Orient Anything V2 is more flexible and dependable for real-world applications.
A quick note on limitations
- If the image doesn’t show much (e.g., the object is heavily blocked or far away), the model can still struggle—because one picture alone can be ambiguous.
- It currently handles up to two images at a time; supporting longer sequences (like videos) is a future step.
Takeaway
Orient Anything V2 is like giving computers a strong “sense of direction” for objects: it knows where the front is, how many fronts there might be, and how much an object has turned—working even on new objects it hasn’t seen before. This makes many vision tasks more reliable and realistic.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of the paper’s unresolved issues to guide future research.
- Synthetic data realism and domain gap: No quantitative validation that assets generated via Class Tag → Caption → Image → 3D Mesh match real-world appearance, geometry completeness, and material properties; require metrics and controlled studies to quantify how synthetic vs. real assets affect orientation/rotation performance.
- Biases from ImageNet-21K tag-driven generation: Coverage of long-tail object types, attribute diversity, and pose variation is unmeasured; need analyses of category imbalance, semantic drift in captions, and their impact on generalization.
- Single-object synthetic setups vs. real multi-object scenes: The pipeline and evaluations largely assume isolated objects with clean crops; end-to-end performance in cluttered, multi-object scenes with automatic detection/segmentation and background confounders is not assessed.
- Pseudo-label ensemble reliability: Symmetry/orientation labels derived from V1 predictions are not benchmarked against human ground truth; quantify label noise, uncertainty, and bias propagation from the annotator to V2.
- Category-level symmetry assumption: Inter-asset consistency calibration assumes all assets in a category share the same rotational symmetry; this is often false (e.g., chairs, lamps); measure mislabel rates and develop instance-level calibration without collapsing valid intra-category diversity.
- Rotational symmetry restriction: Training limits symmetries to {0,1,2,4}, mapping α>4 to 0, leaving 3-, 5-, 6-, 8-fold symmetries unmodeled; extend to arbitrary discrete n-fold and continuous cylindrical symmetries with appropriate targets and metrics.
- Azimuth-only symmetry modeling: Symmetries are defined around the vertical axis; objects with symmetry around non-vertical or intrinsic principal axes are unsupported; require methods to infer object-centric axes and gravity/vertical direction from images.
- Equal-peak periodic distribution: The cos(α(i−φ)) target enforces equal peak heights; cannot represent near-symmetry or unequal plausibility of multiple valid front faces; investigate mixture-of-von-Mises with learnable peak weights and anisotropic peak widths.
- Fixed dispersion in training: σ is treated as a global hyper-parameter for targets, ignoring per-instance ambiguity; learn per-instance dispersion and calibrate predictive uncertainty for downstream decision-making.
- Unimodal polar and roll targets: Potential elevation or in-plane symmetries (e.g., circular plates, propellers) are not modeled; extend periodicity to polar and in-plane rotation where applicable.
- Decoding robustness: Least-squares fitting for parameter extraction is sensitive to multimodal/noisy distributions; compare maximum likelihood, Bayesian decoding, or robust estimators and analyze failure modes.
- Rotation-only relative pose: The multi-frame module predicts relative rotation but not translation/scale; evaluate full 6DoF (R, t), scale, and camera intrinsics, and their coupling with orientation understanding.
- Two-frame limitation: Architecture supports at most two frames; extend to N-frame inputs and videos with temporal consistency, rotation tracking, and memory, including occlusion-aware fusion.
- Occlusion and low-information views: Failure cases under heavy occlusion or minimal visual cues are acknowledged but not addressed; develop uncertainty-aware outputs, occlusion reasoning, and active viewpoint selection.
- Symmetry-aware evaluation gaps: Orientation benchmarks provide single ground truth even for symmetric objects; design datasets and metrics that encode symmetry equivalence classes and evaluate multi-orientation predictions fairly.
- Sensitivity to cropping/segmentation: Rotation benchmarks rely on external cropping; quantify sensitivity to bounding box/segmentation errors and assess end-to-end performance with automatic detection/segmentation.
- Upright assumption and gravity: Synthetic data enforces upright pose via caption engineering; robustness to tilted objects and unknown gravity direction in real scenes is untested; devise gravity estimation or coordinate-free orientation definitions.
- Articulated/deformable objects: Front-face semantics and symmetry can change with articulation; model pose-dependent orientation/symmetry and evaluate on articulated categories.
- Task-conditioned “front” semantics: “Front” is culturally and task-dependent; formalize task-conditioned orientation definitions and adaptation mechanisms to downstream tasks (e.g., manipulation vs. recognition).
- Architectural ablations and efficiency: No ablation of tokenization (K), learnable tokens, transformer depth, or pretraining choices; study design trade-offs, parameter efficiency, latency, and memory for deployment.
- Angle discretization resolution: Discretizing angles into 360/180 bins may cap precision; analyze bin-size effects and explore continuous-angle regressors or hybrid discrete–continuous objectives.
- Confidence and abstention: Removing explicit orientation confidence in favor of symmetry-aware distributions leaves uncertainty calibration unclear; add calibrated confidence/abstention for ambiguous cases.
- Mesh quality assurance: Geometry completeness (e.g., watertightness), topology errors, and alignment between generated images and reconstructed meshes are not quantified; propose automatic quality checks and filtering.
- Bootstrapping bias analysis: The annotator (improved V1) may imprint its biases; compare against human-labeled subsets and alternative annotators, and measure bias transfer to V2 outputs.
- Stress-testing generalization: Robustness to adversarial textures, confusing backgrounds, extreme lighting, motion blur, and domain shifts (industrial, medical, aerial) remains unexplored; perform targeted stress tests.
- Reproducibility and licensing: Dataset/code release details, annotation schema, and licensing for generated assets are unclear; provide open artifacts, protocols, and usage constraints to enable replication and extension.
Practical Applications
Overview
Below are actionable applications that leverage the findings, methods, and innovations of Orient Anything V2 (OAV2)—notably its symmetry-aware orientation distributions, multi-frame relative rotation prediction, scalable synthetic 3D data engine, and robust ensemble annotation. Each item notes target sectors, possible tools/products/workflows, and assumptions or dependencies that affect feasibility.
Immediate Applications
These can be deployed now with modest integration effort.
- Zero-shot pick-and-place for novel objects in warehouses and factories (Robotics)
- What: Use single-view orientation predictions and symmetry-aware distributions to select grasp approach angles and avoid ambiguous faces on symmetric parts.
- Tools/workflows: ROS node + MoveIt plugin; integration with object detectors/segmenters; “two-view” capture for higher confidence via relative rotation.
- Assumptions/dependencies: Accurate object crops; camera calibration; performance may degrade under severe occlusion; current symmetry types modeled as {0,1,2,4}.
- Bin picking and robotic insertion of symmetric parts (Manufacturing)
- What: Recognize multiple valid “fronts” (e.g., bolts, gears) and plan equivalent insert orientations; reject cases with continuous symmetry where orientation is meaningless.
- Tools/workflows: OAV2 API + PLC bridge; vision-guided insertion pipelines.
- Assumptions/dependencies: Reliable lighting; stable backgrounds; minimal occlusion; training data domain match.
- Product image normalization and 3D viewer alignment (E-commerce, Software)
- What: Auto-rotate product photos to canonical “front”; choose default camera angles for 3D viewers; detect rotational symmetry to decide whether to expose orientation controls to users.
- Tools/workflows: Web microservice; Photoshop/Figma/Blender plugin; CMS batch pipeline.
- Assumptions/dependencies: High-resolution imagery; consistent product framing; downstream tooling supports orientation metadata.
- AR furniture placement and alignment (AR/VR, Consumer)
- What: Single-view orientation to “snap” furniture to walls/axes; use two-frame relative rotation for more precise placement across viewpoints.
- Tools/workflows: Mobile AR SDK (Unity/Unreal) with OAV2; on-device inference or cloud call.
- Assumptions/dependencies: Device camera calibration; acceptable latency; sufficient texture/features in scenes.
- Scene understanding enrichment for autonomous driving perception stacks (Automotive)
- What: Estimate orientations of vehicles, bicycles, traffic cones/signs from monocular frames to improve behavior prediction and map alignment.
- Tools/workflows: Perception fusion node; post-detector orientation head; data augmentation with synthetic assets.
- Assumptions/dependencies: Domain-specific tuning; robust cropping; dynamic scenes with occlusion pose challenges.
- Relative rotation estimation for object tracking across frames (Vision software, VFX)
- What: Stabilize object-centric shots, match 3D inserts to rotating props, and reduce reliance on brittle feature matching under large viewpoint changes.
- Tools/workflows: Nuke/After Effects plugin; Python SDK for shot-to-shot orientation continuity.
- Assumptions/dependencies: Paired frames availability; frame-to-object association; large rotations supported but full 6DoF translation not included.
- QC and assembly verification via orientation checks (Manufacturing, Quality control)
- What: Confirm that components are oriented correctly before fastening/welding; flag mismatches versus canonical front.
- Tools/workflows: Station camera + OAV2 service; MES integration for pass/fail metrics.
- Assumptions/dependencies: Consistent imaging setup; canonical reference orientation defined per part.
- Drone and infrastructure inspection with orientation cues (Energy, Civil)
- What: Assess blade/panel orientation, detect misalignment across views using two-frame rotation prediction in windy or dynamic conditions.
- Tools/workflows: UAV payload app; cloud analytics for relative rotation comparisons.
- Assumptions/dependencies: Motion blur and distance can reduce accuracy; requires reliable object detection and tracking.
- 3D content creation aid: auto-tagging front faces and symmetry (Software, Media)
- What: Annotate 3D assets with front-facing directions and rotational symmetry for better asset libraries, auto-rigging, and snapping in DCC tools.
- Tools/workflows: Blender/Maya add-on; asset library indexer; pipeline hooks for game engines.
- Assumptions/dependencies: Consistent mesh-to-image render pipeline; alignment between 2D thumbnails and 3D canonical views.
- Synthetic 3D data augmentation for orientation tasks (Academia, ML Ops)
- What: Replicate the Class Tag → Caption → Image → 3D Mesh pipeline to balance category coverage and enrich training corpora.
- Tools/workflows: Captioning (Qwen-2.5), FLUX.1-Dev image generation, Hunyuan-3D-2.0 mesh generation; periodic distribution fitting for labels.
- Assumptions/dependencies: Compute budget for large-scale synthesis; quality control via ensemble annotation and category-consistency calibration.
- Educational and STEM demonstrations of symmetry and orientation (Education)
- What: Interactive demos that classify rotational symmetry types and show valid front faces from a single image; teach spatial reasoning concepts.
- Tools/workflows: Web app with OAV2; classroom AR activities.
- Assumptions/dependencies: Properly curated examples; explainability/UI to visualize distributions.
- Privacy-compliant data curation using synthetic assets (Policy, Data governance)
- What: Replace or complement real data with synthetic 3D assets to reduce IP/privacy risks while maintaining balanced coverage and high-quality textures.
- Tools/workflows: Synthetic data pipelines; audit dashboards for class balance and label consistency.
- Assumptions/dependencies: Synthetic-to-real domain gap must be assessed; governance around generative models’ provenance.
Long-Term Applications
These require further research, scale-up, domain adaptation, or extensions (e.g., >2 frames), and potential regulatory approvals.
- Open-world 6DoF manipulation without CAD models (Robotics)
- What: Combine OAV2’s relative rotation with object localization and contact modeling to achieve generalized grasping/insertion of unseen objects.
- Tools/workflows: Multi-sensor fusion (RGB-D/tactile); policy learning that uses symmetry cues for robust planning.
- Assumptions/dependencies: Extension to more frames/video; integration with force/torque sensing; safety and reliability testing.
- Full video-based orientation/pose tracking and scene graphs (Software, AR/VR, Robotics)
- What: Extend beyond two frames to track objects’ orientation continuously; build scene-level orientation graphs for interaction and planning.
- Tools/workflows: Temporal transformer; SLAM integration; streaming inference.
- Assumptions/dependencies: OAV2 architecture currently supports two frames; research needed for scalable multi-frame training.
- Autonomy stacks for dynamic urban environments with robust orientation priors (Automotive)
- What: Use persistent orientation signals to improve prediction of intent (e.g., cyclist facing direction), multi-object coordination, and map alignment.
- Tools/workflows: End-to-end perception-planning coupling; cross-modal fusion (LiDAR/Radar + OAV2).
- Assumptions/dependencies: Domain adaptation; thorough validation under corner cases and occlusions.
- Surgical and teleoperation orientation assistance (Healthcare)
- What: Aid surgeons and teleoperators with tool orientation awareness during minimally invasive procedures; reduce errors with symmetry-aware cues.
- Tools/workflows: OR camera feeds; haptic feedback mapping; AR overlays.
- Assumptions/dependencies: Domain-specific training; latency constraints; regulatory approvals (FDA/CE).
- Smart manufacturing digital twins with orientation-aware twins (Industry 4.0)
- What: Synchronize real-time orientation states of assets into digital twins for monitoring, simulation, and predictive maintenance.
- Tools/workflows: Edge camera networks; MES/PLM integration; orientation anomaly detection.
- Assumptions/dependencies: Reliable tracking across time; scaling to many objects; occlusion handling.
- Energy sector monitoring of rotating machinery (Energy)
- What: Model turbine blade orientations over time, detect misalignments after maintenance, and quantify rotation under load for safety.
- Tools/workflows: Multi-view capture; predictive analytics integrating OAV2 rotation with vibration/SCADA signals.
- Assumptions/dependencies: Harsh environment imaging; robust detection of known components.
- Standards for rotational symmetry labeling and orientation metadata (Policy, Standards)
- What: Establish common schemas for encoding orientation distributions and symmetry classes in datasets and asset libraries.
- Tools/workflows: Working groups with industry/academia; conformance tests.
- Assumptions/dependencies: Broad stakeholder buy-in; versioning and provenance tracking.
- Improving 3D generative models via symmetry-aware training targets (Research, Software)
- What: Use symmetry labels and orientation distributions to regularize 3D generation, reduce artifacts, and ensure canonical fronts.
- Tools/workflows: Joint training pipelines; differentiable rendering for feedback loops.
- Assumptions/dependencies: Access to model internals; compute scale; robust label quality.
- Forensic analysis and tamper detection using orientation inconsistencies (Security)
- What: Detect mismatched object orientations across frames (e.g., in deepfake or composited media) as a cue for manipulation.
- Tools/workflows: Media forensics suite; orientation-consistency scoring.
- Assumptions/dependencies: High-quality video frames; scene constraints; adversarial robustness.
- Human-robot interaction with explicit symmetry-aware affordances (Robotics, HRI)
- What: Design interfaces that communicate which orientations are equivalent for symmetric objects, reducing operator confusion and task time.
- Tools/workflows: AR affordance overlays; teach-and-repeat with symmetry-informed paths.
- Assumptions/dependencies: Usability studies; standardized affordance visuals; multi-frame temporal coherence.
Cross-cutting assumptions and dependencies
- Domain shift: Synthetic-to-real generalization is strong but not guaranteed for highly specialized domains; domain adaptation may be needed.
- Occlusion and low-information views: Performance drops when texture/structure is limited; multi-view capture improves robustness.
- Frame limits: Current architecture supports up to two frames; video-scale applications need architectural extension.
- Symmetry coverage: Training restricts periodicity to {0,1,2,4}; rare higher-order symmetries may need custom handling.
- Pre-requisites: Reliable detection/segmentation, accurate cropping, and camera calibration often required.
- Latency and compute: Real-time applications may need edge inference or model distillation/quantization.
- Governance: Synthetic pipelines require provenance tracking, auditing for balance, and compliance with IP/privacy policies.
Glossary
- 2D-3D correspondences: Matching image features to 3D points across views to infer pose. "estimate object rotation by solving 2D-3D correspondences across views."
- 6DoF pose estimation: Estimating full 3D pose with three rotations and three translations. "Extensive experiments show that Orient Anything V2 achieves state-of-the-art zero-shot performance on orientation estimation, 6DoF pose estimation, and object symmetry recognition across 11 widely used benchmarks."
- Absolute orientation estimation: Predicting an object’s orientation relative to a fixed canonical frame. "While it exhibits strong robustness and accuracy in absolute orientation estimation, it lacks an understanding of rotation (despite its intrinsic link to orientation)."
- Azimuth: The angle of rotation around the vertical axis (yaw). "we first arrange the discrete predicted azimuth angles over [0°, 360°) into a probability distribution"
- Azimuthal symmetry: Rotational symmetry around the vertical axis, determining multiple valid front orientations. "we enable the prediction of an object's azimuthal symmetry from a single 2D image."
- Binary Cross-Entropy (BCE) loss: A loss function for binary targets, used here to fit predicted angle distributions. "We train the model to fit target orientation (or rotation) distributions using Binary Cross-Entropy (BCE) loss for 20k iterations."
- Camera extrinsics: Parameters describing the camera’s position and orientation in the world. "We repurpose its original 'camera' token, designed to predict camera extrinsics, to predict object orientation and rotation."
- Canonical front view: The standard, reference viewing direction that defines an object’s front. "Orient Anything V1 employs VLM to annotate the unique canonical front view of 3D assets."
- Cosine learning rate scheduler: A training schedule where the learning rate follows a cosine decay. "A cosine learning rate scheduler is used with an initial rate of 1e-3."
- DINOv2: A pre-trained vision transformer used as the visual encoder. "first using a visual encoder, DINOv2~\cite{oquab2023dinov2}, to encode each input image into tokens, augmented with learnable tokens."
- Ensembling: Combining multiple predictions to reduce errors and improve robustness. "Ensembling multiple pseudo labels in the 3D world effectively suppresses outlier errors from single-view predictions, resulting in significantly more reliable annotations."
- Human-in-the-loop: Incorporating human review to improve annotation quality and consistency. "we further perform human-in-the-loop consistency calibration across assets."
- In-plane rotation: Rotation around the camera’s optical axis within the image plane (roll). "learn circular Gaussian distributions over azimuth, polar, and in-plane rotation angles"
- Least squares method: An optimization technique minimizing squared errors, used to fit distributions. "This distribution is then fitted to a periodic Gaussian distribution using the least squares method:"
- Learnable token: A trainable embedding representing frame-specific information in a transformer. "The final learnable token corresponding to each frame is used for prediction."
- Model-in-the-loop: Using a model to generate or refine labels iteratively within the annotation process. "refine them through model-in-the-loop calibration."
- Multi-frame architecture: A network design that processes multiple input images jointly to predict relative rotations. "A multi-frame architecture that directly predicts relative object rotations."
- Orientation confidence: A score indicating whether an object has a unique front-facing orientation. "the model additionally predicts a low orientation confidence to filter them out."
- Orientation distribution fitting: Learning to predict probability distributions over orientation angles rather than single values. "proposes an orientation distribution fitting task that guides the model to learn circular Gaussian distributions over azimuth, polar, and in-plane rotation angles"
- Periodic Gaussian distribution: A circular probability distribution over angles used to model symmetries. "This distribution is then fitted to a periodic Gaussian distribution using the least squares method:"
- Periodicity (α): A parameter indicating rotational symmetry frequency; α valid front faces imply 360/α-degree symmetry. "The periodicity signifies -degree rotational symmetry"
- Polar angle: The elevation angle relative to the vertical axis (pitch). "Target probability distributions for the polar angle "
- Relative rotation: The rotation of an object between two views or frames. "However, estimating relative rotation through independent absolute orientation predictions suffers from significant error accumulation"
- Rotational symmetry: Invariance of an object’s appearance under rotation by specific angles. "Rotational symmetry indicates that an object may retain its original shape after being rotated by certain angles."
- SAM (Segment Anything Model): A segmentation model used to help pose estimation. "POPE~\cite{fan2024pope} follows a similar idea and achieves zero-shot rotation estimation with a single reference frame with the help of SAM~\cite{kirillov2023segment} and DINOv2~\cite{oquab2023dinov2}."
- Transformer block: A neural network module that processes token sequences via attention mechanisms. "The combined set of tokens from all frames is then passed into a unified transformer block."
- VGGT: A large feed-forward transformer pre-trained on 3D geometry tasks used for initialization. "Our model is initialized from VGGT, a large feed-forward transformer with 1.2 billion parameters pre-trained on 3D geometry tasks."
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs for tasks like annotation. "Orient Anything V1 employs VLM to annotate the unique canonical front view of 3D assets."
- Zero-shot: Evaluating performance on tasks or datasets without task-specific training data. "It achieves superior performance on zero-shot orientation estimation and sets new records on zero-shot rotation estimation"
Collections
Sign up for free to add this paper to one or more collections.