PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
Abstract: We introduce Parallel Coordinated Reasoning (PaCoRe), a training-and-inference framework designed to overcome a central limitation of contemporary LLMs: their inability to scale test-time compute (TTC) far beyond sequential reasoning under a fixed context window. PaCoRe departs from the traditional sequential paradigm by driving TTC through massive parallel exploration coordinated via a message-passing architecture in multiple rounds. Each round launches many parallel reasoning trajectories, compacts their findings into context-bounded messages, and synthesizes these messages to guide the next round and ultimately produce the final answer. Trained end-to-end with large-scale, outcome-based reinforcement learning, the model masters the synthesis abilities required by PaCoRe and scales to multi-million-token effective TTC without exceeding context limits. The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5's 93.2% by scaling effective TTC to roughly two million tokens. We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning”
What is this paper about?
This paper introduces a new way for AI LLMs to “think” more effectively on tough problems without running into their usual memory limits. The method is called PaCoRe, short for Parallel Coordinated Reasoning. It lets a model do a lot more work per question by splitting the thinking into many parallel attempts, summarizing what they found, and then coordinating the next steps—over several rounds—until it reaches a final answer.
In short: PaCoRe helps AI use much more brainpower on a single problem, even though the model’s memory (context window) is limited.
What questions are the researchers trying to answer?
To make this easy to follow, here are the key goals in plain language:
- Can we make AI think harder on one question by trying many ideas at once, and then combining them smartly?
- Can we avoid the model’s memory limit by passing only short summaries between rounds of thinking?
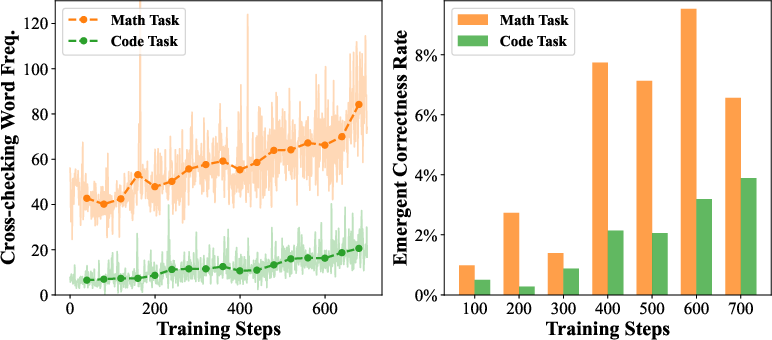
- Can we train the AI to actually use those summaries well—comparing, cross-checking, and combining them—instead of just ignoring them?
- If we do this, will the AI perform better on hard tasks like advanced math and coding?
How does PaCoRe work?
Think of a group project where:
- Many classmates try different approaches to the same problem at the same time.
- Each classmate writes a short sticky-note summary with just their final conclusion.
- The team reads those short notes, learns from them, and launches a new round of attempts that are better informed.
- After a few rounds, the team writes a final, well-reasoned answer.
PaCoRe does the same thing with an AI model:
- Parallel attempts: The model creates many independent solution attempts at once.
- Message compaction: Instead of keeping all the long reasoning, it keeps only the final conclusions from each attempt as short “messages.” This keeps the information small enough to fit into the model’s memory next round.
- Coordination: In the next round, the model reads the short messages plus the original question, compares them, and launches new, improved attempts.
- Final answer: In the last round, it produces a single final solution.
Why this matters: A model’s memory (the “context window”) is limited, so it can’t hold a huge, never-ending chain of thoughts. PaCoRe sidesteps this by keeping only short summaries between rounds. Even though the AI may generate millions of tokens across all attempts, each round only passes along brief notes—so it fits.
Training the model to do this well:
- The authors use reinforcement learning (RL), which is like training by trial and error with rewards. The model tries to solve problems, gets rewarded when it ends up correct, and learns to pay attention to the helpful summaries and combine them wisely.
- They also avoid easy cases where “majority voting” would work (just picking the most common answer). This forces the model to practice real synthesis: checking conflicts, fixing mistakes, and building better answers from imperfect hints.
What did they find, and why is it important?
Here are the main results and why they matter:
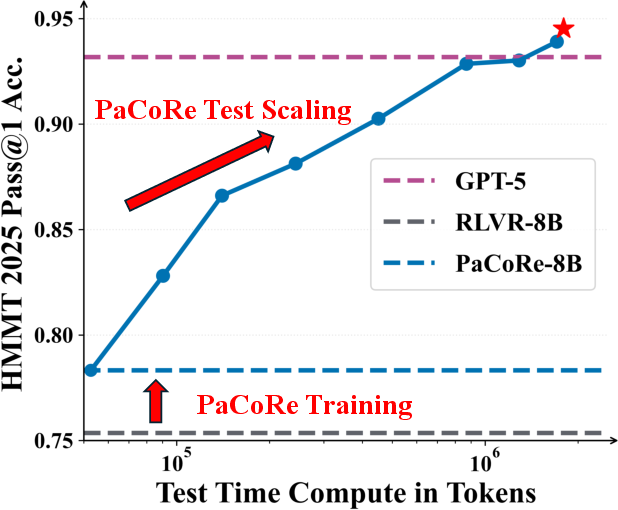
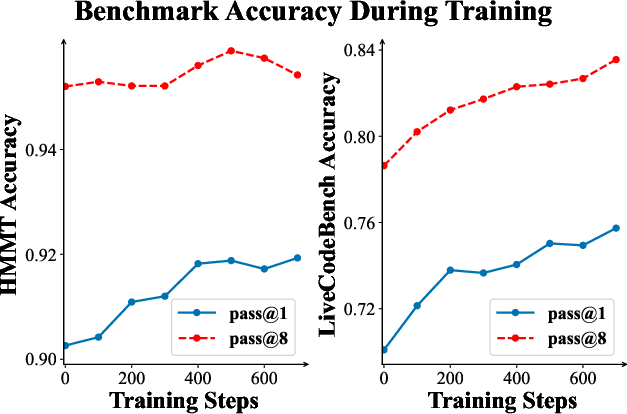
- Much better performance on hard math: Their 8B-parameter model (PaCoRe-8B) scored 94.5% on HMMT 2025, beating a top system (they report GPT-5 at 93.2%). This shows that smart coordination can beat just scaling a model’s size or doing simple voting.
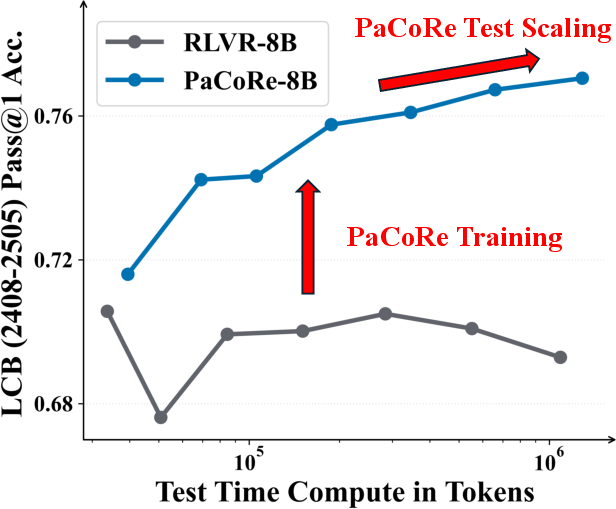
- Real test-time scaling: As they increased the number of parallel attempts and rounds, performance kept improving—because the model learned to use more “thinking time” effectively.
- Works beyond math: The approach also improved results on coding (LiveCodeBench) and carried over to software engineering and multi-turn conversation tests. This suggests the method is general, not just a math trick.
- Key design wins:
- Parallel is better than pure sequential thinking: Trying many ideas at once and coordinating them was more effective than just making one long chain of thought.
- Message passing (the short summaries) is essential: Without compact summaries, performance hit the model’s memory limit and stopped improving.
- Better than majority voting: Standard voting over many answers quickly hit a ceiling. PaCoRe kept getting better because it truly synthesizes information.
They also open-sourced their model, data, and code, which helps others build on this work.
What is the impact of this research?
- Solving harder problems: By coordinating many ideas across rounds, PaCoRe helps smaller models perform like (or better than) much larger systems on complex tasks.
- Smarter use of compute: Instead of stuffing all thinking into one long chain that runs out of memory, PaCoRe spreads thinking across many short, coordinated attempts.
- Foundations for multi-agent intelligence: The system looks a bit like a team of agents cooperating. This could lead to future AI that organizes tasks, divides work, and communicates more effectively.
- Broad applications: From math contests to coding challenges to software engineering, this approach could boost AI on any task where careful reasoning matters.
The bottom line
PaCoRe is like turning a single thinker into a well-organized team: many attempts in parallel, short notes passed between rounds, and a final decision that’s better than any one attempt. With reinforcement learning, the model learns to actually use those notes—to cross-check, correct, and combine ideas. This lets AI spend much more “thinking time” on a problem without hitting its memory ceiling, leading to strong gains on difficult tasks and pointing to a promising direction for future AI reasoning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains uncertain or unexplored in the paper and where targeted research could close the gaps.
- Message compaction discards all intermediate reasoning, keeping only “final conclusions”; quantify how much useful signal is lost and evaluate learned compaction schemes (e.g., structured summaries, key steps, uncertainty tags) under strict context budgets.
- Introduce and assess confidence/uncertainty in compact messages (calibration, per-message scores, provenance) to enable weighted synthesis and robustness to misleading messages.
- The same model weights are used for all rounds and roles; study specialized policies (exploration vs synthesis), role-based mixtures-of-experts, or co-training multiple agents for division of labor.
- Rounds are effectively limited (e.g., [32, 4]); perform systematic scaling beyond two rounds, derive convergence/stopping rules, and characterize diminishing returns and error propagation across rounds.
- The claim of “unbounded” scaling is empirical; formally model how context saturates as the number and length of messages grow, and design adaptive message-length control (e.g., learned bottlenecks, truncation policies).
- Quantify end-to-end efficiency: wall-clock latency, throughput, memory footprint, GPU-hours, and energy for different K/R configurations and hardware; compare TTC vs accuracy trade-offs, not just token counts.
- Evaluation uses first-round cached trajectories; rigorously verify equivalence to on-the-fly generation across tasks, quantify deviations, and identify cases where caching biases results.
- Expand baselines beyond Self-Consistency to include strong, general aggregators (e.g., AggLM, Mixture-of-Agents, LLM-as-aggregator, learned rankers) under matched TTC and context limits.
- Stress-test robustness to adversarial/noisy message sets (e.g., targeted poisoning, duplicated spurious answers, conflicting high-confidence errors) and develop defenses (confidence gating, diversity filters).
- Develop synthesis strategies that can identify and ignore highly confident but wrong messages; evaluate failure modes under correlated errors.
- Code-specific compaction: test whether compacting to program outputs or short signatures harms synthesis; explore compact test coverage summaries or unit-level results as messages.
- Math-specific compaction: explore structured messages (key lemmas, invariant checks, candidate answer sets) and measure their effect on synthesis quality under equal context budgets.
- Sensitivity to sampling hyperparameters (temperature, top-p, nucleus constraints) during trajectory generation is not analyzed; map their impact on synthesis reliability and diversity.
- Training is restricted to verifiable rewards (math/code); design and evaluate reward schemes for non-verifiable tasks (open-ended writing, QA without ground truth, multimodal) and study transfer.
- The curriculum filters out high-accuracy message sets; quantify selection bias and its effect on generalization, and ablate different curriculum thresholds.
- Report run-to-run variance (seeds) and confidence intervals; assess stability and reproducibility of gains across training/evaluation replicates.
- Training compute (GPU-hours, FLOPs) and cost-efficiency are omitted; provide budgets to enable reproducibility on modest hardware and relate training investment to inference gains.
- Credit assignment across parallel trajectories is implicit; investigate multi-agent RL that attaches per-message rewards, counterfactual credit, or Shapley-like contributions to improve synthesis learning.
- Compaction is a deterministic parser; prototype trainable compressors (autoencoders, bottleneck transformers) and compare their effectiveness and stability against deterministic extraction.
- Joint training of exploration and synthesis policies is not evaluated; study two-stage vs end-to-end training and the potential for co-evolution of exploration diversity and synthesis accuracy.
- Certain tasks (proofs, long-form reasoning, dialogues) may not compact into single “final conclusions”; design hierarchical or multi-field messages and test on proof-heavy or multi-turn tasks.
- Safety/alignment is not addressed; analyze emergent multi-agent behaviors (collusion, echo chambers), failure cascades, and propose alignment controls (debiasing, adversarial training, oversight messages).
- Domain breadth is limited (math/code primary); evaluate on science, law, medicine, multilingual tasks, and multimodal inputs (vision, audio), including domain-specific compaction strategies.
- External baseline comparability (e.g., GPT-5) lacks methodological detail; document prompts, seeds, API configurations, and evaluation protocols to ensure fair, reproducible comparisons.
- Effective TTC is reported in tokens; relate TTC to FLOPs, latency, and cost across models to allow apples-to-apples efficiency comparisons and budget-aware deployment decisions.
- Adaptive allocation of K and R is not studied; design schedulers that dynamically allocate trajectories/rounds based on intermediate signals (confidence, disagreement, progress).
- RLVR decontamination and leakage checks for the 500k prompts are not detailed; quantify potential contamination and its impact on benchmarks used for evaluation.
- Message-set sizes beyond ~32 first-round trajectories are unexplored; characterize performance, synthesis saturation, and memory/latency implications at much larger parallel widths.
- Per-message metadata (source trajectory id, rationale length, diversity scores) are not leveraged; evaluate whether such metadata improves synthesis decisions.
- Explore hybrid schemes that combine deeper sequential search with wide parallel exploration; build models to optimize the depth/width schedule for a fixed compute budget.
- Formal analysis is absent; derive probabilistic guarantees for when synthesis improves over base trajectories (e.g., under error rates, correlation structures, and message diversity).
Glossary
- Agentless: A framework for running LLM-based software engineering workflows without external agents or tool orchestration. "both under Agentless framework."
- Agentic tasks: Tasks that require autonomous, multi-step decision-making by an AI agent. "extending the application to agentic tasks and multi-modal understanding"
- AIME 2025: A short-answer mathematics benchmark derived from the American Invitational Mathematics Examination (2025 edition). "We report pass@1 accuracy for all approaches based on average performance of multiple independent generations per problem: 64 for AIME 2025, HMMT 2025, and APEX;"
- Apex: An extremely challenging reasoning benchmark used to stress-test advanced models. "A standout result is observed on the extremely challenging Apex benchmark: while the RLVR-8B fails to answer any questions correctly (0.0%), PaCoRe-8B achieves 2.3% in the High setting."
- Attention temperature: A parameter controlling the sharpness of attention distributions during inference. "We apply YaRN (scale 2.0) without modifying attention temperature."
- Chain-of-thought: A prompting and decoding strategy that elicits explicit, step-by-step reasoning traces before the final answer. "Reasoning models typically produce detailed intermediate derivations (e.g., chain-of-thought or "reasoning content") followed by a final conclusion."
- Context window: The maximum number of tokens an LLM can condition on for a single input, limiting how much intermediate reasoning can be included. "a fixed context window places a hard ceiling on how much such search-driven TTC can be expressed"
- Coordinated rounds: Iterative stages of parallel exploration and synthesis used in PaCoRe to progressively refine solutions. "increasing both parallel trajectories and coordinated rounds, yielding steady gains and ultimately surpassing GPT-5."
- Cosine learning rate scheduler: A schedule that anneals the learning rate following a cosine curve, often with an initial warmup. "We employ a cosine learning rate scheduler with a 200-step warmup phase, where the learning rate peaks at and anneals to a final value of ."
- Effective TTC: The aggregate test-time compute (e.g., total tokens across trajectories) realized via parallel expansion beyond the input’s context limit. "scales to multi-million-token effective TTC without exceeding context limits."
- Emergent Correctness Rate: The probability that the model produces a correct solution even when all input messages are incorrect. "Right: The Emergent Correctness Rate tracks the probability of generating a correct solution given input messages that are all incorrect, averaged over 100-step intervals."
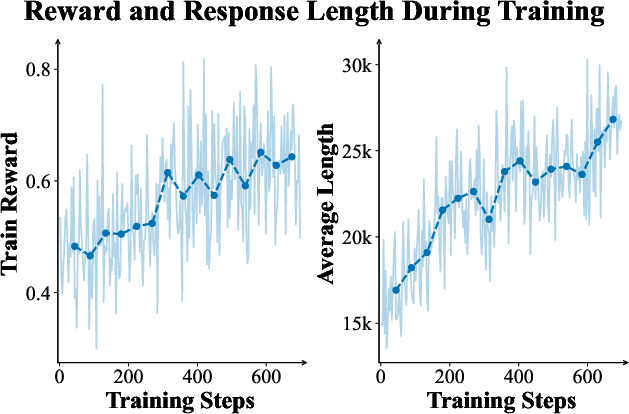
- Entropy loss: A regularization term in RL that promotes exploration by encouraging higher policy entropy; sometimes omitted to stabilize training. "We omit KL divergence constraints (both as reward penalties and loss terms) and entropy loss during training."
- Generalized Advantage Estimation (GAE): A variance-reducing technique for estimating advantages in policy gradient RL using exponentially weighted temporal differences. "strict on-policy PPO with GAE () following the ORZ setup"
- KL divergence constraints: Penalties that limit how far a policy can deviate from a reference distribution during RL updates. "We omit KL divergence constraints (both as reward penalties and loss terms) and entropy loss during training."
- Majority voting: A simple aggregation method that selects the most frequent answer among multiple samples. "Vanilla reasoning models tend to rely on simple heuristics such as majority voting when problems admit a simple, easily comparable answer."
- Megatron: A distributed training system/library for large-scale transformer models. "utilizing vLLM for inference and Megatron for training."
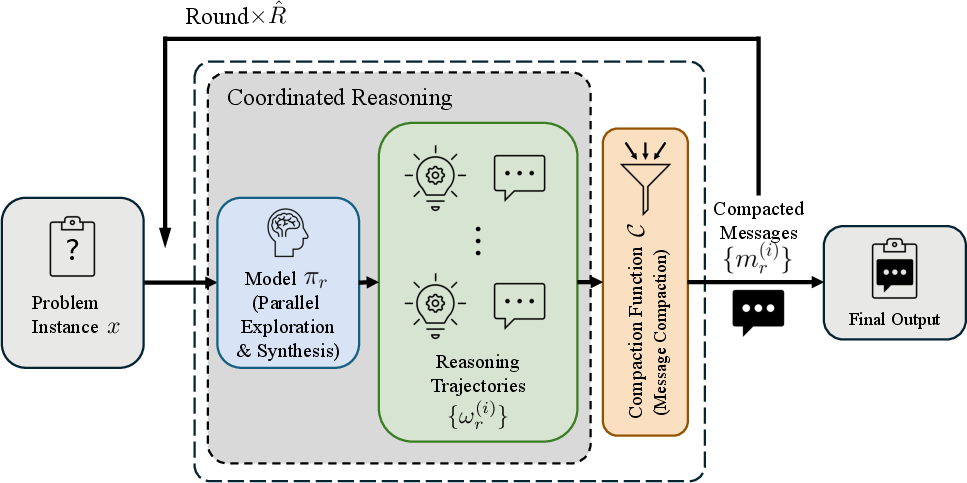
- Message Compaction: The process of compressing full trajectories into short messages so coordination can proceed within a fixed context. "Each round then comprises two stages: (i) Synthesis and Parallel Exploration, ...; and (ii) Message Compaction, where the trajectories are compressed into the next-round message set , allowing PaCoRe to massively scale effective test-time compute under a fixed context window."
- Message passing: An architectural mechanism for coordinating parallel exploration by exchanging compact messages across rounds. "coordinated via a message-passing architecture in multiple rounds."
- Off-policy PPO: Proximal Policy Optimization updates computed from trajectories not generated by the current policy. "We use an off-policy PPO algorithm with GAE (), while omitting importance sampling."
- On-policy PPO: Proximal Policy Optimization where updates use data sampled directly from the current policy. "We employ strict on-policy PPO with GAE () following the ORZ setup"
- Outcome-based reinforcement learning: RL that rewards the final solution correctness rather than intermediate steps, encouraging synthesis. "We then apply large-scale, outcome-based reinforcement learning to elicit these advanced synthesis behaviors."
- PaCoRe (Parallel Coordinated Reasoning): A framework that scales test-time compute via parallel trajectories, message passing, and synthesis within fixed context limits. "We introduce Parallel Coordinated Reasoning (PaCoRe), a training-and-inference framework designed to overcome a central limitation of contemporary LLMs"
- Pass@1 accuracy: The metric indicating whether the first generated answer is correct (without retries). "Pass@1 accuracy is evaluated on HMMT 2025."
- Partial rollout: An inference/training strategy that processes incomplete trajectories to reduce latency. "To address long-tail inference latency, we enable the partial rollout strategy~\cite{team2025kimi}."
- Proximal Policy Optimization (PPO): A popular RL algorithm that stabilizes updates via a clipped objective. "We use an off-policy PPO algorithm with GAE (), while omitting importance sampling."
- Prompting function: A function that serializes the problem and messages into a structured input sequence for the model. "the system uses the prompting function to serialize the problem and the compact messages, producing a structured input sequence for the model."
- Reasoning Solipsism: A failure mode where the model ignores provided insights and tries to solve from scratch, wasting compute. "they often exhibit Reasoning Solipsism: despite receiving rich insights from parallel branches, they ignore this context and attempt to solve the problem from scratch"
- Reasoning Synthesis: The capability to reconcile diverse parallel insights into a coherent, superior solution. "compelling the model to master Reasoning Synthesis: the capacity to scrutinize parallel branches, reconcile conflicting evidence, and synthesize a unified solution that exceeds any individual trajectory."
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL setup where rewards are computed via programmatic or judge-based verification of correctness. "comprising Supervised Fine-Tuning (SFT) and Reinforcement Learning with Verifiable Rewards (RLVR)."
- Self-Consistency sampling: A decoding approach that samples multiple solutions and aggregates them, typically via voting. "Test-time scaling comparison with Self-Consistency sampling (Majority voting)."
- Supervised Fine-Tuning (SFT): Training an LLM on curated labeled data to improve base capabilities before RL or inference-time scaling. "comprising Supervised Fine-Tuning (SFT) and Reinforcement Learning with Verifiable Rewards (RLVR)."
- Test-time compute (TTC): The computation budget spent during inference on a single instance, often via search or multiple trajectories. "their inability to scale test-time compute (TTC) far beyond sequential reasoning under a fixed context window."
- Top-p sampling: Nucleus sampling that restricts token choices to the smallest set whose cumulative probability exceeds p. "generation temperature/top-p of 1.0."
- Truncated Importance Sampling: A technique that caps importance sampling ratios to reduce variance and stabilize off-policy training. "we apply the Truncated Importance Sampling ratio (threshold ) proposed by Yao et al."
- vLLM: An efficient, high-throughput inference engine for LLMs. "utilizing vLLM for inference and Megatron for training."
- YaRN: A method for efficient context-window extension to enable longer inputs without changing attention temperature. "We apply YaRN~\cite{peng2023yarnefficientcontextwindow} (scale 2.0) without modifying attention temperature."
Practical Applications
Practical Applications of PaCoRe: Parallel Coordinated Reasoning
Below are actionable applications that translate PaCoRe’s findings and innovations into real-world value. Each item notes the sector(s), outlines concrete tools/products/workflows, and lists assumptions or dependencies that affect feasibility.
Immediate Applications
- Mathematics tutoring and competition coaching (education)
- What: Deliver multi-strategy solutions to contest-style problems (AIME/HMMT-style), verify final answers, and synthesize the best path from many partially correct attempts.
- Tools/products/workflows: “MathCoach++” that runs PaCoRe-8B or a stronger base model with K-configured parallel trajectories; practice generators that produce multiple independent solution sketches and a synthesized explanation; auto-checkers for problem sets.
- Assumptions/dependencies: Verifiable answer formats (numeric/single-expression); sufficient compute for parallel decoding; appropriate compaction functions (e.g., keep final answer + short rationale).
- Competitive programming and software engineering assistants (software)
- What: Parallel patch search, test generation, and synthesis of fixes from multiple candidate implementations; triage and root-cause analysis via hypothesis branching and synthesis.
- Tools/products/workflows: “Parallel Code Fixer” for GitHub/GitLab CI that proposes multiple diffs and synthesizes a unified patch; test augmentation tools using generator–validator loops; integration with Agentless-style execution sandboxes.
- Assumptions/dependencies: Secure sandboxing; good test coverage or verifiable oracles; compute budget for multi-million-token TTC; compaction customized to store patch diffs, test pass/fail, and key deltas (not only final text).
- Massive document synthesis under tight context windows (knowledge management, legal, enterprise search)
- What: Iteratively summarize and reconcile large corpora (e-discovery, due diligence, policy comment aggregation) via round-wise compaction of claims/evidence.
- Tools/products/workflows: “Message-Graph Summarizer” that uses PaCoRe’s message-passing to ingest and compress multi-document evidence into decision memos; compliance review assistants that synthesize across many regulations and precedents.
- Assumptions/dependencies: Domain-specific compaction schema (claims, citations, confidence); retrieval integration for each round; human-in-the-loop validation to mitigate hallucinations or missed evidence.
- Multi-hypothesis incident response, SRE, and cybersecurity triage (IT operations, security)
- What: Launch many parallel hypotheses on root cause or threat vectors, then synthesize convergent findings and next best actions.
- Tools/products/workflows: “Parallel RCA” runbook node in incident workflows (PagerDuty/ServiceNow); SIEM/SOAR augmentation that enumerates and compacts hypotheses and indicators across rounds.
- Assumptions/dependencies: Access to logs/telemetry; connectors for tooling; latency/cost limits for high-K runs; compaction tuned to preserve indicators, confidence, and evidence links.
- Portfolio, risk, and strategy memos via scenario synthesis (finance, enterprise strategy)
- What: Explore diverse scenarios, stress tests, and strategies in parallel, then synthesize a consensus plan with justifications.
- Tools/products/workflows: “RiskSynth” that runs N concurrent scenario narratives and an overview round to produce a decision memo with assumptions and sensitivities; integration with spreadsheets/analytics for automatic metric checks.
- Assumptions/dependencies: Clear synthesis rubric; structured compaction (key metrics, assumptions); not a substitute for regulated investment advice; governance and sign-off workflows.
- Research assistance and literature review at scale (academia, R&D)
- What: Multi-round paper triage, claim extraction, and cross-checking to produce compact literature maps; exploration of competing model designs or proofs with synthesis of stronger solutions.
- Tools/products/workflows: “ResearchSynth” that ingests hundreds of papers via retrieval, compacts claims per round, and outputs structured summaries and gaps; integration with citation managers and biblio APIs.
- Assumptions/dependencies: High-quality retrieval; compaction schema for claims, methods, and evidence; human curation for correctness; compute budgets sized to corpus size.
- Generalized PaCoRe orchestration layer for enterprises (platform tooling)
- What: A PaCoRe inference server that exposes trajectory configuration, rounds, message compaction, caching, and budget guardrails for any LLM.
- Tools/products/workflows: SDKs and LangGraph/LangChain nodes for “Generate K → Compact → Synthesize → Repeat”; job scheduler for parallel sampling on vLLM; observability dashboards (TTC spent vs accuracy/ROI).
- Assumptions/dependencies: GPU/CPU capacity; robust prompt templates; per-domain compaction design; alignment with enterprise privacy/security.
- Data curation and RL fine-tuning with PaCoRe-style corpora (ML engineering)
- What: Use the released PaCoRe dataset to train synthesis behaviors (RLVR or PPO), improving reasoning performance even without adopting full PaCoRe inference.
- Tools/products/workflows: Lightweight RL pipelines that apply PaCoRe’s instance filters (low majority-vote solvability) to induce synthesis; evaluation harnesses with self-consistency baselines.
- Assumptions/dependencies: Verifiable reward signals for target domains; compute for RL; careful decontamination; monitoring for reward hacking.
- Advanced classroom assistants and exam prep (education)
- What: Provide multiple distinct solution approaches, diagnose common misconceptions by comparing divergent trajectories, and synthesize the most pedagogically clear explanation.
- Tools/products/workflows: Classroom plugins that show “branch gallery” of reasoning attempts; personalized “rounds” that add targeted hints; teacher dashboards showing synthesis rationales and pitfalls.
- Assumptions/dependencies: Clear correctness checks for exercises; safety filters for student use; compute limits tuned to classroom scale.
- Conversational copilots with improved multi-turn synthesis (customer support, internal help)
- What: Use message-passing to reconcile conflicting knowledge base entries, FAQs, and ticket histories into consistent responses under strict context limits.
- Tools/products/workflows: Helpdesk assistants that run first-round retrieval + multi-trajectory answers, then synthesize guidance with cited snippets; escalation memos composed from compacted messages.
- Assumptions/dependencies: Retrieval quality; compaction designed for citations and confidence; monitoring for hallucinations.
Long-Term Applications
- Clinical decision support and care pathway exploration (healthcare)
- What: Parallel differential diagnosis, treatment option exploration, and literature-grounded synthesis for complex cases; iterative rounds integrate labs, imaging, and guidelines.
- Tools/products/workflows: “DiagSynth” for tumor boards or multidisciplinary rounds; EHR-integrated assistants that generate compacted differentials and evidence tables across rounds.
- Assumptions/dependencies: Regulatory approval; clinically validated reward oracles (hard to verify); rigorous safety, provenance, and audit trails; domain-specific compaction (findings, contraindications).
- Formal theorem proving and mechanized verification (academia, safety-critical software)
- What: Combine PaCoRe-style coordinated search with formal checkers (Lean, Coq, Isabelle) to scale proof discovery, cross-checking, and synthesis beyond context limits.
- Tools/products/workflows: Multi-agent proof explorers where trajectories propose lemmas and tactics; compaction stores verified intermediate lemmas; synthesis guides next exploration wave.
- Assumptions/dependencies: Tight integration with formal toolchains; structured compaction of proof states; reliable verifiers as reward signals; significant compute.
- High-stakes policy analysis and impact synthesis (public policy, governance)
- What: Explore many regulatory options and stakeholder positions in parallel and synthesize balanced recommendations grounded in evidence and constraints.
- Tools/products/workflows: “Policy Synth Studio” for public comment aggregation, scenario planning, and distributional impact assessment; round-wise compaction of evidence and trade-offs.
- Assumptions/dependencies: Transparent datasets and provenance tracking; bias auditing; human deliberation and oversight; political and ethical guardrails.
- Robotics and multi-agent task planning (robotics, logistics)
- What: Parallel plan proposals and coordinated synthesis to produce robust action sequences under uncertainty; division of labor among sub-agents with message passing.
- Tools/products/workflows: PaCoRe-in-the-loop planners that generate candidate plans, compact environment feedback, and refine plans across rounds; integration with motion planners and simulators.
- Assumptions/dependencies: Real-time constraints vs compute-heavy parallelism; safety guarantees; high-fidelity simulators as reward sources; multi-modal perception integration.
- Grid, energy, and infrastructure planning (energy, civil engineering)
- What: Large-scale scenario exploration (demand growth, DER integration, outage contingencies) with synthesis into robust investment or dispatch plans.
- Tools/products/workflows: “GridSynth” decision support that runs parallel scenarios and compacts KPIs per round; interfaces to power flow solvers and optimization engines.
- Assumptions/dependencies: Quantitative simulators to ground rewards; domain-specific compaction (reliability, cost, emissions); governance and compliance.
- Quant research and algorithm discovery (finance, science, optimization)
- What: Launch diverse model/parameter hypotheses in parallel and synthesize robust strategies less prone to overfit via cross-round constraints.
- Tools/products/workflows: PaCoRe-driven strategy search with out-of-sample tests; automated research notebooks that compact metrics and diagnostics for next-round proposals.
- Assumptions/dependencies: Reliable backtesting frameworks; strict data leakage controls; risk and compliance reviews.
- Extreme-scale summarization/compression of long-running processes and logs (observability, safety monitoring)
- What: Multi-round compaction to convert multi-billion token streams (e.g., factory logs, autonomous fleet telemetry) into actionable summaries.
- Tools/products/workflows: Streaming PaCoRe workers with rolling windows and periodic synthesis checkpoints; anomaly digests and causal hypotheses.
- Assumptions/dependencies: Stream processing infrastructure; latency-aware scheduling; compaction formats that preserve traceability and drill-down.
- Multi-modal coordinated reasoning (vision, science, medical imaging)
- What: Extend message passing and synthesis to images, time series, and structured data, enabling coordinated exploration across modalities.
- Tools/products/workflows: Multi-modal PaCoRe variants that compact visual findings (e.g., regions, features) and textual interpretations; use in radiology pre-reads or lab automation planning.
- Assumptions/dependencies: Multi-modal base models; compaction for non-text signals; verifiable or proxy rewards.
- Autonomous research pipelines and synthetic data generation (ML R&D)
- What: Use PaCoRe to generate high-density synthetic curricula that emphasize synthesis (not majority voting), then train next-generation models.
- Tools/products/workflows: “Ouroboros” pipelines that iteratively propose–compact–synthesize to create challenging datasets for pretraining/post-training; curriculum schedulers that adapt K and rounds.
- Assumptions/dependencies: Reliable quality controls; scalable RL infrastructure; prevention of mode collapse or reward hacking; strong decontamination.
- Cloud services for managed TTC scaling and budget-aware reasoning (cloud/infra)
- What: Offer PaCoRe-as-a-Service with elastic parallel sampling, cost guardrails, and SLA-aware scheduling to trade accuracy vs latency vs spend.
- Tools/products/workflows: Managed endpoints exposing trajectory configuration vectors (K, rounds), per-request spend caps, and ROI analytics; autoscaling across GPU pools.
- Assumptions/dependencies: Efficient batching and caching; usage governance; clear KPIs for TTC–accuracy trade-offs.
Cross-cutting assumptions and dependencies
- Compute budgets and orchestration: Parallel exploration requires scalable inference (e.g., vLLM) and careful scheduling to manage cost and latency.
- Domain-specific compaction: The paper’s default “final conclusion only” compaction must be adapted per domain (e.g., code diffs, test results; claims/evidence; KPIs/metrics; proof states).
- Verified or proxy reward signals: Outcome-based RL depends on checkers or strong proxies (math answers, testcases, formal verifiers, simulators).
- Synthesis training: Without RL for synthesis, models tend toward “reasoning solipsism”; domain-adapted RL can be necessary for strong gains.
- Safety, reliability, and governance: High-stakes uses require human oversight, provenance, and regulatory compliance, especially in healthcare, finance, and policy.
- Data quality and decontamination: Prevent leakage and ensure trustworthy evaluations; monitor for hallucinations and bias.
- Cost–benefit tuning: Select K and number of rounds to optimize ROI for each task; caching and first-round pools can reduce spend while retaining performance.
Collections
Sign up for free to add this paper to one or more collections.