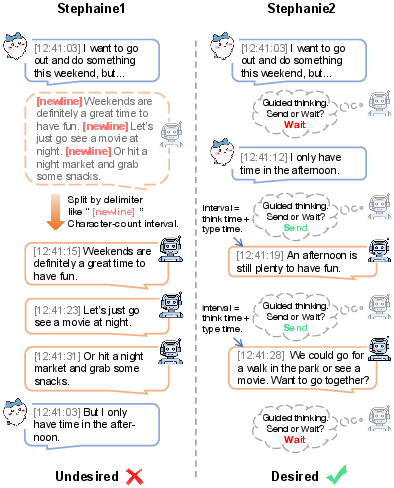
Figure 1: Stephanie2 differs from Stephanie1 by implementing active waiting and message pacing adaptation.
Stephanie2 is instantiated as a step-wise decision-making agent that iteratively chooses between sending a message or waiting, grounded in active analysis of dialogue context and persona constraints. At each dialogue step, the agent outputs explicit > traces followed by either <response> or <wait> actions. The decision policy π(a∣mt,pt) leverages both short-term and periodic long-term memory summarization to efficiently capture conversation flow while maintaining context relevance. Latency computation for message delivery combines coefficients for thinking and typing time per character, decoupled from raw message length, yielding realistic timing consistent with observed human behavior.
The novel dual-agent dialogue system applies a time-window allocation protocol to both Stephanie2 and baseline variants, enabling agents to hold the speaking floor for a probabilistically bounded interval and minimizing unnatural turn-taking. This mechanism generates high-quality step-by-step interaction histories, suitable for downstream evaluation and scalable to multi-party chat environments.
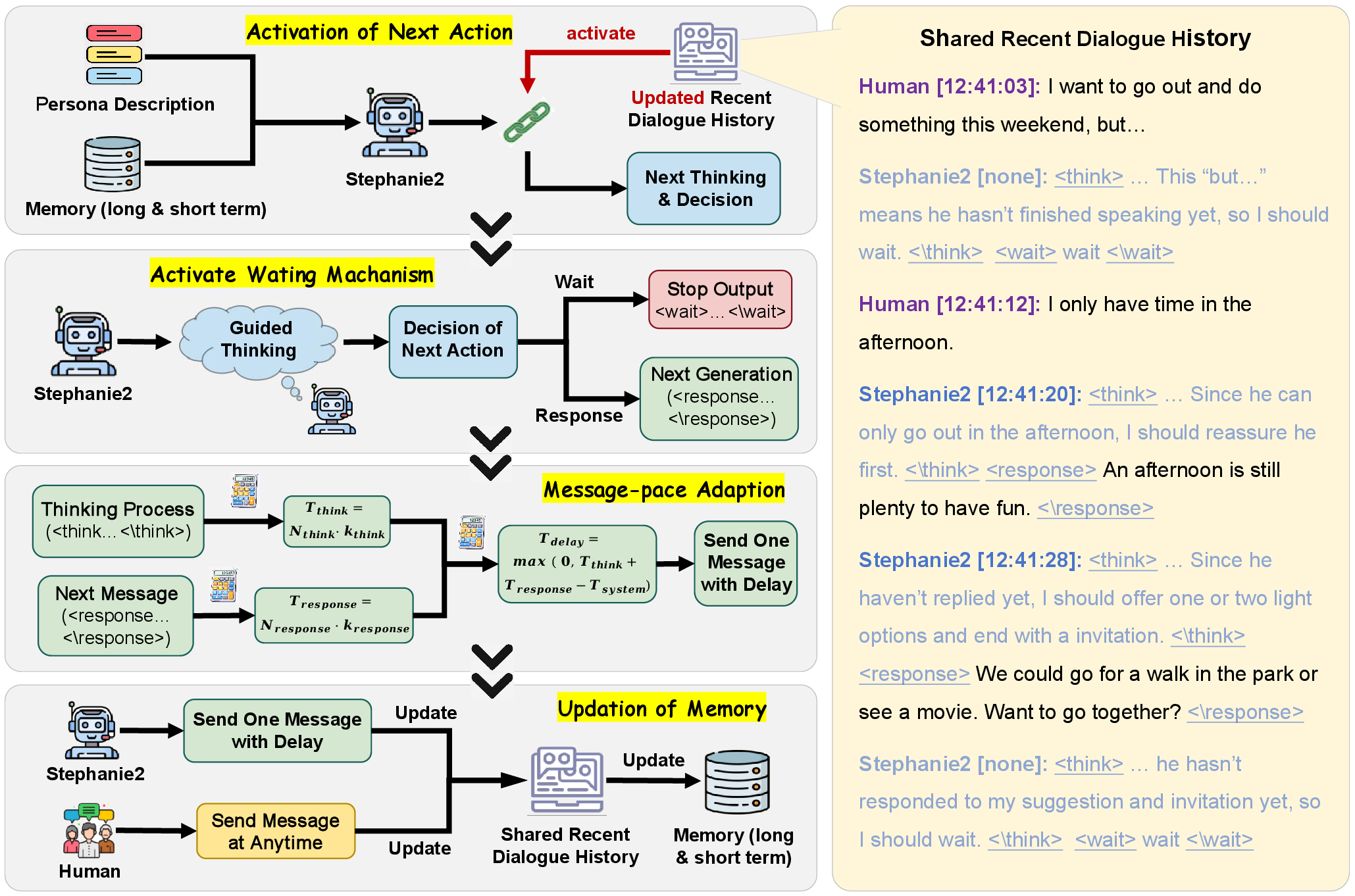
Figure 2: Stephanie2 is a step-wise decision-making agent with proactive waiting and message-paced adaptation mechanisms.
Evaluation Protocol and Metrics
Stephanie2 is benchmarked against Stephanie1 and punctuation-segmented dialogue (PD) variants using both automatic and human assessments. Metrics encompass seven dialogue-experience dimensions (Interesting, Informative, Natural, Coherent, Engaging, On-topic, On-persona), lexical diversity via Distinct-N, average consecutive message count (ACMC), words per message, and a pass rate on a role identification Turing test. The pass rate quantifies dialogue indistinguishability from humans, calculated as the proportion of evaluators misclassifying or marking the AI role as unclear.
Empirical Results
Stephanie2 consistently outperforms baselines in naturalness, engagement, and persona adherence, as scored by GPT5.2, DeepSeek-V3, and Llama3.1-8B backbones. For overall dialogue experience, Stephanie2 exhibits improvements of +2.1 to +4.1 points versus Stephanie1, and achieves an average human rating of 3.83, compared to 3.62 (Stephanie1) and 3.36 (PD). Lexical diversity as measured by Distinct-N is higher for Stephanie2 especially for lower-order n-grams, evidencing richer and less repetitive responses.
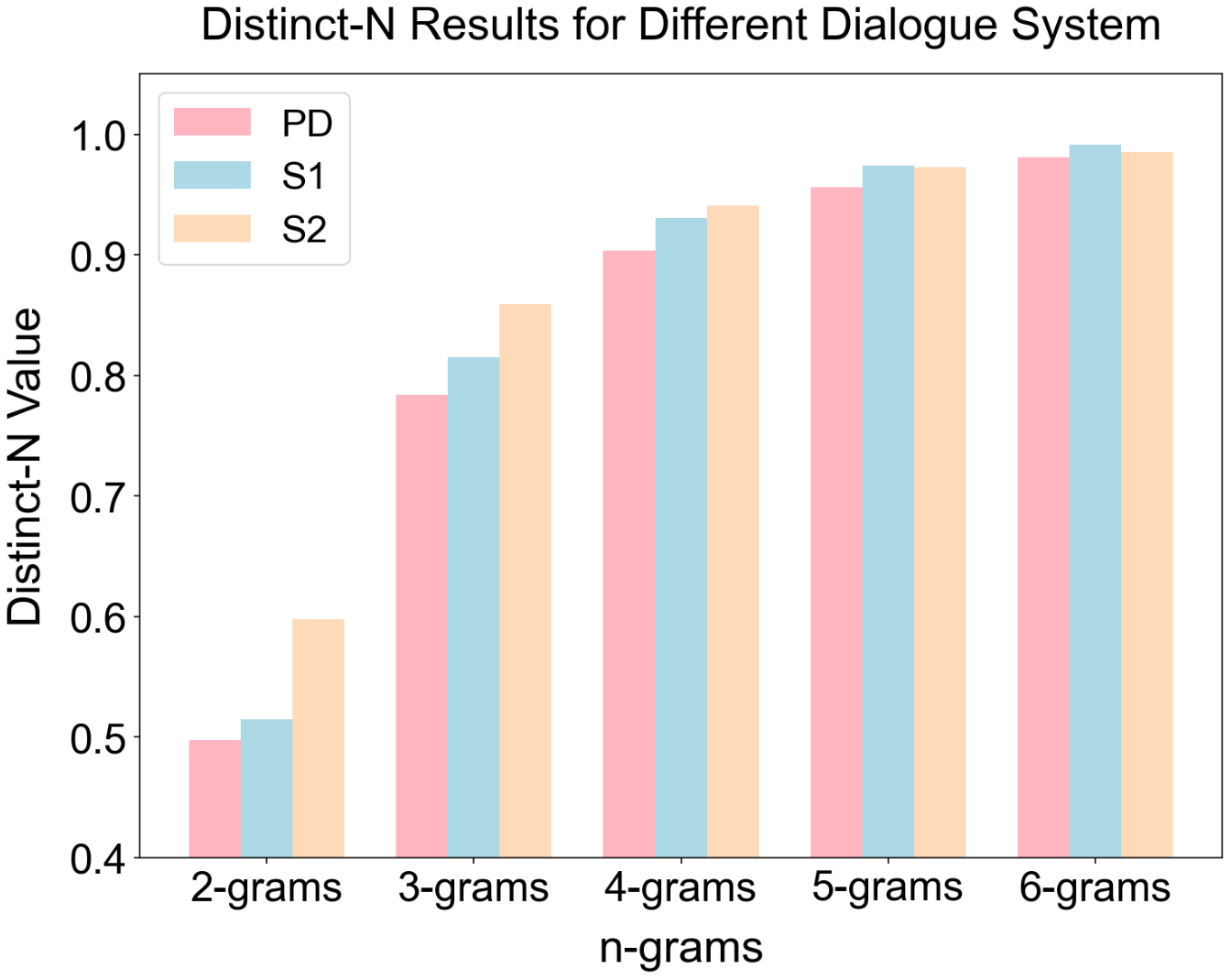
Figure 3: Distinct-N results highlight Stephanie2’s superior lexical diversity.
Role identification tests reveal Stephanie2 dialogues are significantly harder to distinguish from human interactions. On GPT5.2, the pass rate rises from 36.08% (Stephanie1) to 49.60%, indicating Stephanie2’s behavioral realism. DeepSeek-V3 and Llama3.1-8B show similar trends, with pass rates up to 56.24%, and correct identifications correspondingly decreasing by 13–20 percentage points.
Message-level analysis indicates that Stephanie2’s words/message and ACMC closely align with human statistics (7.29 words/message vs. 5.84 for humans; ACMC 1.66 vs. 1.70 for humans), demonstrating effective suppression of monologue-like message runs and congruence with conversational rhythm.
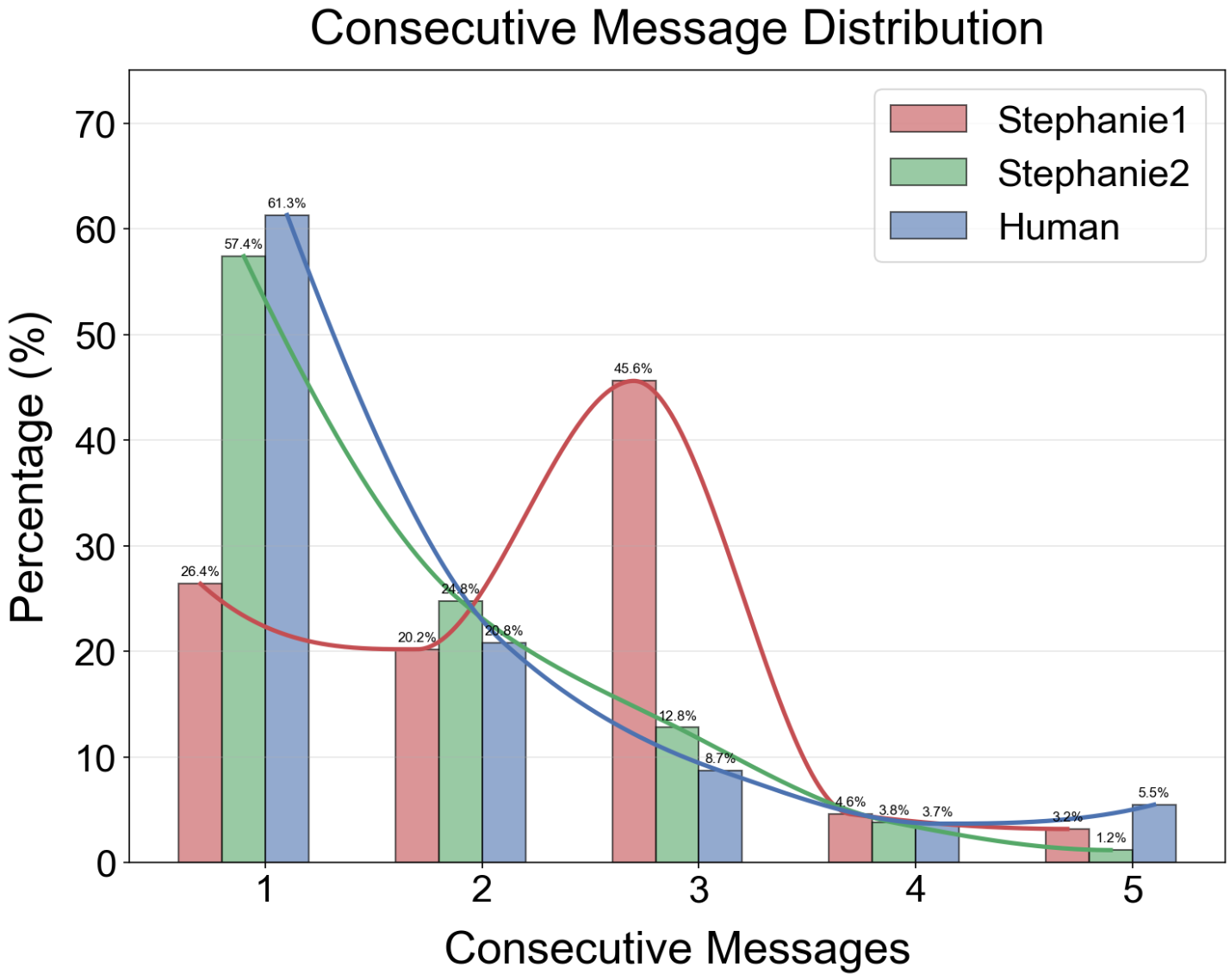
Figure 4: Distribution of consecutive reply counts reveals Stephanie2’s improved imitation of human chat patterns.
Stephanie2’s active waiting mechanism produces reply interval distributions with heavier long-tailed dynamics, with mean intervals increasing from 6.5s (Stephanie1) to 10.5s, yielding less frequent interruptions and more natural latency.
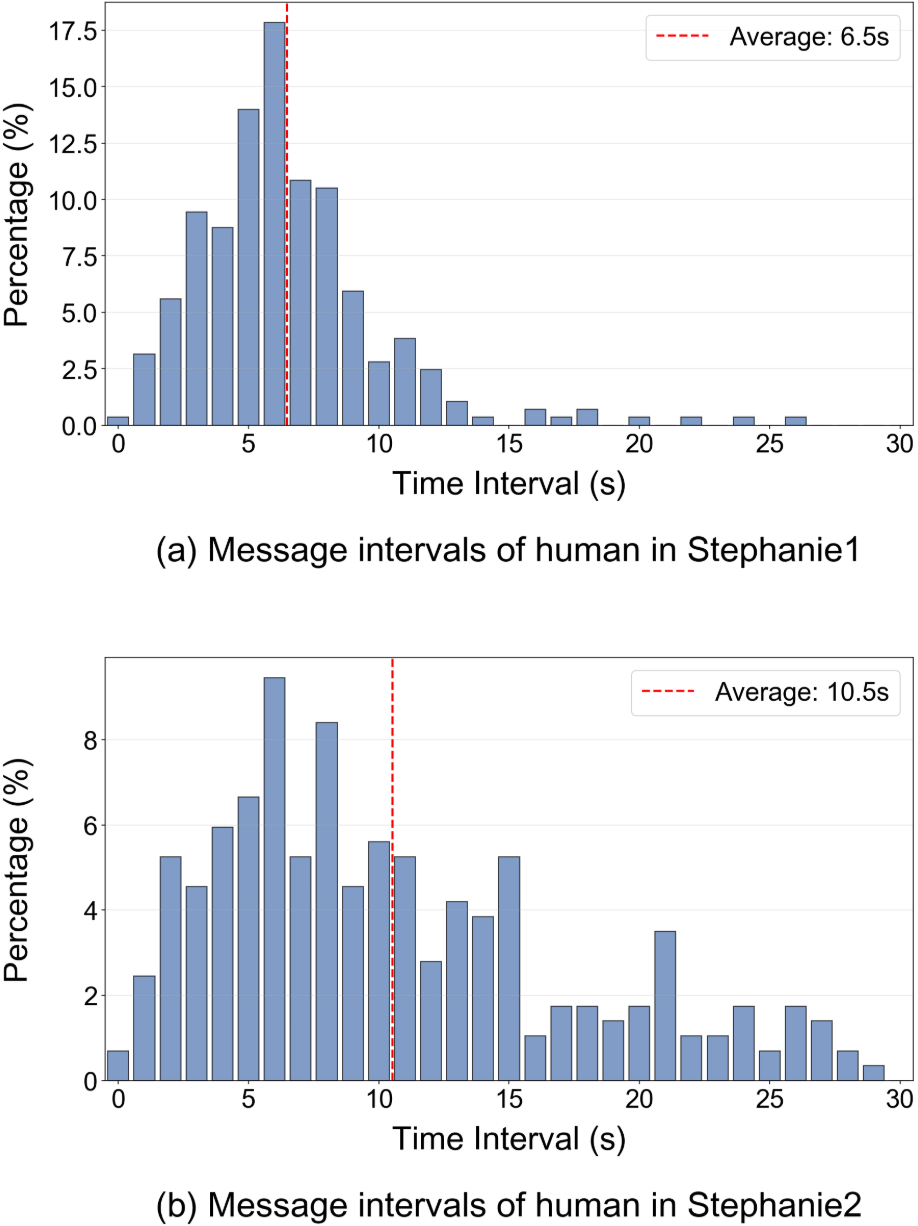
Figure 5: Distribution of message intervals illustrates realistic timing and reduced interruption with Stephanie2.
Topic Distribution and Data Generation
The dual-agent methodology allows for stratified sampling across 60 clustered topics extracted from hierarchical summarization of Persona-Chat corpus instances, ensuring evaluation generalizes to a broad range of conversational themes. Stephanie2-generated dialogues retain granular persona cues and realistic temporal structure, crucial for emotional and engagement metrics.
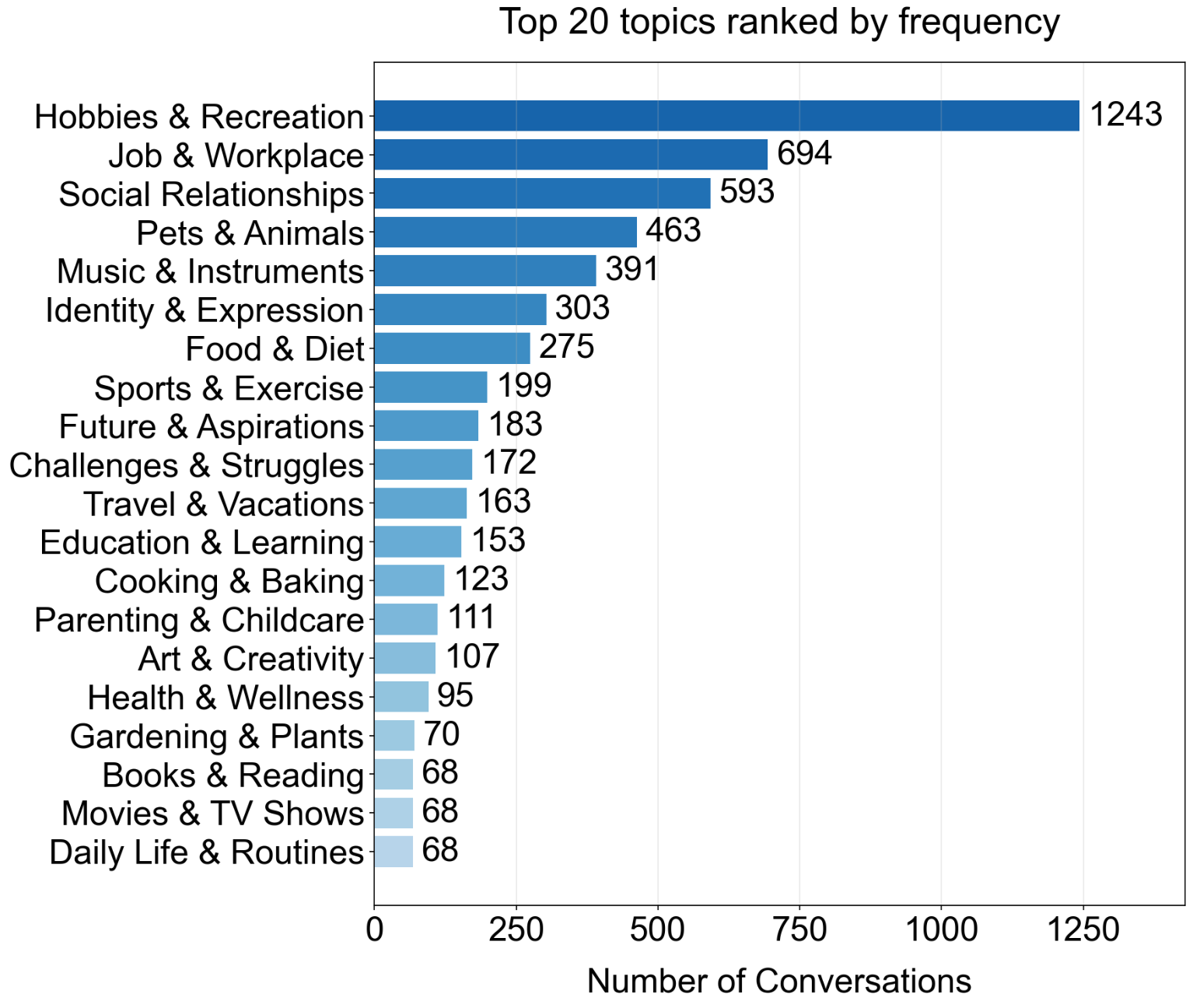
Figure 6: Topic distribution of Stephanie2 dialogue datasets for evaluation across diverse conversational domains.
Case Studies: Decision Dynamics and Conversation Flow
Case analyses demonstrate Stephanie2’s ability to perform context-sensitive situational waiting and conversation closure. In multi-message scenarios, Stephanie2 listens until interlocutor details conclude (Figure 7), and can proactively end exchanges in appropriate situations (Figure 8), contrasting with premature or delayed responses from Stephanie1. The combined thinking and message pacing mechanisms yield delay behaviors more aligned with human cognitive conversational processes.

Figure 7: Case 2—Stephanie2’s conditional waiting during extended details exemplifies controlled non-interruption.

Figure 8: Case 3—Stephanie2’s proactive decision to end conversation upon mutual “good night” closure.
Implications and Future Directions
Stephanie2’s step-wise architecture and latency modeling introduce persuasive evidence for integrating explicit reasoning traces and waiting policies in social chat agents. The alignment of conversational statistics and human evaluation metrics substantiates Stephanie2’s potential for AI companion and emotional support applications. Incorporating dual-agent and time-window protocols marks a significant methodological direction for robust data generation and evaluation in multi-agent or group-chat domains.
Continued investigation into finer-grained context management, adaptive persona alignment, and scalable multi-agent coordination will further advance user-centered dialogue systems. Stephanie2’s modular design is well-positioned for extension to richer dialogue strategies, enhanced emotional intelligence, and safer, more aligned conversation in real-world deployments.
Conclusion
Stephanie2 represents a substantial technical advance in step-by-step AI social chat by addressing critical deficiencies in active waiting and human-like pacing. Through explicit reasoning traces, adaptive decision making, and realistic latency modeling, Stephanie2 delivers more natural, engaging, and context-consistent dialogue interactions. Empirical results across automatic and human evaluations confirm improved naturalness and indistinguishability from human counterparts. The dual-agent paradigm and topic-stratified data generation framework may inform future multi-agent chat systems and evaluation methodologies. These findings contribute concretely to the evolving landscape of conversational AI, offering a path toward more authentic, user-aligned social agents.
(2601.05657)