Goal Force: Teaching Video Models To Accomplish Physics-Conditioned Goals
Abstract: Recent advancements in video generation have enabled the development of ``world models'' capable of simulating potential futures for robotics and planning. However, specifying precise goals for these models remains a challenge; text instructions are often too abstract to capture physical nuances, while target images are frequently infeasible to specify for dynamic tasks. To address this, we introduce Goal Force, a novel framework that allows users to define goals via explicit force vectors and intermediate dynamics, mirroring how humans conceptualize physical tasks. We train a video generation model on a curated dataset of synthetic causal primitives-such as elastic collisions and falling dominos-teaching it to propagate forces through time and space. Despite being trained on simple physics data, our model exhibits remarkable zero-shot generalization to complex, real-world scenarios, including tool manipulation and multi-object causal chains. Our results suggest that by grounding video generation in fundamental physical interactions, models can emerge as implicit neural physics simulators, enabling precise, physics-aware planning without reliance on external engines. We release all datasets, code, model weights, and interactive video demos at our project page.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
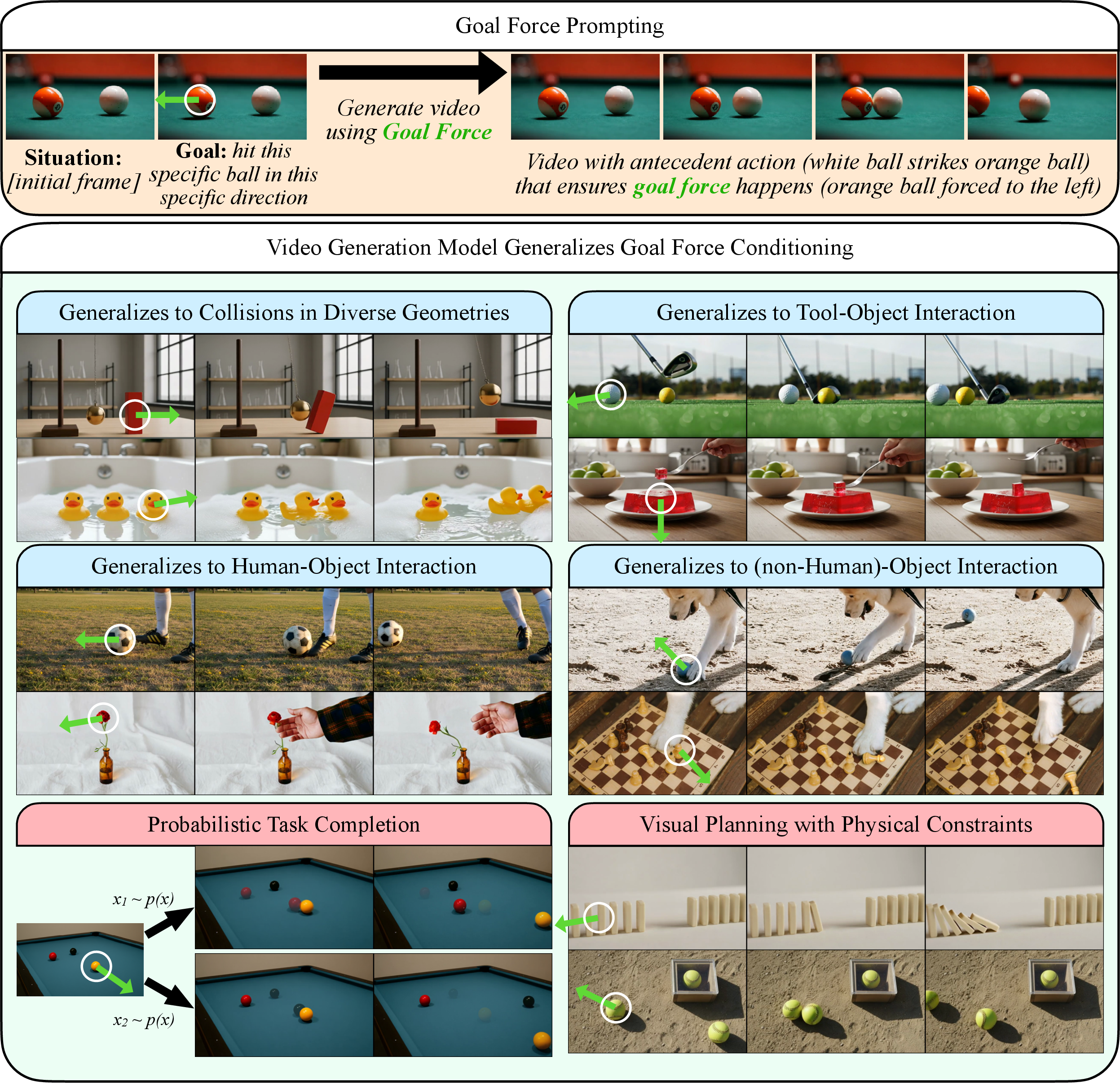
This paper is about teaching an AI that makes videos to plan like a person who understands physics. Instead of telling the AI “make the ball go in the goal” (which is vague) or showing a perfect final picture (which is hard), you tell it the exact push you want on a target object—like “give this ball a strong push to the right.” The AI then creates a short video that shows what needs to happen before that push—maybe another ball hits it, a pendulum swings into it, or a person uses a tool. The key idea: you set a desired effect (a “goal force”), and the model invents a physically sensible cause to make it happen.
What questions were the researchers asking?
The researchers wanted to know:
- Can we give a video model clear, physics-based goals (like a specific push on an object) instead of vague text or hard-to-make target images?
- Can a model learn to work backward from a desired effect (the goal force) to create a believable chain of causes (what hits what, when, and how)?
- If we train only on simple physics (balls, dominos, plants), will the model still handle more complicated, real-world scenes—like tools, hands, and many objects interacting?
- Can it do all this without using a separate physics simulator during generation?
How did they do it? (Methods in simple terms)
Think of the model as a skilled movie-maker that can also “feel” pushes.
- A new way to “talk” to the model: goal forces
- The user marks where on the frame the target object is and specifies a force arrow (direction and strength). The model treats this as the effect we want.
- They also support “direct forces” (a push you apply directly somewhere) and optional “mass hints” (which objects are heavier or lighter).
- How forces are encoded
- The researchers represent forces as a small, moving fuzzy dot that slides in the direction of the desired push. The dot’s path and speed capture the force’s direction and strength. This dot is just a visual trick the AI understands as “apply a push like this.”
- Mass is shown as a static fuzzy dot over an object—bigger for heavier, smaller for lighter.
- Training on simple building blocks of physics
- They made lots of short synthetic videos of:
- Dominos falling in a chain.
- Balls rolling and colliding.
- A flower swaying after being poked (to teach bendy, not-rigid motion).
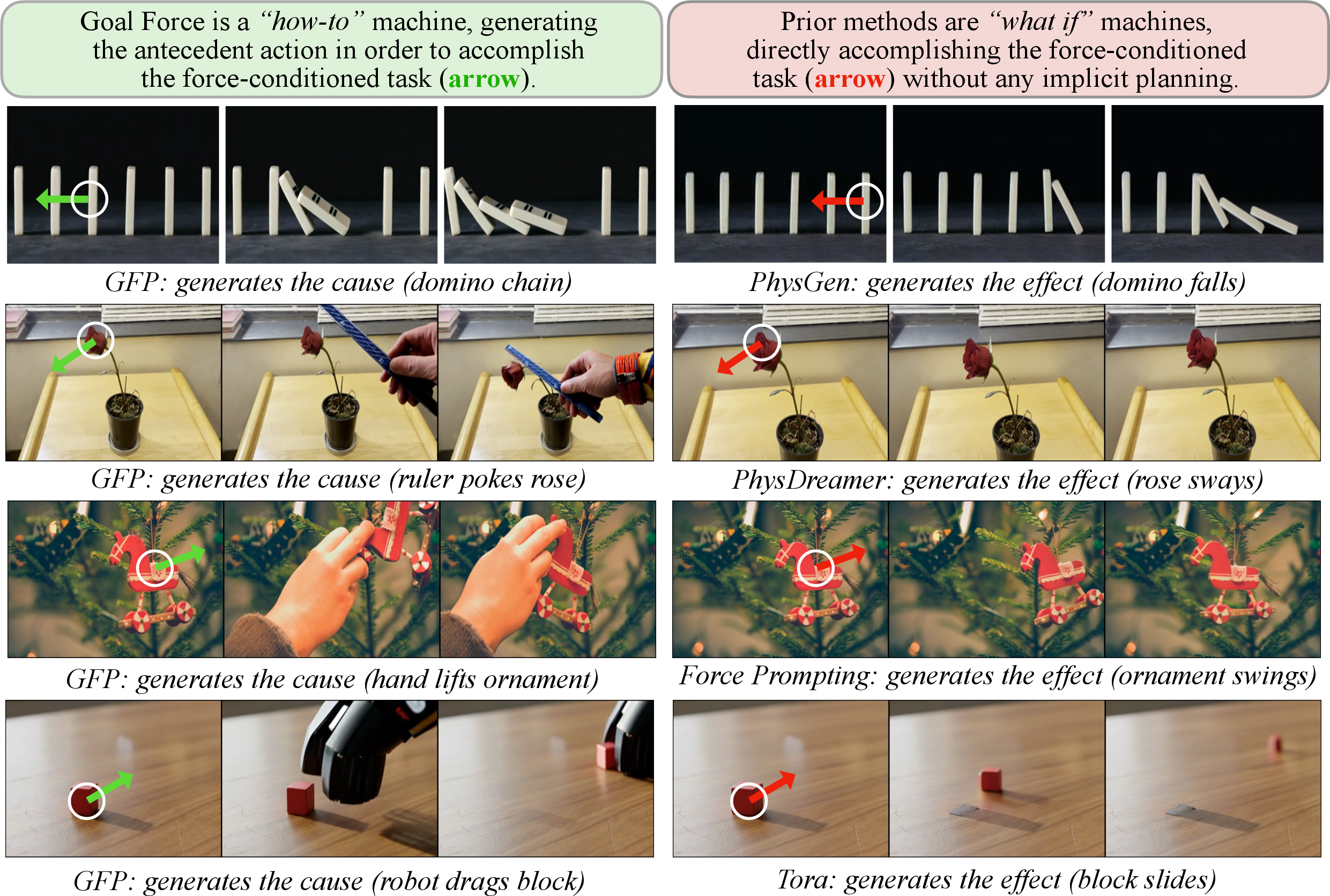
- In some training clips, the AI sees the cause (a direct push) and must predict the effect. In others, it only sees the desired effect (goal force) and must invent a believable cause. This back-and-forth teaches it to plan.
- No external physics engine at test time
- After training, the model doesn’t call a physics simulator. It “learned” enough physics to plan on its own while generating video.
- The base model
- They started with a powerful video generator and attached a small “controller” that reads the force and mass signals. You can think of it as adding a new set of dials that tell the model how to behave physically.
What did they find, and why does it matter?
Here are the main results the authors report:
- Better at following physics-based goals
- In human studies, the model that used goal forces was preferred for “Did the video actually accomplish the requested push?” compared to text-only approaches. In short: telling the model a precise physical goal works better than vague text.
- Plans that respect real-world obstacles
- When some objects were blocked and couldn’t start the chain, the model learned to pick a different, valid initiator. Example: if one ball is trapped, it chooses another ball to hit the target. That means it isn’t just “making stuff move”—it’s reasoning about what can and can’t happen.
- Multiple valid plans (not stuck on one idea)
- In a domino test where several starting points could topple the final domino, the model produced a variety of valid plans across different runs, not the same solution every time. This is closer to how humans think: “There’s more than one way to do it.”
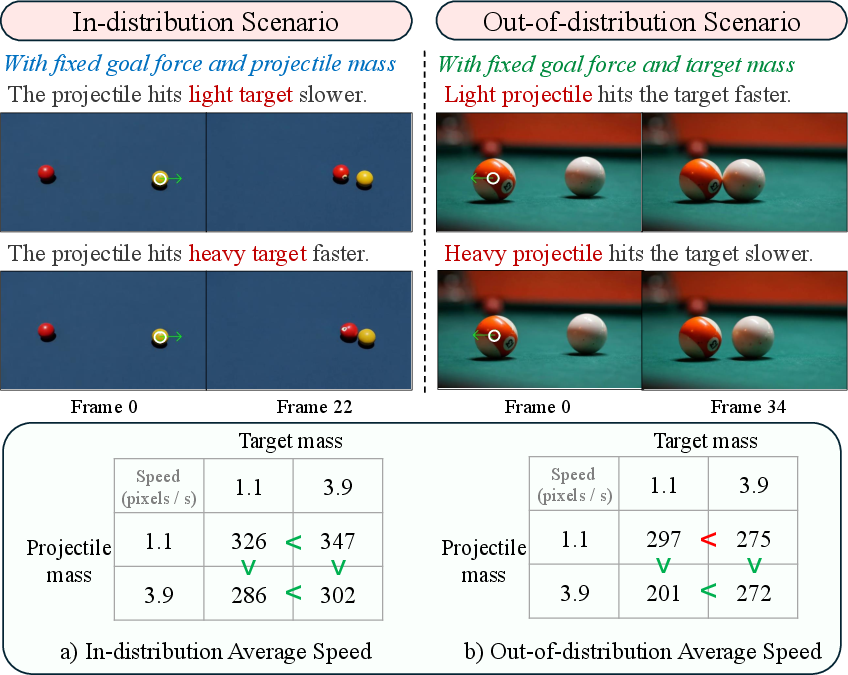
- Uses mass information sensibly
- When the target was heavier, the model planned a faster or heavier projectile to achieve the same goal force—just like real physics. When the projectile was heavier, it didn’t need to move as fast.
- Surprising generalization to real scenes
- Even though it trained on simple balls and dominos, the model handled scenes with tools and hands—like using a golf club to hit a ball or tapping an object with a fork—without extra training on those specifics. That suggests it learned useful physics ideas, not just memorized training clips.
- High visual quality maintained
- The improvements in hitting the goal didn’t come with big losses in realism or video quality, according to human ratings.
Why this matters: If you want an AI to plan actions in the physical world (like a robot or an animation tool), telling it the exact force you want on an object is both precise and natural. It shifts control from “describe in words” to “specify the physics,” which is often what you really care about.
What could this change in the future? (Implications)
- Smarter planning for robots and tools
- Robots could plan actions visually by aiming for specific forces (e.g., “apply a gentle push to open the door”) and letting the model figure out the safe, physically correct chain of steps.
- Better creative tools
- Animators and game designers could specify how objects should be affected (bounce, tip, slide) and let the model invent realistic causes, saving time.
- More intuitive interfaces
- People already think in forces: “push this harder,” “nudge that left.” This method gives a direct way to communicate that to an AI.
- A step toward “neural physics engines”
- The model behaves like an approximate physics simulator without needing perfect 3D models or a heavy physics engine. That’s promising for real-time planning and for messy, real-world scenes.
A simple caveat: It’s not perfect yet. Sometimes the model may produce odd visuals or miss subtle constraints. Still, learning from simple physics and then handling complex scenes—without a separate simulator—is a big step forward.
In short: This paper shows a new, physics-first way to control video-generating AIs. By asking for a desired push on a target, the model figures out how to make that push happen, creating believable chains of cause and effect. That’s useful for planning, robotics, animation, and any task where what matters is not just how things look, but how they should move and interact.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- External validity of “zero-shot” generalization is weak: evaluation relies on 25 curated scenes and N=10 human raters; no large-scale, statistically powered benchmark across diverse real-world domains, object categories, backgrounds, lighting, occlusions, or moving cameras.
- Lack of formal physics adherence metrics: no systematic measurement of momentum/energy transfer, contact timing, or match between specified goal force direction/magnitude and realized object motion beyond limited ball tracking; standardized quantitative metrics are needed.
- Causality is not enforced: observed failures include spontaneous target motion; no explicit losses, constraints, or verification (e.g., contact-before-effect, mutual exclusivity, temporal precedence) to penalize non-causal solutions.
- Ambiguous object targeting: the Gaussian “goal force” overlay assumes the model knows which object should receive the force; no object-centric interface (segmentation/tracking/identity) or method to disambiguate multiple candidates under clutter/occlusion.
- No calibration to real-world units: forces and masses are normalized per dataset and lack consistent absolute scale, limiting transfer to robotics; mapping from user-specified Newtons/kilograms to control signal remains open.
- Short-horizon planning only: videos are limited to 81 frames at 16 FPS (~5 seconds); performance on longer-horizon, multi-stage causal chains and compounding errors is unknown.
- Single-goal limitation: no support for multiple simultaneous/sequential goal forces, priorities, deadlines, or temporal scheduling of effects.
- Constraint-aware planning absent: the model can invent initiators (e.g., a hand or tool); mechanisms to restrict allowed agents, tools, or regions (or to enforce safety constraints) are not provided.
- Robustness in cluttered scenes is untested: how goal localization performs with many distractors, heavy occlusions, and similar-looking objects remains unclear.
- Limited physical regimes: training covers rigid collisions and one non-rigid exemplar (a single flower); generalization to articulated objects, deformables, fluids, granular media, frictional variability, and non-elastic impacts is unproven.
- 3D consistency and camera motion: the control signal is 2D screen-space; handling of moving cameras, depth ambiguities, parallax, and out-of-plane interactions is not evaluated.
- Mass channel practicality: it is unclear how users obtain/estimate masses in the wild; no study on reliability of learned mass inference from appearance or consequences of incorrect mass inputs.
- Missing ablations: no quantification of each control channel’s contribution (direct force, goal force, mass), the masking curriculum, Gaussian encoding design (size, duration, trajectory), or chosen architecture layers; sensitivity to the base model is unreported.
- Limited baseline coverage: prior methods are declared incompatible with “goal force,” but no adapted baselines (e.g., trajectory-to-force converters, differentiable planners, or re-trained variants) are evaluated for fairness.
- No planning verification or search: sampling diversity is shown, but there is no verifier, scoring function, or inference-time search to select the most physically valid or goal-adherent plan; integrating verifiers could improve reliability.
- Latency and scalability unknown: inference-time cost, memory footprint, and throughput are not reported; suitability for real-time planning/control is undetermined.
- Selection bias in evaluation: “invalid” trials are filtered post hoc for visual artifacts before computing accuracy; objective, automatic validity criteria and all-sample reporting are needed.
- Uncertainty quantification absent: the model does not estimate plan feasibility or confidence; mechanisms to predict success probabilities or abstain on impossible goals are missing.
- Impossibility detection not tested: no evaluation on scenes where the desired goal force is physically infeasible; model behavior (e.g., refusal vs hallucination) is unknown.
- Text–force conflicts: sensitivity to inconsistent or conflicting text and goal-force prompts, and how the model resolves them, is unexplored.
- Safety and ethics: the system can invent unsafe or undesirable actions/tools; no safeguards, constraint interfaces, or risk assessments are provided.
- Robotics integration is speculative: no closed-loop experiments mapping generated plans to robot actions, no calibration to embodiment constraints, and no end-to-end success metrics on physical tasks.
- Limited diversity analysis: diversity is measured on a single domino setup; broader multi-modal tasks and trade-offs between diversity and adherence/realism are not characterized.
- Failure mode taxonomy: beyond “spontaneous motion,” a systematic categorization and root-cause analysis of errors (e.g., mis-targeting, interpenetration, temporal misordering) is missing.
- UI/UX for goal specification: how users intuitively author spatiotemporal goal-force vectors (timing, duration, magnitude) and how to provide real-time feedback or corrections is unspecified.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now using the released datasets, code, model weights, and demos, along with sector links, potential tools/workflows, and feasibility notes.
- Robotics research and visual planning
- Sector: robotics, software
- Application: Offline visual planning of causal chains where a user specifies a desired effect (goal force) on a target object and the model generates antecedent actions (e.g., which object should strike the target and how).
- Workflow: Specify a goal force via the multi-channel control signal; generate visual plans; extract action primitives from video via keypoint tracking and inverse dynamics (e.g., as in UniPi/Adapt2Act pipelines); validate with detection (e.g., Faster R-CNN) and collision timing.
- Tools: The released Goal Force ControlNet fine-tuning, force-prompt authoring UI (Gaussian blobs), object detectors, trackers, inverse dynamics modules.
- Assumptions/dependencies: Requires reliable object detection/tracking; action extraction depends on inverse dynamics calibration; physics is learned on a relative scale (not absolute); no 3D geometry at inference; plans need human or programmatic verification.
- Creative media previsualization and game design
- Sector: media/VFX, gaming, software
- Application: Rapid previsualization of physically plausible sequences by specifying desired outcomes (e.g., “this domino should fall,” “this ball should move left strongly”) without hand-animating causes.
- Workflow: Use the force-channel UI to annotate goal forces in a still frame; generate candidate sequences; pick diverse options for storyboards or level design puzzles; iterate quickly without a physics engine.
- Tools: Goal Force plugin for video generators, level design editors with force-vector overlays.
- Assumptions/dependencies: Visual plausibility can exceed physical accuracy; domain assets and scene layout influence plan validity.
- Physics education and interactive demonstrations
- Sector: education
- Application: Teaching causal reasoning and intuitive physics by letting students specify goal forces and observing valid antecedent actions (collisions, multi-object chains).
- Workflow: Classroom demos using the web interface; assignments exploring mass effects via the mass channel; quantify motion with basic detectors.
- Tools: Released demos, classroom-friendly UIs, simple analytics scripts for speed/trajectory.
- Assumptions/dependencies: Simplified synthetic priors; relative scales; not a substitute for high-fidelity simulators in rigorous coursework.
- Sports coaching visual aids
- Sector: sports analytics/training
- Application: Visualizing how to impart specific ball trajectories/velocities (goal forces) and showcasing plausible antecedent actions (e.g., approach angles, tool use such as a club).
- Workflow: Annotate target ball with desired goal force; generate multiple plan videos; discuss technique variations with athletes.
- Tools: Goal Force model, video annotation overlays, coaching review tools.
- Assumptions/dependencies: Not calibrated to real-world force/torque; requires expert interpretation; environmental and equipment variability.
- Academic benchmarking and method development
- Sector: academia
- Application: Evaluating controllability, causal adherence, diversity (e.g., JSD-based metrics), and physics reasoning in video models; building new datasets and tasks around goal-conditioned planning.
- Workflow: Replicate human studies; extend benchmarks; test ablations (e.g., masking channels, mass usage); compare text-only vs. force-conditioned controls.
- Tools: Released datasets/code, evaluation scripts, control signal API.
- Assumptions/dependencies: Benchmarks use permissively licensed data and synthetic scenes; base model priors affect results.
- Safety analysis for generative planning
- Sector: policy, safety engineering
- Application: Using controlled visual planning environments to probe how generative models choose initiators under constraints (e.g., blockers), assess failure modes like spontaneous motion, and design guardrails.
- Workflow: Construct “natural blocker” scenarios; sample plans at scale; categorize error modes; propose policy guidelines for deployment.
- Tools: Goal Force evaluator, scenario generator, qualitative/quantitative assessment protocols.
- Assumptions/dependencies: Visual success ≠ real-world safety; requires risk assessments and human-in-the-loop oversight.
Long-Term Applications
The following applications require further research, scaling, integration, or verification before widespread deployment.
- Closed-loop robot control with goal-conditioned planning
- Sector: robotics
- Application: Embedding Goal Force planning in real robots to synthesize actions that achieve specified physical outcomes (e.g., multi-step object manipulation, tool use).
- Workflow: Real-time perception to identify target objects; goal-force authoring via AR or task planners; plan verification; force-to-action translation with tactile/force feedback; safety interlocks.
- Tools/products: Goal Force SDK for robotics stacks; action extractors integrated with robot controllers; verification modules; simulators for pre-checks.
- Assumptions/dependencies: Robust sim-to-real transfer; calibrated force/torque; 3D-aware verification; stringent safety and compliance.
- Digital twins and industrial automation planning
- Sector: manufacturing, logistics
- Application: Rapid exploration of causal chains (e.g., item routing, collision-based sorting, tool interactions) within digital twins to test “desired effect first” planning before committing to hardware changes.
- Workflow: Author goal forces in digital twin scenes; generate candidate plans; validate with physics engines; deploy via PLCs/robotic cells after certification.
- Tools/products: Goal Force–Twin integrators, CAD/CAE bridges, plan verifiers, HIL (hardware-in-the-loop) test suites.
- Assumptions/dependencies: Tight coupling with accurate 3D geometry and material models; plan verification against standards; domain-specific compliance.
- AR guidance for human tasks
- Sector: consumer AR, enterprise AR
- Application: AR assistants that overlay goal-force vectors on objects (e.g., assembling furniture, lab procedures), then propose antecedent actions that respect constraints (mass, blockers).
- Workflow: On-device perception; AR rendering of goal arrows; sampling diverse valid plans; explainable instruction delivery.
- Tools/products: AR Goal Force app, on-device ControlNet; lightweight verifiers; human factors–aligned UX.
- Assumptions/dependencies: Real-time inference on edge hardware; reliable object/mass estimation; user safety and ergonomics.
- Autonomous systems scenario generation and validation
- Sector: autonomous vehicles/robots
- Application: Generating targeted scenarios with desired effects (e.g., “avoid collision” or “force on target must be below threshold”) to stress-test policies and verifiers.
- Workflow: Author safety-critical goals; generate plans; run in simulators; evaluate policies; iterate.
- Tools/products: Goal-conditioned scenario generators, verifier pipelines, integration with driving/robotics simulators.
- Assumptions/dependencies: Requires accurate physics and closed-loop evaluation; risk of unrealistic edge cases if priors mislead generation.
- Tool and product interaction design
- Sector: product design, HCI/ergonomics
- Application: Iterating on tool forms and interaction sequences to achieve desirable effects (e.g., minimal force on fragile parts) before prototyping.
- Workflow: Specify mass distributions; set goal forces; explore diverse plans; move promising candidates into physics simulators or lab tests.
- Tools/products: Goal Force design IDEs, mass-annotated prompt libraries, verification bridges to CAD/CAE.
- Assumptions/dependencies: Requires calibration to material properties; integration with engineering simulation for final validation.
- Rehabilitation and training planning (non-clinical initially)
- Sector: healthcare (assistive tech, training)
- Application: Visualizing safe movement sequences to achieve desired outcomes (e.g., moving objects without exceeding joint load proxies), guiding therapists/patients with plausible plans.
- Workflow: Annotate goals; generate diverse plans; select therapist-approved sequences; later integrate with sensors/exoskeletons.
- Tools/products: Training simulators, plan verifiers using biomechanical proxies.
- Assumptions/dependencies: Clinical validation required; ethical and regulatory approvals; accurate biomechanical modeling beyond current priors.
- Standards, governance, and guardrails for goal-conditioned generative systems
- Sector: policy, governance
- Application: Defining evaluation standards for causal adherence, diversity, and safety; building guardrails for misuse (e.g., generating harmful plans).
- Workflow: Community benchmarks; conformance tests; risk scoring; deployment guidelines; content moderation.
- Tools/products: Standardized test suites (e.g., blocker scenarios), diversity metrics (e.g., JSD-based), compliance checkers.
- Assumptions/dependencies: Multistakeholder agreement; continuous auditing; transparency about priors and training data.
Cross-cutting assumptions and dependencies
- Physics calibration: Forces and mass are on relative scales; domain-specific calibration and verification are essential for high-stakes use.
- Perception stack: Accurate detection, segmentation, tracking, and optional mass inference are critical to map videos to actionable plans.
- Verification: Generative plans should be validated with physics engines or empirical tests before execution; visual plausibility is not sufficient.
- Safety and ethics: Human-in-the-loop oversight, guardrails, and compliance are required, especially in robotics, healthcare, and public environments.
- Base model priors: Generalization quality depends on the base video model (e.g., Wan2.2) and may vary across domains; retraining/fine-tuning might be needed for specific sectors.
Glossary
- 2AFC: Two-alternative forced-choice, a human evaluation protocol where participants choose between two options. "a 2AFC human study () on Prolific"
- Alpha blending: A technique for overlaying images or videos by mixing pixel values with transparency. "We visualize the control signal overlaid on top of the video via alpha blending."
- Antecedent action: The causative motion or event that precedes and produces a desired effect. "generate the antecedent action to accomplish the task."
- Causal chain: A sequence of cause-and-effect interactions linking actions to outcomes. "plan a causal chain of physical interactions to achieve a specified goal force."
- Causal primitives: Fundamental, simple physical interactions used to teach models basic causality. "simple, synthetic examples of causal primitives, such as elastic collisions and falling dominos."
- ControlNet: A conditioning module that injects control signals into diffusion models to guide generation. "We use a ControlNet \citep{zhang2023adding} module to condition on our physics signal"
- Control tensor: A multi-channel tensor encoding control information (e.g., forces, mass) over space and time. "We introduce a 3-channel physics control tensor"
- DiT: Diffusion Transformer; transformer layers used within diffusion models for generative tasks. "clones the first 10 DiT layers from the pretrained Wan2.2"
- Dirac delta function: A distribution concentrated at a single point, used here to describe a degenerate probability. "i.e., is a Dirac delta function on a single domino"
- Empirical probability mass function (PMF): The sample-based estimate of a discrete probability distribution. "Let be the empirical probability mass function (PMF)"
- Faster R-CNN: A deep learning architecture for object detection and localization. "We use Faster R-CNN~\cite{ren2016fasterrcnnrealtimeobject} to detect the positions of the two balls."
- Force-conditioned video generation: Video synthesis guided by specified forces acting in the scene. "Our method reframes force-conditioned video generation from specifying a direct force ... to declaring a desired goal force."
- Gaussian blob: A smooth localized pattern (Gaussian) used to encode signals like force in space-time. "represent this as a 'moving Gaussian blob' video"
- Goal force: A specified force desired on a target object that the model must achieve via planning. "the user provides a goal force, and the model generates the causes that achieve the desired effect"
- High-noise expert: In a mixture-of-experts diffusion model, the expert specialized for high-noise timesteps. "we fine-tune this ControlNet only for the high-noise expert"
- Implicit neural physics planner: A learned model that plans physical actions without an explicit physics engine. "to act as an implicit neural physics planner."
- Implicit neural physics simulator: A learned model that internally approximates physical dynamics instead of using an external simulator. "implicit neural physics simulators"
- Jensen-Shannon Divergence (JSD): A symmetric information-theoretic measure of difference between probability distributions. "based on the Jensen-Shannon Divergence (JSD)."
- Mixture-of-Experts diffusion model: A diffusion model architecture with multiple expert subnetworks specialized for different conditions. "Wan2.2 \citep{wan2025}, a Mixture-of-Experts diffusion model."
- Out-of-distribution: Data or scenarios that differ significantly from those seen during training. "an out-of-distribution background, viewpoint, lighting, and ball size."
- Patch embedding: Mapping image patches into vector embeddings for transformer-based models. "pass the result through a randomly initialized patch embedding layer"
- Physics-aware planning: Planning that accounts for and respects physical properties and constraints. "enabling precise, physics-aware planning without reliance on external engines."
- Privileged physics information: Additional physical parameters (e.g., mass) provided to the model to aid reasoning. "leverage privileged physics information when available"
- Spatial-temporal encoding: A representation that jointly encodes spatial and temporal information. "This tensor is the spatial-temporal encoding of the abstract user prompt."
- Visual planning: Using generated videos to depict and evaluate prospective action sequences to achieve goals. "and enables visual planning, respecting the physical properties of the objects and their environments."
- World models: Generative models that simulate environment dynamics and possible futures. "development of 'world models' capable of simulating potential futures for robotics and planning."
- Zero-convolutions: Zero-initialized convolutional layers used to safely inject control features into a frozen model. "feeding their outputs to the frozen base model via zero-convolutions."
- Zero-shot generalization: Performing well on novel tasks or domains without task-specific training. "zero-shot generalization to complex, real-world scenarios"
- Zero-shot tool usage: Using tools appropriately in novel contexts without explicit training on those tools. "this capability extends to zero-shot tool usage"
Collections
Sign up for free to add this paper to one or more collections.