- The paper introduces an end-to-end deep learning framework that integrates causal delay, macroeconomic graph priors, and a SoftMin loss for robust allocation.
- It employs a hybrid architecture combining LSTM, variable selection, and self-attention to mitigate noise and capture regime-dependent asset dynamics.
- Empirical results show improved net Sharpe ratios and reduced turnover compared to traditional models, validating its regime robustness in practical settings.
DeePM: Structured Deep Learning for Regime-Robust Systematic Macro Portfolio Management
Systematic macro portfolio management is challenged by non-stationary return distributions, regime shifts, and substantial trading frictions. Classical mean-variance optimization frameworks suffer from error amplification and turnover inefficiency. Common machine learning architectures typically adopt a two-stage, decoupled approach (forecasting then allocation), resulting in loss misalignment and poor deployment efficiency. DeePM re-conceptualizes the portfolio management process by learning allocation policies end-to-end, optimizing directly for robust, risk-adjusted net returns under practical asset universe constraints.
DeePM explicitly addresses three central issues:
- Ragged filtration arising from asynchronous global market closes, solved via a Directed Delay architecture to ensure filtration-respecting causal signal extraction.
- Low signal-to-noise ratio and regime fragility, addressed via a hard-coded macroeconomic prior graph constraining cross-sectional dependence and enforcing information flow along economically plausible transmission channels.
- Distributionally robust objective using a differentiable SoftMin penalty on rolling-window Sharpe ratios, which serves as a smooth surrogate for Entropic Value-at-Risk (EVaR).
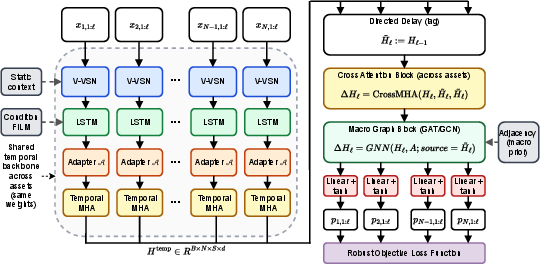
Figure 1: DeePM pipeline integrates temporal encoding, cross-sectional attention with causal Directed Delay, structural regularization via Macro-Graph GNN, and a regime-robust loss.
Architectural Innovations
Temporal and Cross-Sectional Encoding
At each decision epoch, DeePM processes per-asset histories using a hybrid backbone: Variable Selection Network (V-VSN) combined with LSTM and temporal self-attention for denoising and regime-dependent encoding. The temporal encoder is strictly channel-independent until subsequent spatial aggregation, ensuring robust state-representation prior to cross-asset mixing.
The cross-sectional module refines these embeddings using Multi-Head Attention, lagged to respect causal information constraints (Directed Delay), thereby isolating impulse-response and transfer entropy rather than synchronous co-movements. Cascading filtration, which maximizes data freshness by hybridizing information sets across assets depending on regional close times, is provided only as an ablation protocol due to its susceptibility to look-ahead bias and non-stationary noise injection.
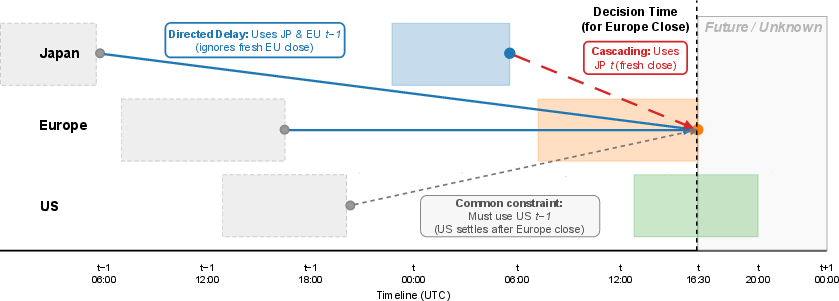
Figure 2: Asynchrony of global closes relative to decision time; Directed Delay enforces robust causal separation in cross-sectional attention.
Macroeconomic Graph Prior
DeePM applies an explicit macroeconomic prior graph to all cross-sectional representations. The graph topology is deterministically designed, encoding sector homophily, supply chain dependencies, transmission channels (e.g., carry, inflation triangle), and regional integrations. Graph Neural Networks (GAT/GNN, Graphormer variants) enforce spectral regularization, constraining asset embeddings to smooth over ex-ante economic linkages. The adjacency matrix imparts real-world sparsity and interpretable inductive biases not achievable via pure data-driven attention.
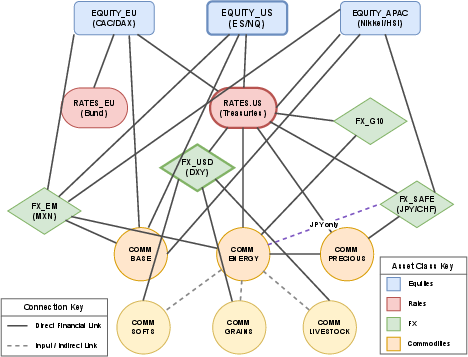
Figure 3: Macro-Structural Prior Graph; deterministic edges enforce economic regularization, limiting overfitting to spurious correlations.
Change from Standard Models
Asset identity is handled rigorously through ticker embeddings and permutation-equivariant set encodings, so DeePM's outputs remain insensitive to arbitrary asset ordering and dynamic universe composition (masking, rolling contracts, missingness). All transaction cost modeling is nontrivial and reflects empirically calibrated tick/impact bands, accounting for microstructure, session effects, and market depth constraints, with convex ensemble cost guarantees formalized in the appendix.
Distributionally Robust Learning Objectives
DeePM replaces naive pooled Sharpe objectives with a SoftMin aggregation over windowed Sharpe ratios. This is shown to be mathematically equivalent to adversarial EVaR minimization, imposing an implicit KL-ball distributionally robust optimization constraint. The SoftMin temperature tunes the trade-off between average-case (risk-neutral) and worst-case (minimax) regime survival, with gradient signal concentrated on the hardest windows. Gradient accumulation is handled by a two-pass protocol to ensure non-separable objective correctness when batching exceeds device memory.
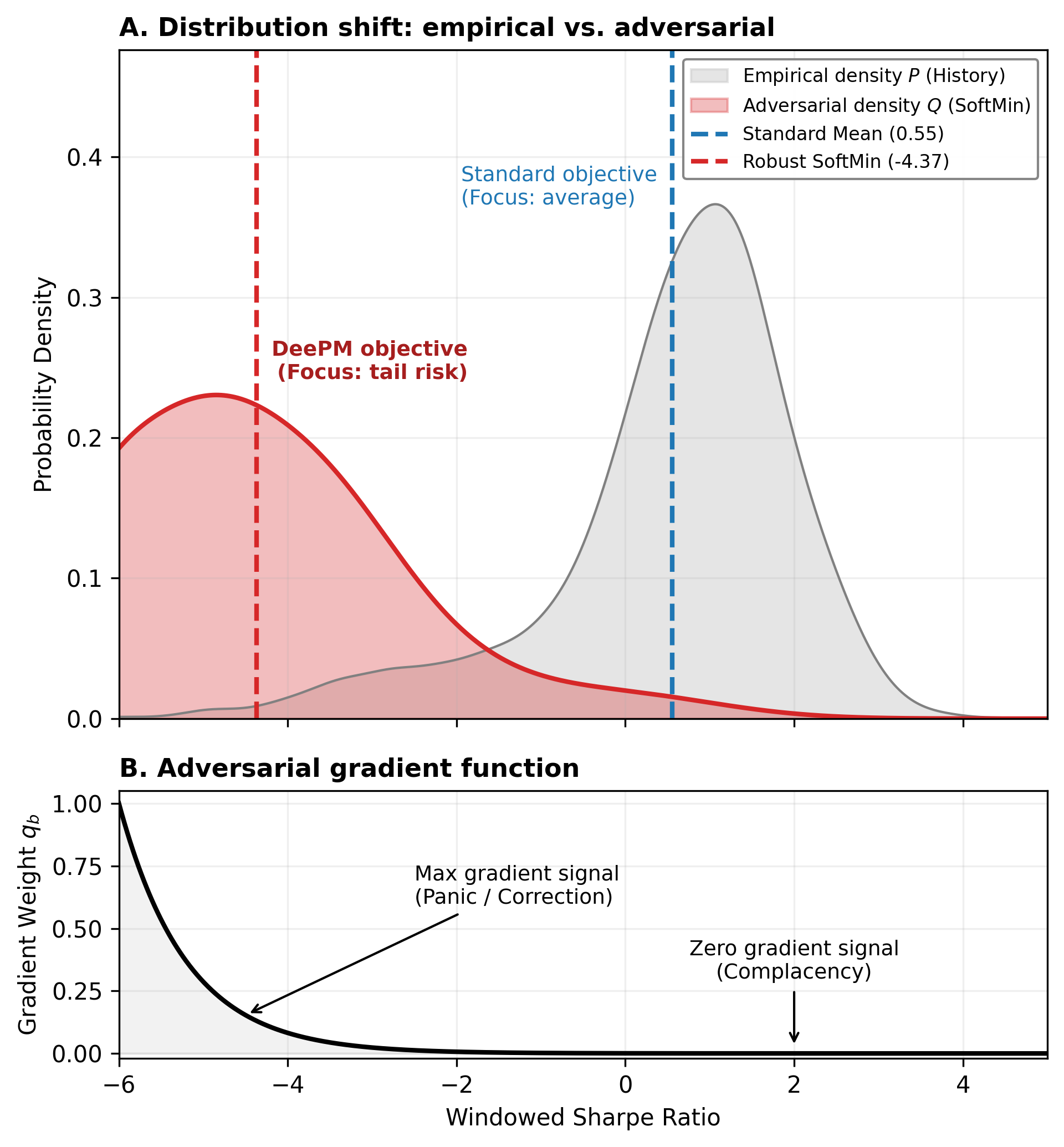
Figure 4: SoftMin penalty shifts adversarial weights to worst historical windows, enforcing regime-robust minimax curriculum.
Empirical Results
DeePM is bench-marked out-of-sample (2010–2025) vs a spectrum of baselines including passive equal risk, TSMOM, MACD and covariance-aware two-stage pipelines (risk managed trend, MVO, risk parity), as well as the Momentum Transformer. All strategies are strictly evaluated net-of-cost, using the full asset universe, realistic frictions, and chronological walk-forward splits. Ensembles (top K seeds) are used for performance stability and structural turnover regularization.
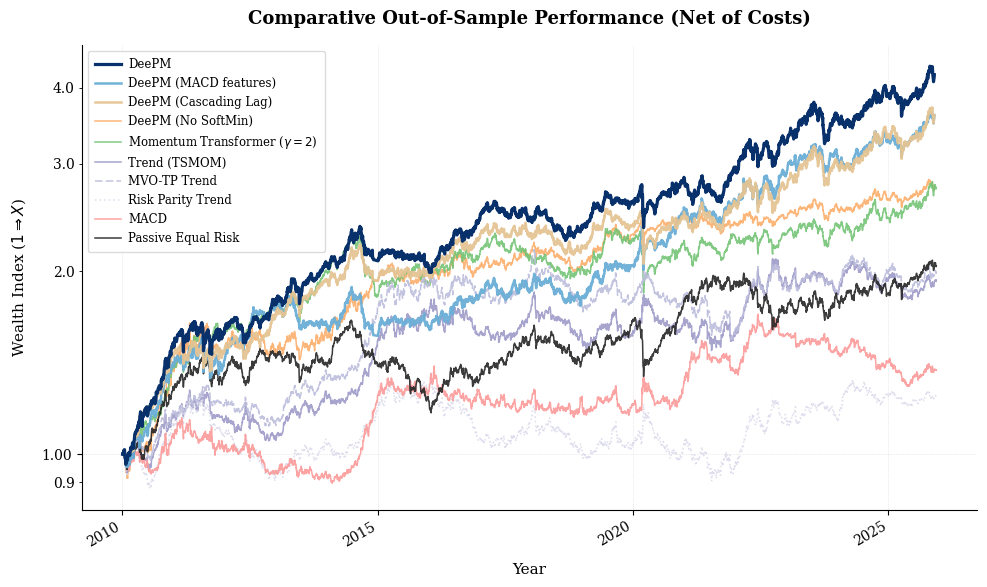
Figure 5: Cumulative net-of-cost wealth for DeePM variants vs systematic baselines; long-term compounding is visualized on a log scale.
Strong numerical results and bold claims in the paper include:
- DeePM achieves a net Sharpe ratio of $0.93$ (annualized) with HAC t-statistic $3.69$, statistically significant advantage vs passive/risk parity ($0.50$) and TSMOM ($0.45$).
- Outperforms Momentum Transformer (Sharpe $0.66$), quantifying marginal gains of graph prior and causal delay.
- Ablation studies confirm that lagged cross-attention, graph priors, SoftMin objective, and optimal cost scaler (γ=0.5) dominate generalization capability.
- Unconstrained attention (no graph) yields lower Sharpe ($0.79$), demonstrating overfitting risk; graph-only and cross-attention-only fail to match the full model.
- SoftMin loss outperforms pooled-only Sharpe; pure minimax (τ→0) causes optimization instability, while looser τ dilutes regime robustness.
- Ensembles reliably reduce turnover and improve net Sharpe, confirming convex cost guarantees.
Rolling window analysis demonstrates robust performance across regime shifts (CTA winter, post-2020 volatility). DeePM maintains positive Sharpe during periods where classical momentum strategies suffer major drawdowns and is statistically significant relative to passive allocation even during an "Everything Bubble," signifying genuine cross-sectional alpha extraction (Information Ratio $0.44$).
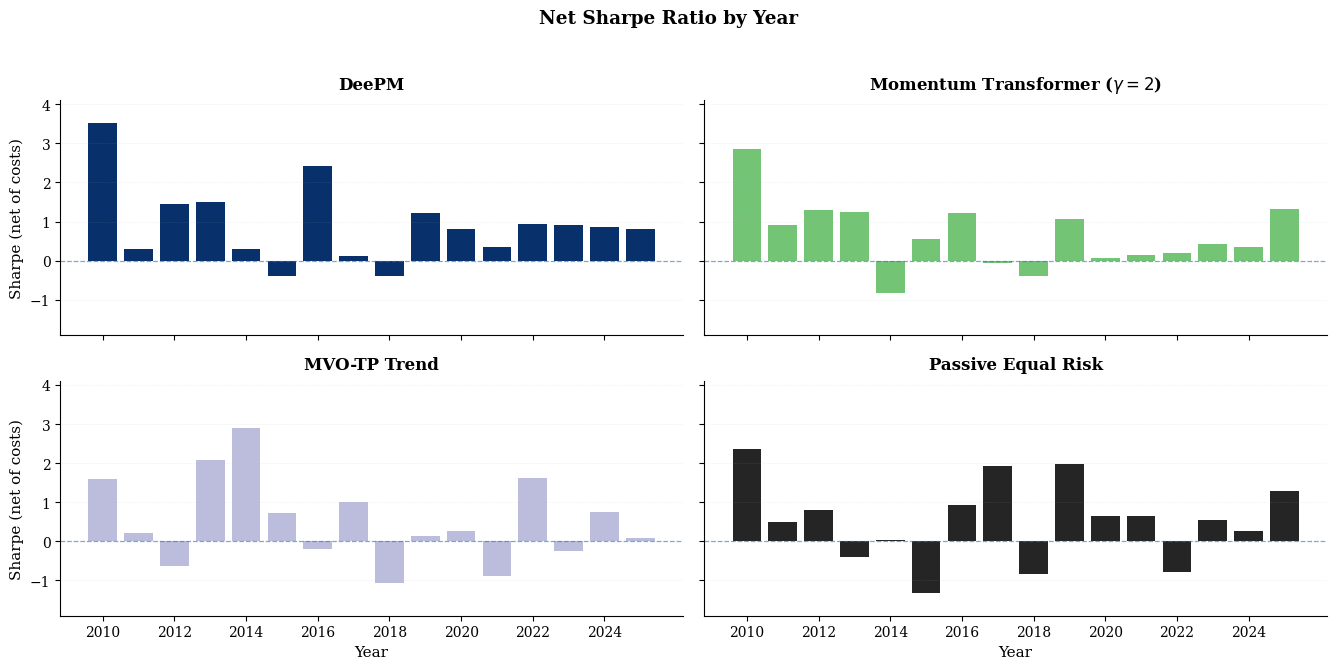
Figure 6: Rolling 12-month Sharpe of DeePM vs TSMOM; DeePM preserves stable alpha during adverse macro regimes.
Theoretical Implications
Architectural choices are interpreted in dynamical, Bayesian, and information-theoretic frameworks. Temporal modules are shown to approximate state-space reconstruction under noisy dynamical systems. Graph regularization is related to GMRF priors enforcing Dirichlet energy minimization, balancing likelihood and structure on the latent manifold. Cross-sectional lagging enforces transfer entropy over mutual information, targeting asymmetric hierarchical causal drivers rather than transient correlations. Ensemble regularization and turnover convexity proofs are presented, substantiating the methodology's practical viability.
Practical Implications and Future Directions
DeePM serves as a template for deployable macro portfolio management architectures that are robust to regime changes, frictions, and asset universe composition. Its core advances—causal cross-asset attention, fixed economic priors, and distributionally robust objectives—mitigate overfitting, optimize realistic execution, and prioritize survival in adverse environments. The framework is extensible to dynamic topologies (graph learning), explainable GNN analysis, hierarchical representations, expanded feature sets (carry, macro drivers), and higher-frequency decision problems (intraday regime learning).
Conclusion
DeePM systematically unifies domain structure with deep representation learning, achieving regime-robust, cost-aware outperformance in systematic macro portfolio management. Its theoretical alignment with EVaR, practical treatment of asynchronous information, and empirical validation establish its authority as a blueprint for next-generation institutional quantitative trading architectures.